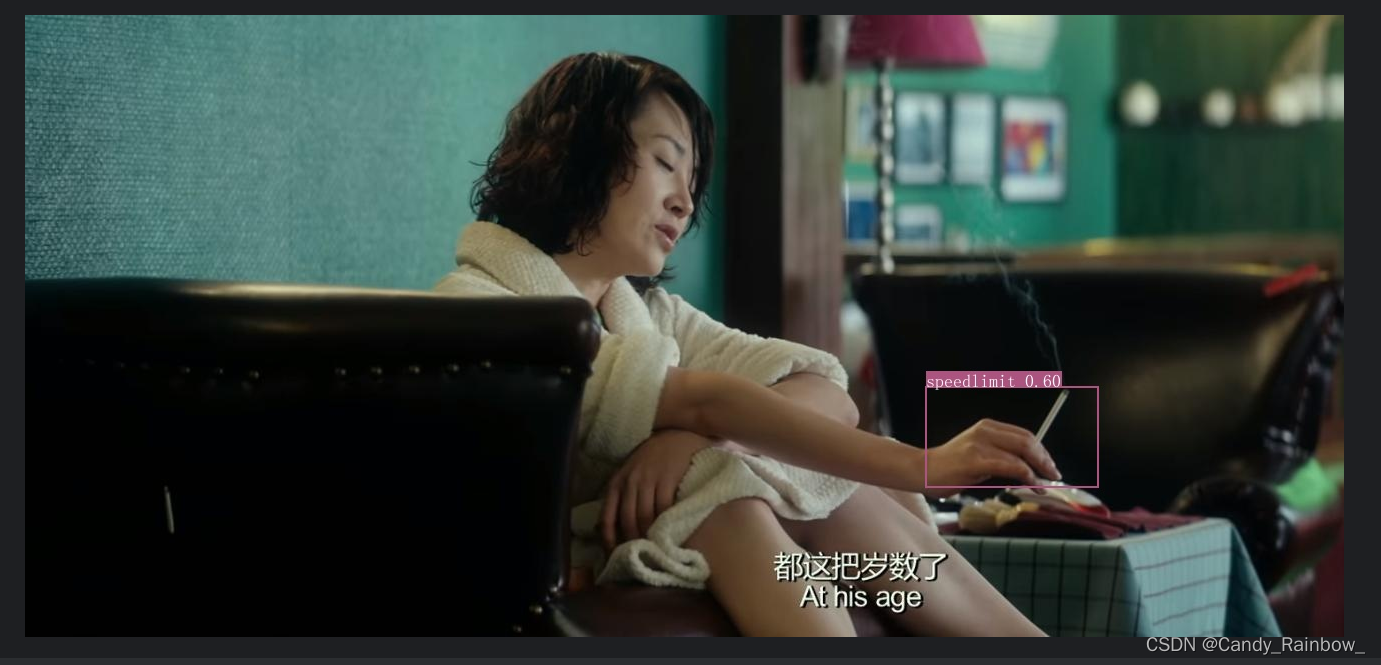
一 安装paddlepaddle和paddledection(略)
笔者使用的是自己的数据集
二 在dataset目录下新建自己的数据集文件,如下:
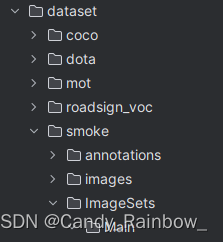
其中
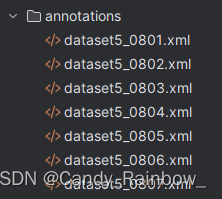
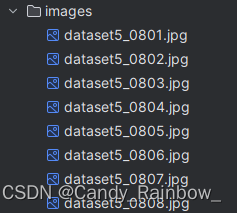
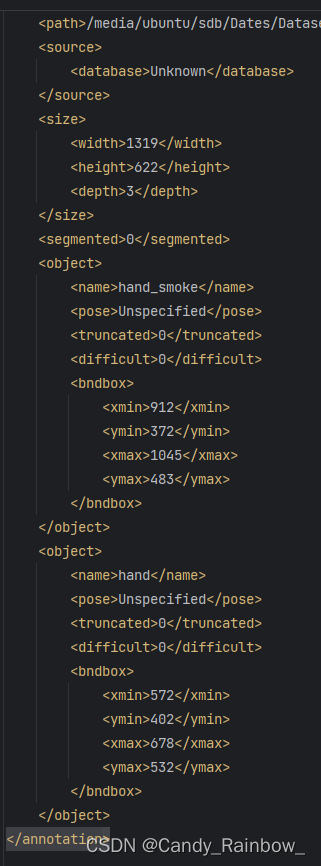
xml文件内容如下:
另外新建一个createList.py文件:
# -- coding: UTF-8 --
import os
import os.path as osp
import re
import random
devkit_dir = '../smoke/'
years = ['2007', '2012']
def get_dir(devkit_dir, type):
return osp.join(devkit_dir, type)
def walk_dir(devkit_dir):
filelist_dir = get_dir(devkit_dir, 'ImageSets/Main')
annotation_dir = get_dir(devkit_dir, 'annotations')
img_dir = get_dir(devkit_dir, 'images')
trainval_list = []
test_list = []
added = set()
for _, _, files in os.walk(filelist_dir):
for fname in files:
img_ann_list = []
if re.match('train\.txt', fname):
img_ann_list = trainval_list
elif re.match('val\.txt', fname):
img_ann_list = test_list
else:
continue
fpath = osp.join(filelist_dir, fname)
for line in open(fpath):
name_prefix = line.strip().split()[0]
if name_prefix in added:
continue
added.add(name_prefix)
ann_path = osp.join(annotation_dir, name_prefix + '.xml')
img_path = osp.join(img_dir, name_prefix + '.jpg')
assert os.path.isfile(ann_path), 'file %s not found.' % ann_path
assert os.path.isfile(img_path), 'file %s not found.' % img_path
img_ann_list.append((img_path, ann_path))
return trainval_list, test_list
def prepare_filelist(devkit_dir, output_dir):
trainval_list = []
test_list = []
trainval, test = walk_dir(devkit_dir)
trainval_list.extend(trainval)
test_list.extend(test)
random.shuffle(trainval_list)
with open(osp.join(output_dir, 'trainval.txt'), 'w') as ftrainval:
for item in trainval_list:
ftrainval.write(item[0] + ' ' + item[1] + '\n')
with open(osp.join(output_dir, 'test.txt'), 'w') as ftest:
for item in test_list:
ftest.write(item[0] + ' ' + item[1] + '\n')
if __name__ == '__main__':
prepare_filelist(devkit_dir, '../smoke')
一个data2tarin.py文件:
# -- coding: UTF-8 --
import os
import random
trainval_percent = 0.9
train_percent = 0.9
xml = r"D:\Coding\PaddleDetection-release-2.7\dataset\smoke\annotations"
save_path = r"D:\Coding\PaddleDetection-release-2.7\dataset\smoke\ImageSets\Main"
if not os.path.exists(save_path):
os.makedirs(save_path)
total_xml = os.listdir(xml)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
print("train and val size", tv)
print("traub size", tr)
ftrainval = open(os.path.join(save_path, 'trainval.txt'), 'w')
ftest = open(os.path.join(save_path, 'test.txt'), 'w')
ftrain = open(os.path.join(save_path, 'train.txt'), 'w')
fval = open(os.path.join(save_path, 'val.txt'), 'w')
for i in list:
name = total_xml[i][:-4]+'\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest .close()
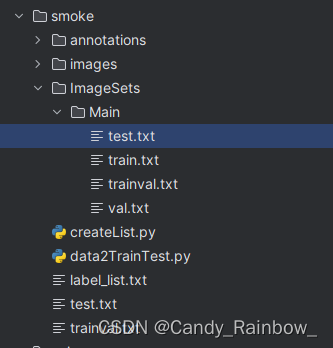
运行以上两个脚本,结果如图:
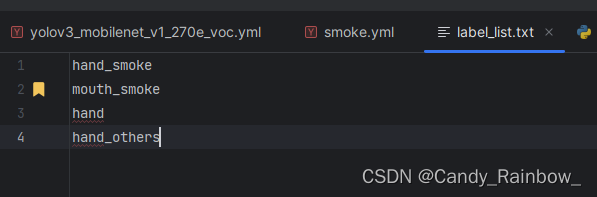
新建label_list.txt文件,内容如下,为标签文件:
三 新建smoke.yml文件
内容如下:
metric: VOC
map_type: 11point
num_classes: 4
TrainDataset:
name: VOCDataSet
dataset_dir: dataset/smoke
anno_path: trainval.txt
label_list: label_list.txt
data_fields: ['image', 'gt_bbox', 'gt_class', 'difficult']
EvalDataset:
name: VOCDataSet
dataset_dir: dataset/smoke
anno_path: test.txt
label_list: label_list.txt
data_fields: ['image', 'gt_bbox', 'gt_class', 'difficult']
TestDataset:
name: ImageFolder
anno_path: dataset/smoke/label_list.txt
主要修改num_classes以及dataset_dir和anno_path
四 修改yolov3.yml文件,内容如下:
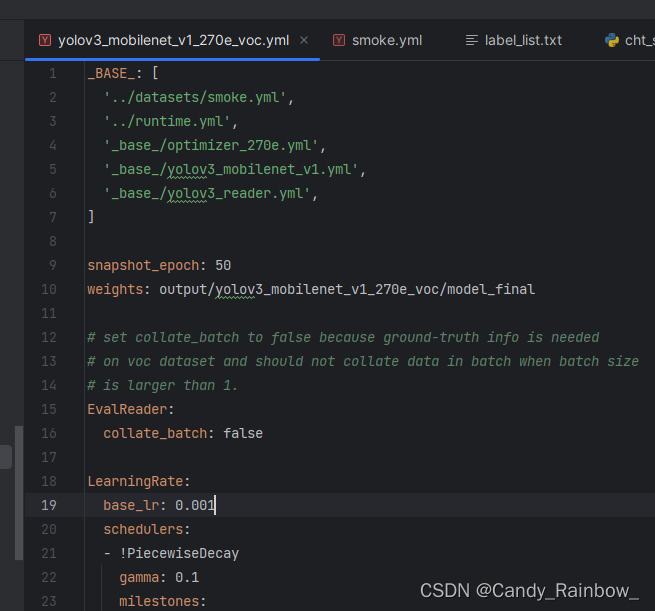
主要修改第一行
五 运行
六 大功告成

七 推理
修改yolov3.yml文件
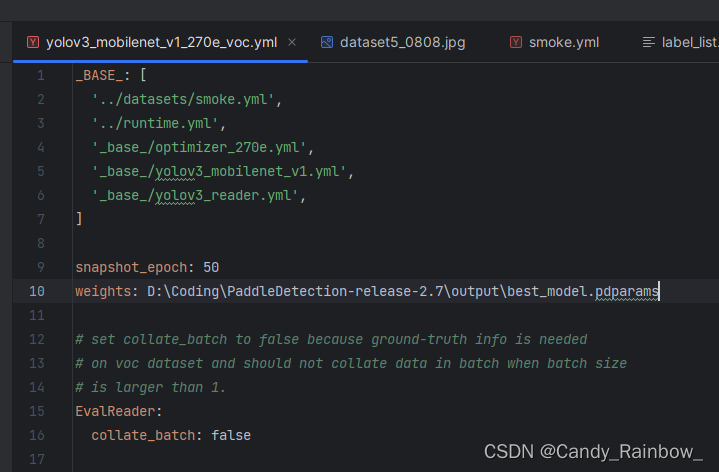
主要修改weights文件地址
运行
输出到output文件夹中