首先附视频学习地址
https://www.bilibili.com/video/BV1ywSUY6EDp/?spm_id_from=333.880.my_history.page.click
Python基础学习
前言,对于安装VM虚拟机以及python环境这里不做详细笔记
在python中也是有主函数main的,不过是属于魔术方法
if __name__=='__main__':
pass #空语句pass
一、基本数据类型的初步了解
① 数字(number)
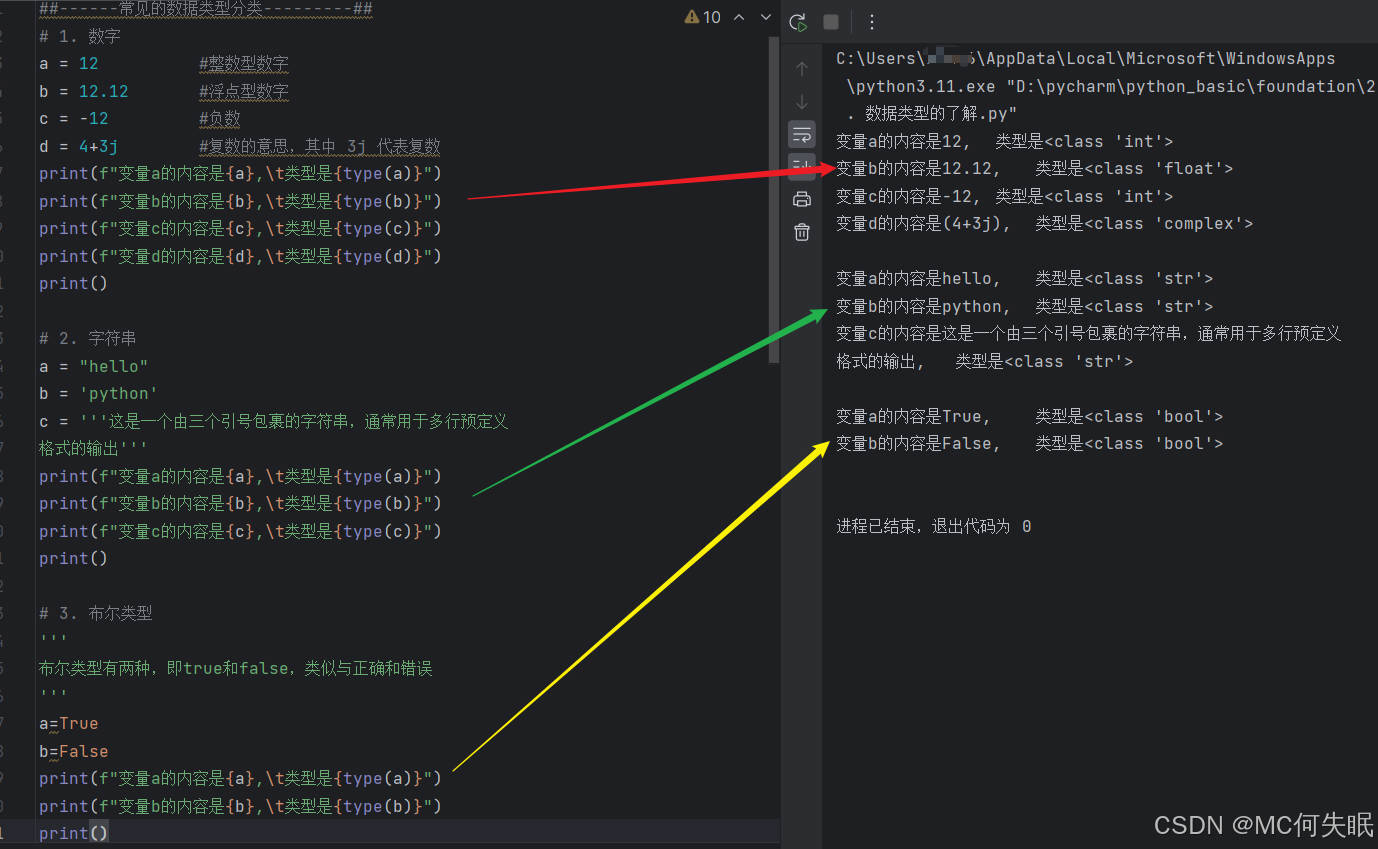
a = 12 #整数型数字
b = 12.12 #浮点型数字
c = -12 #负数
d = 4+3j #复数的意思,其中 3j 代表复数 #转义字符有很多,\n换行等,可自查
print(f"变量a的内容是{a},\t类型是{type(a)}") #这里的\t表示转义字符,也就是制表符
print(f"变量b的内容是{b},\t类型是{type(b)}") #如果不想让其生效,在输出的时候可以加r
print(f"变量c的内容是{c},\t类型是{type(c)}") #如print(r'\t类型是xxxx')
print(f"变量d的内容是{d},\t类型是{type(d)}") #这里就会把\t原封不动的输出
② 字符串(string)
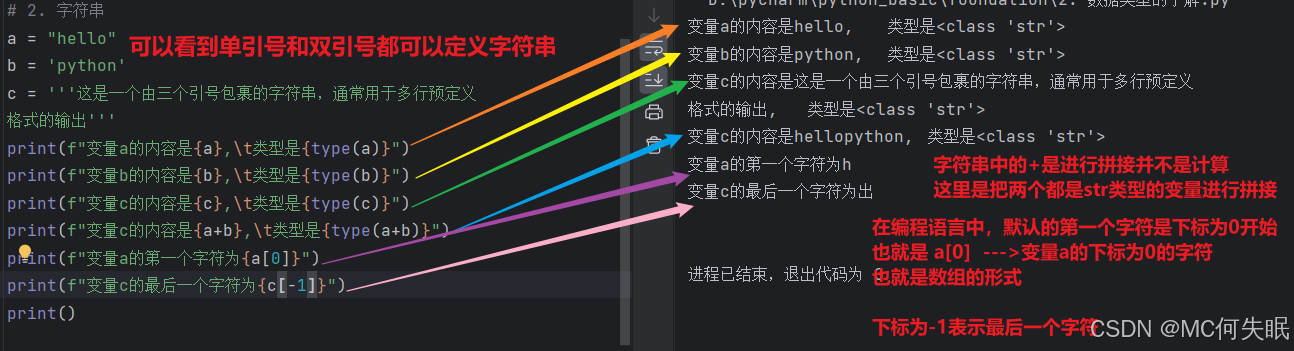
a = "hello"
b = 'python'
c = '''这是一个由三个引号包裹的字符串,通常用于多行预定义
格式的输出'''
print(f"变量a的内容是{a},\t类型是{type(a)}")
print(f"变量b的内容是{b},\t类型是{type(b)}")
print(f"变量c的内容是{c},\t类型是{type(c)}")
③ 布尔类型(bool)
'''
布尔类型有两种,即true和false,类似与正确和错误
'''
a=True
b=False
print(f"变量a的内容是{a},\t类型是{type(a)}")
print(f"变量b的内容是{b},\t类型是{type(b)}")
④ 列表(list)
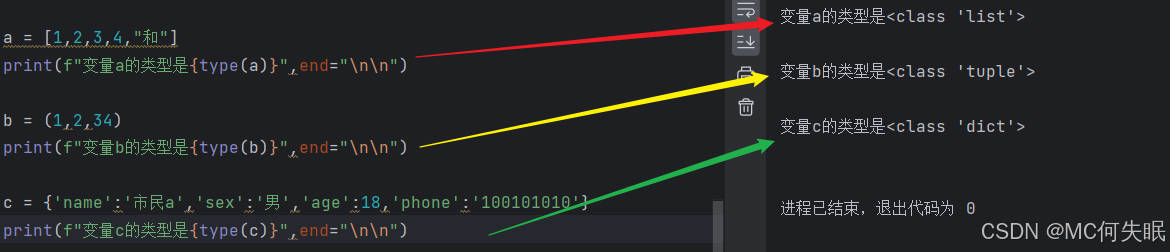
a = [1,2,3,4,"和"] #列表是以中括号为代表
print(f"变量a的类型是{type(a)}",end="\n\n")
⑤ 元组(tuple)
b = (1,2,34) #元组是以圆括号为代表
print(f"变量b的类型是{type(b)}",end="\n\n")
⑥ 字典(dictionary)
c = {'name':'市民a','sex':'男','age':18,'phone':'100101010'} #字典是以大括号为代表
print(f"变量c的类型是{type(c)}",end="\n\n")
二、基本数据类型的进一步学习
① 数字(number)
a = 12 #整数型数字
b = 12.12 #浮点型数字
c = -12 #负数
d = 4+3j #复数的意思,其中 3j 代表复数
print(f"变量a+b的值为:{a+b},\t类型为{type(a+b)}")
print(f"变量a+c的值是:{a+c}, \t类型为{type(a+c)}")
print(f"变量c+b的值是:{c+b}, \t类型为{type(c+b)}")
print(f"变量a+d的值是:{a+d},\t类型为{type(a+d)}")

② 字符串(string)
a = "hello"
b = 'python'
c = '''这是一个由三个引号包裹的字符串,通常用于多行预定义
格式的输出'''
print(f"变量a的内容是{a},\t类型是{type(a)}")
print(f"变量b的内容是{b},\t类型是{type(b)}")
print(f"变量c的内容是{c},\t类型是{type(c)}")
print(f"变量c的内容是{a+b},\t类型是{type(a+b)}")
print(f"变量a的第一个字符为{a[0]}")
print(f"变量c的最后一个字符为{c[-1]}")
print(a[1:3]) #这里表示截取变量a中的指定的范围,然后输出,也就是ell
#变量名[头下标 : 尾下标]
a[1]='sd' #可以修改指定下标位置的字符串数据
③ 布尔(bool)
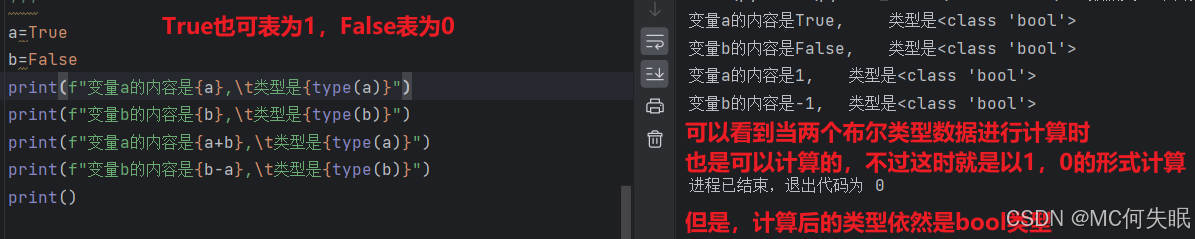
a=True
b=False
print(f"变量a的内容是{a},\t类型是{type(a)}")
print(f"变量b的内容是{b},\t类型是{type(b)}")
print(f"变量a的内容是{a+b},\t类型是{type(a)}")
print(f"变量b的内容是{b-a},\t类型是{type(b)}")
④ 列表(list)
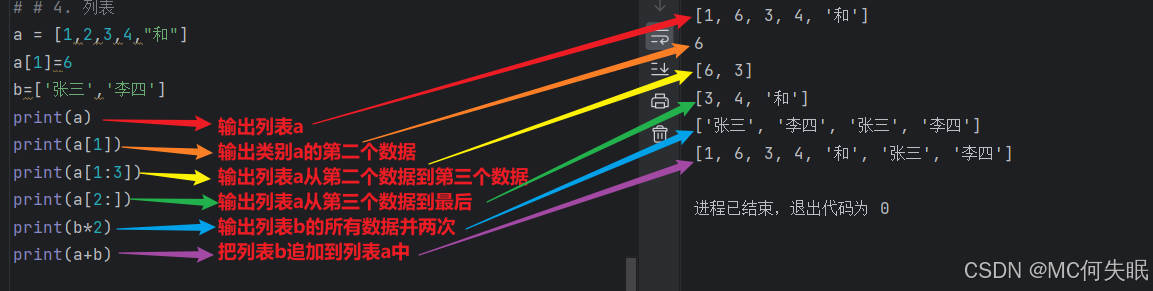
a = [1,2,3,4,"和"]
a[1]=6
b=['张三','李四']
print(a)
print(a[1])
print(a[1:3]) #这里需要注意,列表是左开右闭的,所以尾下标的值是不包含在内的
print(a[2:])
print(b*2)
print(a+b)
a.append("longyusec") #添加longyusec至列表的尾部
print(a)
a.pop(-1) #删除下标为-1的列表中的数据,也就是删除尾部数据
print(a)

#列表推导式 推导式的方式,比是以遍历然后使用a.append()添加的速度更快
a = [1,2,3,4,"和"]
list1 = [x for x in a] #把列表a中的数据进行遍历,然后添加到list1列表中
list2 = [x for x in range(20)] #把0~19数字添加到list2列表
print(list1) #range也是左开右闭,并且是从0开始
print(list2)

⑤ 元组(tuple)
#元组中的查看与列表一样,只有一点,不能修改数据,也就是元组创建之后,就定性了
a = (1,2,34)
print(a)
print(a[0])
print(a[1:])
#a[0]=12 #一旦修改,系统会报错
print(a)

#元组推导式 与列表推导式相似
a = (1,2,34)
x = {x for x in a}
print(x)

⑥ 字典(dictionary)
#字典的形式是键值对的形式,也就是 key:value 的形式,可通过查询key获取对应的值
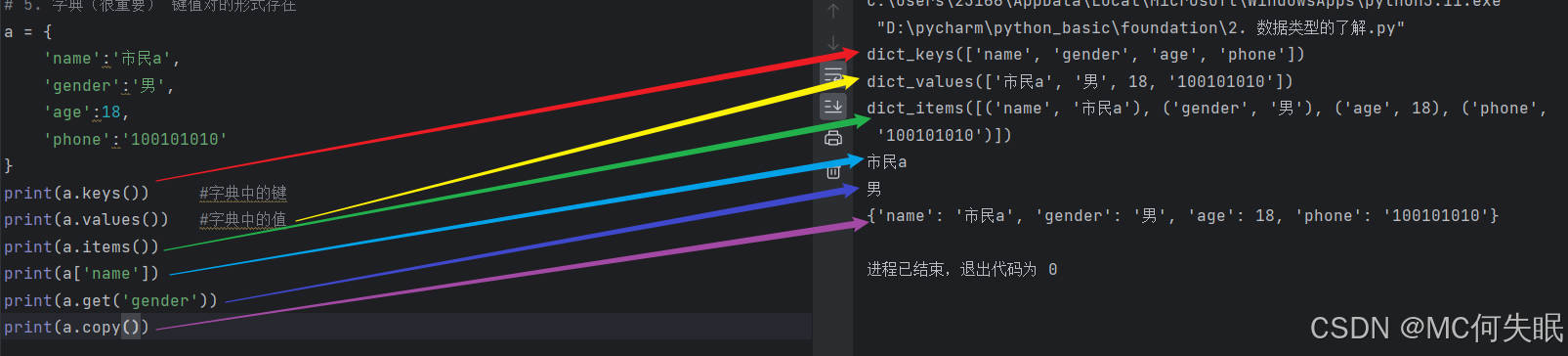
a = {
'name':'市民a',
'gender':'男',
'age':18,
'phone':'100101010'
}
print(a.keys()) #字典中的键
print(a.values()) #字典中的值
print(a.items()) #以键值对的形式输出一组组数据
print(a['name']) #输出字典中,key为name的值
print(a.get('gender')) #这个get也是通过输入key来获取对应的值
print(a.copy()) #这个是把字典进行复制下来的
print(a.pop('name')) #当然还有pop删除,这个也是对应的值,进行删除
#字典推导式 index表下标,从0开始
num = 100
x = {x: index*num for index,x in enumerate(['key1','key2','key3'])}
print(x)
#x对应的是字典的名称
#就是把index与x进行for循环遍历时,每次遍历按照前面的 x:index*num的形式去赋值
#后面的key1....就是key的名称
#这种就是已知key名,往key中添加数据
#相当于
x={}
for x,index in enumerate(['key1','key2','key3']){
value = index * num
x[key] = value
}
print(x)

三、条件分支语句
#语句结构
if 【条件判断】: #如果条件判断正确
xxxx #执行这里
elif 【条件判断 #否则,并且再如果
xxxx #执行这里
else #否则
xxxx #执行这里
#常有的条件判断符号
#比较运算符
< (小于)
> (大于)
>= (大于等于)
<= (小于等于)
!= (不等于)
== (是否相等)
#逻辑运算符
and (与)
or (或)
not (非)
#实列
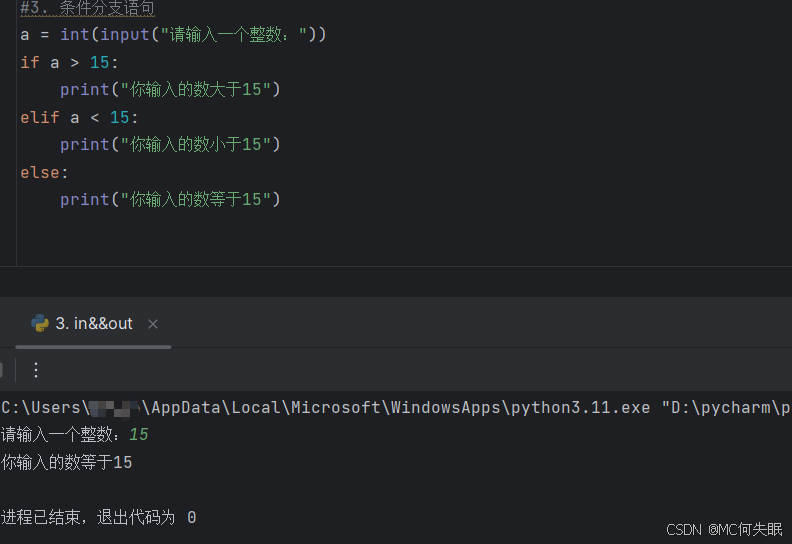
a = int(input("请输入一个值:")) #input(),是可以与用户进行交互的函数
#也就是执行到这里,等待用户输入,里面的字符会显示在屏幕,int()是强制转换为int类型
if a < 15:
print("输入的数小于15")
else a > 15:
print("输入的数大于15")
else:
print("输入的数等于15")
四、循环语句
① while循环
while 【判断】: #程序执行到这里进入循环,然后判断,若结果为true或者不满足这个判断时,才会结束
xxxx #执行语句,如果循环未结束,会一直进入循环,执行语句
while True: #所谓的死循环,因为True可表示1,1表示正确,就会永远执行循环
xxxx
#实例
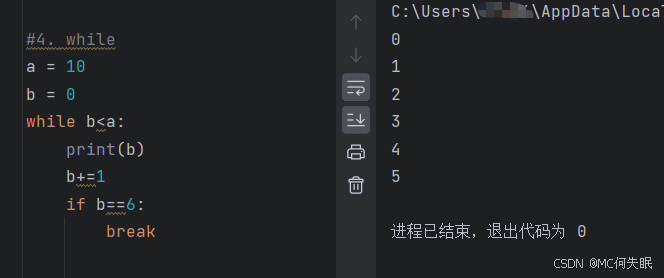
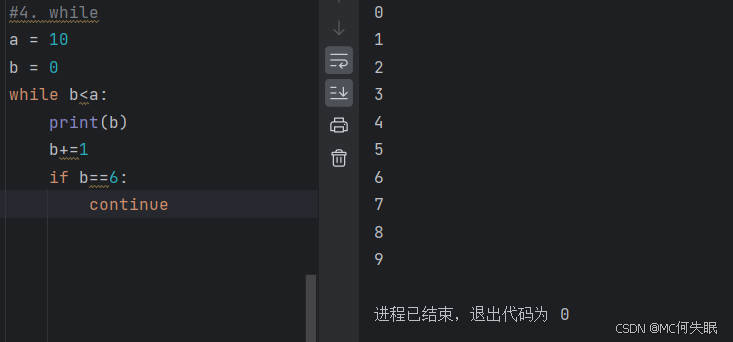
a = 10
b = 0
while b<a:
print(b)
b+=1
if b==6:
continue/break #break表示退出当前循环
#continue表示继续进入循环
#在循环到某个点的时候,当到达需要的时候,可以使其退出循环,或者也可以当不到达想要的时候,可以再继续进行下去
② for语句
for ....else 形式,for表示循环,else表示在循环结束后会怎么怎么样
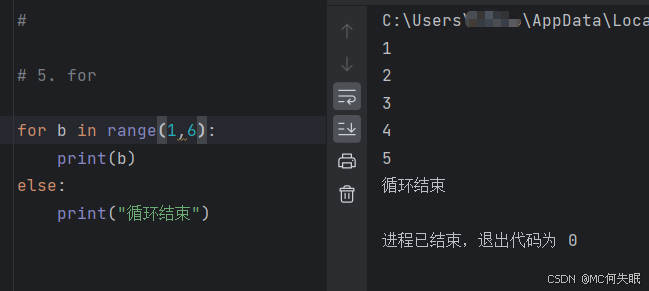
#简单的示例
for b in range(1,6):
print(b)
else:
print("循环结束")
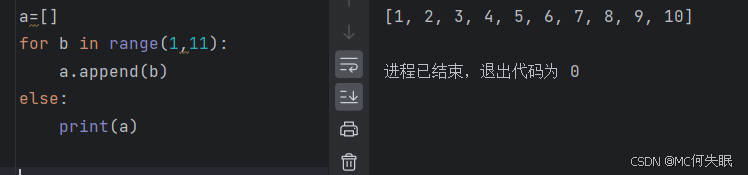
#示例,向空列表中生成1-10的数
a=[]
for b in range(1,11):
a.append(b)
else:
print(a)
#pass怎么使用
for b in enumerate(rage(1,10)):
pass
#表示在循环体中,我不想执行任何语句,但是python的机制不允许,这时候,使用pass即可
五、函数
① 函数声明
def 【函数名】: #def表示定义一个函数,define
pass
#函数是可调用的
#简单的示例
def name(name,age):
pass
def class():
name()
if __name__=='__main__':
name = 'sss'
age='22'
cl = class() #也就是相当于new,把函数class()的地址给cl
cl() #调用cl,相当于调用class()
name(name,age)
'''
函数的参数分为以下4种:
1. 必需参数(位置参数:positional argument)
2. 默认值参数(定义形参时,可以设置默认值)
3. 可变长参数,可选参数,必须加*号说明(*args)
4. 字典参数,关键字参数在,在可变长参数之后,还可以定义字典参数,必须加**声明(**kwargs)即key word args
参数顺序不能乱
'''
六、迭代器和生成器
① 迭代器
迭代是python最强大的功能之一,是访问集合元素的一种方式
迭代器是一个可以记住遍历的位置的对象
迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问结束。迭代器只能向前不会后退
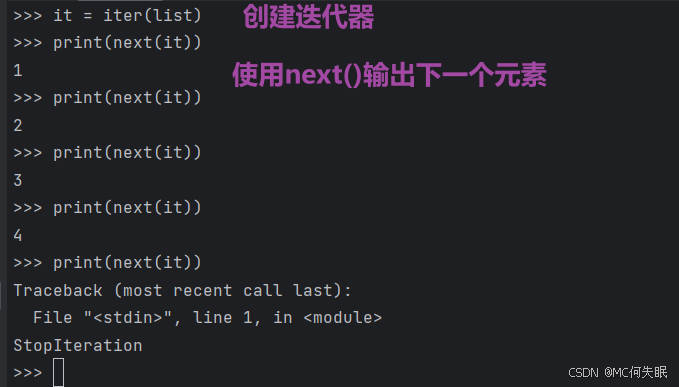
迭代器有两个方法:iter()和next()
字符串、列表或元组对象都可用于创建迭代器
#用for循环遍历,会自动结束
list = [1,2,3,4]
it = iter(list)
for x in it:
print(x,end=" ")

#使用next()函数
import sys #import是导入包的意思,python最叼的就是庞大的包,sys是可执行一些系统命令的
list=[1,2,3,4]
it = iter(list)
while True: #死循环
try:
print(next(it))
except StopIteration:
sys.exit() #StopIteraction是一种报错,如果出现其中的报错信息,就会执行下面命令
#sys.exit()系统的退出命令,会直接结束程序的运行
#这是一种报错处理,如果出现报错会进行处理,在该语句中,可以使得程序安全的运行。
try :
pass
except xxx: #这其中的报错包有太多,这个是有树状图的,建议了解一下
pass
finally:
pass #最终这里都会被执行
#一个try中,可能又很多except语句,这些语句可能对应着各种错误
#如果没有错误,就会忽略except语句
#如果有错误,那么在错误的地方停止程序,try中的后面语句不会再被执行
#except子句可同时处理多个一场,这些异常以元组的形式,except (valueerror,typeerror....)

② 生成器
它可以在循环中逐个返回值,而不必将所有值一次性加载到内存中。生成器函数使用yield关键字来暂停函数并产生一个值,然后在需要下一个值时再次恢复执行,使得生成器处理大量数据和无限序列时非常高效
生成器函数看起来像一个普通函数,但是使用yield而不是return返回结果。每次调用生成器函数时,会在上次离开的位置继续执行
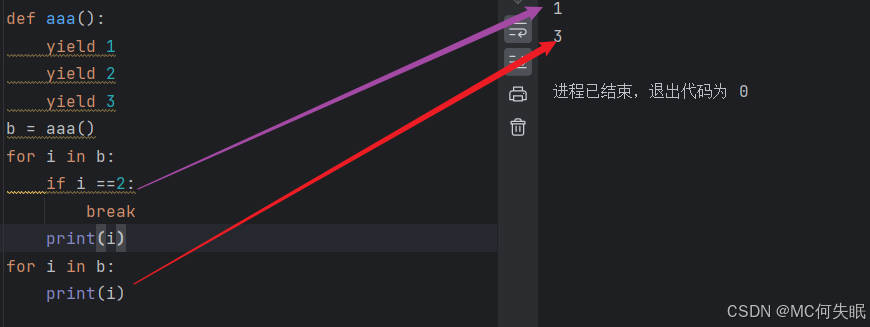
def aaa():
yield 1 #返回1
yield 2 #返回2
yield 3 #返回3
b = aaa()
for i in b:
if i ==2: #当i的值等于2时,退出循环,也就是根据yield的返回值判断
break #退出for表示不需要下一个值了
print(i)
for i in b: #当再次需要下一个值时,也就是又调用aaa(),发现是从上次暂停的位置和值开始
print(i)
#斐波那契数列生成器
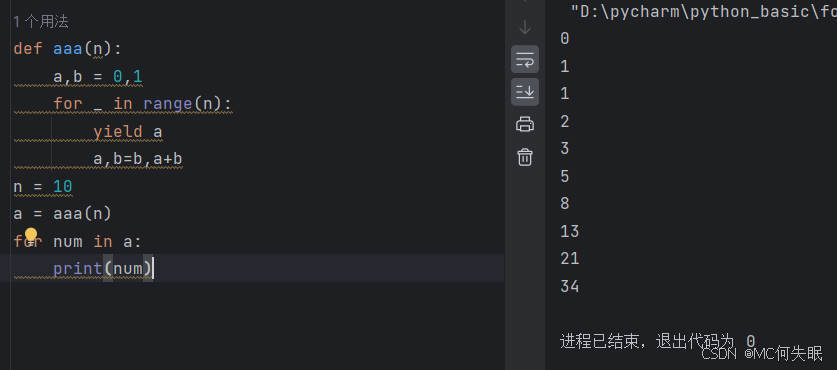
斐波那契数列(Fibonacci sequence),又称黄金分割数列。它的特点是数列的第一项和第二项是给定的起始值(通常是 0 和 1),从第三项开始,每一项都等于前两项之和。用数学公式表示为:F(n)=F(n-1)+F(n-2),其中n>1,且F(0)=0,F(1)=1。
数列的前几项依次是:0、1、1、2、3、5、8、13、21、34……
def aaa(n):
a,b = 0,1
for _ in range(n):
yield a
a,b=b,a+b
n = 10
a = aaa(n)
for num in a:
print(num)
七、文件读写
#文件读写两种方式
#打开文件,需要手动关闭文件
file="xxx"
a=open(file , mode='r') #mode有r(读)、w(写)
print(a.read())
a.close()
#使用with...as...使用,可自动关闭文件
with open(file , mode='r') as f:
print(f.read()) #read()表示读,write('xxx')表示把xxx写入file
'''
读取操作
1. read()
read(10),表示读取前面10个字符,指定读取的长度,不带参数,读取所以字符,包括换行符
2. readline()
按行读取,默认读取第一行
3. readlines()
按行全部读取,并将每一行保存到列表中
'''
这里的mode方式需要知道
文本模式
| 参数 | 用途 |
|---|---|
r(只读模式) | 用于读取文本文件的内容 |
w(只写模式) | 用于写入文本内容到文件。如果文件不存在,会创建一个新文件; 如果文件存在,则会清空文件原有内容后再写入。 |
a(追加模式) | 用于在文件末尾追加文本内容。如果文件不存在,会创建一个新文件。 |
r+(读写模式) | 用于对文件进行读取和写入操作。文件指针初始位置在文件开头, 读取操作从文件开头开始,写入操作可以在文件的任意位置进行 但要注意文件指针的位置 |
二进制模式
| 参数 | 用途 |
|---|---|
rb(只读二进制模式) | 用于读取二进制文件,如图片、音频、视频等文件。 |
wb(只写二进制模式) | 用于写入二进制数据到文件。如果文件不存在,会创建一个新文件; 如果文件存在,则会清空文件原有内容后再写入 |
ab(追加二进制模式) | 用于在二进制文件末尾追加二进制数据。如果文件不存在,会创建一个新文件。 |
rb+(读写二进制模式) | 用于对二进制文件进行读取和写入操作。文件指针初始位置在开头, 读取操作从文件开头开始,写入操作可以在文件的任意位置进行, 但要注意文件指针的位置 |