
本文字数:11871;估计阅读时间:30 分钟
作者: ClickHouse官方
本文在公众号【ClickHouseInc】首发

又到了月度版本更新的时间!
发布概要
ClickHouse 24.12 版本重磅发布,本次更新带来了16项全新功能🦃、16项性能优化⛸️、36个bug修复🏕️
本次版本新增了多项实用功能,包括改进 Enum 的可用性、支持 Iceberg REST 目录和模式演进、实现反序表排序、支持将 JSON 子列作为主键、自动优化 JOIN 的执行顺序等更多亮点功能!
新贡献者
我们热烈欢迎 24.12 版本中的所有新贡献者!ClickHouse 的成功离不开社区的共同努力。每次看到社区不断壮大,都会让我们倍感激励和鼓舞。
以下是本次版本的新贡献者名单:
Emmanuel Dias, Xavier Leune, Zawa_ll, Zaynulla, erickurbanov, jotosoares, zhangwanyun1, zwy991114, JiaQi
Enum 可用性改进
贡献者:ZhangLiStar
本次发布改进了 Enum 类型的可用性。我们将通过 Reddit 评论数据集示例来展示这些变化。首先,创建一个包含几个字段的表:
CREATE TABLE reddit
(
subreddit LowCardinality(String),
subreddit_type Enum(
'public' = 1, 'restricted' = 2, 'user' = 3,
'archived' = 4, 'gold_restricted' = 5, 'private' = 6
),
)
ENGINE = MergeTree
ORDER BY (subreddit);随后,我们可以插入数据,如下所示:
INSERT INTO reddit
SELECT subreddit, subreddit_type
FROM s3(
'https://clickhouse-public-datasets.s3.eu-central-1.amazonaws.com/reddit/original/RC_2017-12.xz',
'JSONEachRow'
);假如我们希望统计 subreddit_type 中包含字符 "e" 的帖子数量,可以使用 LIKE 运算符编写如下查询:
SELECT
subreddit_type,
count() AS c
FROM reddit
WHERE subreddit_type LIKE '%restricted%'
GROUP BY ALL
ORDER BY c DESC;在 24.12 版本之前运行该查询,会显示以下错误信息:
Received exception:
Code: 43. DB::Exception: Illegal type Enum8('public' = 1, 'restricted' = 2, 'user' = 3, 'archived' = 4, 'gold_restricted' = 5, 'private' = 6) of argument of function like: In scope SELECT subreddit, count() AS c FROM reddit WHERE subreddit_type LIKE '%e%' GROUP BY subreddit ORDER BY c DESC LIMIT 20. (ILLEGAL_TYPE_OF_ARGUMENT)而在 24.12 版本中运行相同的查询,则会返回如下结果:
┌─subreddit_type─┬──────c─┐
1. │ restricted │ 698263 │
2. │ user │ 39640 │
└────────────────┴────────┘此外,等号 (=) 和 IN 运算符现在也支持未知值。例如,以下查询会返回类型为 Foo 或 public 的所有记录:
SELECT count() AS c
FROM reddit
WHERE subreddit_type IN ('Foo', 'public')
GROUP BY ALL;在 24.12 版本之前运行这段查询时,会显示以下错误信息:
Received exception:
Code: 691. DB::Exception: Unknown element 'Foo' for enum: while converting 'Foo' to Enum8('public' = 1, 'restricted' = 2, 'user' = 3, 'archived' = 4, 'gold_restricted' = 5, 'private' = 6). (UNKNOWN_ELEMENT_OF_ENUM)而在 24.12 版本中运行该查询,则会返回如下结果:
┌────────c─┐
1. │ 85235907 │ -- 85.24 million
└──────────┘反向表排序
贡献者:Amos Bird
本次版本新增了一个 MergeTree 设置 allow_experimental_reverse_key,支持在 MergeTree 排序键中启用降序排序。以下是一个简单的示例:
ENGINE = MergeTree
ORDER BY (time DESC, key)
SETTINGS allow_experimental_reverse_key=1;这个表会按照 time 字段进行降序排列。
这种降序排序功能在时间序列分析中非常有用,尤其是处理 Top N 查询时效果显著。
JSON 子列作为表主键
贡献者:Pavel Kruglov
ClickHouse 引入了全新的 JSON 实现,可以将每个唯一的 JSON 路径存储为真正的列式数据:
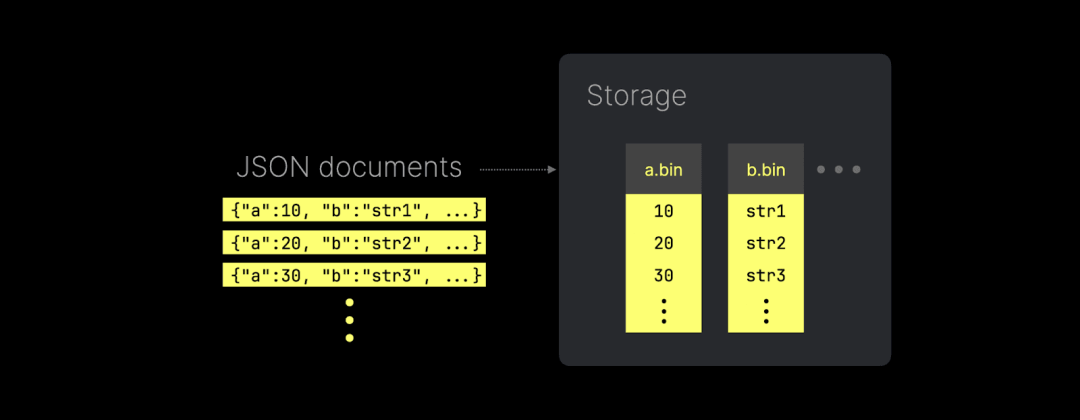
上图展示了 ClickHouse 如何将 JSON 键路径以原生子列的形式存储(并支持读取)。这种方式不仅提供了出色的数据压缩,还能保持与传统数据类型相同的查询性能。
在本次发布中,ClickHouse 现已支持将 JSON 子列用作表的主键列:
CREATE TABLE T
(
data JSON()
)
ORDER BY (data.a, data.b);这意味着,写入的 JSON 文档会根据用作主键的 JSON 子列,按分片顺序在磁盘上进行排序。此外,ClickHouse 会为这些主键列自动创建主索引文件,从而加速基于主键的过滤查询:
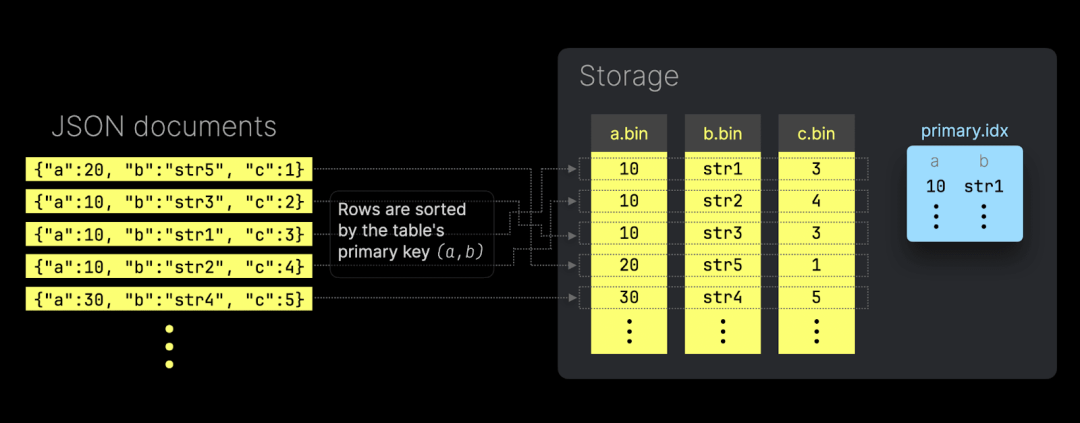
同时,当主键列按基数从低到高排序时,JSON 子列的 *.bin 数据文件也能实现最佳压缩效果。
以下是一个更具体的示例:
测试中我们使用了一台 AWS EC2 m6i.8xlarge 实例,配置为 32 个 vCPU 和 128 GiB 内存,并选用了 Bluesky 数据集。
我们将 1 亿条 Bluesky 事件(每个事件为一个 JSON 文档)加载到两个不同的 ClickHouse 表中。
第一个表没有使用任何 JSON 子列作为主键列:
CREATE TABLE bluesky_100m_raw
(
data JSON()
)
ORDER BY ();第二个表则使用了一些 JSON 子列作为主键列(还为部分列添加了类型提示,以避免查询中的类型转换):
CREATE TABLE bluesky_100m_primary_key
(
data JSON(
kind LowCardinality(String),
commit.operation LowCardinality(String),
commit.collection LowCardinality(String),
time_us UInt64
)
)
ORDER BY (
data.kind,
data.commit.operation,
data.commit.collection,
fromUnixTimestamp64Micro(data.time_us)
);这两个表都存储了完全相同的 1 亿条 JSON 文档。
接着,我们在没有主键的表上运行一个查询(查询内容为“人们何时在 Bluesky 上屏蔽他人”,改编自“人们何时使用 Bluesky?”的查询,您可以在 ClickHouse SQL playground 上试运行):
SELECT
toHour(fromUnixTimestamp64Micro(data.time_us::UInt64)) AS hour_of_day,
count() AS block_events
FROM bluesky_100m_raw
WHERE (data.kind = 'commit')
AND (data.commit.operation = 'create')
AND (data.commit.collection = 'app.bsky.graph.block')
GROUP BY hour_of_day
ORDER BY hour_of_day ASC; ┌─hour_of_day─┬─block_events─┐
1. │ 0 │ 89395 │
2. │ 1 │ 143542 │
3. │ 2 │ 154424 │
4. │ 3 │ 162894 │
5. │ 4 │ 65893 │
6. │ 5 │ 39556 │
7. │ 6 │ 34359 │
8. │ 7 │ 35230 │
9. │ 8 │ 30812 │
10. │ 9 │ 35620 │
11. │ 10 │ 31094 │
12. │ 16 │ 33359 │
13. │ 17 │ 65555 │
14. │ 18 │ 65135 │
15. │ 19 │ 65775 │
16. │ 20 │ 70096 │
17. │ 21 │ 65640 │
18. │ 22 │ 75840 │
19. │ 23 │ 143024 │
└─────────────┴──────────────┘
19 rows in set. Elapsed: 0.607 sec. Processed 100.00 million rows, 10.21 GB (164.83 million rows/s., 16.83 GB/s.)
Peak memory usage: 337.52 MiB.然后,我们在带有主键的表上运行相同的查询(需要注意,该查询对主键列的前缀字段进行了过滤):
SELECT
toHour(fromUnixTimestamp64Micro(data.time_us)) AS hour_of_day,
count() AS block_events
FROM bluesky_100m_primary_key
WHERE (data.kind = 'commit')
AND (data.commit.operation = 'create')
AND (data.commit.collection = 'app.bsky.graph.block')
GROUP BY hour_of_day
ORDER BY hour_of_day ASC; ┌─hour_of_day─┬─block_events─┐
1. │ 0 │ 89395 │
2. │ 1 │ 143542 │
3. │ 2 │ 154424 │
4. │ 3 │ 162894 │
5. │ 4 │ 65893 │
6. │ 5 │ 39556 │
7. │ 6 │ 34359 │
8. │ 7 │ 35230 │
9. │ 8 │ 30812 │
10. │ 9 │ 35620 │
11. │ 10 │ 31094 │
12. │ 16 │ 33359 │
13. │ 17 │ 65555 │
14. │ 18 │ 65135 │
15. │ 19 │ 65775 │
16. │ 20 │ 70096 │
17. │ 21 │ 65640 │
18. │ 22 │ 75840 │
19. │ 23 │ 143024 │
└─────────────┴──────────────┘
19 rows in set. Elapsed: 0.011 sec. Processed 1.47 million rows, 16.16 MB (129.69 million rows/s., 1.43 GB/s.)
Peak memory usage: 2.18 MiB.Boom!查询速度提升了 50 倍,内存使用减少了 150 倍。
Iceberg REST catalog 和模式演化支持
贡献者:Daniil Ivanik 和 Kseniia Sumarokova
在本次版本中,ClickHouse 新增了对 Apache Iceberg REST catalog 查询的支持。目前已支持 Unity 和 Polaris catalog。我们可以通过 Iceberg 表引擎创建表:
CREATE TABLE unity_demo
ENGINE = Iceberg('https://dbc-55555555-5555.cloud.databricks.com/api/2.1/unity-catalog/iceberg')
SETTINGS
catalog_type = 'rest',
catalog_credential = 'aaaaaaaa-bbbb-cccc-dddd-eeeeeeeeeeee:...',
warehouse = 'unity',
oauth_server_uri = 'https://dbc-55555555-5555.cloud.databricks.com/oidc/v1/token',
auth_scope = 'all-apis,sql';接着,可以查询 catalog 中底层表的数据:
SHOW TABLES FROM unity_demo;
SELECT * unity_demo."webinar.test";Iceberg 表引擎还支持模式演化功能,包括列的新增和移除、列名的修改,以及在原始数据类型之间的类型变更。
并行哈希 JOIN 默认启用
贡献者:Nikita Taranov
每次 ClickHouse 的新版本发布,都会对 JOIN 功能进行优化。这次的圣诞特别版本也不例外,带来了许多 JOIN 相关的增强功能!✨
在 24.11 版本的发布文章中,我们提到并行哈希 JOIN 已成为 ClickHouse 的默认 JOIN 策略。在这里,我们将通过具体示例展示这一改进带来的性能提升。
我们在一台 AWS EC2 m6i.8xlarge 实例上进行了测试,该实例配置了 32 个 vCPU 和 128 GiB 内存。
测试数据集选用的是 TPC-H 数据集,扩展因子为 100,表示所有表中的总数据量约为 100 GB。
我们按照官方文档的指引,创建并加载了 8 个表,这些表模拟了一个批发供应商的数据仓库。
首先,我们在使用 ClickHouse 之前默认的 JOIN 策略(哈希 JOIN)时,运行了 TPC-H 基准查询集中第 3 个查询:
SELECT
l_orderkey,
sum(l_extendedprice * (1 - l_discount)) AS revenue,
o_orderdate,
o_shippriority
FROM
customer,
orders,
lineitem
WHERE
c_mktsegment = 'BUILDING'
AND c_custkey = o_custkey
AND l_orderkey = o_orderkey
AND o_orderdate < DATE '1995-03-15'
AND l_shipdate > DATE '1995-03-15'
GROUP BY
l_orderkey,
o_orderdate,
o_shippriority
ORDER BY
revenue DESC,
o_orderdate
FORMAT Null
SETTINGS join_algorithm='hash';0 rows in set. Elapsed: 38.305 sec. Processed 765.04 million rows, 15.03 GB (19.97 million rows/s., 392.40 MB/s.)
Peak memory usage: 25.42 GiB.接下来,我们切换为 ClickHouse 新的默认 JOIN 策略(并行哈希 JOIN),运行相同的查询:
SELECT
l_orderkey,
sum(l_extendedprice * (1 - l_discount)) AS revenue,
o_orderdate,
o_shippriority
FROM
customer,
orders,
lineitem
WHERE
c_mktsegment = 'BUILDING'
AND c_custkey = o_custkey
AND l_orderkey = o_orderkey
AND o_orderdate < DATE '1995-03-15'
AND l_shipdate > DATE '1995-03-15'
GROUP BY
l_orderkey,
o_orderdate,
o_shippriority
ORDER BY
revenue DESC,
o_orderdate
FORMAT Null
SETTINGS join_algorithm='default';0 rows in set. Elapsed: 5.099 sec. Processed 765.04 million rows, 15.03 GB (150.04 million rows/s., 2.95 GB/s.)
Peak memory usage: 29.65 GiB.使用并行哈希 JOIN 后,查询速度提升了约 8 倍。
JOIN 自动重排序
贡献者:Vladimir Cherkasov
圣诞节版本新增了一项功能——JOIN 自动重排序。
首先,我们回顾一下 ClickHouse 的最快 JOIN 算法(例如其默认的并行哈希 JOIN)的工作原理。这些算法依赖于内存中的哈希表,分为两个主要阶段:
第一步,将 JOIN 查询右侧表的数据加载到哈希表中(构建阶段);
第二步,将左侧表的数据流式读取,并通过哈希表进行匹配(扫描阶段):
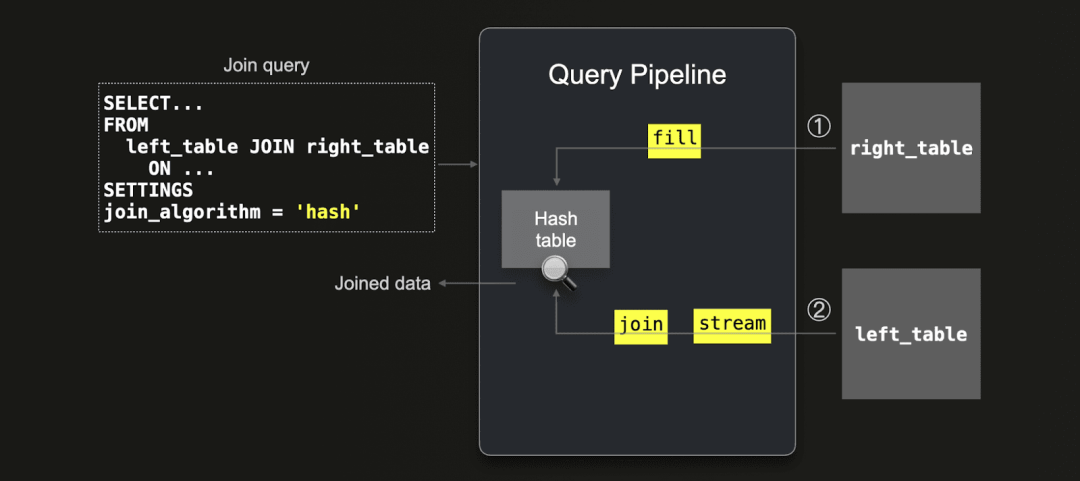
需要注意的是,由于 ClickHouse 会将右侧表的数据加载到内存中并创建哈希表,因此将较小的表放在 JOIN 的右侧可以更高效地使用内存,并且速度通常更快。
类似地,ClickHouse 的部分合并 JOIN(基于外部排序的 JOIN 算法)也有类似的构建和扫描阶段。例如,部分合并 JOIN 会先对右表进行排序,然后扫描左表。因此,将较小的表作为右表也能显著提高效率。
为了更灵活地选择构建表,ClickHouse 引入了新的设置项 query_plan_join_swap_table,可以根据需要调整构建表的选择逻辑。其取值如下:
-
auto(默认值):自动选择行数较少的表作为构建表,几乎适用于所有 JOIN 查询。
-
false:固定使用右表作为构建表。
-
true:固定使用左表作为构建表。
接下来,我们通过一个 TPC-H 查询示例演示 query_plan_join_swap_table 的 auto 模式(有关表的创建和加载方法以及测试硬件信息,请参见上一节)。该查询将连接 lineitem 表和 part 表。
首先,查看两个表的大小:
SELECT
table,
formatReadableQuantity(sum(rows)) AS rows,
formatReadableSize(sum(bytes_on_disk)) AS size_on_disk
FROM system.parts
WHERE active AND (table IN ['lineitem', 'part'])
GROUP BY table
ORDER BY table ASC; ┌─table────┬─rows───────────┬─size_on_disk─┐
1. │ lineitem │ 600.04 million │ 26.69 GiB │
2. │ part │ 20.00 million │ 896.47 MiB │
└──────────┴────────────────┴──────────────┘可以看到,lineitem 表的规模远大于 part 表。
下一条查询语句将 lineitem 表和 part 表进行连接,并且把规模大得多的lineitem表放在连接操作的右侧:
SELECT 100.00 * sum(
CASE
WHEN p_type LIKE 'PROMO%'
THEN l_extendedprice * (1 - l_discount)
ELSE 0 END) / sum(l_extendedprice * (1 - l_discount)) AS promo_revenue
FROM part, lineitem
WHERE l_partkey = p_partkey;接着运行一个查询,将规模更大的 lineitem 表放在 JOIN 的右侧,同时将 query_plan_join_swap_table 设置为 false(默认行为)。此时,ClickHouse 会将 lineitem 表的数据加载到内存中(并行加载到多个哈希表中,因为并行哈希 JOIN 是默认算法):
SELECT 100.00 * sum(
CASE
WHEN p_type LIKE 'PROMO%'
THEN l_extendedprice * (1 - l_discount)
ELSE 0 END) / sum(l_extendedprice * (1 - l_discount)) AS promo_revenue
FROM part, lineitem
WHERE l_partkey = p_partkey
SETTINGS query_plan_join_swap_table='false'; ┌──────promo_revenue─┐
1. │ 16.650141208349083 │
└────────────────────┘
1 row in set. Elapsed: 55.687 sec. Processed 620.04 million rows, 12.67 GB (11.13 million rows/s., 227.57 MB/s.)
Peak memory usage: 24.39 GiB.然后,将 query_plan_join_swap_table 设置为 auto 并运行相同的查询。此时,ClickHouse 会基于表大小的估算结果,选择将较小的 part 表作为构建表,先将其加载到哈希表中,再对 lineitem 表进行流式连接:
SELECT 100.00 * sum(
CASE
WHEN p_type LIKE 'PROMO%'
THEN l_extendedprice * (1 - l_discount)
ELSE 0 END) / sum(l_extendedprice * (1 - l_discount)) AS promo_revenue
FROM part, lineitem
WHERE l_partkey = p_partkey
SETTINGS query_plan_join_swap_table='auto'; ┌──────promo_revenue─┐
1. │ 16.650141208349083 │
└────────────────────┘
1 row in set. Elapsed: 9.447 sec. Processed 620.04 million rows, 12.67 GB (65.63 million rows/s., 1.34 GB/s.)
Peak memory usage: 4.72 GiB.结果显示,查询速度提升了 5 倍以上,内存使用量减少了 5 倍。
JOIN 优化:表达式提取
贡献者:János Benjamin Antal
对于包含多个 OR 条件链的 JOIN 查询,例如以下抽象案例:
JOIN ... ON (a=b AND x) OR (a=b AND y) OR (a=b AND z)…当 ClickHouse 使用基于哈希表的 JOIN 算法时,会为每个条件单独创建一个哈希表。
为了减少哈希表的数量并支持更高效的谓词下推(将过滤条件推到更接近数据源的位置以减少数据量),可以从上述 JOIN 查询的 ON 子句中提取公共表达式:
JOIN ...ON a=b AND (x OR y OR z)这一优化功能可以通过开启新设置 optimize_extract_common_expressions(设为 1)来实现。由于该功能仍处于实验阶段,默认值为 0(关闭)。
接下来,我们用一个 TPC-H 查询展示该设置的效果(有关表的创建、数据加载及测试硬件说明,请参考上一节)。
首先,我们运行以下包含多个 OR 条件链的 JOIN 查询,并将 optimize_extract_common_expressions 设置为 0(禁用优化):
SELECT
sum(l_extendedprice * (1 - l_discount)) AS revenue
FROM
lineitem, part
WHERE
(
p_partkey = l_partkey
AND p_brand = 'Brand#12'
AND p_container in ('SM CASE', 'SM BOX','SM PACK', 'SM PKG')
AND l_quantity >= 1 AND l_quantity <= 1 + 10
AND p_size BETWEEN 1 AND 5
AND l_shipmode in ('AIR', 'AIR REG')
AND l_shipinstruct = 'DELIVER IN PERSON'
)
OR
(
p_partkey = l_partkey
AND p_brand = 'Brand#23'
AND p_container in ('MED BAG', 'MED BOX', 'MED PKG', 'MED PACK')
AND l_quantity >= 10 AND l_quantity <= 10 + 10
AND p_size BETWEEN 1 AND 10
AND l_shipmode in ('AIR', 'AIR REG')
AND l_shipinstruct = 'DELIVER IN PERSON'
)
OR
(
p_partkey = l_partkey
AND p_brand = 'Brand#34'
AND p_container in ('LG CASE', 'LG BOX', 'LG PACK', 'LG PKG')
AND l_quantity >= 20 AND l_quantity <= 20 + 10
AND p_size BETWEEN 1 AND 15
AND l_shipmode in ('AIR', 'AIR REG')
AND l_shipinstruct = 'DELIVER IN PERSON'
)
SETTINGS optimize_extract_common_expressions = 0;在测试机器上,这个查询运行了 30 分钟,但仅完成了 3% 的进度……我们随即中止了查询,并将 optimize_extract_common_expressions 设置为 1(启用优化),再次运行相同的查询:
SELECT
sum(l_extendedprice * (1 - l_discount)) AS revenue
FROM
lineitem, part
WHERE
(
p_partkey = l_partkey
AND p_brand = 'Brand#12'
AND p_container in ('SM CASE', 'SM BOX','SM PACK', 'SM PKG')
AND l_quantity >= 1 AND l_quantity <= 1 + 10
AND p_size BETWEEN 1 AND 5
AND l_shipmode in ('AIR', 'AIR REG')
AND l_shipinstruct = 'DELIVER IN PERSON'
)
OR
(
p_partkey = l_partkey
AND p_brand = 'Brand#23'
AND p_container in ('MED BAG', 'MED BOX', 'MED PKG', 'MED PACK')
AND l_quantity >= 10 AND l_quantity <= 10 + 10
AND p_size BETWEEN 1 AND 10
AND l_shipmode in ('AIR', 'AIR REG')
AND l_shipinstruct = 'DELIVER IN PERSON'
)
OR
(
p_partkey = l_partkey
AND p_brand = 'Brand#34'
AND p_container in ('LG CASE', 'LG BOX', 'LG PACK', 'LG PKG')
AND l_quantity >= 20 AND l_quantity <= 20 + 10
AND p_size BETWEEN 1 AND 15
AND l_shipmode in ('AIR', 'AIR REG')
AND l_shipinstruct = 'DELIVER IN PERSON'
)
SETTINGS optimize_extract_common_expressions = 1; ┌───────revenue─┐
1. │ 298937728.882 │ -- 298.94 million
└───────────────┘
1 row in set. Elapsed: 3.021 sec. Processed 620.04 million rows, 38.21 GB (205.24 million rows/s., 12.65 GB/s.)
Peak memory usage: 2.79 GiB.这次查询仅用 3 秒便完成了执行并返回结果,性能提升极其显著。
非等值 JOIN:默认支持
贡献者:Vladimir Cherkasov
自 24.05 版本以来,ClickHouse 已以实验功能形式支持在 JOIN 的 ON 子句中使用非等值条件:
-- Equi join
SELECT t1.*, t2.* FROM t1 JOIN t2 ON t1.key = t2.key;
-- Non-equi joins
SELECT t1.*, t2.* FROM t1 JOIN t2 ON t1.key != t2.key;
SELECT t1.*, t2.* FROM t1 JOIN t2 ON t1.key > t2.key
在当前版本中,这项功能已全面启用,并默认支持。
敬请期待今年后续版本更新,我们将继续带来更多令人兴奋的 JOIN 改进!
征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出&图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:[email protected]
