一、操作系统中堆和栈的区别
堆内存申请,释放,操作,特点:
1. 堆内存申请环境:堆内存需要程序员在程序中申请 ,动态分配,申请的大小有程序决定。
2. 堆内存申请方法:C语言中的malloc() 函数 , c++ 中的new()函数。堆内存进行申请时候可能会申请失败,申请成功与失败与计算机性能,当前运行环境等有关。
3. 堆内存释放:申请过后的堆内存不能由系统自动进行释放,C语言中采用 free() 函数,c++中采用 delete() 函数进行释放内存。
4. 堆内存操作:申请过后的内存,会返回指向堆内存的指针,后续对于内存的读写等操作需要通过此指针进行。
5. 堆内存特点:地址由低向高生长。 堆内存非线性,呈现无序状态。因此用到了链表。
栈内存申请,释放,操作,特点:
1. 栈内存的申请是在程序中定义好的,比如数组,包括栈的大小,包含的变量(存储局部变量,数组,栈帧,函数返回地址等)
2. 栈内存的释放是有程序自身决定的不用掉用函数,当程序退出时,栈内存会自动销毁,维持栈平衡,否则就会发生内存访问错误。
3. 栈内存的操作 push pop 只有这两种操作。
4. 栈内存的特点:由高地址向低地址生长,呈现线性规划。参考OD中栈缓冲区向上增长,即向低地址增长。
二、堆-heap
1、动态内存分配的方法
动态内存分配(Dynamic memory allocation)又称为堆内存分配,是指计算机程序在运行期中分配使用内存。它可以当成是一种分配有限内存资源所有权的方法。 动态分配的内存在被程序员明确释放或被垃圾回收之前一直有效。与静态内存分配的区别在于没有一个固定的生存期。这样被分配的对象称之为有一个“动态生存期”。
2、堆内存中数据结构——堆块、堆表
① 堆块
出于对性能的考虑,堆区的内存按照不同大小的内存块被组织起来,以字节为单位。
堆块的结构:堆块分为块首和块身。
块首的结构:块首包含当前堆块的主要信息例如:堆块的大小,空闲态还是占用态等状态表信息。
对块首的识别:当连续进行内存申请时,如果返回的指针地址是有差距的,两个连续的指针之间的差距就是第二个块身的块首。
块身的结构:块身就是本堆块存放数据的位置,即最终分配给用户的数据区。
块身位置:块身位于块首的后面紧挨着。
对块身的操作: 申请堆区成功后返回的指针直接指向的块身的首地址,对块身的操作也就是对堆区的操作
② 堆表
堆表的意义:堆表用来索引堆块。堆表中包含所有堆块的大小,位置,状态等信息。堆表的数据结构决定了堆区的组织方式,是快速检索空闲块,保证堆分配效率的关键。堆表进行设计的时候会考虑二叉树平衡策略,快速查找策略等。现代的操作系统中堆表的数据结构还不止一种。像一个字典一样用来查找堆块,并且在 windows 中索引的是所有空闲态的堆块。
这里需要严格区分一点:占用态的堆块使用自己的程序索引,堆表只索引所有空闲态的堆块。重要的堆表包含两类:空闲双向链表(简称空表),快速单向链表(块表)。下面逐一对其要点进行分析。
——空表(空闲双向链表)
1. 堆区空闲堆块的块首都包含一对指针,这对指针用于将空闲的堆块组织成双向链表,按照大小的不同,总共分为128条。
2. 堆区一开始的堆表区中,有一个128项的指针数组,下标从0~127,即 freelist[0]~freelist[127],叫做空表数组索引,该数组的每一项都包含两个指针,用来标示一条空表。
3. 空表的结构如下:
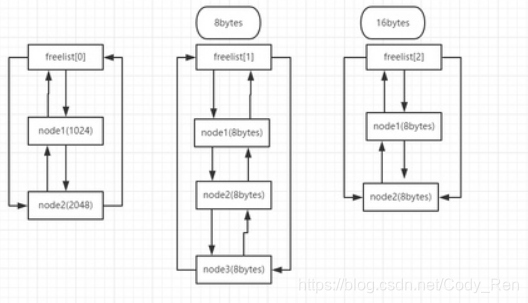
freelist[0] 被称为零号空表,并且是节点从第一个 node1(1024bytes) 逐渐增或减 1024bytes 的整数倍,第二个及以后的节点的大小肯定是 >=1024 bytes。注意从第二个链表 freelist[1] 开始,此空闲链表中每个节点是 8bytes,freelist[2] 中每个节点的大小变成了 16bytes,上图中第三列 freelist[2] 中节点大小标记错误,注意一下。即从第二个空表 freeslist[1] 开始:节点的字节数 = 空表的下标 * 8 。此处谨记零号空闲链表,因为在堆分配的时候很重要。空表的特点:可以发生堆块合并,并且分配的效率低。
——块表(快速单向链表)
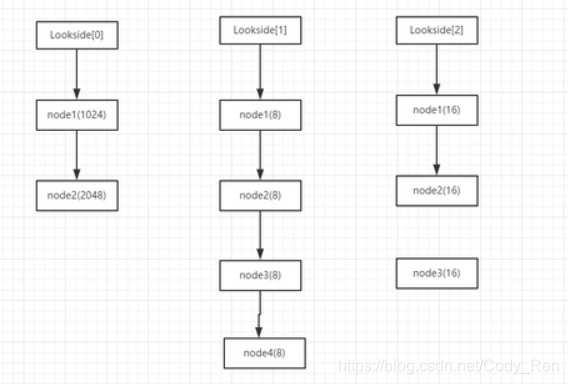
1. 快速单向链表也就是块表是 windows 加速堆块分配的一种链表
2. 块表的特点:永远处于占用态意味着不会发生合并,块表包含128项,每项是一个单向链表,每个链表最多只包含4个节点,链表一共128条,下标从0~127,和空表一样,组织结构跟空表很类似,块表总是被初始化为空。
3. 结构如下图,应该是 blocklist:
3、堆分配策略——堆块分配、堆块释放、堆块合并
堆块分配——块表分配、零号空表分配、空表分配
① 块表的分配:寻找到精确匹配大小的空闲块,将此空闲块标注为占用状态,从块表中卸下,返回指向堆块块身的指针供程序使用。
② 零号空表的分配:零号空表中所有的空闲块是按照从小到大的顺序排列的,因此在分配的时候先从最后的堆块进行分配,看能否满足要求,如果能满足要求,则正向寻找最小能满足要求的堆块进行分配。
③ 空表分配:普通空表进行分配时候,寻找最优解决方案,若不满满足最优解决方案,则采用次优解决方案进行分配。空表分配中存在找零钱的现象,即:当无法找到最优解决方案,次优解决方案的时候,就会从大的尾块中割下一小块能够满足要求的堆块,最后把尾块块首的状态信息进行修改即可。
堆块分配的特点:块表中只存在精确分配,不存在找零钱现象。空表中存在找零钱现象(不考虑堆缓存,碎片化等情况)
堆块释放
堆表的释放包括将占用态改为空闲态,释放的堆块链入相应的堆表,所有释放的堆块都链入相应的表尾,分配的时候先从表尾进行分配。块表最多只包含四个节点。
堆块合并
经过反反复复的堆块的分配与释放,堆区会出新很多凌乱的碎片,这时候就需要用到堆块的合并,堆块的合并包括几个动作:将堆块从空表中卸下,合并堆块,修改合并后的块首,链接入新的链表(合并的时候还有一种操作叫内存紧缩)。合并的时候只合并相邻的堆块。
三、堆的调试方法
调试堆与调试栈的方法不同,调试栈可以直接加载或者 attach 程序,但调试堆的时候也这样子的话,堆管理策略就会采用调试状态下的堆管理策略,使用调试状态下的堆管理函数。
正常堆和调试堆的区别:
1. 调试堆只采用空表分配,不采用块表分配
2. 所有的堆块末尾都加上十六个字节的数据用来防止程序溢出(仅仅是用来防止程序溢出,而不是堆溢出),其中这十六个字节包括:8个 0xAB + 8个 0x00
3. 块首的标志位不同,调试状态下的堆和正常堆的区别类似 debug 下的PE文件和 release 下的PE文件,做堆溢出实验的时候,调试器中可以正常运行 shellcode,单独运行却不行,这很可能就是调试堆与正常堆的差异造成的。
为避免采用调试状态下的堆,直接在程序中嵌入 int3 断点,然后调用实时调试器即可, 源码:
#include <windows.h>
main()
{
HLOCAL h1,h2,h3,h4,h5,h6;
HANDLE hp;
hp = HeapCreate(0,0x1000,0x10000);
__asm int 3
h1 = HeapAlloc(hp,HEAP_ZERO_MEMORY,3);
h2 = HeapAlloc(hp,HEAP_ZERO_MEMORY,5);
h3 = HeapAlloc(hp,HEAP_ZERO_MEMORY,6);
h4 = HeapAlloc(hp,HEAP_ZERO_MEMORY,8);
h5 = HeapAlloc(hp,HEAP_ZERO_MEMORY,19);
h6 = HeapAlloc(hp,HEAP_ZERO_MEMORY,24);
HeapFree(hp,0,h1); //free to freelist[2]
HeapFree(hp,0,h3); //free to freelist[2]
HeapFree(hp,0,h5); //free to freelist[4]
HeapFree(hp,0,h4); //coalese h3,h4,h5,link the large block to freelist[8]
return 0;
}待续。。
参考:
https://www.jianshu.com/p/c082b014fdf9
https://www.jianshu.com/p/59cc7c8a44d3
https://www.kanxue.com/chm.htm?id=10532&pid=node1000986