I. 前言
在前面的两篇文章PyTorch搭建LSTM实现时间序列预测(负荷预测)和PyTorch搭建LSTM实现多变量时间序列预测(负荷预测)中,我们利用LSTM分别实现了单变量单步长时间序列预测和多变量单步长时间序列预测。
本篇文章主要考虑用PyTorch搭建LSTM实现多变量多步长时间序列预测。
系列文章:
- 深入理解PyTorch中LSTM的输入和输出(从input输入到Linear输出)
- PyTorch搭建LSTM实现时间序列预测(负荷预测)
- PyTorch中利用LSTMCell搭建多层LSTM实现时间序列预测
- PyTorch搭建LSTM实现多变量时间序列预测(负荷预测)
- PyTorch搭建双向LSTM实现时间序列预测(负荷预测)
- PyTorch搭建LSTM实现多变量多步长时间序列预测(一):直接多输出
- PyTorch搭建LSTM实现多变量多步长时间序列预测(二):单步滚动预测
- PyTorch搭建LSTM实现多变量多步长时间序列预测(三):多模型单步预测
- PyTorch搭建LSTM实现多变量多步长时间序列预测(四):多模型滚动预测
- PyTorch搭建LSTM实现多变量多步长时间序列预测(五):seq2seq
- PyTorch中实现LSTM多步长时间序列预测的几种方法总结(负荷预测)
- PyTorch-LSTM时间序列预测中如何预测真正的未来值
- PyTorch搭建LSTM实现多变量输入多变量输出时间序列预测(多任务学习)
- PyTorch搭建ANN实现时间序列预测(风速预测)
- PyTorch搭建CNN实现时间序列预测(风速预测)
- PyTorch搭建CNN-LSTM混合模型实现多变量多步长时间序列预测(负荷预测)
- PyTorch搭建Transformer实现多变量多步长时间序列预测(负荷预测)
- PyTorch时间序列预测系列文章总结(代码使用方法)
- TensorFlow搭建LSTM实现时间序列预测(负荷预测)
- TensorFlow搭建LSTM实现多变量时间序列预测(负荷预测)
- TensorFlow搭建双向LSTM实现时间序列预测(负荷预测)
- TensorFlow搭建LSTM实现多变量多步长时间序列预测(一):直接多输出
- TensorFlow搭建LSTM实现多变量多步长时间序列预测(二):单步滚动预测
- TensorFlow搭建LSTM实现多变量多步长时间序列预测(三):多模型单步预测
- TensorFlow搭建LSTM实现多变量多步长时间序列预测(四):多模型滚动预测
- TensorFlow搭建LSTM实现多变量多步长时间序列预测(五):seq2seq
- TensorFlow搭建LSTM实现多变量输入多变量输出时间序列预测(多任务学习)
- TensorFlow搭建ANN实现时间序列预测(风速预测)
- TensorFlow搭建CNN实现时间序列预测(风速预测)
- TensorFlow搭建CNN-LSTM混合模型实现多变量多步长时间序列预测(负荷预测)
- PyG搭建图神经网络实现多变量输入多变量输出时间序列预测
- PyTorch搭建GNN-LSTM和LSTM-GNN模型实现多变量输入多变量输出时间序列预测
- PyG Temporal搭建STGCN实现多变量输入多变量输出时间序列预测
- 时序预测中Attention机制是否真的有效?盘点LSTM/RNN中24种Attention机制+效果对比
- 详解Transformer在时序预测中的Encoder和Decoder过程:以负荷预测为例
- (PyTorch)TCN和RNN/LSTM/GRU结合实现时间序列预测
- PyTorch搭建Informer实现长序列时间序列预测
- PyTorch搭建Autoformer实现长序列时间序列预测
- PyTorch搭建GNN(GCN、GraphSAGE和GAT)实现多节点、单节点内多变量输入多变量输出时空预测
II. 数据处理
数据集为某个地区某段时间内的电力负荷数据,除了负荷以外,还包括温度、湿度等信息。
本文中,我们根据前24个时刻的负荷以及该时刻的环境变量来预测接下来4个时刻的负荷(步长可调)。
任意输出其中一条数据:
(tensor([[0.5830, 1.0000, 0.9091, 0.6957, 0.8333, 0.4884, 0.5122],
[0.6215, 1.0000, 0.9091, 0.7391, 0.8333, 0.4884, 0.5122],
[0.5954, 1.0000, 0.9091, 0.7826, 0.8333, 0.4884, 0.5122],
[0.5391, 1.0000, 0.9091, 0.8261, 0.8333, 0.4884, 0.5122],
[0.5351, 1.0000, 0.9091, 0.8696, 0.8333, 0.4884, 0.5122],
[0.5169, 1.0000, 0.9091, 0.9130, 0.8333, 0.4884, 0.5122],
[0.4694, 1.0000, 0.9091, 0.9565, 0.8333, 0.4884, 0.5122],
[0.4489, 1.0000, 0.9091, 1.0000, 0.8333, 0.4884, 0.5122],
[0.4885, 1.0000, 0.9091, 0.0000, 1.0000, 0.3256, 0.3902],
[0.4612, 1.0000, 0.9091, 0.0435, 1.0000, 0.3256, 0.3902],
[0.4229, 1.0000, 0.9091, 0.0870, 1.0000, 0.3256, 0.3902],
[0.4173, 1.0000, 0.9091, 0.1304, 1.0000, 0.3256, 0.3902],
[0.4503, 1.0000, 0.9091, 0.1739, 1.0000, 0.3256, 0.3902],
[0.4502, 1.0000, 0.9091, 0.2174, 1.0000, 0.3256, 0.3902],
[0.5426, 1.0000, 0.9091, 0.2609, 1.0000, 0.3256, 0.3902],
[0.5579, 1.0000, 0.9091, 0.3043, 1.0000, 0.3256, 0.3902],
[0.6035, 1.0000, 0.9091, 0.3478, 1.0000, 0.3256, 0.3902],
[0.6540, 1.0000, 0.9091, 0.3913, 1.0000, 0.3256, 0.3902],
[0.6181, 1.0000, 0.9091, 0.4348, 1.0000, 0.3256, 0.3902],
[0.6334, 1.0000, 0.9091, 0.4783, 1.0000, 0.3256, 0.3902],
[0.6297, 1.0000, 0.9091, 0.5217, 1.0000, 0.3256, 0.3902],
[0.5610, 1.0000, 0.9091, 0.5652, 1.0000, 0.3256, 0.3902],
[0.5957, 1.0000, 0.9091, 0.6087, 1.0000, 0.3256, 0.3902],
[0.6427, 1.0000, 0.9091, 0.6522, 1.0000, 0.3256, 0.3902]]), tensor([0.6360, 0.6996, 0.6889, 0.6434]))
数据格式为(X, Y)。其中X一共24行,表示前24个时刻的负荷值和该时刻的环境变量。Y一共四个值,表示需要预测的四个负荷值。需要注意的是,此时input_size=7,output_size=4。
III. LSTM模型
这里采用了深入理解PyTorch中LSTM的输入和输出(从input输入到Linear输出)中的模型:
class LSTM(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, output_size, batch_size):
super().__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.num_layers = num_layers
self.output_size = output_size
self.num_directions = 1 # 单向LSTM
self.batch_size = batch_size
self.lstm = nn.LSTM(self.input_size, self.hidden_size, self.num_layers, batch_first=True)
self.linear = nn.Linear(self.hidden_size, self.output_size)
def forward(self, input_seq):
batch_size, seq_len = input_seq.shape[0], input_seq.shape[1]
h_0 = torch.randn(self.num_directions * self.num_layers, self.batch_size, self.hidden_size).to(device)
c_0 = torch.randn(self.num_directions * self.num_layers, self.batch_size, self.hidden_size).to(device)
# output(batch_size, seq_len, num_directions * hidden_size)
output, _ = self.lstm(input_seq, (h_0, c_0)) # output(5, 30, 64)
pred = self.linear(output) # (5, 30, 1)
pred = pred[:, -1, :] # (5, 1)
return pred
IV. 训练和预测
训练和预测代码和前几篇都差不多,只是需要注意input_size和output_size的大小。
鉴于很多人一直在问代码,那这里重新贴一下好了,训练代码如下:
def train(args, Dtr, Val, path):
if args.bidirectional:
model = BiLSTM(args).to(device)
else:
model = LSTM(args).to(device)
loss_function = nn.MSELoss().to(device)
if args.optimizer == 'adam':
optimizer = torch.optim.Adam(model.parameters(), lr=args.lr,
weight_decay=args.weight_decay)
else:
optimizer = torch.optim.SGD(model.parameters(), lr=args.lr,
momentum=0.9, weight_decay=args.weight_decay)
scheduler = StepLR(optimizer, step_size=args.step_size, gamma=args.gamma)
# training
min_epochs = 10
best_model = None
min_val_loss = 5
for epoch in tqdm(range(args.epochs)):
train_loss = []
for (seq, label) in Dtr:
seq = seq.to(device)
label = label.to(device)
y_pred = model(seq)
loss = loss_function(y_pred, label)
train_loss.append(loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
scheduler.step()
# validation
val_loss = get_val_loss(args, model, Val)
if epoch > min_epochs and val_loss < min_val_loss:
min_val_loss = val_loss
best_model = copy.deepcopy(model)
print('epoch {:03d} train_loss {:.8f} val_loss {:.8f}'.format(epoch, np.mean(train_loss), val_loss))
model.train()
state = {'model': best_model.state_dict()}
torch.save(state, path)
验证集上损失计算:
def get_val_loss(args, model, Val):
model.eval()
loss_function = nn.MSELoss().to(args.device)
val_loss = []
for (seq, label) in Val:
with torch.no_grad():
seq = seq.to(args.device)
label = label.to(args.device)
y_pred = model(seq)
loss = loss_function(y_pred, label)
val_loss.append(loss.item())
return np.mean(val_loss)
测试:
def test(args, Dte, path, m, n):
pred = []
y = []
print('loading models...')
if args.bidirectional:
model = BiLSTM(args).to(device)
else:
model = LSTM(args).to(device)
model.load_state_dict(torch.load(path)['model'])
model.eval()
print('predicting...')
for (seq, target) in tqdm(Dte):
target = list(chain.from_iterable(target.data.tolist()))
y.extend(target)
seq = seq.to(device)
with torch.no_grad():
y_pred = model(seq)
y_pred = list(chain.from_iterable(y_pred.data.tolist()))
pred.extend(y_pred)
y, pred = np.array(y), np.array(pred)
y = (m - n) * y + n
pred = (m - n) * pred + n
# print(pred[-100:])
print('mae:', get_mae(y, pred))
print('mse', get_mse(y, pred))
print('rmse:', get_rmse(y, pred))
print('mape:', get_mape(y, pred))
print('r2:', get_r2(y, pred))
# plot
plot(y, pred)
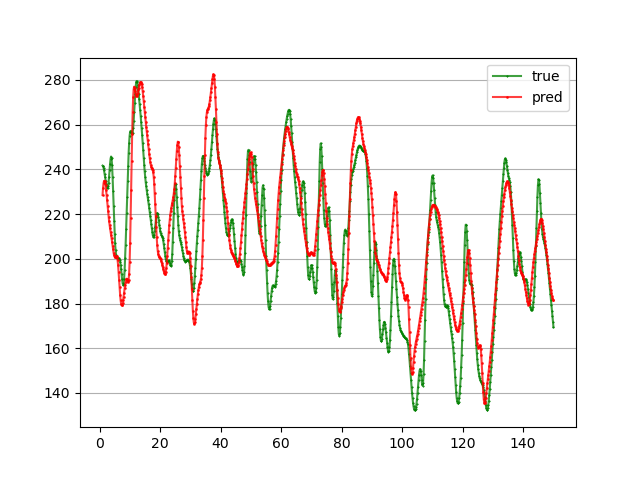
训练了50轮,预测接下来4个时刻的负荷值,MAPE为7.62%:
V. 源码及数据
后面将陆续公开~