文章目录
前言
这期是在上期YOLOv10的基础上,使用YOLOv11结合Transformer复现了论文《Cross-Modality Fusion Transformer for Multispectral Object Detection》,v11算是魔改版的v8吧,检测头加了dw卷积,添加了一些新的模块,个人认为亮点不算很多,最终实验结果在LLVIP数据集的MAP为95.4,下期预计会出带界面版的多模态代码,界面预计会支持图像、视频、热力图等功能,大家有啥想法欢迎在评论区留言~
往期博客地址:
地址1:多模态YOLOv8 融合可见光+红外光(RGB+IR)双输入【附代码】
地址2:结合Transformer的YOLOv8多模态 融合可见光+红外光(RGB+IR)双输入 完美复现论文【附代码】
地址3:YOLOv10多模态 结合Transformer与NMS-Free 融合可见光+红外光(RGB+IR)双输入【附代码】
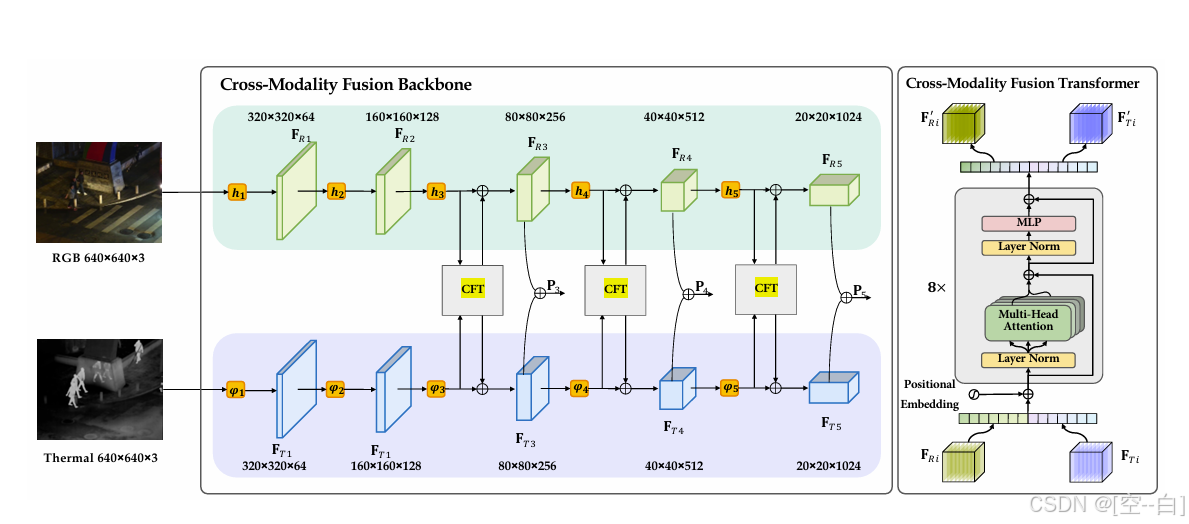
双模态模型结构图:
视频效果
YOLOv11多模态 结合CFT模块 融合可见光+红外光双输入
文章概述
本文将详细讲解结合Transformer的YOLOv11多模态训练、验证和推理流程。内容涵盖数据结构的定义、代码运行方法以及关键参数的含义
必要环境
-
配置v11环境 可参考往期博客
地址:搭建YOLOv11环境 训练+推理+模型评估+简单的小界面
-
实现过程中参考的论文
地址:Cross-Modality Fusion Transformer for Multispectral Object Detection
一、模型训练
1、 定义数据
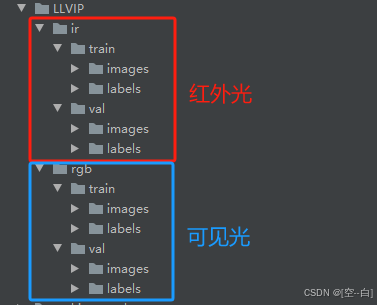
1.1、数据集结构
如下图所示,分别定义红外光与可见光的数据,images文件夹下存放图像 labels图像存放标注结果(.txt)
上图训练案例下载链接:
https://pan.baidu.com/s/1D6CAY1dDfEfa73ezgc_gQg?pwd=pd4y
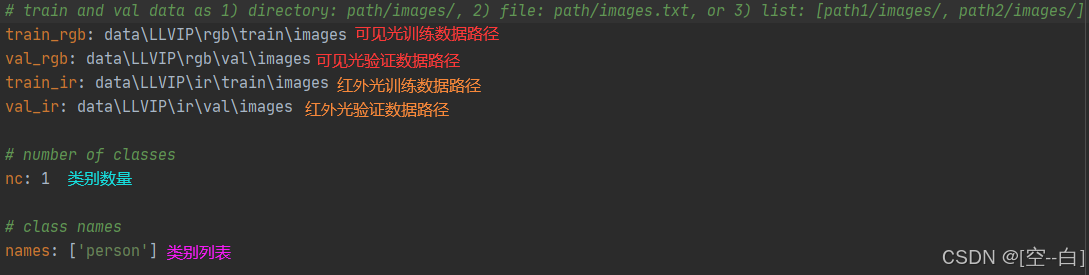
1.2、定义data.yaml
根据1.1定义的结构 依次填写路径
2、 运行方法
python train.py --weights yolo11n.pt --cfg models/yolov11n-transformerx3.yaml --data data.yaml --epoch 200 --batch-size 64 --workers 8
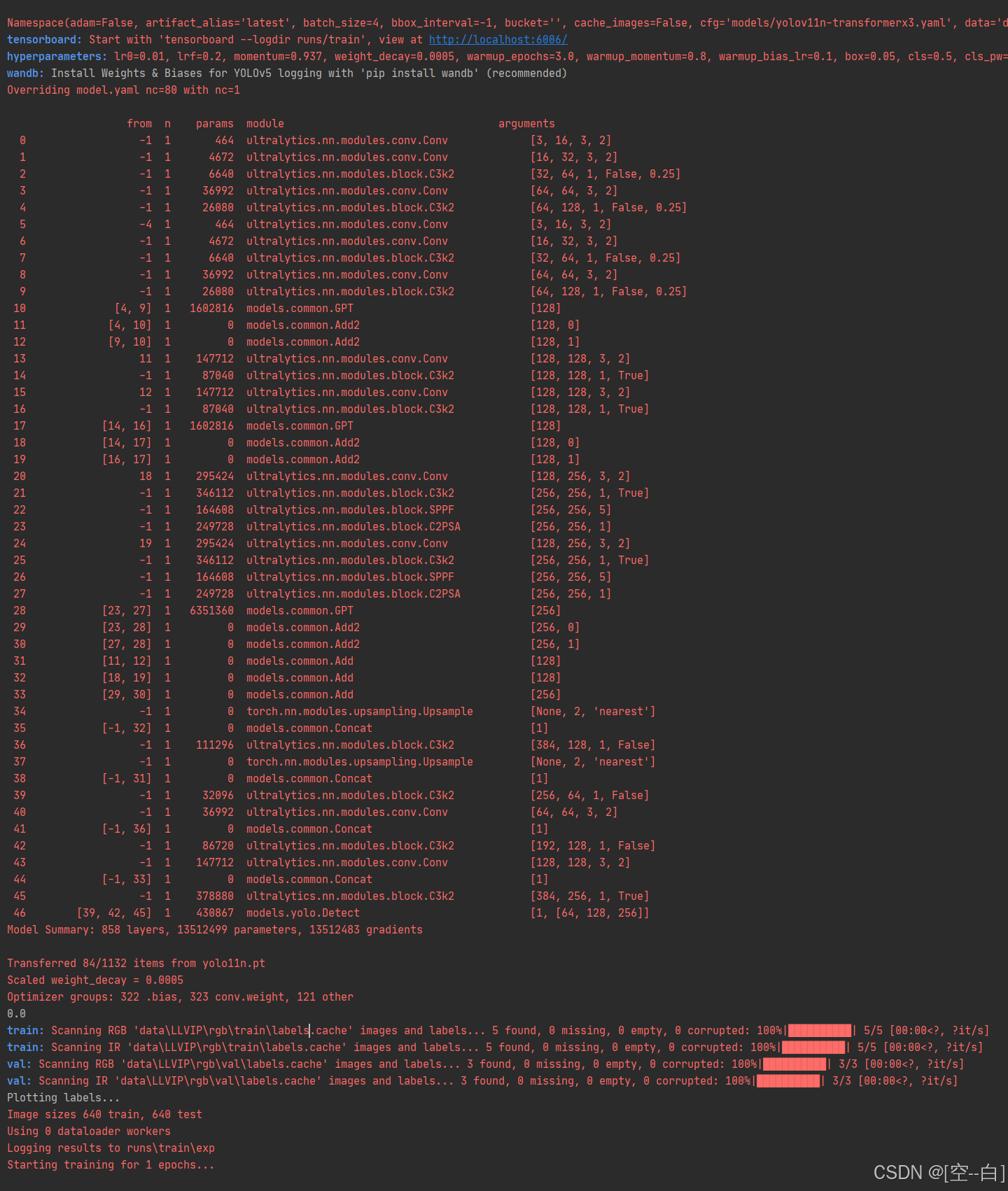
运行效果
正常训练时会打印模型在yaml文件中定义的网络结构以及rgb和ir的数据
关键参数详解:
- –weights: 填写预训练模型路径,不使用预训练模型时这里为空
- –cfg:填写网络结构的yaml文件路径,此处为models/yolov8n.yaml
- –data: 填写定义数据集的yaml文件路径
- –epoch: 模型每轮训练的批次,增加轮数有助于提升模型性能,但同时也会增加训练时间
- –batch-size: 模型每轮训练的批次,可根据实际显存大小进行调整
- –workers: 设置数据加载进程数 linux系统下一般设置为8或16,windows系统设置为0
二、模型验证
训练结束后会在最后一轮输出模型的完整指标,但如果想要单独评估一下模型,可以通过如下命令来进行
运行方法
python test.py --weights runs\train\exp\weights\best.pt --data data.yaml --batch-size 128
运行效果
运行成功后会输出map0.5、map0.75、map0.5:0.95、P、R以及每个类别的AP等指标

关键参数详解:
- –weights: 填写想要评估模型的路径
- –batch-size: 用于评估的批次,一般是训练时的2倍,可根据实际显存大小进行调整
三、模型推理
3.1. 推理图像
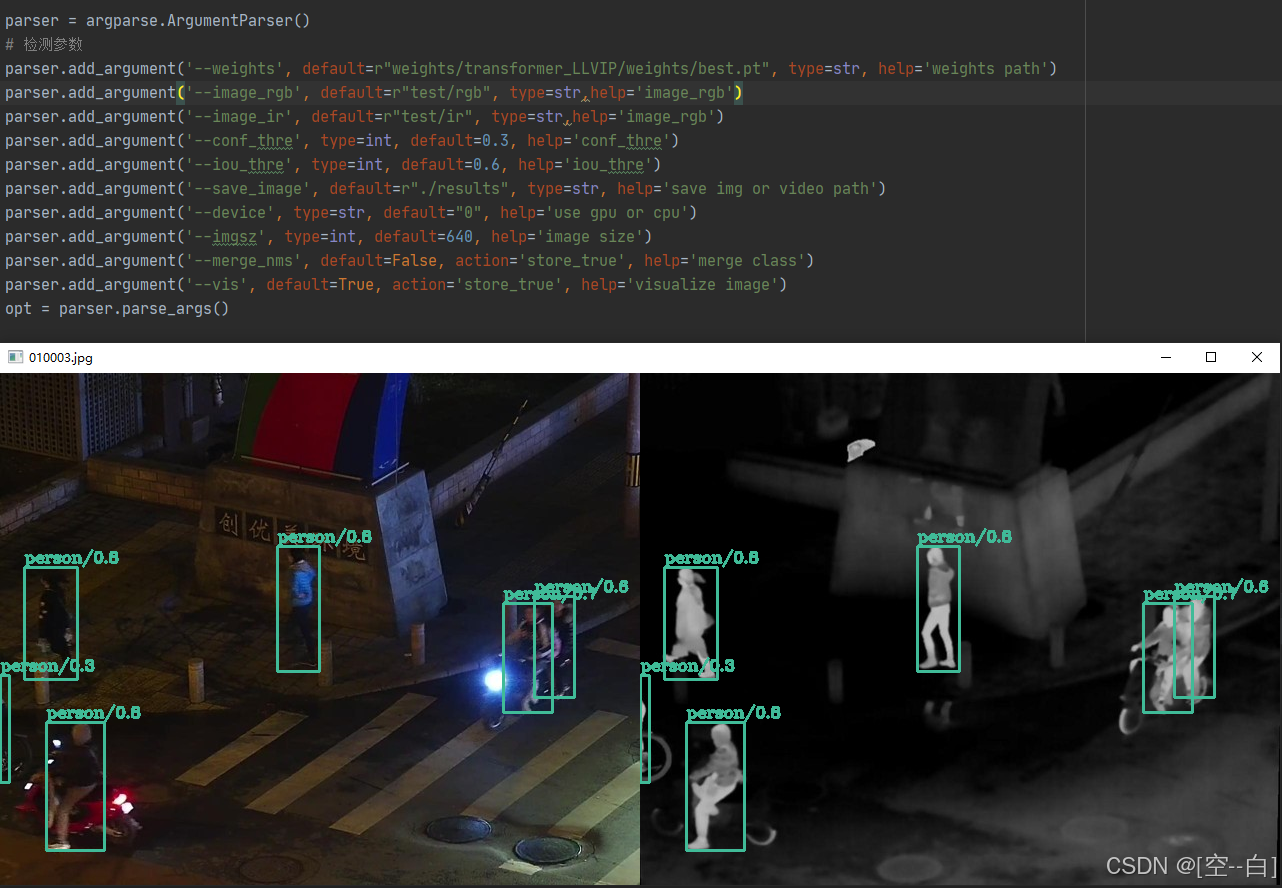
1. 参数定义
parser = argparse.ArgumentParser()
# 检测参数
parser.add_argument('--weights', default=r"weights\transformer_LLVIP\weights\best.pt", type=str, help='Path to model weights file.')
parser.add_argument('--image_rgb', default=r"test\rgb", type=str, help='Directory for RGB images.')
parser.add_argument('--image_ir', default=r"test\ir", type=str, help='Directory for IR images.')
parser.add_argument('--conf_thre', type=int, default=0.3, help='Confidence threshold for detections.')
parser.add_argument('--save_image', default=r"./results", type=str, help='Directory to save result images.')
parser.add_argument('--vis', default=True, action='store_true', help='Visualize images with detections.')
parser.add_argument('--device', type=str, default="0", help='Device: "0" for GPU, "cpu" for CPU.')
parser.add_argument('--imgsz', type=int, default=640, help='Input image size for inference.')
opt = parser.parse_args()
关键参数详解:
- –weights: 指定用于推理的模型路径,可通过更改此路径来加载不同的权重文件
- –image_rgb: 指定包含可见光图像的路径
- –image_ir: 指定包含红外光图像的路径
- –save_image: 指定推理图像保存的路径
- –vis: 可选的标志,启用后将实时显示推理的图像,默认为True
- –device: 指定用于处理的设备,默认是“0”表示使用cuda:0,如果设置为“cpu”,则使用CPU处理
2. 运行方法
改好上述参数后直接运行detect_image.py即可
python detect_image.py
运行效果
3.2. 推理视频
1. 参数定义
parser = argparse.ArgumentParser()
# 检测参数
parser.add_argument('--weights', default=r"weights\transformer_LLVIP\weights\best.pt", type=str,
help='Path to model weights file.')
parser.add_argument('--video_rgb', default=r"RGB.mp4", type=str, help='Path to RGB video file.')
parser.add_argument('--video_ir', default=r"IR.mp4", type=str, help='Path to IR video file.')
parser.add_argument('--conf_thre', type=int, default=0.4, help='Confidence threshold for detections.')
parser.add_argument('--save_video', default=r"./results", type=str, help='Directory to save result videos.')
parser.add_argument('--vis', default=True, action='store_true', help='Visualize frames with detections.')
parser.add_argument('--device', type=str, default="0", help='Device: "0" for GPU, "cpu" for CPU.')
parser.add_argument('--imgsz', type=int, default=640, help='Input image size for inference.')
opt = parser.parse_args()
关键参数详解:
- –weights: 指定用于推理的模型路径,可通过更改此路径来加载不同的权重文件
- –video_rgb: 指定可见光视频的路径
- –video_ir: 指定红外光视频的路径
- –save_image: 指定推理图像保存的路径
- –vis: 可选的标志,启用后将实时显示推理的图像,默认为True
- –device: 指定用于处理的设备,默认是“0”表示使用cuda:0,如果设置为“cpu”,则使用CPU处理
2. 运行方法
改好上述参数后直接运行detect_video.py即可
python detect_video.py
运行效果

四、效果展示
白天


夜间


总结
本期博客就到这里啦,喜欢的小伙伴们可以点点关注,感谢!