您或许知道,作者后续分享网络安全的文章会越来越少。但如果您想学习人工智能和安全结合的应用,您就有福利了,作者将重新打造一个《当人工智能遇上安全》系列博客,详细介绍人工智能与安全相关的论文、实践,并分享各种案例,涉及恶意代码检测、恶意请求识别、入侵检测、对抗样本等等。只想更好地帮助初学者,更加成体系的分享新知识。该系列文章会更加聚焦,更加学术,更加深入,也是作者的慢慢成长史。换专业确实挺难的,系统安全也是块硬骨头,但我也试试,看看自己未来四年究竟能将它学到什么程度,漫漫长征路,偏向虎山行。享受过程,一起加油~
前文详细介绍如何学习提取的API序列特征,并构建深度学习算法实现恶意家族分类,这也是安全领域典型的任务或工作。这篇文章将讲解如何实现威胁情报实体识别,利用BiLSTM-CRF算法实现对ATT&CK相关的技战术实体进行提取,是安全知识图谱构建的重要支撑。基础性文章,希望对您有帮助,如果存在错误或不足之处,还请海涵。且看且珍惜!
版本信息:
- keras-contrib V2.0.8
- keras V2.3.1
- tensorflow V2.2.0
常见框架如下图所示:
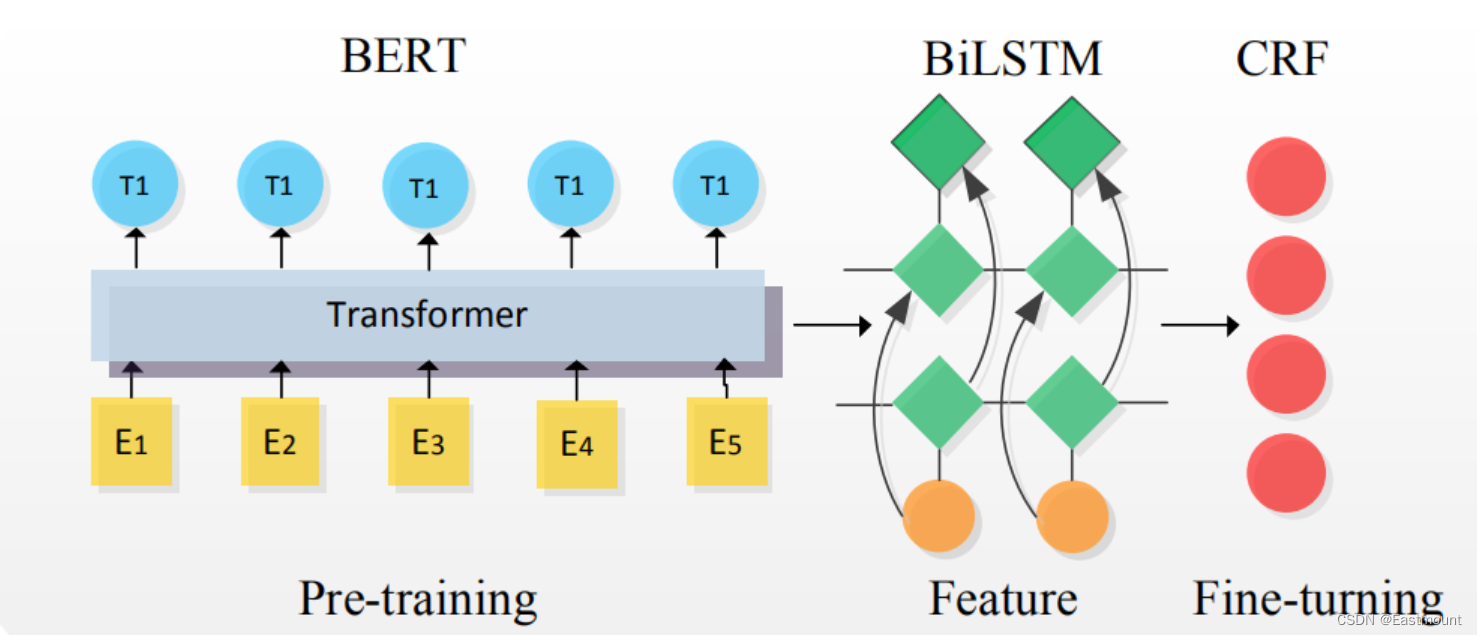
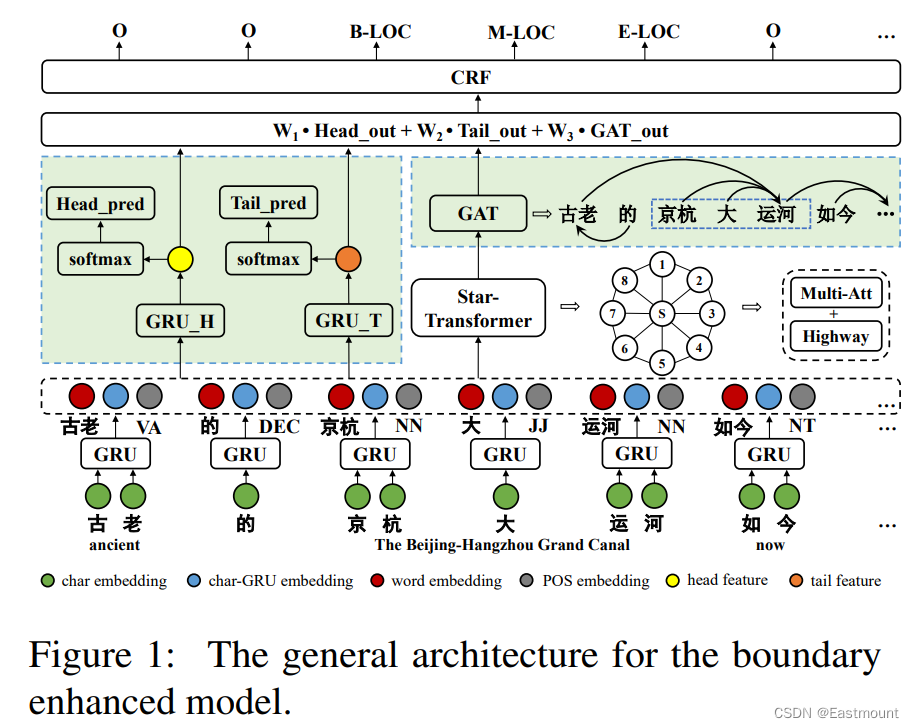
文章目录
作者作为网络安全的小白,分享一些自学基础教程给大家,主要是在线笔记,希望您们喜欢。同时,更希望您能与我一起操作和进步,后续将深入学习AI安全和系统安全知识并分享相关实验。总之,希望该系列文章对博友有所帮助,写文不易,大神们不喜勿喷,谢谢!如果文章对您有帮助,将是我创作的最大动力,点赞、评论、私聊均可,一起加油喔!
前文推荐:
- [当人工智能遇上安全] 1.人工智能真的安全吗?浙大团队外滩大会分享AI对抗样本技术
- [当人工智能遇上安全] 2.清华张超老师 - GreyOne: Discover Vulnerabilities with Data Flow Sensitive Fuzzing
- [当人工智能遇上安全] 3.安全领域中的机器学习及机器学习恶意请求识别案例分享
- [当人工智能遇上安全] 4.基于机器学习的恶意代码检测技术详解
- [当人工智能遇上安全] 5.基于机器学习算法的主机恶意代码识别研究
- [当人工智能遇上安全] 6.基于机器学习的入侵检测和攻击识别——以KDD CUP99数据集为例
- [当人工智能遇上安全] 7.基于机器学习的安全数据集总结
- [当人工智能遇上安全] 8.基于API序列和机器学习的恶意家族分类实例详解
- [当人工智能遇上安全] 9.基于API序列和深度学习的恶意家族分类实例详解
- [当人工智能遇上安全] 10.威胁情报实体识别之基于BiLSTM-CRF的实体识别万字详解
作者的github资源:
- https://github.com/eastmountyxz/AI-Security-Paper
- https://github.com/eastmountyxz/When-AI-meet-Security
一.ATT&CK数据采集
了解威胁情报的同学,应该都熟悉Mitre的ATT&CK网站,本文将采集该网站APT组织的攻击技战术数据,开展威胁情报实体识别实验。网址如下:
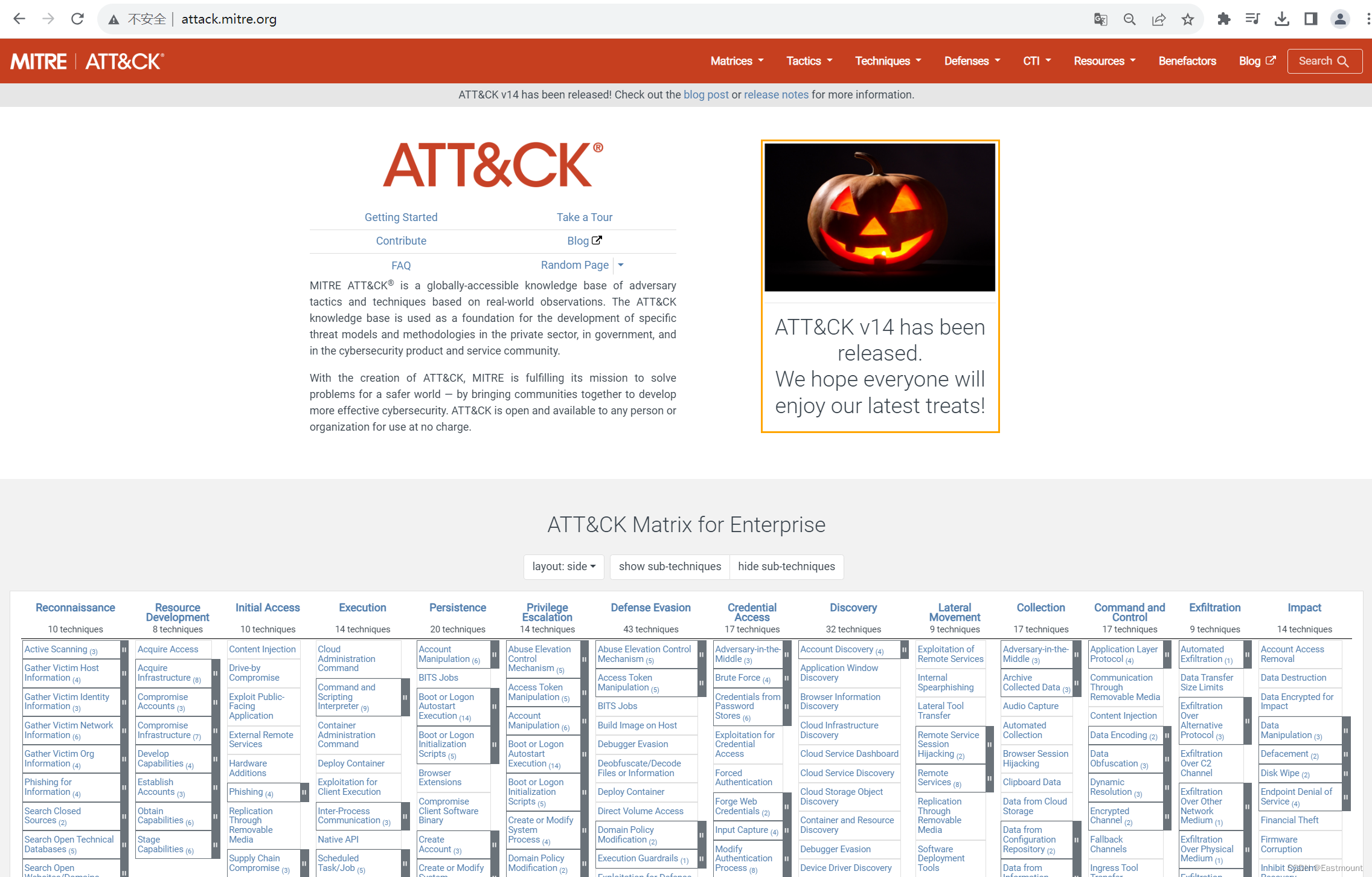
第一步,通过ATT&CK网站源码分析定位APT组织名称,并进行系统采集。
安装BeautifulSoup扩展包,该部分代码如下所示:
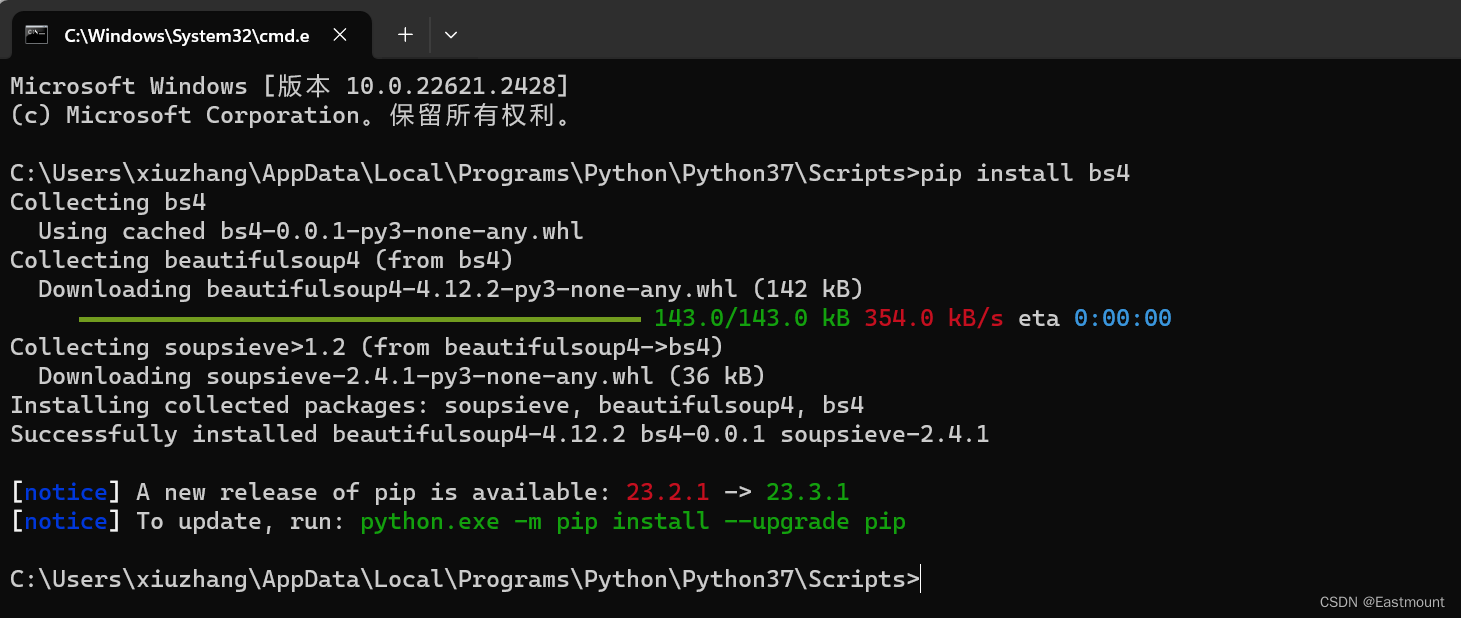
01-get-aptentity.py
#encoding:utf-8
#By:Eastmount CSDN
import re
import requests
from lxml import etree
from bs4 import BeautifulSoup
import urllib.request
#-------------------------------------------------------------------------------------------
#获取APT组织名称及链接
#设置浏览器代理,它是一个字典
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) \
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36'
}
url = 'https://attack.mitre.org/groups/'
#向服务器发出请求
r = requests.get(url = url, headers = headers).text
#解析DOM树结构
html_etree = etree.HTML(r)
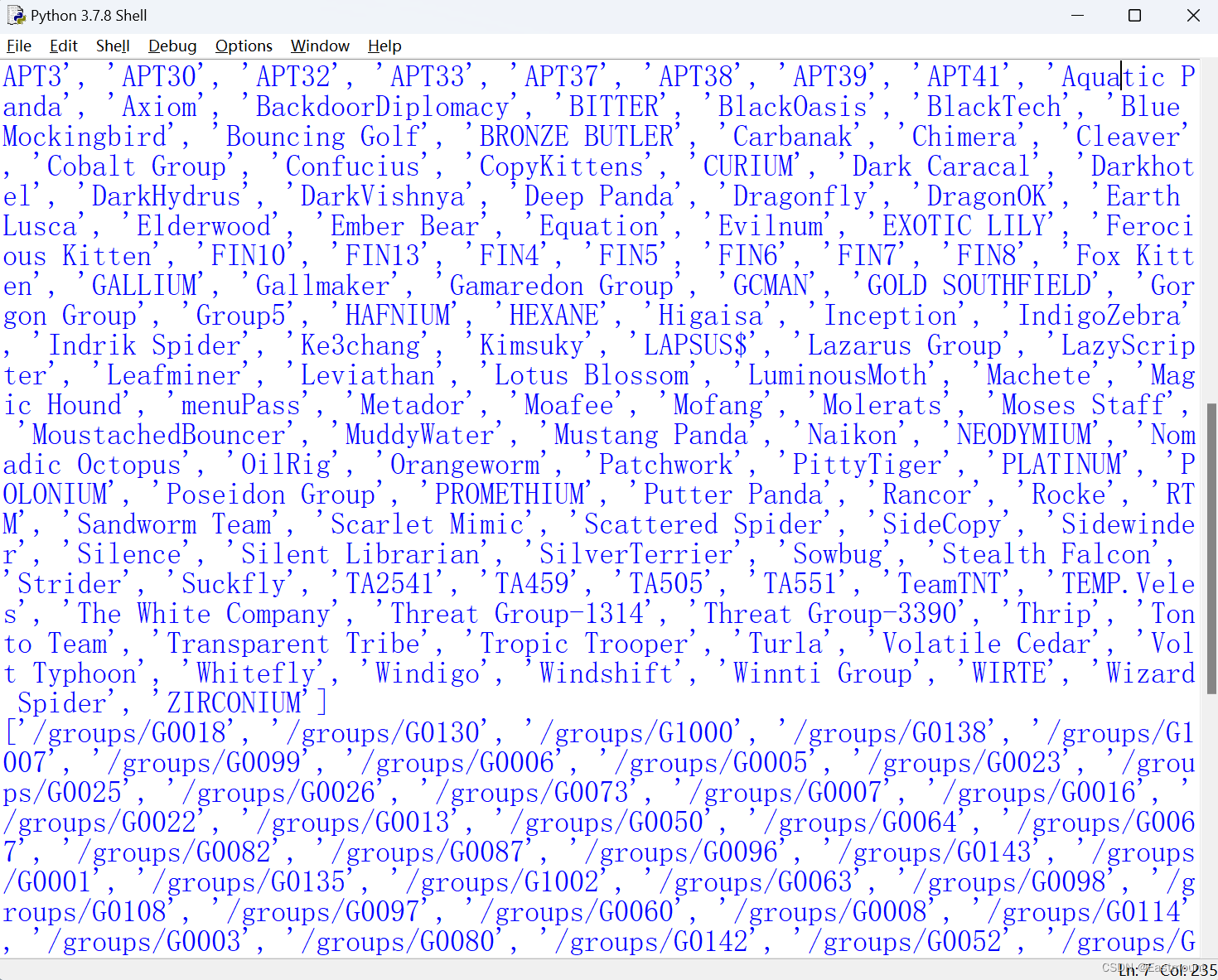
names = html_etree.xpath('//*[@class="table table-bordered table-alternate mt-2"]/tbody/tr/td[2]/a/text()')
print (names)
print(len(names),names[0])
filename = []
for name in names:
filename.append(name.strip())
print(filename)
#链接
urls = html_etree.xpath('//*[@class="table table-bordered table-alternate mt-2"]/tbody/tr/td[2]/a/@href')
print(urls)
print(len(urls), urls[0])
print("\n")
此时输出结果如下图所示,包括APT组织名称及对应的URL网址。
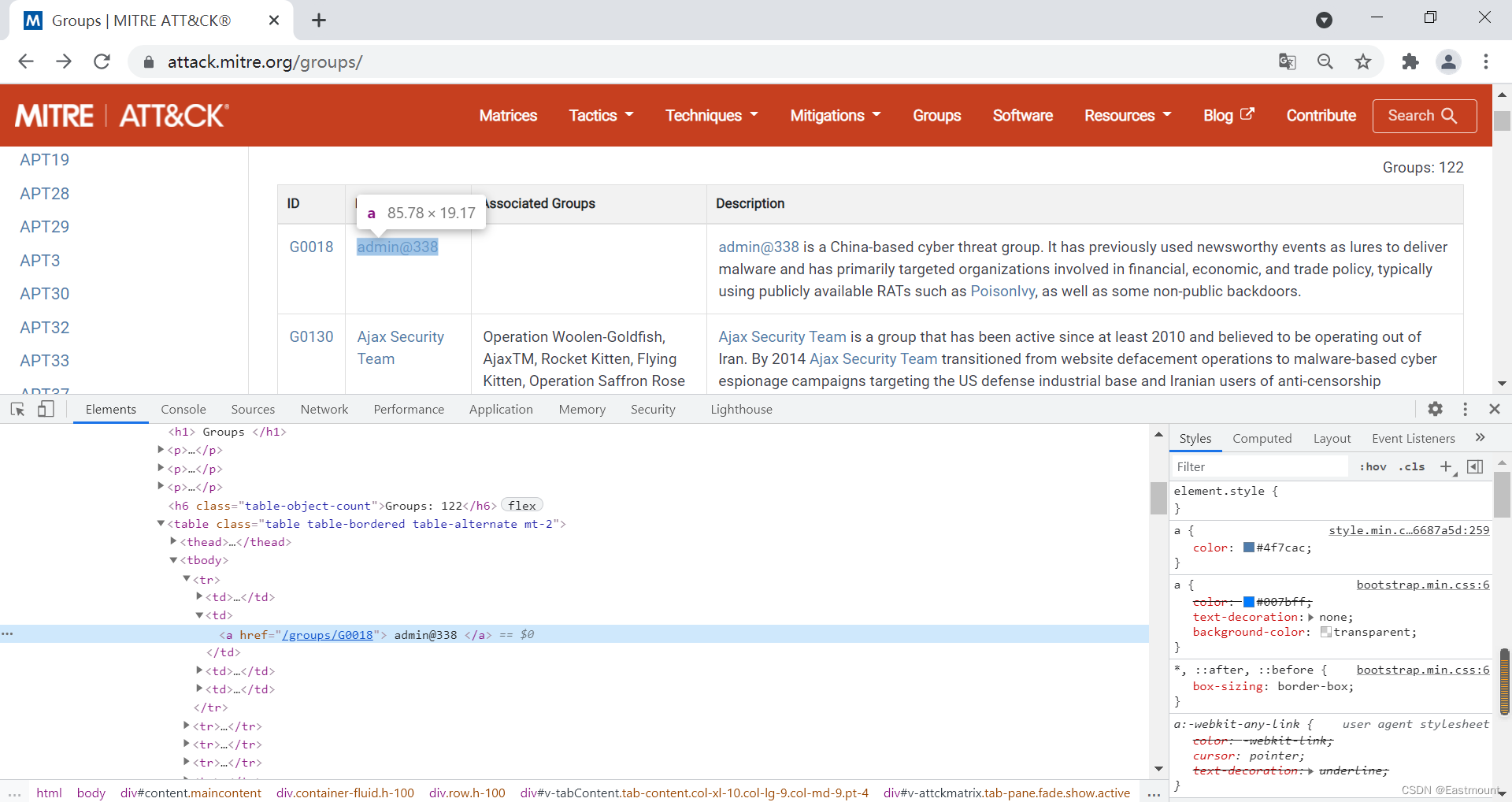
第二步,访问APT组织对应的URL,采集详细信息(正文描述)。
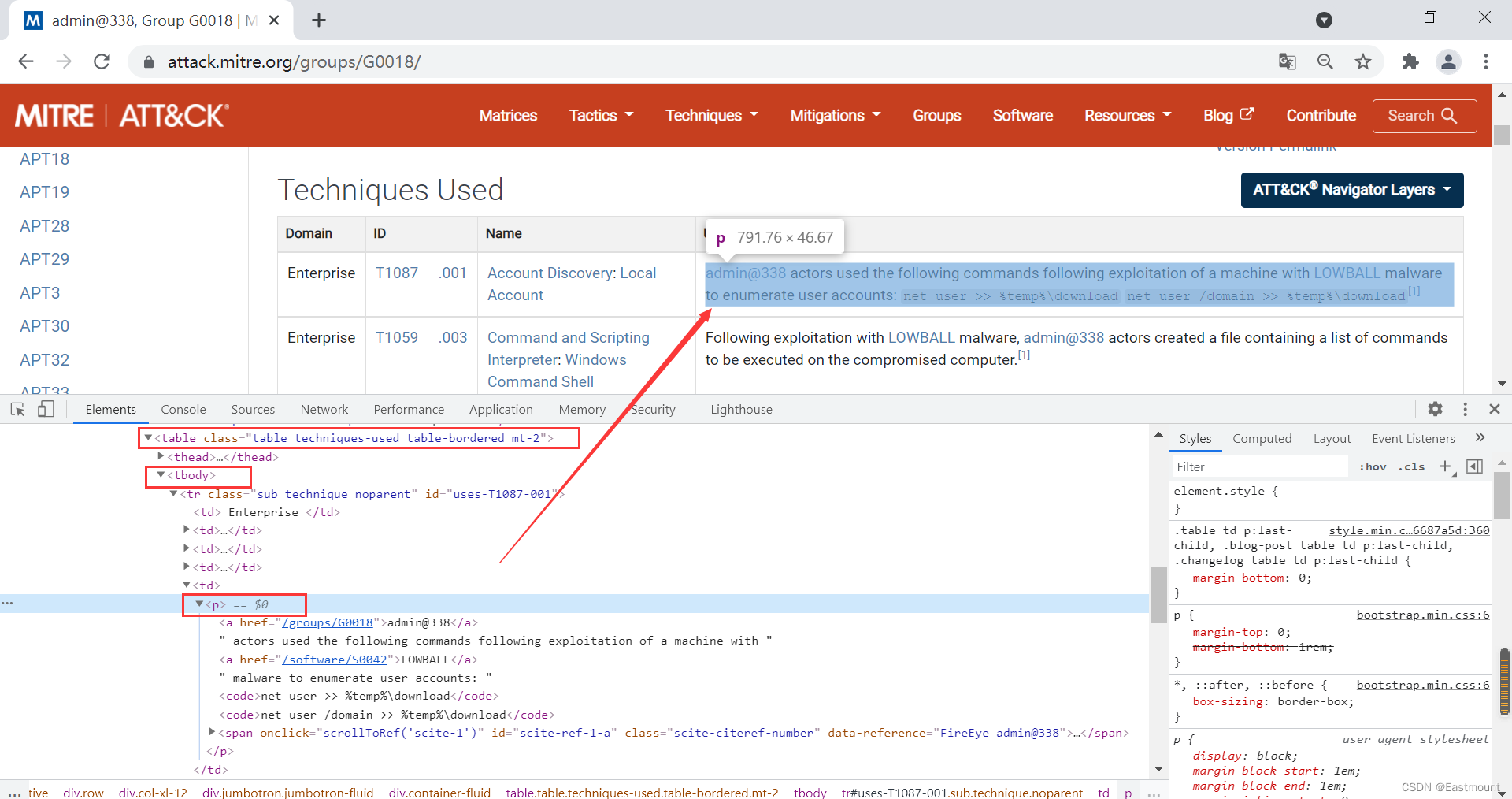
第三步,采集对应的技战术TTPs信息,其源码定位如下图所示。
第四步,编写代码完成威胁情报数据采集。01-spider-mitre.py 完整代码如下:
#encoding:utf-8
#By:Eastmount CSDN
import re
import requests
from lxml import etree
from bs4 import BeautifulSoup
import urllib.request
#-------------------------------------------------------------------------------------------
#获取APT组织名称及链接
#设置浏览器代理,它是一个字典
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) \
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36'
}
url = 'https://attack.mitre.org/groups/'
#向服务器发出请求
r = requests.get(url = url, headers = headers).text
#解析DOM树结构
html_etree = etree.HTML(r)
names = html_etree.xpath('//*[@class="table table-bordered table-alternate mt-2"]/tbody/tr/td[2]/a/text()')
print (names)
print(len(names),names[0])
#链接
urls = html_etree.xpath('//*[@class="table table-bordered table-alternate mt-2"]/tbody/tr/td[2]/a/@href')
print(urls)
print(len(urls), urls[0])
print("\n")
#-------------------------------------------------------------------------------------------
#获取详细信息
k = 0
while k<len(names):
filename = str(names[k]).strip() + ".txt"
url = "https://attack.mitre.org" + urls[k]
print(url)
#获取正文信息
page = urllib.request.Request(url, headers=headers)
page = urllib.request.urlopen(page)
contents = page.read()
soup = BeautifulSoup(contents, "html.parser")
#获取正文摘要信息
content = ""
for tag in soup.find_all(attrs={"class":"description-body"}):
#contents = tag.find("p").get_text()
contents = tag.find_all("p")
for con in contents:
content += con.get_text().strip() + "###\n" #标记句子结束(第二部分分句用)
#print(content)
#获取表格中的技术信息
for tag in soup.find_all(attrs={"class":"table techniques-used table-bordered mt-2"}):
contents = tag.find("tbody").find_all("tr")
for con in contents:
value = con.find("p").get_text() #存在4列或5列 故获取p值
#print(value)
content += value.strip() + "###\n" #标记句子结束(第二部分分句用)
#删除内容中的参考文献括号 [n]
result = re.sub(u"\\[.*?]", "", content)
print(result)
#文件写入
filename = "Mitre//" + filename
print(filename)
f = open(filename, "w", encoding="utf-8")
f.write(result)
f.close()
k += 1
输出结果如下图所示,共整理100个组织信息。
每个文件显示内容如下图所示:
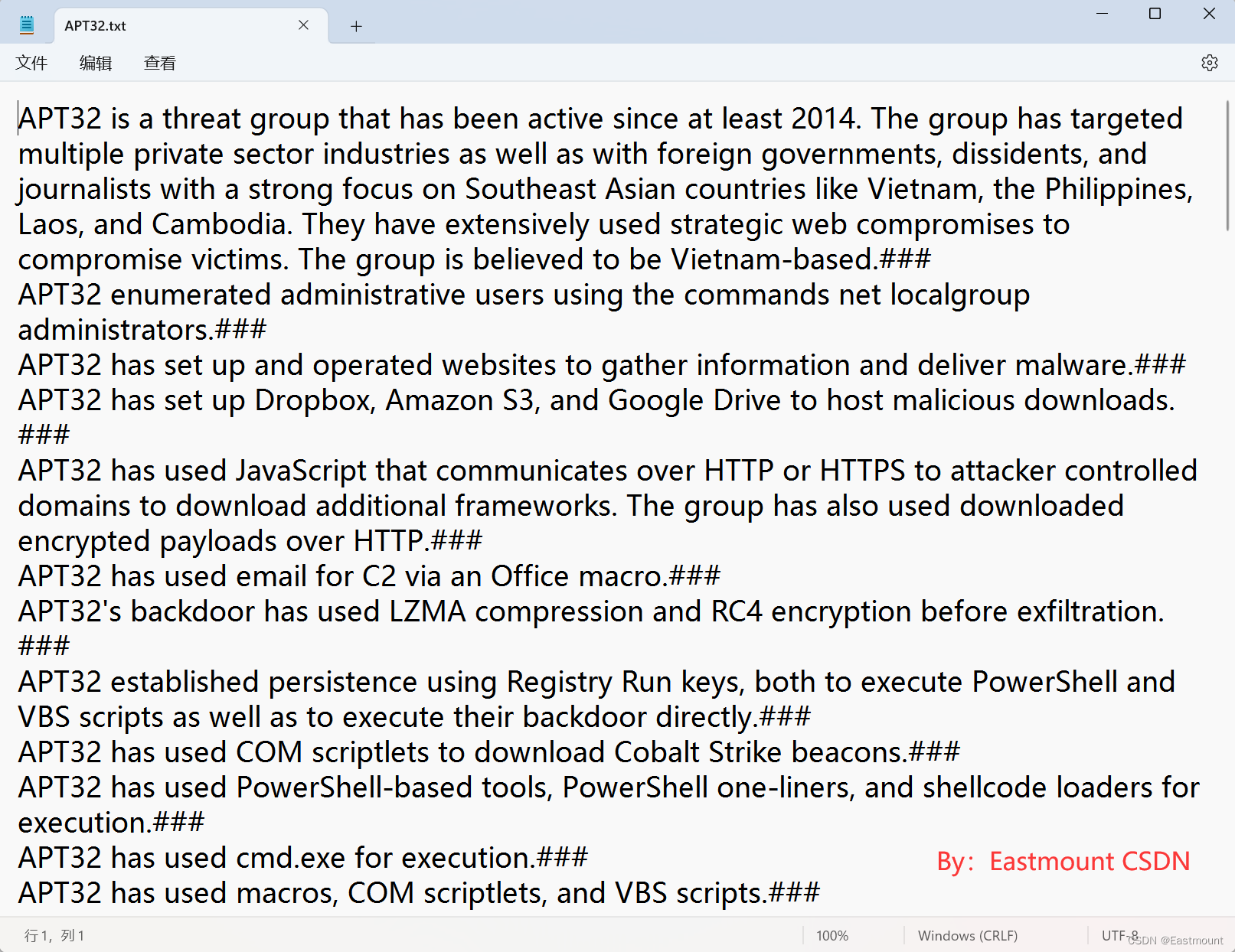
温馨提示:
由于网站的布局会不断变化和优化,因此读者需要掌握数据采集及语法树定位的基本方法,以不变应万变。此外,读者可以尝试采集所有锻炼甚至是URL跳转链接内容,请读者自行尝试和拓展!
二.数据拆分及内容统计
1.段落拆分
为了扩充数据集和更好地开展NLP处理,我们需要将文本数据进行分段处理。采用的方法是:
- 获取先前定义的标志位“###”
- 每隔五句生成一个TXT文件,命名方式为“10XX_组织名称”
02-dataset-split.py 完整代码:
#encoding:utf-8
#By:Eastmount CSDN
import re
import os
#------------------------------------------------------------------------
#获取文件路径及名称
def get_filepath(path):
entities = {} #字段实体类别
files = os.listdir(path) #遍历路径
return files
#-----------------------------------------------------------------------
#获取文件内容
def get_content(filename):
content = ""
with open(filename, "r", encoding="utf8") as f:
for line in f.readlines():
content += line.replace("\n"," ")
return content
#---------------------------------------------------------------------
#自定义分隔符文本分割
def split_text(text):
pattern = '###'
nums = text.split(pattern) #获取字符的下标位置
return nums
#-----------------------------------------------------------------------
#主函数
if __name__ == '__main__':
#获取文件名
path = "Mitre"
savepath = "Mitre-Split"
filenames = get_filepath(path)
print(filenames)
print("\n")
#遍历文件内容
k = 0
begin = 1001 #命名计数
while k<len(filenames):
filename = "Mitre//" + filenames[k]
print(filename)
content = get_content(filename)
print(content)
#分割句子
nums = split_text(content)
#每隔五句输出为一个TXT文档
n = 0
result = ""
while n<len(nums):
if n>0 and (n%5)==0: #存储
savename = savepath + "//" + str(begin) + "-" + filenames[k]
print(savename)
f = open(savename, "w", encoding="utf8")
f.write(result)
result = ""
result = nums[n].lstrip() + "### " #第一句
begin += 1
f.close()
else: #赋值
result += nums[n].lstrip() + "### "
n += 1
k += 1
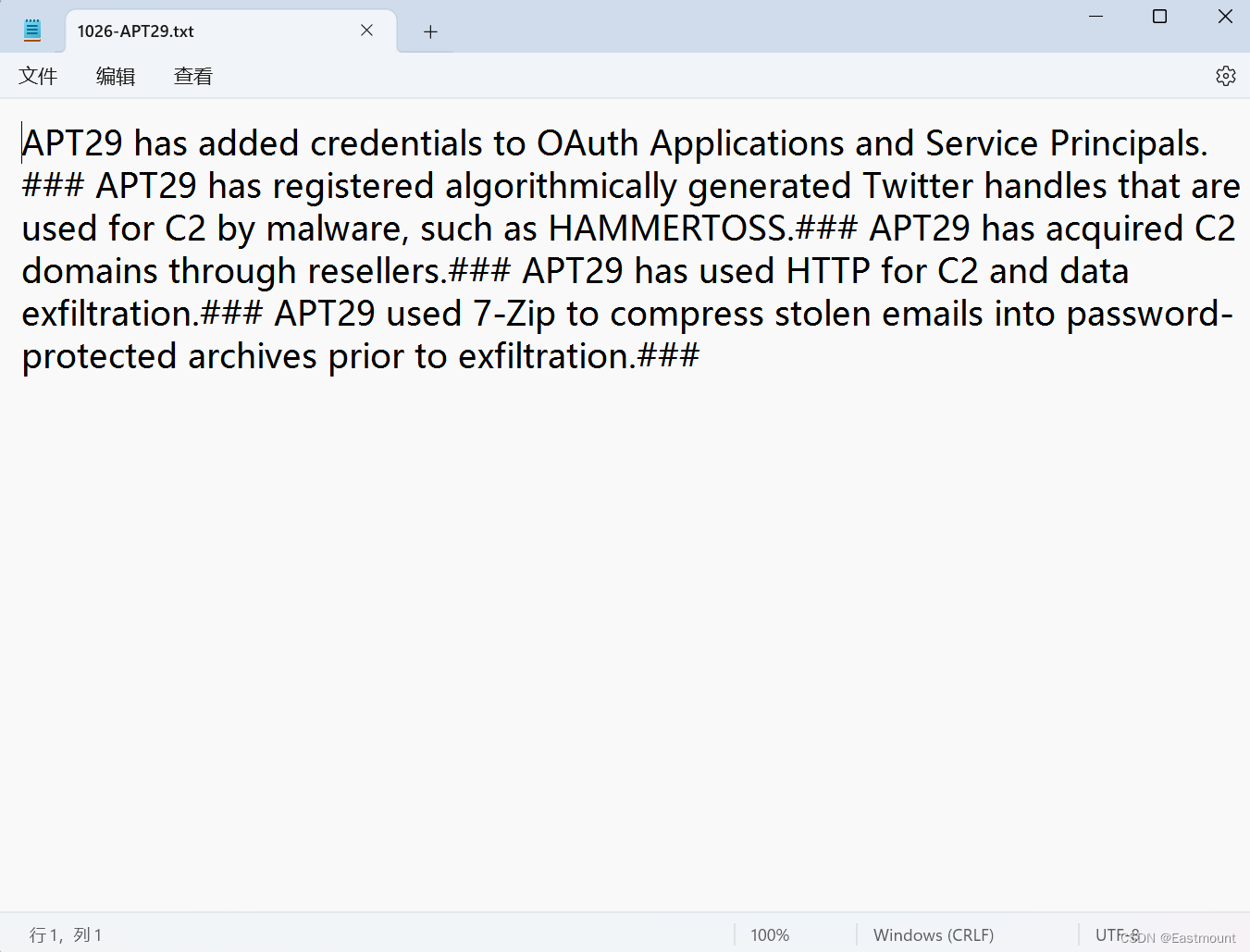
最终拆分成381个文件,位于“Mitre-Split”文件夹。
单个文件如下图所示:
2.句子拆分
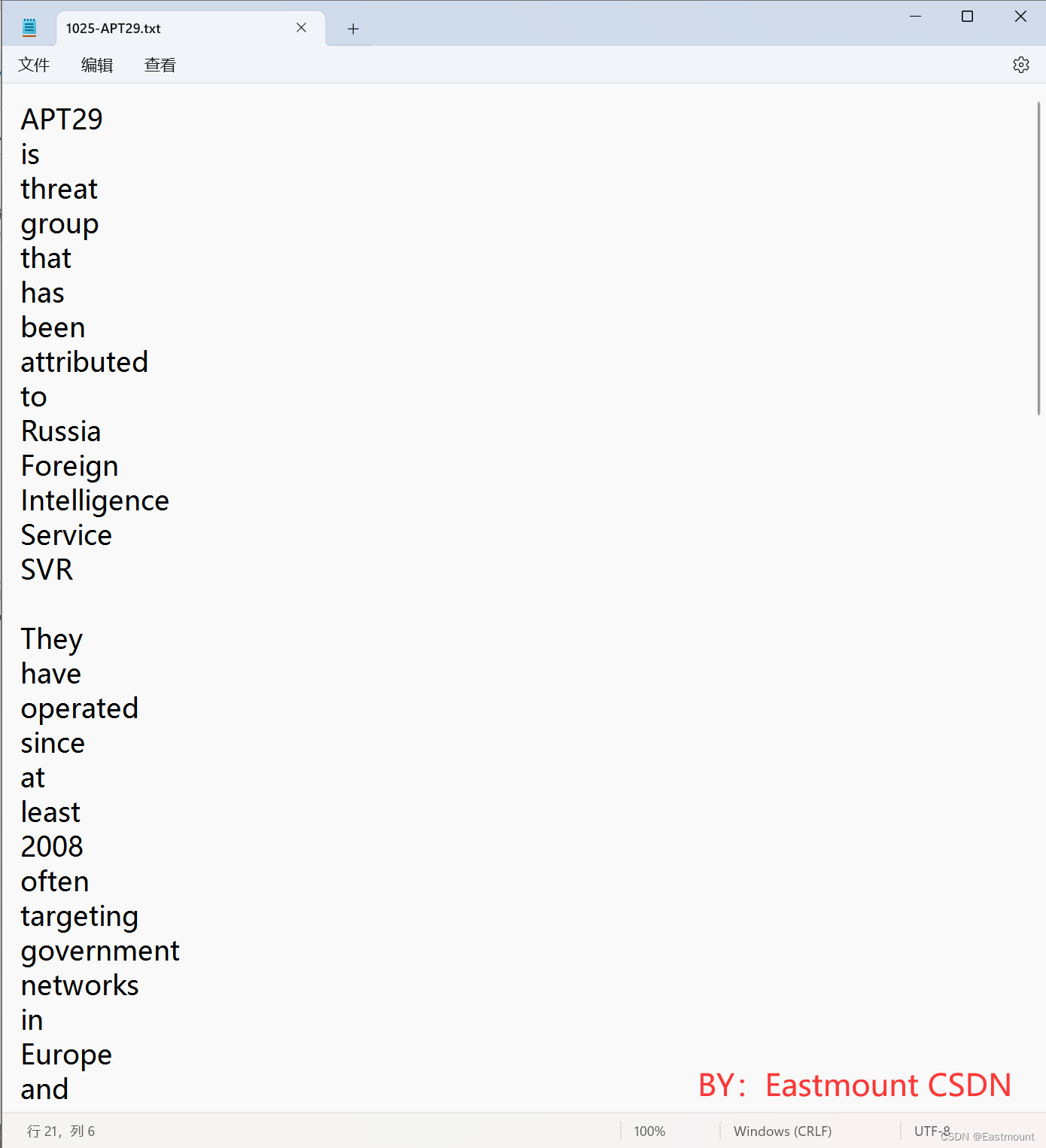
命名实体识别任务在数据标注之前,需要完成:
- 将段落拆分成句子
- 将句子按照单词分隔,每行对应一个单词,每个单词对应后续的一个标注
- 关键代码 text.split(" ")
句子拆分后的效果如下图所示:
完整代码如下所示,并生成“Mitre-Split-Word”文件夹。
#encoding:utf-8
#By:Eastmount CSDN
import re
import os
#------------------------------------------------------------------------
#获取文件路径及名称
def get_filepath(path):
entities = {} #字段实体类别
files = os.listdir(path) #遍历路径
return files
#-----------------------------------------------------------------------
#获取文件内容
def get_content(filename):
content = ""
with open(filename, "r", encoding="utf8") as f:
for line in f.readlines():
content += line.replace("\n"," ")
return content
#---------------------------------------------------------------------
#空格分隔获取英文单词
def split_word(text):
nums = text.split(" ")
#print(nums)
return nums
#-----------------------------------------------------------------------
#主函数
if __name__ == '__main__':
#获取文件名
path = "Mitre-Split"
savepath = "Mitre-Split-Word"
filenames = get_filepath(path)
print(filenames)
print("\n")
#遍历文件内容
k = 0
while k<len(filenames):
filename = path + "//" + filenames[k]
print(filename)
content = get_content(filename)
content = content.replace("###","\n")
#分割句子
nums = split_word(content)
#print(nums)
savename = savepath + "//" + filenames[k]
f = open(savename, "w", encoding="utf8")
for n in nums:
if n != "":
#替换标点符号
n = n.replace(",", "")
n = n.replace(";", "")
n = n.replace("!", "")
n = n.replace("?", "")
n = n.replace(":", "")
n = n.replace('"', "")
n = n.replace('(', "")
n = n.replace(')', "")
n = n.replace('’', "")
n = n.replace('\'s', "")
#替换句号
if ("." in n) and (n not in ["U.S.","U.K."]):
n = n.rstrip(".")
n = n.rstrip(".\n")
n = n + "\n"
f.write(n+"\n")
f.close()
k += 1
三.数据标注
数据标注采用暴力的方式进行,即定义不同类型的实体名称并利用BIO的方式进行标注。通过ATT&CK技战术方式进行标注,后续可以结合人工校正,同时可以定义更多类型的实体。
- BIO标注
| 实体名称 | 实体数量 | 示例 |
|---|---|---|
| APT攻击组织 | 128 | APT32、Lazarus Group |
| 攻击漏洞 | 56 | CVE-2009-0927 |
| 区域位置 | 72 | America、Europe |
| 攻击行业 | 34 | companies、finance |
| 攻击手法 | 65 | C&C、RAT、DDoS |
| 利用软件 | 48 | 7-Zip、Microsoft |
| 操作系统 | 10 | Linux、Windows |
常见的数据标注工具:
- 图像标注:labelme,LabelImg,Labelbox,RectLabel,CVAT,VIA
- 半自动ocr标注:PPOCRLabel
- NLP标注工具:labelstudio
该部分完整代码(04-BIO-data-annotation.py)如下所示:
#encoding:utf-8
import re
import os
import csv
#-----------------------------------------定义实体类型-------------------------------------
#APT攻击组织
aptName = ['admin@338', 'Ajax Security Team', 'APT-C-36', 'APT1', 'APT12', 'APT16', 'APT17', 'APT18', 'APT19', 'APT28', 'APT29', 'APT3', 'APT30', 'APT32',
'APT33', 'APT37', 'APT38', 'APT39', 'APT41', 'Axiom', 'BlackOasis', 'BlackTech', 'Blue Mockingbird', 'Bouncing Golf', 'BRONZE BUTLER',
'Carbanak', 'Chimera', 'Cleaver', 'Cobalt Group', 'CopyKittens', 'Dark Caracal', 'Darkhotel', 'DarkHydrus', 'DarkVishnya', 'Deep Panda',
'Dragonfly', 'Dragonfly 2.0', 'DragonOK', 'Dust Storm', 'Elderwood', 'Equation', 'Evilnum', 'FIN10', 'FIN4', 'FIN5', 'FIN6', 'FIN7', 'FIN8',
'Fox Kitten', 'Frankenstein', 'GALLIUM', 'Gallmaker', 'Gamaredon Group', 'GCMAN', 'GOLD SOUTHFIELD', 'Gorgon Group', 'Group5', 'HAFNIUM',
'Higaisa', 'Honeybee', 'Inception', 'Indrik Spider', 'Ke3chang', 'Kimsuky', 'Lazarus Group', 'Leafminer', 'Leviathan', 'Lotus Blossom',
'Machete', 'Magic Hound', 'menuPass', 'Moafee', 'Mofang', 'Molerats', 'MuddyWater', 'Mustang Panda', 'Naikon', 'NEODYMIUM', 'Night Dragon',
'OilRig', 'Operation Wocao', 'Orangeworm', 'Patchwork', 'PittyTiger', 'PLATINUM', 'Poseidon Group', 'PROMETHIUM', 'Putter Panda', 'Rancor',
'Rocke', 'RTM', 'Sandworm Team', 'Scarlet Mimic', 'Sharpshooter', 'Sidewinder', 'Silence', 'Silent Librarian', 'SilverTerrier', 'Sowbug', 'Stealth Falcon',
'Stolen Pencil', 'Strider', 'Suckfly', 'TA459', 'TA505', 'TA551', 'Taidoor', 'TEMP.Veles', 'The White Company', 'Threat Group-1314', 'Threat Group-3390',
'Thrip', 'Tropic Trooper', 'Turla', 'Volatile Cedar', 'Whitefly', 'Windigo', 'Windshift', 'Winnti Group', 'WIRTE', 'Wizard Spider', 'ZIRCONIUM',
'UNC2452', 'NOBELIUM', 'StellarParticle']
#特殊名称的攻击漏洞
cveName = ['CVE-2009-3129', 'CVE-2012-0158', 'CVE-2009-4324' 'CVE-2009-0927', 'CVE-2011-0609', 'CVE-2011-0611', 'CVE-2012-0158',
'CVE-2017-0262', 'CVE-2015-4902', 'CVE-2015-1701', 'CVE-2014-4076', 'CVE-2015-2387', 'CVE-2015-1701', 'CVE-2017-0263']
#区域位置
locationName = ['China-based', 'China', 'North', 'Korea', 'Russia', 'South', 'Asia', 'US', 'U.S.', 'UK', 'U.K.', 'Iran', 'Iranian', 'America', 'Colombian',
'Chinese', "People’s", 'Liberation', 'Army', 'PLA', 'General', 'Staff', "Department’s", 'GSD', 'MUCD', 'Unit', '61398', 'Chinese-based',
"Russia's", "General", "Staff", "Main", "Intelligence", "Directorate", "GRU", "GTsSS", "unit", "26165", '74455', 'Georgian', 'SVR',
'Europe', 'Asia', 'Hong Kong', 'Vietnam', 'Cambodia', 'Thailand', 'Germany', 'Spain', 'Finland', 'Israel', 'India', 'Italy', 'South Asia',
'Korea', 'Kuwait', 'Lebanon', 'Malaysia', 'United', 'Kingdom', 'Netherlands', 'Southeast', 'Asia', 'Pakistan', 'Canada', 'Bangladesh',
'Ukraine', 'Austria', 'France', 'Korea']
#攻击行业
industryName = ['financial', 'economic', 'trade', 'policy', 'defense', 'industrial', 'espionage', 'government', 'institutions', 'institution', 'petroleum',
'industry', 'manufacturing', 'corporations', 'media', 'outlets', 'high-tech', 'companies', 'governments', 'medical', 'defense', 'finance',
'energy', 'pharmaceutical', 'telecommunications', 'high', 'tech', 'education', 'investment', 'firms', 'organizations', 'research', 'institutes',
]
#攻击方法
methodName = ['RATs', 'RAT', 'SQL', 'injection', 'spearphishing', 'spear', 'phishing', 'backdoors', 'vulnerabilities', 'vulnerability', 'commands', 'command',
'anti-censorship', 'keystrokes', 'VBScript', 'malicious', 'document', 'scheduled', 'tasks', 'C2', 'C&C', 'communications', 'batch', 'script',
'shell', 'scripting', 'social', 'engineering', 'privilege', 'escalation', 'credential', 'dumping', 'control', 'obfuscates', 'obfuscate', 'payload', 'upload',
'payloads', 'encode', 'decrypts', 'attachments', 'attachment', 'inject', 'collect', 'large-scale', 'scans', 'persistence', 'brute-force/password-spray',
'password-spraying', 'backdoor', 'bypass', 'hijacking', 'escalate', 'privileges', 'lateral', 'movement', 'Vulnerability', 'timestomping',
'keylogging', 'DDoS', 'bootkit', 'UPX' ]
#利用软件
softwareName = ['Microsoft', 'Word', 'Office', 'Firefox', 'Google', 'RAR', 'WinRAR', 'zip', 'GETMAIL', 'MAPIGET', 'Outlook', 'Exchange', "Adobe's", 'Adobe',
'Acrobat', 'Reader', 'RDP', 'PDFs', 'PDF', 'RTF', 'XLSM', 'USB', 'SharePoint', 'Forfiles', 'Delphi', 'COM', 'Excel', 'NetBIOS',
'Tor', 'Defender', 'Scanner', 'Gmail', 'Yahoo', 'Mail', '7-Zip', 'Twitter', 'gMSA', 'Azure', 'Exchange', 'OWA', 'SMB', 'Netbios',
'WinRM']
#操作系统
osName = ['Windows', 'windows', 'Mac', 'Linux', 'Android', 'android', 'linux', 'mac', 'unix', 'Unix']
#计算并输出相关的内容
saveCVE = cveName
saveAPT = aptName
saveLocation = locationName
saveIndustry = industryName
saveMethod = methodName
saveSoftware = softwareName
saveOS = osName
#------------------------------------------------------------------------
#获取文件路径及名称
def get_filepath(path):
entities = {} #字段实体类别
files = os.listdir(path) #遍历路径
return files
#-----------------------------------------------------------------------
#获取文件内容
def get_content(filename):
content = []
with open(filename, "r", encoding="utf8") as f:
for line in f.readlines():
content.append(line.strip())
return content
#---------------------------------------------------------------------
#空格分隔获取英文单词
def data_annotation(text):
n = 0
nums = []
while n<len(text):
word = text[n].strip()
if word == "": #换行 startswith
n += 1
nums.append("")
continue
#APT攻击组织
if word in aptName:
nums.append("B-AG")
#攻击漏洞
elif "CVE-" in word or 'MS-' in word:
nums.append("B-AV")
print("CVE漏洞:", word)
if word not in saveCVE:
saveCVE.append(word)
#区域位置
elif word in locationName:
nums.append("B-RL")
#攻击行业
elif word in industryName:
nums.append("B-AI")
#攻击手法
elif word in methodName:
nums.append("B-AM")
#利用软件
elif word in softwareName:
nums.append("B-SI")
#操作系统
elif word in osName:
nums.append("B-OS")
#特殊情况-APT组织
#Ajax Security Team、Deep Panda、Sandworm Team、Cozy Bear、The Dukes、Dark Halo
elif ((word in "Ajax Security Team") and (text[n+1].strip() in "Ajax Security Team") and word!="a" and word!="it") or \
((word in "Ajax Security Team") and (text[n-1].strip() in "Ajax Security Team") and word!="a" and word!="it") or \
((word=="Deep") and (text[n+1].strip()=="Panda")) or \
((word=="Panda") and (text[n-1].strip()=="Deep")) or \
((word=="Sandworm") and (text[n+1].strip()=="Team")) or \
((word=="Team") and (text[n-1].strip()=="Sandworm")) or \
((word=="Cozy") and (text[n+1].strip()=="Bear")) or \
((word=="Bear") and (text[n-1].strip()=="Cozy")) or \
((word=="The") and (text[n+1].strip()=="Dukes")) or \
((word=="Dukes") and (text[n-1].strip()=="The")) or \
((word=="Dark") and (text[n+1].strip()=="Halo")) or \
((word=="Halo") and (text[n-1].strip()=="Dark")):
nums.append("B-AG")
if "Deep Panda" not in saveAPT:
saveAPT.append("Deep Panda")
if "Sandworm Team" not in saveAPT:
saveAPT.append("Sandworm Team")
if "Cozy Bear" not in saveAPT:
saveAPT.append("Cozy Bear")
if "The Dukes" not in saveAPT:
saveAPT.append("The Dukes")
if "Dark Halo" not in saveAPT:
saveAPT.append("Dark Halo")
#特殊情况-攻击行业
elif ((word=="legal") and (text[n+1].strip()=="services")) or \
((word=="services") and (text[n-1].strip()=="legal")):
nums.append("B-AI")
if "legal services" not in saveIndustry:
saveIndustry.append("legal services")
#特殊情况-攻击方法
#watering hole attack、bypass application control、take screenshots
elif ((word in "watering hole attack") and (text[n+1].strip() in "watering hole attack") and word!="a" and text[n+1].strip()!="a") or \
((word in "watering hole attack") and (text[n-1].strip() in "watering hole attack") and word!="a" and text[n+1].strip()!="a") or \
((word in "bypass application control") and (text[n+1].strip() in "bypass application control") and word!="a" and text[n+1].strip()!="a") or \
((word in "bypass application control") and (text[n-1].strip() in "bypass application control") and word!="a" and text[n-1].strip()!="a") or \
((word=="take") and (text[n+1].strip()=="screenshots")) or \
((word=="screenshots") and (text[n-1].strip()=="take")):
nums.append("B-AM")
if "watering hole attack" not in saveMethod:
saveMethod.append("watering hole attack")
if "bypass application control" not in saveMethod:
saveMethod.append("bypass application control")
if "take screenshots" not in saveMethod:
saveMethod.append("take screenshots")
#特殊情况-利用软件
#MAC address、IP address、Port 22、Delivery Service、McAfee Email Protection
elif ((word=="legal") and (text[n+1].strip()=="services")) or \
((word=="services") and (text[n-1].strip()=="legal")) or \
((word=="MAC") and (text[n+1].strip()=="address")) or \
((word=="address") and (text[n-1].strip()=="MAC")) or \
((word=="IP") and (text[n+1].strip()=="address")) or \
((word=="address") and (text[n-1].strip()=="IP")) or \
((word=="Port") and (text[n+1].strip()=="22")) or \
((word=="22") and (text[n-1].strip()=="Port")) or \
((word=="Delivery") and (text[n+1].strip()=="Service")) or \
((word=="Service") and (text[n-1].strip()=="Delivery")) or \
((word in "McAfee Email Protection") and (text[n+1].strip() in "McAfee Email Protection")) or \
((word in "McAfee Email Protection") and (text[n-1].strip() in "McAfee Email Protection")):
nums.append("B-SI")
if "MAC address" not in saveSoftware:
saveSoftware.append("MAC address")
if "IP address" not in saveSoftware:
saveSoftware.append("IP address")
if "Port 22" not in saveSoftware:
saveSoftware.append("Port 22")
if "Delivery Service" not in saveSoftware:
saveSoftware.append("Delivery Service")
if "McAfee Email Protection" not in saveSoftware:
saveSoftware.append("McAfee Email Protection")
#特殊情况-区域位置
#Russia's Foreign Intelligence Service、the Middle East
elif ((word in "Russia's Foreign Intelligence Service") and (text[n+1].strip() in "Russia's Foreign Intelligence Service")) or \
((word in "Russia's Foreign Intelligence Service") and (text[n-1].strip() in "Russia's Foreign Intelligence Service")) or \
((word in "the Middle East") and (text[n+1].strip() in "the Middle East")) or \
((word in "the Middle East") and (text[n-1].strip() in "the Middle East")) :
nums.append("B-RL")
if "Russia's Foreign Intelligence Service" not in saveLocation:
saveLocation.append("Russia's Foreign Intelligence Service")
if "the Middle East" not in saveLocation:
saveLocation.append("the Middle East")
else:
nums.append("O")
n += 1
return nums
#-----------------------------------------------------------------------
#主函数
if __name__ == '__main__':
path = "Mitre-Split-Word"
savepath = "Mitre-Split-Word-BIO"
filenames = get_filepath(path)
print(filenames)
print("\n")
#遍历文件内容
k = 0
while k<len(filenames):
filename = path + "//" + filenames[k]
print("-------------------------")
print(filename)
content = get_content(filename)
#分割句子
nums = data_annotation(content)
#print(nums)
print(len(content),len(nums))
#数据存储
filename = filenames[k].replace(".txt", ".csv")
savename = savepath + "//" + filename
f = open(savename, "w", encoding="utf8", newline='')
fwrite = csv.writer(f)
fwrite.writerow(['word','label'])
n = 0
while n<len(content):
fwrite.writerow([content[n],nums[n]])
n += 1
f.close()
print("-------------------------\n\n")
#if k>=28:
# break
k += 1
#-------------------------------------------------------------------------------------------------
#输出存储的漏洞结果
saveCVE.remove("CVE-2009-4324CVE-2009-0927")
saveCVE.sort()
print(saveCVE)
print("CVE漏洞:", len(saveCVE))
saveAPT.sort()
print(saveAPT)
print("APT组织:", len(saveAPT))
saveLocation.sort()
print(saveLocation)
print("区域位置:", len(saveLocation))
saveIndustry.sort()
print(saveIndustry)
print("攻击行业:", len(saveIndustry))
saveSoftware.sort()
print(saveSoftware)
print("利用软件:", len(saveSoftware))
saveMethod.sort()
print(saveMethod)
print("攻击手法:", len(saveMethod))
saveOS.sort()
print(saveOS)
print("操作系统:", len(saveOS))
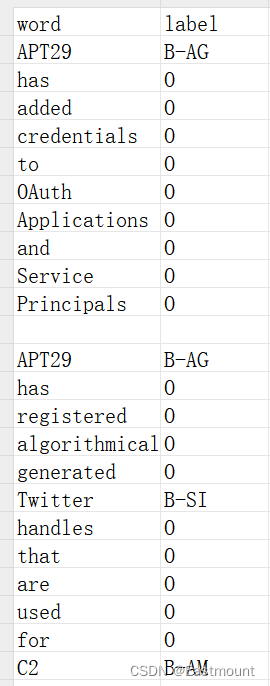
此时的输出结果如下图所示:
温馨提示:
关于数据标注的校正和优化过程请读着自行思考,此外BIO结尾标注代码还需要调整。当我们拥有更准确的标注,将有利于所有的实体识别研究。
四.数据集划分
在进行实体识别标注之前,我们将数据集随机划分为训练集、测试集、验证集。
- 将Mitre-Split-Word-BIO中的文件随机划分并存储在三个文件夹中
- 构建代码合成三个TXT文件,后续代码将对这些文件开展训练和测试任务
– dataset-train.txt、dataset-test.txt、dataset-val.txt
如下图所示:
完整代码如下所示:
#encoding:utf-8
#By:Eastmount CSDN
import re
import os
import csv
#------------------------------------------------------------------------
#获取文件路径及名称
def get_filepath(path):
entities = {} #字段实体类别
files = os.listdir(path) #遍历路径
return files
#-----------------------------------------------------------------------
#获取文件内容
def get_content(filename):
content = ""
fr = open(filename, "r", encoding="utf8")
reader = csv.reader(fr)
k = 0
for r in reader:
if k>0 and (r[0]!="" or r[0]!=" ") and r[1]!="":
content += r[0] + " " + r[1] + "\n"
elif (r[0]=="" or r[0]==" ") and r[1]!="":
content += "UNK" + " " + r[1] + "\n"
elif (r[0]=="" or r[0]==" ") and r[1]=="":
content += "\n"
k += 1
return content
#-----------------------------------------------------------------------
#主函数
if __name__ == '__main__':
#获取文件名
path = "train"
#path = "test"
#path = "val"
filenames = get_filepath(path)
print(filenames)
print("\n")
savefilename = "dataset-train.txt"
#savefilename = "dataset-test.txt"
#savefilename = "dataset-val.txt"
f = open(savefilename, "w", encoding="utf8")
#遍历文件内容
k = 0
while k<len(filenames):
filename = path + "//" + filenames[k]
print(filename)
content = get_content(filename)
print(content)
f.write(content)
k += 1
f.close()
运行结果如下图所示:
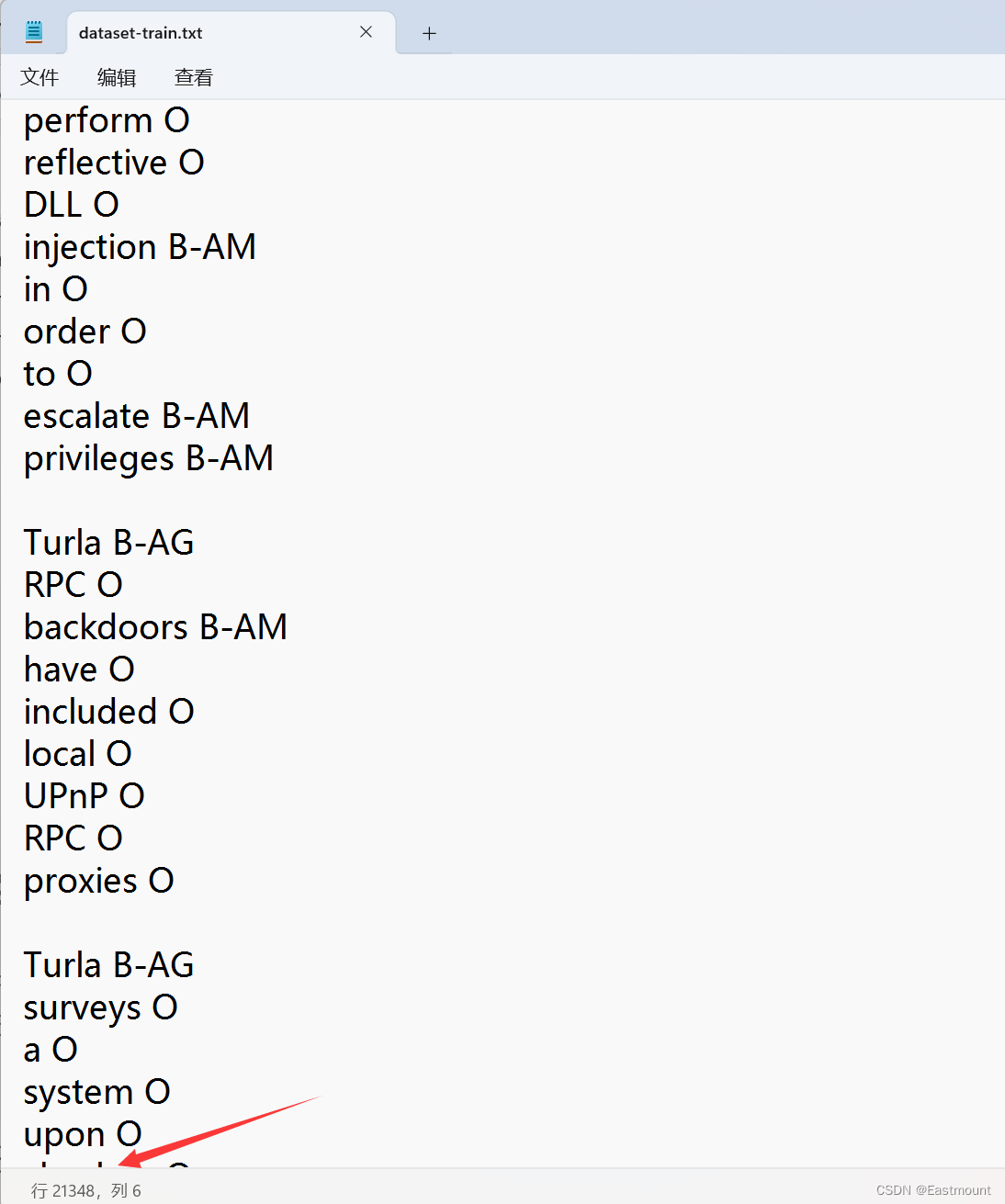
五.基于CRF的实体识别
写到该部分我们即可开展实体识别研究,首先利用代表性的条件随机场(Conditional Random Fields,CRF)模型讲解。关于CRF原理请读者自行了解。
1.安装keras-contrib
CRF模型作者安装的是 keras-contrib。
第一步,如果读者直接使用“pip install keras-contrib”可能会报错,远程下载也报错。
- pip install git+https://www.github.com/keras-team/keras-contrib.git
甚至会报错 ModuleNotFoundError: No module named ‘keras_contrib’。
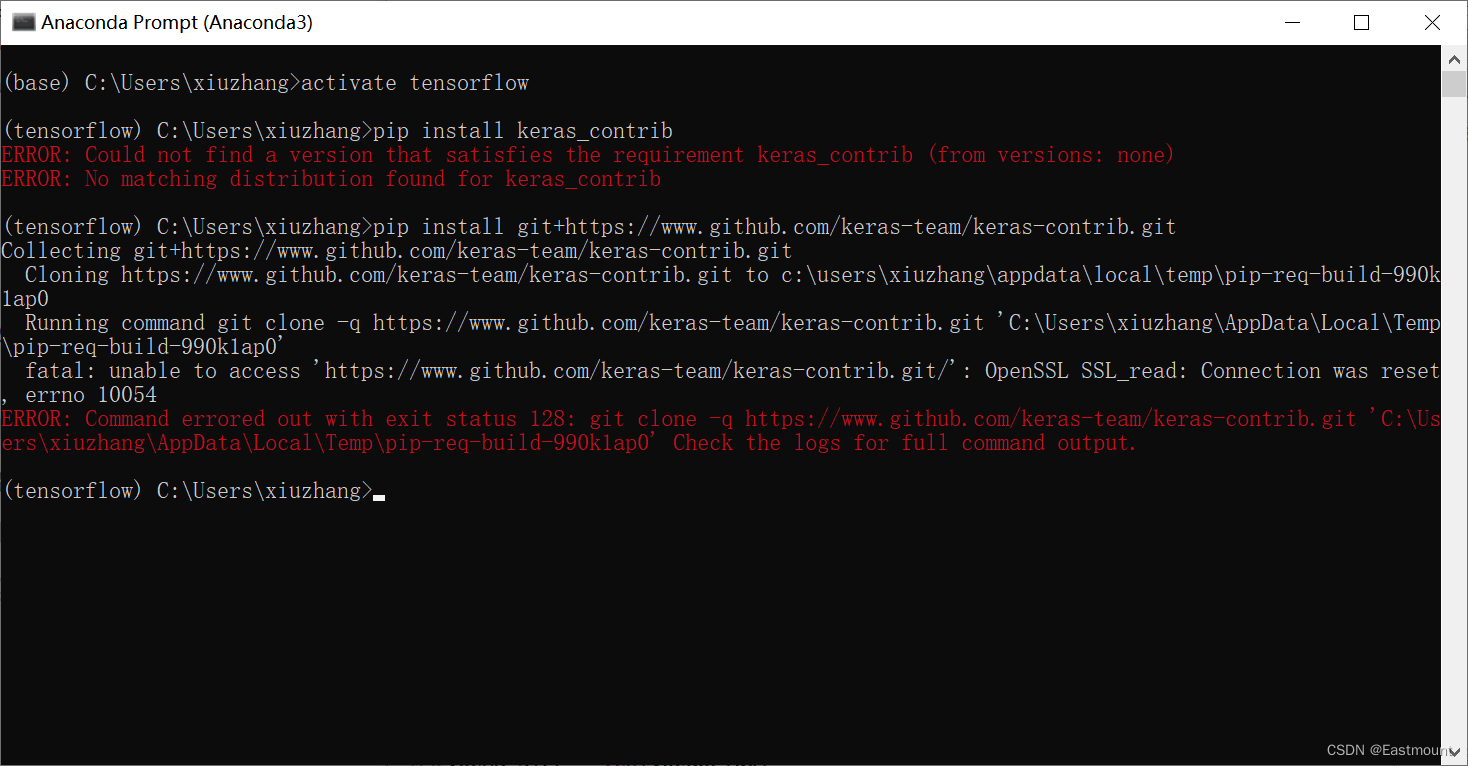
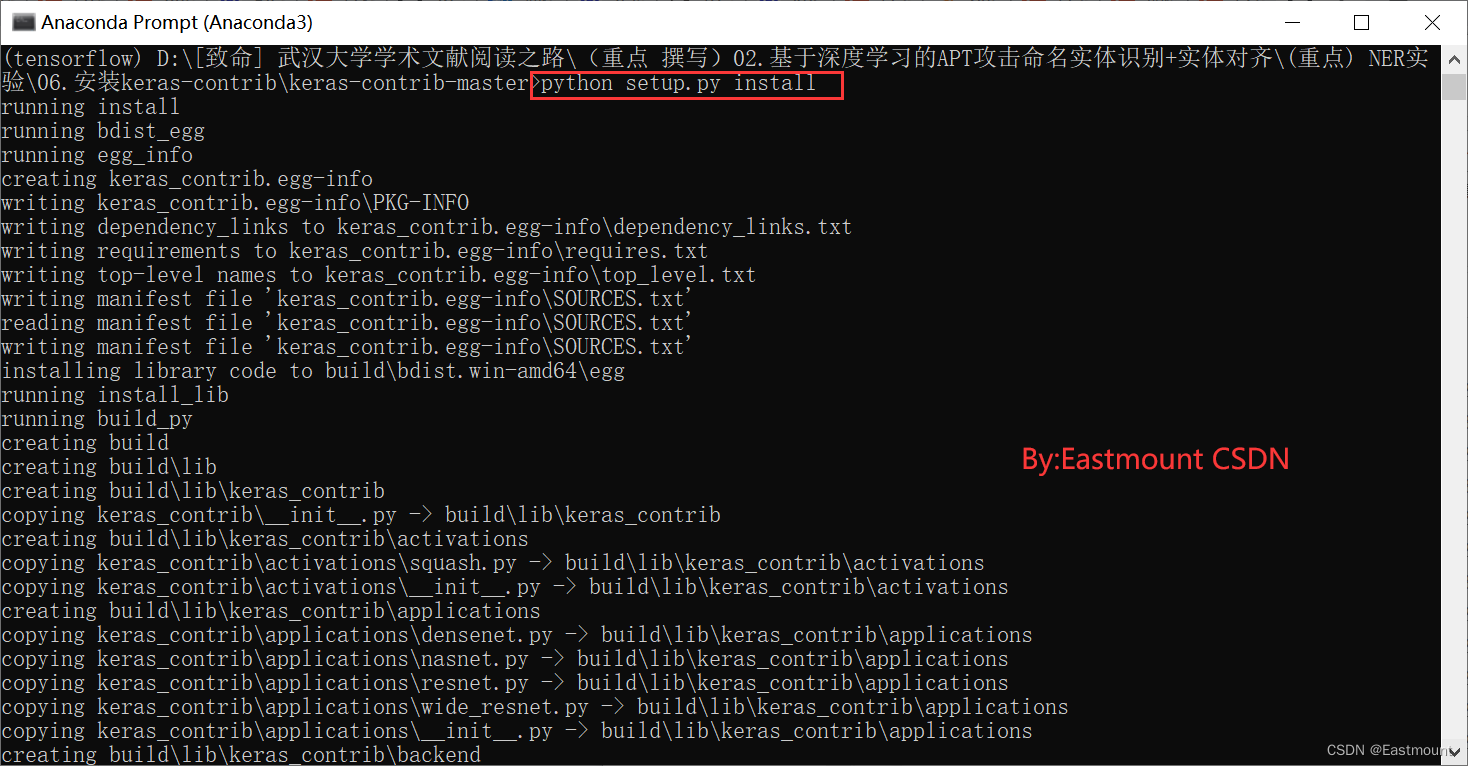
第二步,作者从github中下载该资源,并在本地安装。
- https://github.com/keras-team/keras-contrib
- keras-contrib 版本:2.0.8
git clone https://www.github.com/keras-team/keras-contrib.git
cd keras-contrib
python setup.py install
安装成功如下图所示:
读者可以从我的资源中下载代码和扩展包。
2.安装Keras
同样需要安装keras和TensorFlow扩展包。
如果TensorFlow下载太慢,可以设置清华大学镜像,实际安装2.2版本。
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
pip install tensorflow==2.2
3.完整代码
代码如下所示,推荐资料:
- https://github.com/huanghao128/zh-nlp-demo
- https://blog.csdn.net/qq_35549634/article/details/106861168
#encoding:utf-8
#By:Eastmount CSDN
import re
import os
import csv
import numpy as np
import keras
from keras.preprocessing import sequence
from keras.models import Sequential
from keras.models import Model
from keras.layers import Masking, Embedding, Bidirectional, LSTM, Dense
from keras.layers import Input, TimeDistributed, Activation
from keras.models import load_model
from keras_contrib.layers import CRF
from keras_contrib.losses import crf_loss
from keras_contrib.metrics import crf_viterbi_accuracy
from keras import backend as K
from sklearn import metrics
#------------------------------------------------------------------------
#第一步 数据预处理
#------------------------------------------------------------------------
train_data_path = "dataset-train.txt" #训练数据
test_data_path = "dataset-test.txt" #测试数据
val_data_path = "dataset-val.txt" #验证数据
char_vocab_path = "char_vocabs.txt" #字典文件
special_words = ['<PAD>', '<UNK>'] #特殊词表示
#BIO标记的标签
label2idx = {"O": 0, "B-AG": 1, "B-AV": 2, "B-RL": 3,
"B-AI":4, "B-AM": 5, "B-SI": 6, "B-OS": 7 }
# 索引和BIO标签对应
idx2label = {idx: label for label, idx in label2idx.items()}
print(idx2label)
# 读取字符词典文件
with open(char_vocab_path, "r", encoding="utf8") as fo:
char_vocabs = [line.strip() for line in fo]
char_vocabs = special_words + char_vocabs
print(char_vocabs)
print("--------------------------------------------\n\n")
# 字符和索引编号对应 {'<PAD>': 0, '<UNK>': 1, 'APT-C-36': 2, ...}
idx2vocab = {idx: char for idx, char in enumerate(char_vocabs)}
vocab2idx = {char: idx for idx, char in idx2vocab.items()}
print(idx2vocab)
print("--------------------------------------------\n\n")
print(vocab2idx)
print("--------------------------------------------\n\n")
#------------------------------------------------------------------------
#第二步 读取训练语料
#------------------------------------------------------------------------
def read_corpus(corpus_path, vocab2idx, label2idx):
datas, labels = [], []
with open(corpus_path, encoding='utf-8') as fr:
lines = fr.readlines()
sent_, tag_ = [], []
for line in lines:
if line != '\n': #断句
line = line.strip()
[char, label] = line.split()
sent_.append(char)
tag_.append(label)
else:
#print(line)
#vocab2idx[0] => <PAD>
sent_ids = [vocab2idx[char] if char in vocab2idx else vocab2idx['<UNK>'] for char in sent_]
tag_ids = [label2idx[label] if label in label2idx else 0 for label in tag_]
datas.append(sent_ids)
labels.append(tag_ids)
sent_, tag_ = [], []
return datas, labels
#原始数据
train_datas_, train_labels_ = read_corpus(train_data_path, vocab2idx, label2idx)
test_datas_, test_labels_ = read_corpus(test_data_path, vocab2idx, label2idx)
#输出测试结果 1639 1639 923 923
print(len(train_datas_), len(train_labels_), len(test_datas_), len(test_labels_))
print(train_datas_[5])
print([idx2vocab[idx] for idx in train_datas_[5]])
print(train_labels_[5])
print([idx2label[idx] for idx in train_labels_[5]])
#------------------------------------------------------------------------
#第三步 数据填充 one-hot编码
#------------------------------------------------------------------------
MAX_LEN = 100
VOCAB_SIZE = len(vocab2idx)
CLASS_NUMS = len(label2idx)
# padding data
print('padding sequences')
train_datas = sequence.pad_sequences(train_datas_, maxlen=MAX_LEN)
train_labels = sequence.pad_sequences(train_labels_, maxlen=MAX_LEN)
test_datas = sequence.pad_sequences(test_datas_, maxlen=MAX_LEN)
test_labels = sequence.pad_sequences(test_labels_, maxlen=MAX_LEN)
print('x_train shape:', train_datas.shape)
print('x_test shape:', test_datas.shape)
# (1639, 100) (923, 100)
# encoder one-hot
train_labels = keras.utils.to_categorical(train_labels, CLASS_NUMS)
test_labels = keras.utils.to_categorical(test_labels, CLASS_NUMS)
print('trainlabels shape:', train_labels.shape)
print('testlabels shape:', test_labels.shape)
# (1639, 100, 8) (923, 100, 8)
#------------------------------------------------------------------------
#第四步 构建CRF模型
#------------------------------------------------------------------------
EPOCHS = 20
BATCH_SIZE = 64
EMBED_DIM = 128
HIDDEN_SIZE = 64
MAX_LEN = 100
VOCAB_SIZE = len(vocab2idx)
CLASS_NUMS = len(label2idx)
K.clear_session()
print(VOCAB_SIZE, CLASS_NUMS, '\n') #3860 8
#模型构建 CRF
inputs = Input(shape=(MAX_LEN,), dtype='int32')
x = Masking(mask_value=0)(inputs)
x = Embedding(VOCAB_SIZE, 32, mask_zero=False)(x)
x = TimeDistributed(Dense(CLASS_NUMS))(x)
outputs = CRF(CLASS_NUMS)(x)
model = Model(inputs=inputs, outputs=outputs)
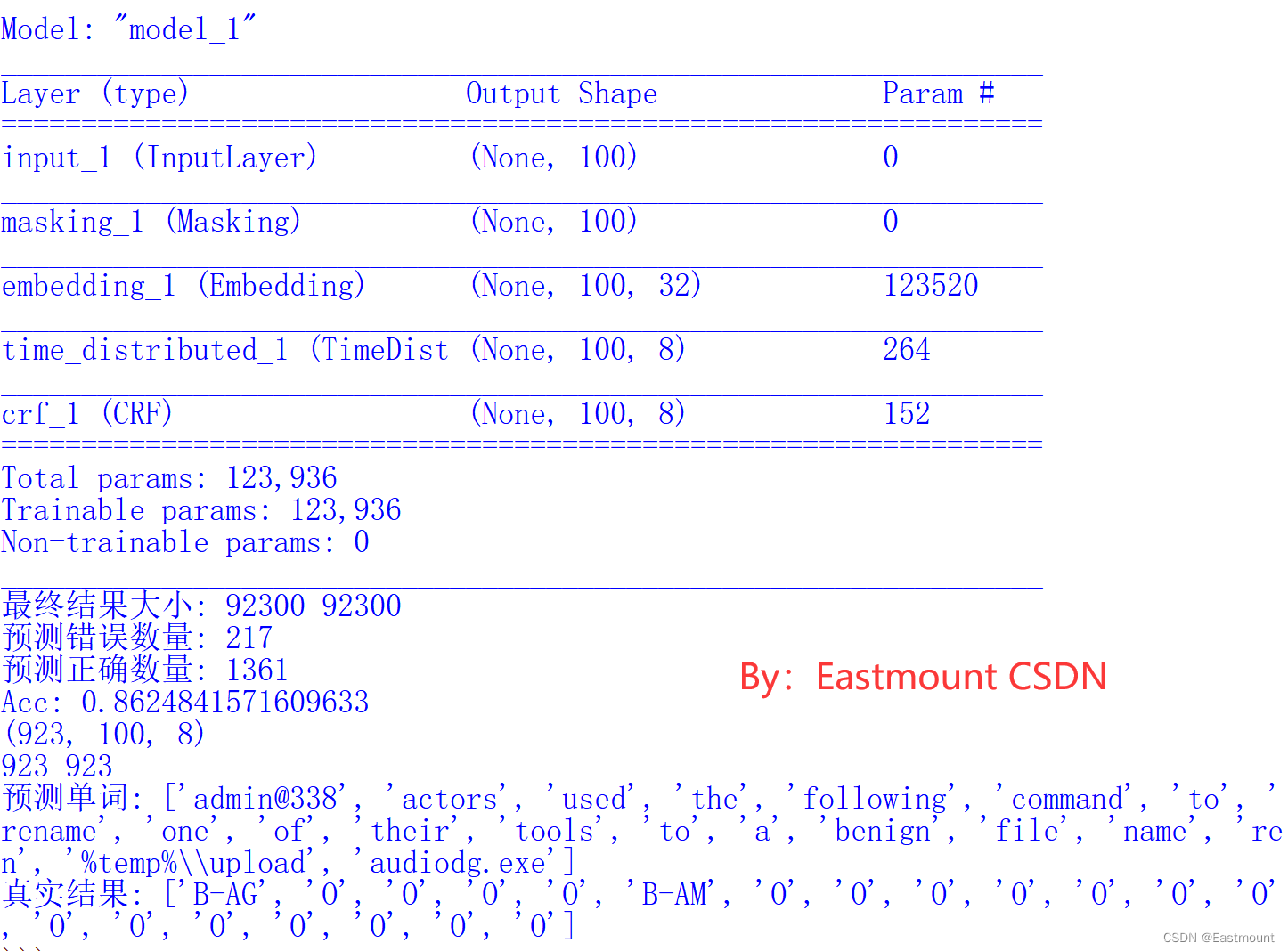
model.summary()
flag = "test"
if flag=="train":
#模型训练
model.compile(loss=crf_loss, optimizer='adam', metrics=[crf_viterbi_accuracy])
model.fit(train_datas, train_labels, epochs=EPOCHS, verbose=1, validation_split=0.1)
score = model.evaluate(test_datas, test_labels, batch_size=BATCH_SIZE)
print(model.metrics_names)
print(score)
model.save("ch_ner_model.h5")
else:
#------------------------------------------------------------------------
#第五步 训练模型
#------------------------------------------------------------------------
char_vocab_path = "char_vocabs.txt" #字典文件
model_path = "ch_ner_model.h5" #模型文件
ner_labels = {"O": 0, "B-AG": 1, "B-AV": 2, "B-RL": 3,
"B-AI":4, "B-AM": 5, "B-SI": 6, "B-OS": 7 }
special_words = ['<PAD>', '<UNK>']
MAX_LEN = 100
#预测结果
model = load_model(model_path, custom_objects={'CRF': CRF}, compile=False)
y_pred = model.predict(test_datas)
y_labels = np.argmax(y_pred, axis=2) #取最大值
z_labels = np.argmax(test_labels, axis=2) #真实值
word_labels = test_datas #真实值
k = 0
final_y = [] #预测结果对应的标签
final_z = [] #真实结果对应的标签
final_word = [] #对应的特征单词
while k<len(y_labels):
y = y_labels[k]
for idx in y:
final_y.append(idx2label[idx])
#print("预测结果:", [idx2label[idx] for idx in y])
z = z_labels[k]
#print(z)
for idx in z:
final_z.append(idx2label[idx])
#print("真实结果:", [idx2label[idx] for idx in z])
word = word_labels[k]
#print(word)
n for idx in word:
final_word.append(idx2vocab[idx])
k += 1
print("最终结果大小:", len(final_y),len(final_z))
n = 0
numError = 0
numRight = 0
while n<len(final_y):
if final_y[n]!=final_z[n] and final_z[n]!='O':
numError += 1
if final_y[n]==final_z[n] and final_z[n]!='O':
numRight += 1
n += 1
print("预测错误数量:", numError)
print("预测正确数量:", numRight)
print("Acc:", numRight*1.0/(numError+numRight))
print(y_pred.shape)
print(len(test_datas_), len(test_labels_))
print("预测单词:", [idx2vocab[idx] for idx in test_datas_[0]])
print("真实结果:", [idx2label[idx] for idx in test_labels_[0]])
#文件存储
fw = open("Final_CRF_Result.csv", "w", encoding="utf8", newline='')
fwrite = csv.writer(fw)
fwrite.writerow(['pre_label','real_label', 'word'])
n = 0
while n<len(final_y):
fwrite.writerow([final_y[n],final_z[n],final_word[n]])
n += 1
fw.close()
构建的模型如下图所示:

运行结果如下,训练完成后将flag变量修改为“test”测试。
32/1475 [..............................] - ETA: 0s - loss: 0.0102 - crf_viterbi_accuracy: 0.9997
416/1475 [=======>......................] - ETA: 5s - loss: 0.0143 - crf_viterbi_accuracy: 0.9982
736/1475 [=============>................] - ETA: 4s - loss: 0.0147 - crf_viterbi_accuracy: 0.9981
1056/1475 [====================>.........] - ETA: 2s - loss: 0.0141 - crf_viterbi_accuracy: 0.9983
1344/1475 [==========================>...] - ETA: 0s - loss: 0.0138 - crf_viterbi_accuracy: 0.9984
1472/1475 [============================>.] - ETA: 0s - loss: 0.0136 - crf_viterbi_accuracy: 0.9984
['loss', 'crf_viterbi_accuracy']
[0.021301430796362854, 0.9972449541091919]
六.基于BiLSTM-CRF的实体识别
下面的代码是构建BiLSTM-CRF模型实现实体识别。
#encoding:utf-8
#By:Eastmount CSDN
import re
import os
import csv
import numpy as np
import keras
from keras.preprocessing import sequence
from keras.models import Sequential
from keras.models import Model
from keras.layers import Masking, Embedding, Bidirectional, LSTM, Dense
from keras.layers import Input, TimeDistributed, Activation
from keras.models import load_model
from keras_contrib.layers import CRF
from keras_contrib.losses import crf_loss
from keras_contrib.metrics import crf_viterbi_accuracy
from keras import backend as K
from sklearn import metrics
#------------------------------------------------------------------------
#第一步 数据预处理
#------------------------------------------------------------------------
train_data_path = "dataset-train.txt" #训练数据
test_data_path = "dataset-test.txt" #测试数据
val_data_path = "dataset-val.txt" #验证数据
char_vocab_path = "char_vocabs.txt" #字典文件
special_words = ['<PAD>', '<UNK>'] #特殊词表示
#BIO标记的标签
label2idx = {"O": 0, "B-AG": 1, "B-AV": 2, "B-RL": 3,
"B-AI":4, "B-AM": 5, "B-SI": 6, "B-OS": 7 }
# 索引和BIO标签对应
idx2label = {idx: label for label, idx in label2idx.items()}
print(idx2label)
# 读取字符词典文件
with open(char_vocab_path, "r", encoding="utf8") as fo:
char_vocabs = [line.strip() for line in fo]
char_vocabs = special_words + char_vocabs
# 字符和索引编号对应 {'<PAD>': 0, '<UNK>': 1, 'APT-C-36': 2, ...}
idx2vocab = {idx: char for idx, char in enumerate(char_vocabs)}
vocab2idx = {char: idx for idx, char in idx2vocab.items()}
#------------------------------------------------------------------------
#第二步 读取训练语料
#------------------------------------------------------------------------
def read_corpus(corpus_path, vocab2idx, label2idx):
datas, labels = [], []
with open(corpus_path, encoding='utf-8') as fr:
lines = fr.readlines()
sent_, tag_ = [], []
for line in lines:
if line != '\n': #断句
line = line.strip()
[char, label] = line.split()
sent_.append(char)
tag_.append(label)
else:
sent_ids = [vocab2idx[char] if char in vocab2idx else vocab2idx['<UNK>'] for char in sent_]
tag_ids = [label2idx[label] if label in label2idx else 0 for label in tag_]
datas.append(sent_ids)
labels.append(tag_ids)
sent_, tag_ = [], []
return datas, labels
#原始数据
train_datas_, train_labels_ = read_corpus(train_data_path, vocab2idx, label2idx)
test_datas_, test_labels_ = read_corpus(test_data_path, vocab2idx, label2idx)
#------------------------------------------------------------------------
#第三步 数据填充 one-hot编码
#------------------------------------------------------------------------
MAX_LEN = 100
VOCAB_SIZE = len(vocab2idx)
CLASS_NUMS = len(label2idx)
print('padding sequences')
train_datas = sequence.pad_sequences(train_datas_, maxlen=MAX_LEN)
train_labels = sequence.pad_sequences(train_labels_, maxlen=MAX_LEN)
test_datas = sequence.pad_sequences(test_datas_, maxlen=MAX_LEN)
test_labels = sequence.pad_sequences(test_labels_, maxlen=MAX_LEN)
print('x_train shape:', train_datas.shape)
print('x_test shape:', test_datas.shape)
train_labels = keras.utils.to_categorical(train_labels, CLASS_NUMS)
test_labels = keras.utils.to_categorical(test_labels, CLASS_NUMS)
print('trainlabels shape:', train_labels.shape)
print('testlabels shape:', test_labels.shape)
#------------------------------------------------------------------------
#第四步 构建BiLSTM+CRF模型
#------------------------------------------------------------------------
EPOCHS = 12
BATCH_SIZE = 64
EMBED_DIM = 128
HIDDEN_SIZE = 64
MAX_LEN = 100
VOCAB_SIZE = len(vocab2idx)
CLASS_NUMS = len(label2idx)
K.clear_session()
print(VOCAB_SIZE, CLASS_NUMS, '\n') #3860 8
#模型构建 BiLSTM-CRF
inputs = Input(shape=(MAX_LEN,), dtype='int32')
x = Masking(mask_value=0)(inputs)
x = Embedding(VOCAB_SIZE, EMBED_DIM, mask_zero=False)(x) #修改掩码False
x = Bidirectional(LSTM(HIDDEN_SIZE, return_sequences=True))(x)
x = TimeDistributed(Dense(CLASS_NUMS))(x)
outputs = CRF(CLASS_NUMS)(x)
model = Model(inputs=inputs, outputs=outputs)
model.summary()
flag = "train"
if flag=="train":
#模型训练
model.compile(loss=crf_loss, optimizer='adam', metrics=[crf_viterbi_accuracy])
model.fit(train_datas, train_labels, epochs=EPOCHS, verbose=1, validation_split=0.1)
score = model.evaluate(test_datas, test_labels, batch_size=BATCH_SIZE)
print(model.metrics_names)
print(score)
model.save("bilstm_ner_model.h5")
else:
#------------------------------------------------------------------------
#第五步 训练模型
#------------------------------------------------------------------------
char_vocab_path = "char_vocabs.txt" #字典文件
model_path = "bilstm_ner_model.h5" #模型文件
ner_labels = {"O": 0, "B-AG": 1, "B-AV": 2, "B-RL": 3,
"B-AI":4, "B-AM": 5, "B-SI": 6, "B-OS": 7 }
special_words = ['<PAD>', '<UNK>']
MAX_LEN = 100
#预测结果
model = load_model(model_path, custom_objects={'CRF': CRF}, compile=False)
y_pred = model.predict(test_datas)
y_labels = np.argmax(y_pred, axis=2) #取最大值
z_labels = np.argmax(test_labels, axis=2) #真实值
word_labels = test_datas #真实值
k = 0
final_y = [] #预测结果对应的标签
final_z = [] #真实结果对应的标签
final_word = [] #对应的特征单词
while k<len(y_labels):
y = y_labels[k]
for idx in y:
final_y.append(idx2label[idx])
z = z_labels[k]
for idx in z:
final_z.append(idx2label[idx])
word = word_labels[k]
for idx in word:
final_word.append(idx2vocab[idx])
k += 1
print("最终结果大小:", len(final_y),len(final_z))
n = 0
numError = 0
numRight = 0
while n<len(final_y):
if final_y[n]!=final_z[n] and final_z[n]!='O':
numError += 1
if final_y[n]==final_z[n] and final_z[n]!='O':
numRight += 1
n += 1
print("预测错误数量:", numError)
print("预测正确数量:", numRight)
print("Acc:", numRight*1.0/(numError+numRight))
print("预测单词:", [idx2vocab[idx] for idx in test_datas_[0]])
print("真实结果:", [idx2label[idx] for idx in test_labels_[0]])
构建的模型如下图所示:

对比实验及调参请读者自行尝试喔,以后有时间再分享调参内容。
七.总结
写到这里这篇文章就结束,希望对您有所帮助,后续将结合经典的Bert进行分享。忙碌的九月、十月,真的很忙,项目本子论文毕业工作,等忙完后好好写几篇安全博客,感谢支持和陪伴,尤其是家人的鼓励和支持, 继续加油!
- 一.ATT&CK数据采集
- 二.数据拆分及内容统计
1.段落拆分
2.句子拆分 - 三.数据标注
- 四.数据集划分
- 五.基于CRF的实体识别
1.安装keras-contrib
2.安装Keras
3.完整代码 - 六.基于BiLSTM-CRF的实体识别
人生路是一个个十字路口,一次次博弈,一次次纠结和得失组成。得失得失,有得有失,不同的选择,不一样的精彩。虽然累和忙,但看到小珞珞还是挺满足的,感谢家人的陪伴。望小珞能开心健康成长,爱你们喔,继续干活,加油!
(By:Eastmount 2023-11-14 夜于贵阳 http://blog.csdn.net/eastmount/ )