Hello,这里是Easy数模!以下idea仅供参考,无偿分享!
题目背景
本题旨在通过对中国特定城市的房产、人口、经济、服务设施等数据进行分析,评估其在应对人口老龄化、负增长趋势和极端气候事件中的韧性与可持续发展能力。主要目标包括未来房价和房屋存量预测、服务水平量化分析、韧性与可持续发展能力评估,以及根据分析结果为城市未来发展提供规划建议。
问题总览
这四个问题可以按不同类型的分析任务进行概括,具体如下:
1. 问题 (1):未来房价预测与房屋存量估计
类型:预测与估计问题
该问题涉及未来趋势的预测(如房价)和当前状态的估计(如房屋存量),可以通过时间序列分析、回归模型等方法进行解决。它关注对未来市场的预测,为后续的城市发展和政策制定提供参考。
2. 问题 (2):服务水平量化分析
类型:聚类分析与特征提取
该问题关注对现有服务水平的聚类以及特征的提取。它主要是一个数据聚类和特征分析问题,涉及到对不同服务设施的覆盖度、密度等指标的计算,并提取城市服务的共性和个性,找到城市在各方面的优势和劣势。
3. 问题 (3):城市韧性和可持续发展能力评估
类型:评估与优化问题
该问题关注城市在极端气候和紧急事件中的韧性表现,以及在可持续发展方面的能力。它属于评估问题,同时包含一定的优化成分(在预算限制下制定投资计划),可通过构建指标体系、建立资源分配模型等方式来量化并优化城市的韧性与可持续发展能力。
4. 问题 (4):未来发展规划
类型:规划与决策问题
该问题要求制定一个未来发展的具体规划,属于决策与规划问题。它基于前面问题的分析结果,进一步明确投资方向、预算和预期成效,为城市的长远发展提供指导性建议。
总结
- 问题 (1):预测与估计
- 问题 (2):聚类分析与特征提取
- 问题 (3):评估与优化
- 问题 (4):规划与决策
题目解析及解题思路
问题 (1):房价预测与房屋存量估计(预测问题)
目标:预测未来房价走势,估算当前房屋存量。
数据来源:
- 已提供的City 1和City 2的房产销售信息数据(附件1和2)
- 可收集的互联网数据(如人口、GDP等)
数据总览
附件1和附件2(两个城市的房产信息):
- 字段:
- Community Number:小区编号
- Price (USD):房价(美元)
- Total number of households:总住户数
- Greening rate:绿化率
- Floor area ratio:容积率
- Building type:建筑类型(多层、中层、高层等)
- Parking space:停车位信息(总数和车位比)
- Property management fee(/m²/month USD):物业管理费
- above-ground/underground parking fee(/month USD):地上/地下停车费
- property type:房产类型
- citycode 和 adcode:城市代码和地区代码
- lon 和 lat:经纬度
- X 和 Y:坐标转换值
数据特征:
- 包含房价、住户数、绿化率、容积率等多维度的房产和小区信息,有助于进行房价预测、服务水平评估以及后续韧性与可持续发展能力分析。
解题思路:
- 数据预处理:清洗并结构化房产数据,提取关键特征如区域、房价、面积等。
- 特征选取:引入人口、GDP、收入水平、城镇化率等影响房价的宏观经济特征。
- 预测模型:
- 时间序列模型:如ARIMA模型,用于预测房价的时间变化趋势。
- 机器学习模型:如多元回归、随机森林或XGBoost模型,通过房产和经济特征变量预测未来房价。
- 房屋存量估计:
- 使用房产销售信息估算当前房屋市场的供给量。
- 结合人口密度和住宅用地面积数据,估算当前房屋存量。
- 如果可以获得历年住房数据,还可基于住房建成率和出售率进行时间动态估算。
可行性挑战:
- 需要补充人口、经济等数据并进行清洗,以保证预测准确性。
- 需要调整模型参数以适应城市不同的区域特征,避免“一刀切”模式。
1. 数据探索性分析
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# Load the data
file_path_1 = '/content/Appendix 1.xlsx'
data_1 = pd.read_excel(file_path_1)
# Display basic information about the data
print("Data Overview:")
print(data_1.info())
# Display basic statistics
print("\nBasic Statistical Information:")
print(data_1.describe())
# Check for missing values
print("\nMissing Values:")
print(data_1.isnull().sum())
# Distribution of 'Price (USD)'
plt.figure(figsize=(10, 6))
sns.histplot(data_1['Price (USD)'].dropna(), kde=True)
plt.title('Distribution of Price (USD)')
plt.xlabel('Price (USD)')
plt.ylabel('Frequency')
plt.show()
# Distribution of 'Total number of households'
plt.figure(figsize=(10, 6))
sns.histplot(data_1['Total number of households'].dropna(), kde=True)
plt.title('Distribution of Total Number of Households')
plt.xlabel('Total number of households')
plt.ylabel('Frequency')
plt.show()
# Distribution of 'Greening rate'
plt.figure(figsize=(10, 6))
sns.histplot(data_1['Greening rate'].dropna(), kde=True)
plt.title('Distribution of Greening Rate')
plt.xlabel('Greening rate')
plt.ylabel('Frequency')
plt.show()
# Relationship between 'Building type' and 'Price (USD)'
plt.figure(figsize=(12, 8))
sns.boxplot(x='Building type', y='Price (USD)', data=data_1)
plt.xticks(rotation=45)
plt.title('Price (USD) Distribution by Building Type')
plt.xlabel('Building type')
plt.ylabel('Price (USD)')
plt.show()
# Relationship between 'Floor area ratio' and 'Price (USD)'
plt.figure(figsize=(10, 6))
sns.scatterplot(x='Floor area ratio', y='Price (USD)', data=data_1)
plt.title('Relationship between Floor Area Ratio and Price (USD)')
plt.xlabel('Floor area ratio')
plt.ylabel('Price (USD)')
plt.show()
# Calculate and visualize the correlation matrix for numeric columns only
plt.figure(figsize=(12, 8))
numeric_data = data_1.select_dtypes(include=['float64', 'int64']) # Select only numeric columns
correlation_matrix = numeric_data.corr()
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm', square=True)
plt.title('Correlation Matrix of Numeric Variables')
plt.show()
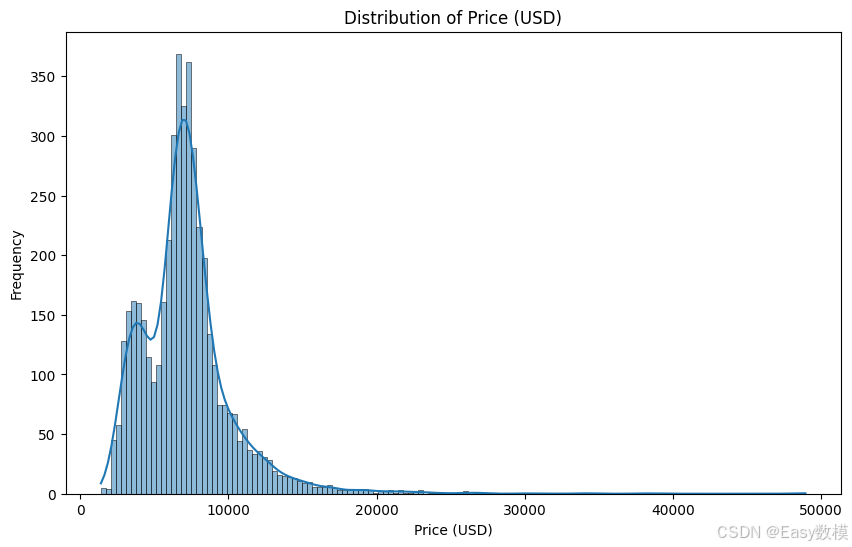
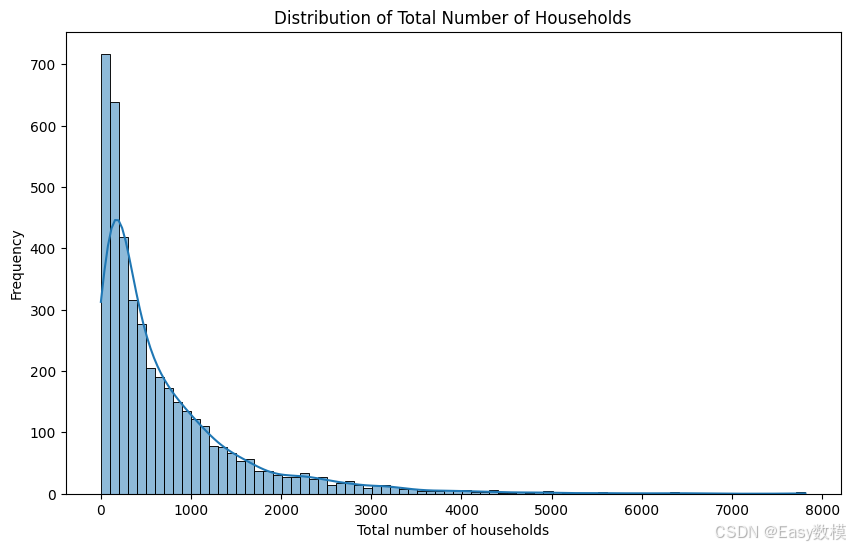
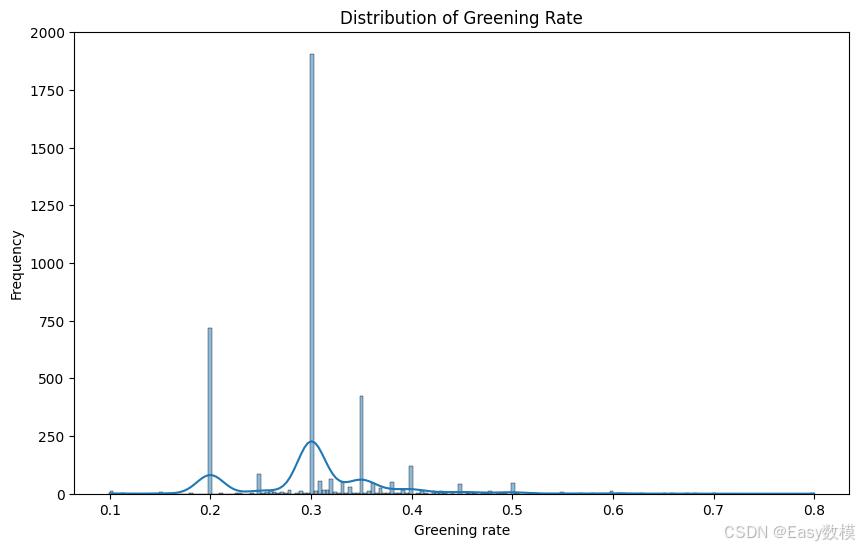
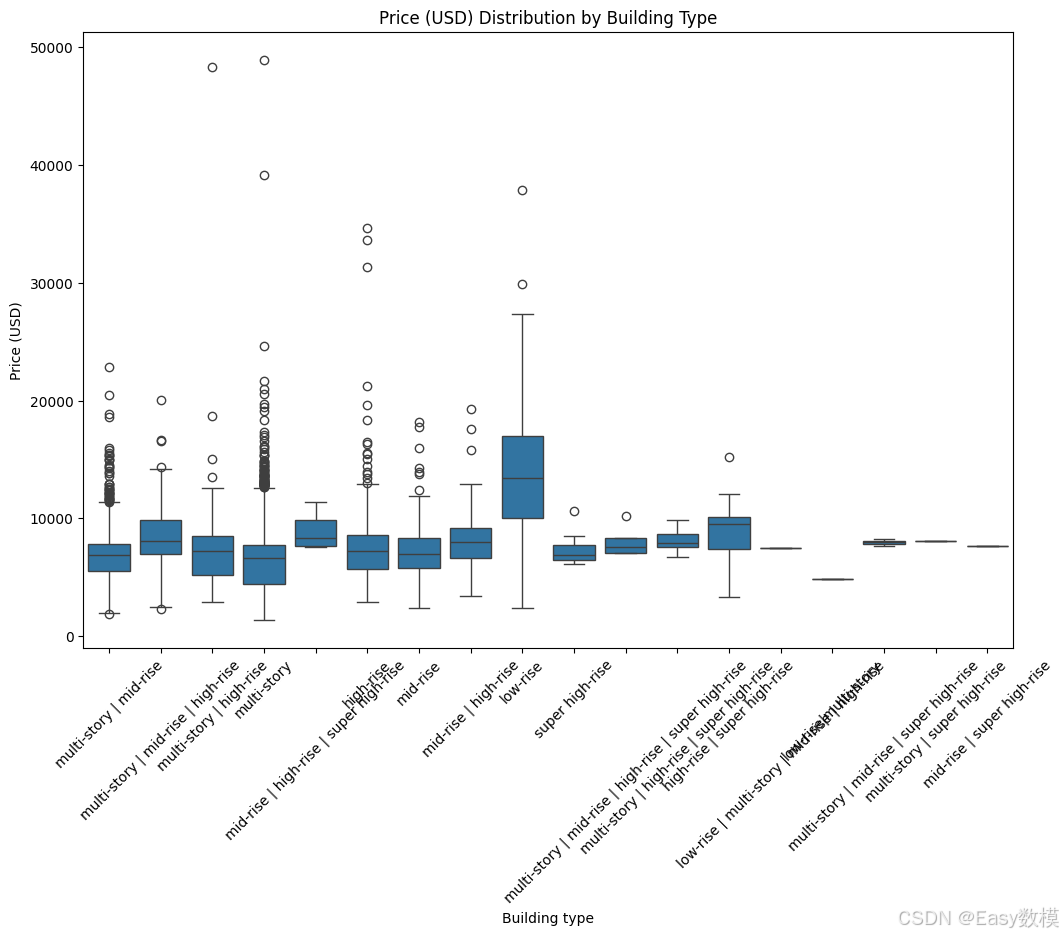
以下是对附件1数据的详细探索性分析结果:
- 房价分布:
- 从房价的分布图中可以看出,房价呈现右偏分布,大部分房价集中在10,000美元以下。这意味着大部分房产的价格处于较为实惠的范围内,但也有少部分房产价格较高(达到30,000美元甚至更高),拉高了整体的价格范围。
- 这种右偏的价格分布表明,在某些区域可能存在少量高端房产,这些房产的价格远高于平均水平。高价房产可能位于市中心、学区房、或是配套设施更完善的区域,从而推高了价格。
- 总体来看,大多数房产的价格集中在5,000至15,000美元之间,可能代表了市场的主流房价水平。
- 总住户数量分布:
- 总住户数量的分布也呈现出右偏,绝大多数小区的住户数较少,主要集中在1,000户以下,但也有少量小区住户数超过4,000户甚至达到7,000户以上。
- 小区住户数量的分布情况可能反映了城市中不同类型住宅区的存在:低住户数的小区可能是小型或低密度住宅区,如独栋住宅、别墅区等,而高住户数的小区可能是大型高密度住宅开发区,如公寓楼群或住宅综合体。
- 这种差异说明该城市的住宅类型多样化,可能存在不同的人群定位和住宅需求。
- 绿化率分布:
- 从绿化率的分布可以看到,大多数房产的绿化率集中在0.2到0.3之间,这可能是由城市规划的标准所决定的,确保住宅区有一定的绿色空间。
- 另外,绿化率在0.5及以上的房产相对较少。这类高绿化率的房产可能集中在生态住宅区、豪华小区或是高端住宅区中,通常这些区域会有更好的绿色环境以提升居住质量。
- 总体来看,绿化率较高的小区可能有更高的市场吸引力,因为绿色空间通常与生活质量的提升相关联。
- 建筑类型与房价的关系:
- 从箱线图中可以看出,不同建筑类型的房价分布差异显著。例如,“超高层”建筑的房价范围最广,价格波动较大,这可能是因为超高层建筑中的楼层位置和景观差异会影响价格,顶层或高层的价格往往较高。
- “多层”和“中层”建筑的房价较为集中且相对较低,表明这些建筑类型可能是普通居民住宅的主流选择,价格较为亲民且较为稳定。
- 此外,建筑类型的多样性也说明了不同人群的需求,例如,家庭可能更倾向于选择低层或中层的多层建筑,而年轻专业人士可能更青睐配套设施更齐全的高层或超高层公寓。
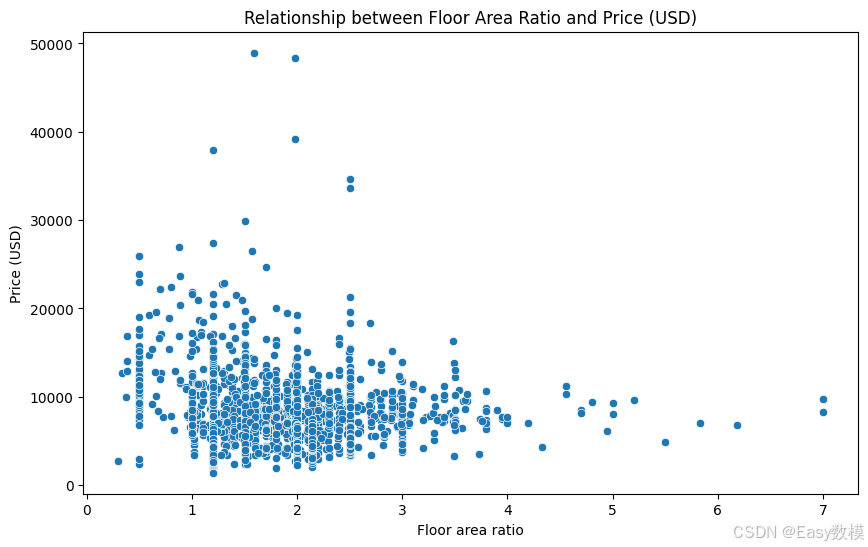
- 容积率与房价的关系:
- 从散点图可以看出,容积率与房价之间存在一定的负相关关系,即容积率越高的房产,房价往往越低。这种关系可以理解为,容积率高的区域往往意味着更高的建筑密度和更少的开放空间,通常与中低端住宅区相关。
- 容积率低的房产通常价格较高,可能是因为低容积率的开发项目往往具有更多的绿色空间、开放视野和更高的生活质量,例如低密度的高档住宅区或别墅区。
- 因此,容积率可以作为房产定位的一个重要参考因素,低容积率的房产可能更适合定位为高端市场,而高容积率的房产适合满足中低收入人群的居住需求。
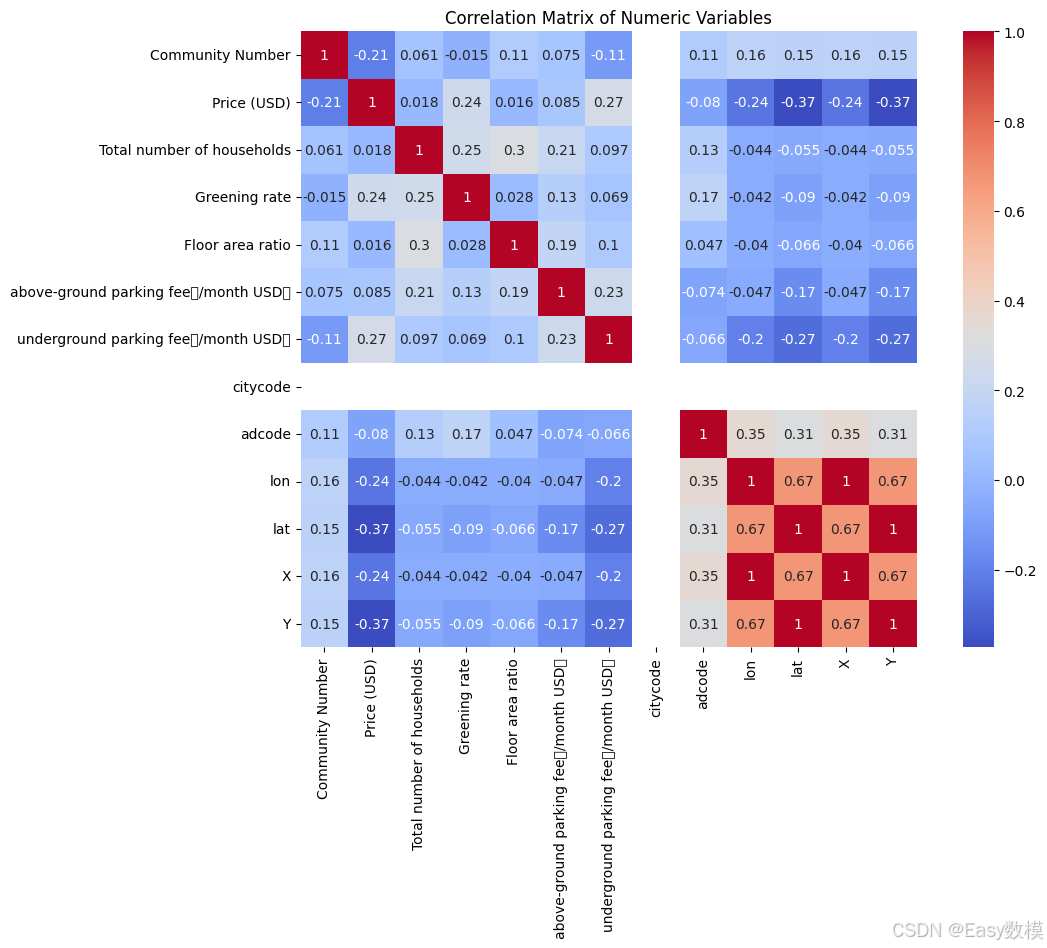
- 相关性矩阵分析:
- 相关性矩阵显示出各变量之间的关系。以下是一些值得注意的相关性:
- 总住户数与地上停车费之间存在一定的正相关性,这表明在住户数较多的小区,停车需求也较大,从而影响停车费用。
- 绿化率与容积率之间存在一定的负相关性,这表明高密度的住宅区往往绿化率较低,而低密度的住宅区有更大的空间用于绿色环境。
- **地理坐标(经纬度)**显示出一些集群性,表明数据中不同房产可能位于不同的地理区域,可以进一步探索其地理位置与房价的关系。
总结
这些探索性分析结果提供了房产市场的整体概况,可以总结出:
- 房价和总住户数量呈现明显的右偏分布。
- 不同建筑类型和容积率对房价有显著影响,反映出不同住宅的市场定位。
- 绿化率和容积率之间的关系揭示了城市规划和住宅质量的关联。
这些见解可以为后续的建模和预测提供基础,尤其是在考虑不同区域、建筑类型和容积率等特征对房价的影响时。
2.数据预处理
- 填充了数值和类别变量的缺失值。
- 提取并转换了停车位信息。
- 转换并填充了物业管理费用。
- 删除了缺失率较高的列。
- 进行了One-Hot编码以便后续建模。
import pandas as pd
import numpy as np
# Load data
file_path_1 = '/content/Appendix 1.xlsx'
data_1 = pd.read_excel(file_path_1)
# Fill missing values
data_1['Price (USD)'].fillna(data_1['Price (USD)'].median(), inplace=True)
data_1['Total number of households'].fillna(data_1['Total number of households'].median(), inplace=True)
data_1['Greening rate'].fillna(data_1['Greening rate'].median(), inplace=True)
data_1['Floor area ratio'].fillna(data_1['Floor area ratio'].median(), inplace=True)
data_1['Building type'].fillna(data_1['Building type'].mode()[0], inplace=True)
data_1['property type'].fillna(data_1['property type'].mode()[0], inplace=True)
# Handle 'parking space' by extracting total spaces and ratio
data_1['Total parking spaces'] = data_1['parking space'].str.extract(r'(\d+)', expand=False).astype(float)
data_1['Parking space ratio'] = data_1['parking space'].str.extract(r'\((1:\d+.\d+)\)', expand=False)
data_1.drop(columns=['parking space'], inplace=True) # Drop the original column
# Handle 'Property management fee(/m²/month USD)' by converting ranges to median
data_1['Property management fee(/m²/month USD)'] = data_1['Property management fee(/m²/month USD)'].apply(
lambda x: np.mean([float(i) for i in str(x).split('-')]) if isinstance(x, str) and '-' in x else x
)
data_1['Property management fee(/m²/month USD)'] = data_1['Property management fee(/m²/month USD)'].astype(float)
data_1['Property management fee(/m²/month USD)'].fillna(data_1['Property management fee(/m²/month USD)'].median(), inplace=True)
# Drop columns with high missing values if necessary
data_1.drop(columns=['underground parking fee(/month USD)'], inplace=True)
# One-Hot Encode categorical variables
data_1 = pd.get_dummies(data_1, columns=['Building type', 'property type'], drop_first=True)
# Check final data
print("Processed Data Types:")
print(data_1.dtypes)
print("\nMissing Values After Processing:")
print(data_1.isnull().sum())
# Convert 'Parking space ratio' to numerical format
data_1['Parking space ratio'] = data_1['Parking space ratio'].str.extract(r'1:(\d+\.\d+)', expand=False).astype(float)
# Fill missing values for remaining columns
data_1['above-ground parking fee(/month USD)'].fillna(data_1['above-ground parking fee(/month USD)'].median(), inplace=True)
data_1['Total parking spaces'].fillna(data_1['Total parking spaces'].median(), inplace=True)
data_1['Parking space ratio'].fillna(data_1['Parking space ratio'].median(), inplace=True)
# Final check for missing values
print("\nFinal Missing Values After Processing:")
print(data_1.isnull().sum())
3.特征工程筛选
进行特征重要性分析和SHAP分析有助于理解各个特征对房价的影响。我们可以使用随机森林回归模型来评估特征重要性,因为随机森林可以自然地输出每个特征对预测结果的重要性。这里将可视化每个特征的重要性。
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
# 分离特征和目标变量
X = data_1.drop(columns=['Price (USD)'])
y = data_1['Price (USD)']
# 分割数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练随机森林模型
model = RandomForestRegressor(random_state=42)
model.fit(X_train, y_train)
# 获取特征重要性
feature_importances = model.feature_importances_
features = X.columns
# 可视化特征重要性
plt.figure(figsize=(10, 8))
plt.barh(features, feature_importances)
plt.xlabel("Feature Importance")
plt.ylabel("Features")
plt.title("Feature Importance Analysis using Random Forest")
plt.show()
根据特征重要性图,我们可以看到一些特征的重要性接近于零或很低,因此可以考虑排除这些对房价预测影响不大的特征,以简化模型,提升计算效率。以下特征可以考虑排除:
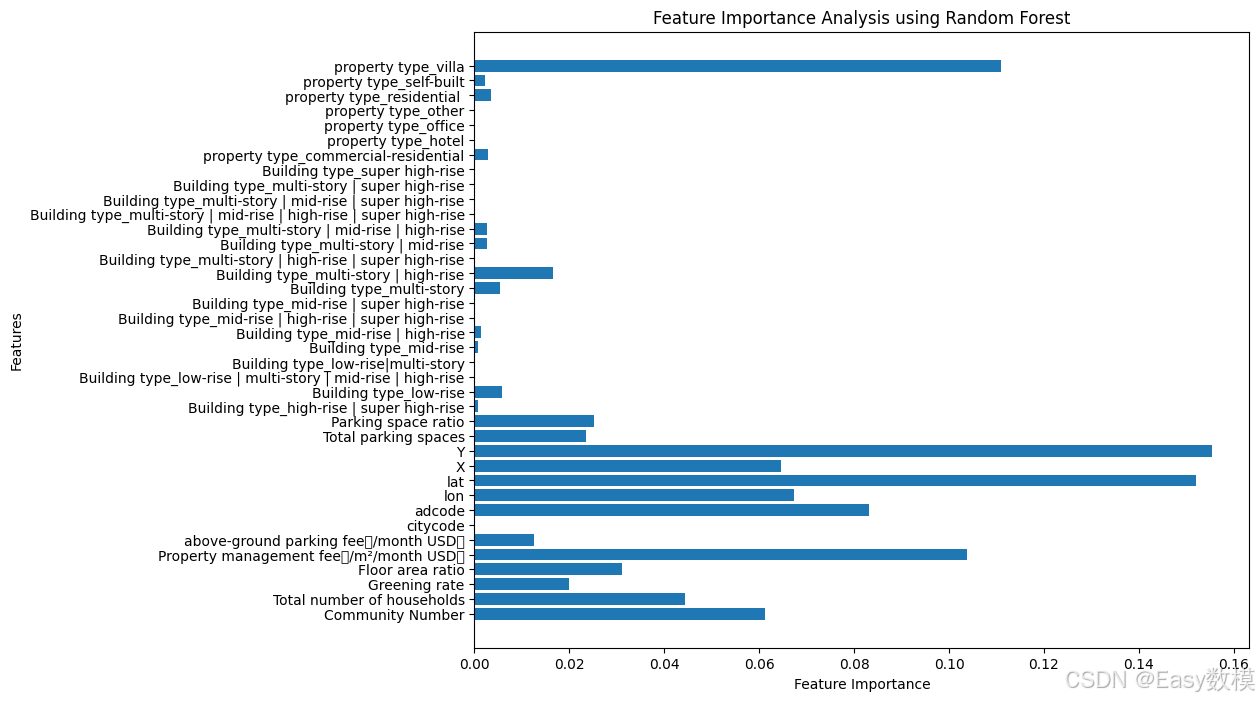
- 建筑类型中的许多组合:例如 Building type_super high-rise、Building type_multi-story | mid-rise | super high-rise 等等,这些类别的特征重要性非常低。
- 物业类型中的部分类别:例如 property type_other、property type_hotel、property type_self-built 等类别对预测影响较小。
- 其他类别变量:citycode、adcode,这些特征对预测的影响也非常小,可以考虑排除。
排除这些变量后,我们可以重新进行SHAP分析,聚焦于对房价预测有显著影响的特征,以便更清晰地理解特征对预测的影响。
import pandas as pd
import numpy as np
import shap
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
# 重新筛选特征,排除不重要的特征
selected_features = data_1.drop(columns=[
'Building type_super high-rise', 'Building type_multi-story | mid-rise | super high-rise',
'Building type_multi-story | mid-rise | high-rise', 'Building type_multi-story | high-rise | super high-rise',
'property type_other', 'property type_hotel', 'property type_self-built',
'citycode', 'adcode'
])
# 分离特征和目标变量
X_selected = selected_features.drop(columns=['Price (USD)'])
y_selected = selected_features['Price (USD)']
# 分割数据集
X_train, X_test, y_train, y_test = train_test_split(X_selected, y_selected, test_size=0.2, random_state=42)
# 训练随机森林模型
model = RandomForestRegressor(random_state=42)
model.fit(X_train, y_train)
# 使用已经训练好的模型进行SHAP值分析
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(X_test)
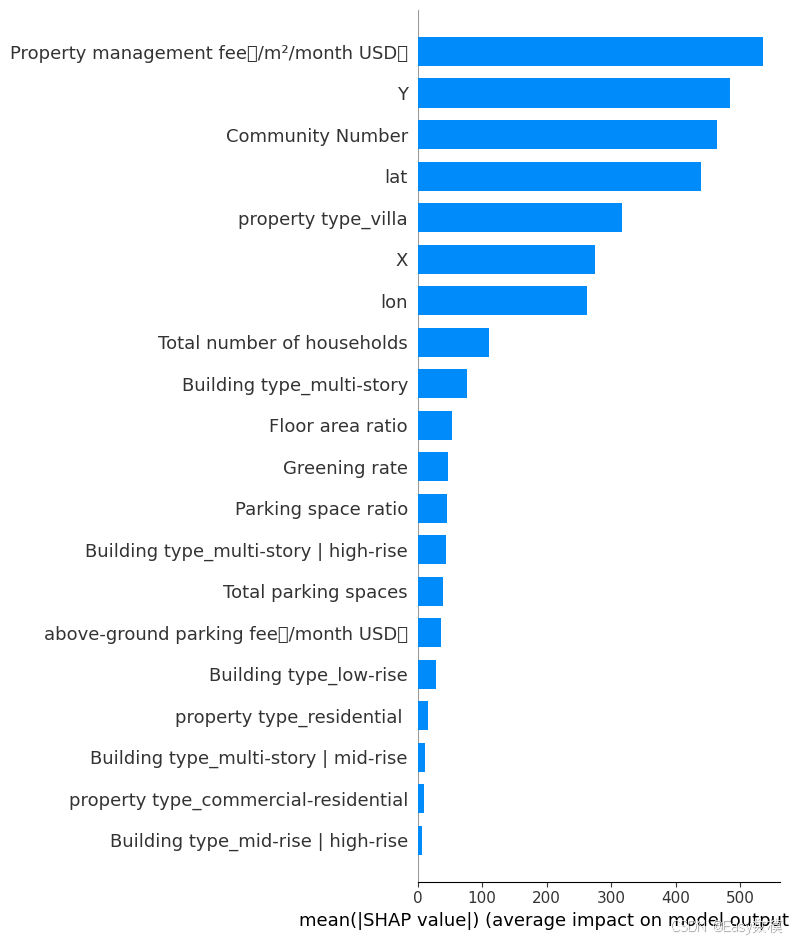
# 可视化SHAP值的整体影响(特征重要性)
plt.figure(figsize=(10, 8))
shap.summary_plot(shap_values, X_test, plot_type="bar")
# 可视化SHAP值的分布(每个特征对预测的影响)
shap.summary_plot(shap_values, X_test)
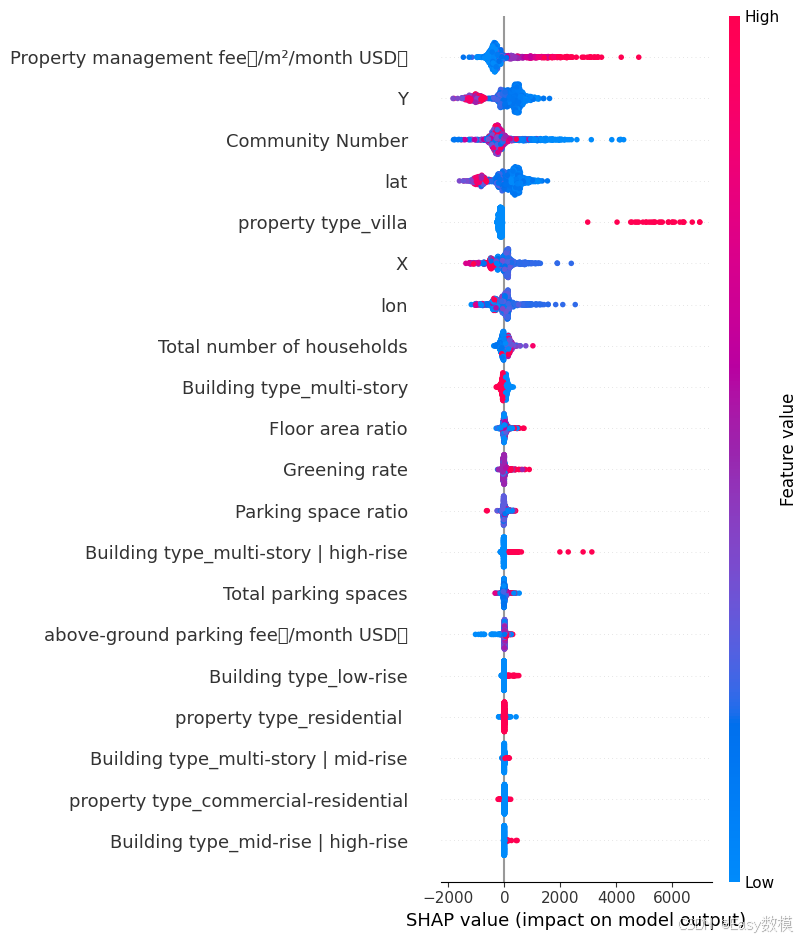
4.预测模型(准备采用之前推文的模型)
等待更新,不早了,先睡了!
问题 (2):服务水平量化分析 (聚类分析)
目标:量化City 1和City 2各行业的服务水平,提取城市的共性和个性特征,分析各自的优势与劣势。
数据来源:
- 附件3和4提供的基本服务POI(Point of Interest)数据。
解题思路:
- POI数据处理:
- 按照POI数据的行业分类(如医疗、教育、公共设施等)进行整理,提取出服务设施的地理分布和数量。
- 服务水平量化指标:
- 设施密度:每个行业的服务设施在特定区域内的密度,反映服务的覆盖率。
- 可达性:基于设施的分布和人口分布,评估居民到达这些服务设施的便捷性(可以使用GIS工具计算)。
- 服务多样性:统计不同类型服务设施的多样性,反映服务的全面性。
- 共性与个性分析:
- 通过聚类分析或主成分分析,对服务设施特征进行降维,识别两城市在服务水平上的共性与差异。
- 优势与劣势:
- 利用得分模型,对比两城市在不同服务领域的表现,找到各自的优势(如教育资源丰富、医疗设施充足)和不足(如缺乏公共娱乐设施等)。
可行性挑战:
- POI数据的完整性和精度会影响分析结果,需确保数据准确性。
- 地理分布分析涉及GIS工具操作,需较强的空间数据处理能力。
问题 (3):城市韧性与可持续发展能力评估(评价问题)
目标:评估两个城市应对极端天气和紧急事件的韧性,量化可持续发展能力,识别具体的弱点及未来投资重点。
数据来源:
- 附件3和4中的POI数据,以及在互联网上获取的有关城市基础设施和气候风险的数据。
解题思路:
- 韧性评估指标:
- 应急响应设施:包括医院、消防站、避难所等数量与分布。
- 基础设施耐久性:评估关键基础设施(如交通、电力、水利设施)的抗风险能力。
- 社会支持网络:例如社区中心、志愿者组织等的数量与活跃度,增强居民在灾害中的自助能力。
- 可持续发展能力量化:
- 建立一套综合指标体系,包括经济、社会和环境维度。
- 计算每个指标的得分,得分越高代表该城市在该指标上的表现越优。
- 短期与长期投资计划:
- 短期投资:主要聚焦在提升基础设施韧性、加强应急响应设施,如增加消防站数量、加强社区防灾教育等。
- 长期投资:关注环境治理、可持续能源和智慧城市建设,制定绿地扩展、公共交通优化等长期规划。
- 财务约束下的优化:
- 使用线性规划或资源分配模型,以“有限资金下最大化韧性与可持续性得分”为目标,合理分配预算。
可行性挑战:
- 需找到适合的韧性评估框架,并调整适应城市实际情况。
- 需要结合外部环境(如经济压力、政策支持),对投资回报进行合理预估。
问题 (4):未来发展规划(规划与决策问题)
目标:根据上述分析结果,制定City 1和City 2的未来发展规划,明确投资方向、金额和预期的智能城市发展提升效果。
解题思路:
- 发展规划框架:
- 将规划分为“基础设施”、“社会服务”、“环境可持续性”、“智能城市建设”四大类,每类明确未来发展方向。
- 投资预算:
- 对各个领域设定具体的投资金额及用途,例如智能交通系统、绿色建筑、智慧医疗设备等。
- 发展效果预测:
- 使用量化指标预测投资后的成效,如基础设施完备度、应急响应时间缩短、服务水平提升等。
- 撰写规划报告:
- 简洁明了地阐述发展规划,确保内容不超过两页,包括城市建设的主要方向、每个领域的投资重点以及对应的预期效果。
可行性挑战:
- 需精简规划内容,确保报告简明扼要。
- 需要合理量化预期效果,便于未来评估成效。