Conv+Transformer=BotNet,这是伯克利、谷歌最新提出的工作BotNet,它充分利用了CNN与自注意力的优势,在ImageNet上取得了84.7%的top1精度,同时文中各种实验分析也相当的详细。
本文首发于极市平台,作者Happy。转载请注明来源。

本文是伯克利与谷歌的研究在Convolution+Transformer组合方面一个探索,它采用混合方式同时利用了CNN的特征提取能力、transformer的内容自注意力与位置自注意力机制,取得了优于纯CNN(如ResNet、EfficientNet)或者自注意力(如ViT、DeiT)的性能。所提方案在ImageNet上取得了84.7%的top1精度;在COCO数据集上,基于MaskR-CNN取得了44.4%的MaskAP与49.7%的BoxAP指标。本文值得对Transformer感兴趣的同学深入研究一番,文中各种实验分析相当的详细。
Abstract
本文提出了一种概念简单但强有力的骨干网络BoTNet,它集成了自注意力机制并用于多个计算机视觉任务(包含图像分类、目标检测、实例分割)。通过简单的采用全局自注意力模块替换ResNet的最后三个Bottleneck模块中的卷积,而无需其他改动即可得到BoTNet,相比baseline,所提方法可以在目标检测与实例分割任务上取得显著的性能提升,同时还可以降低参数量,代价为少量的推理延迟。
通过BoTNet的设计,本文同时指出:带自注意力模块的Bottleneck模块可以视作Transformer模块。无需任何技巧,基于Mask R-CNNN框架,BoTNet在COCO实例分割任务上取得了44.4%的Mask AP与49.7%的Box AP指标,超越了之前由ResNeSt的最佳指标。最后,本文还针对图像分类任务进行了BoTNet的自适应设计,在ImageNet数据集上取得了84.7%的top1精度,同时比EfficientNe快2.33倍(硬件平台为TPU-v3)。
Method
本文的的思路非常简单:采用多头注意力(Multi-Head Self Attention, MHSA)模块替换Bottleneck中的 3 × 3 3\times 3 3×3卷积。而MHSA的结构示意图见下图。
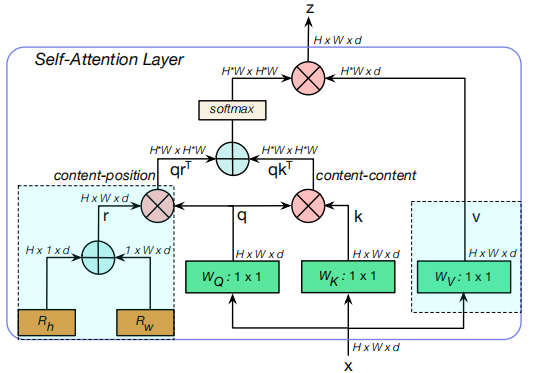
一般来说,ResNet包含4个阶段,即[c2, c3, c4, c5],它们分别对应stride=[4,8,16,32]尺寸的特征。[c2,c3,c4,c5]分别由多个Bottleneck模块构成,比如ResNet50中的数量分别为[3,4,6,3]。ResNet50与BoTNet50的结构信息对比见下表。
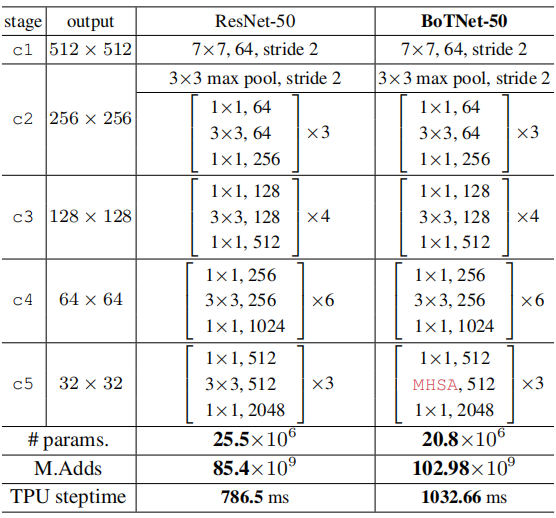
本文与现有自注意力机制方法的一个区别在于:以Vit、SAN等为代表的自注意力机制参与到ResNet的各个阶段的Bottleneck中取了;而BoTNet则只是参与到c5阶段的Bottleneck。为什么会这种设计呢?原因分析如下:
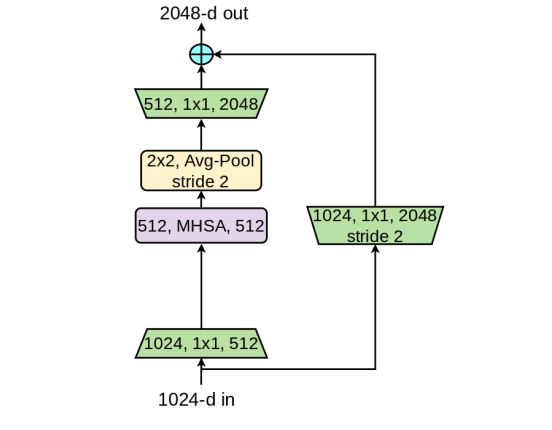
本文的目的是采用注意力提升实例分割模型的性能,而实例分割模块的输入通常比较大(比如 1024 × 1024 1024\times 1024 1024×1024)。考虑到自注意力机制的计算量与内存占用问题,本文采用了上述最简单的配置方式:即旨在最小分辨率特征c5阶段添加自注意力模块。而c5部分只包含3个Bottleneck,每个Bottleneck包含一个 3 × 3 3\times 3 3×3卷积,采用MHSA替换该卷积即可得到本文所涉及的BoTNet。而c5的第一个Bottleneck中的 3 × 3 3\times 3 3×3卷积stride=2,而MHSA模块并不支持stride操作,故而本文词用 2 × 2 2\times 2 2×2均值池化进行下采样。而Stride=2版本的BoT模块则如下图所示。
为更好的使得注意力机制存在位置相关性,基于Transformer的架构引入了Position Encoding。而之前赵恒爽、贾佳亚等人提出的SAN方案已经证实了位置编码在视觉任务中的有效性,故而本文所设计的BoT模块中同样引入了与位置相关的自注意力机制。
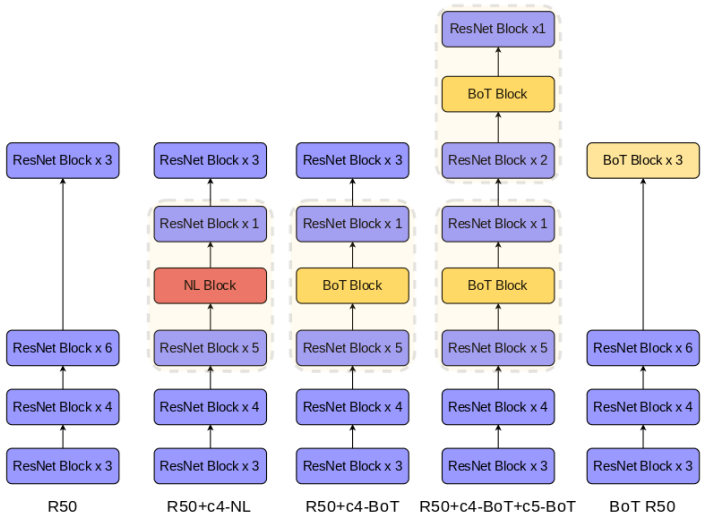
最后,我们附上不同配置的网络架构示意图,见下图。
Experiments
为更好的说明所提方案的有效性,我们在实例分割、目标检测等任务上对其进行了论证。
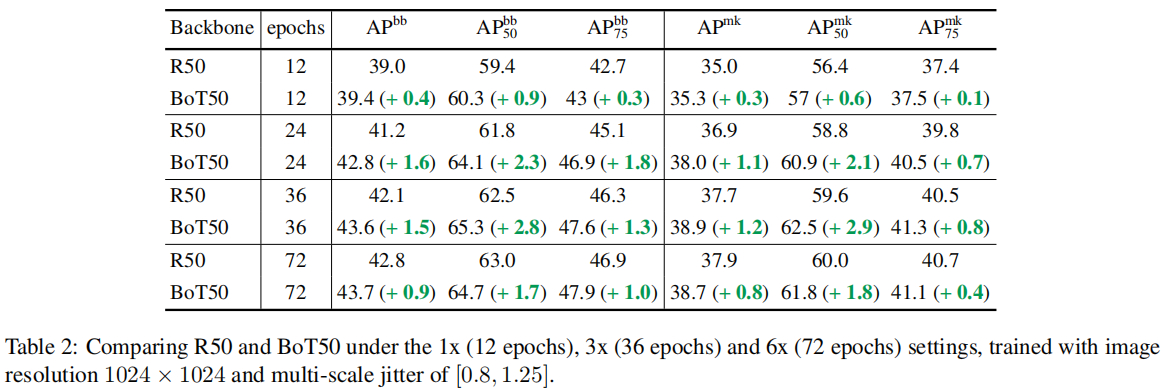
我们先来看一下COCO实例分割上的效果,结果见上表。从上表可以看到:在12epoch训练周期下,相比ResNet50,BoTNet50取得了有效的性能提升;而更长周期的训练可以得到更为显著的性能改善。
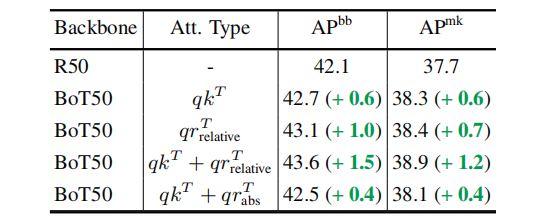
与此同时,为说明位置编码的重要性,本文对其进行了消融实验分析,结果见上表。可以看到:单单内容注意力机制可以取得0.6AP性能提升,而位置注意力机制可以取得1.0AP性能提升;而两者的组合则可以取得1.5AP性能提升。这说明内容与位置注意力具有互补性。
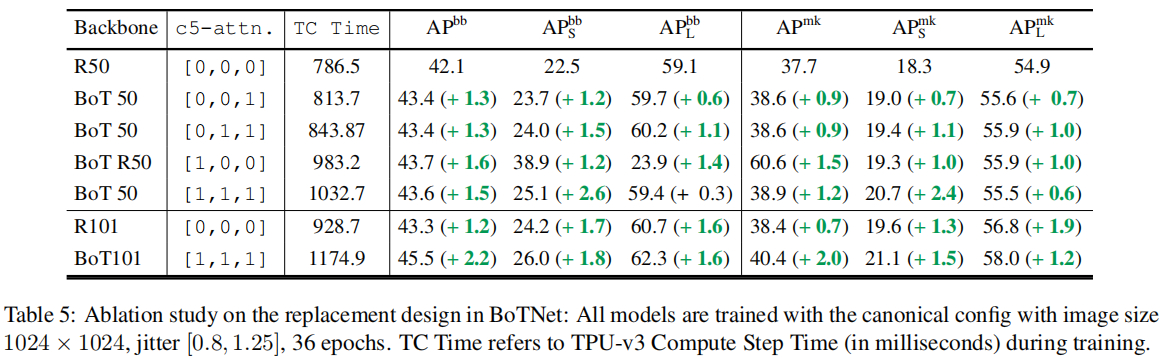
此外,本文还针对“为什么要替换c5中所有Bottleneck的 3 × 3 3\times 3 3×3卷积?”的问题进行消融实验分析,结果见上表。很明显,全部替换带来的性能提升更大,且推理延迟代价很小。通过对比BoT50与BoT101还得出:自注意力机制的替换比堆叠卷积更有效。
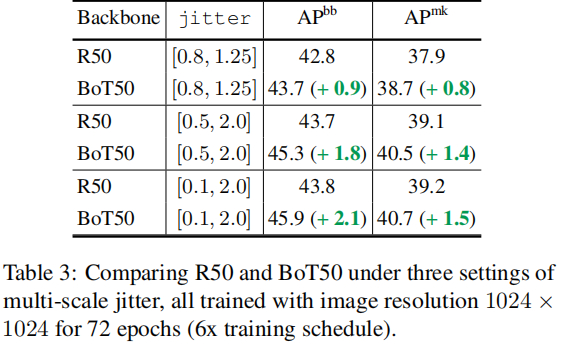
在上述基础上,作者还引入了多尺度jitter配置,可以看到BoT50还可以进一步的加剧性能提升。
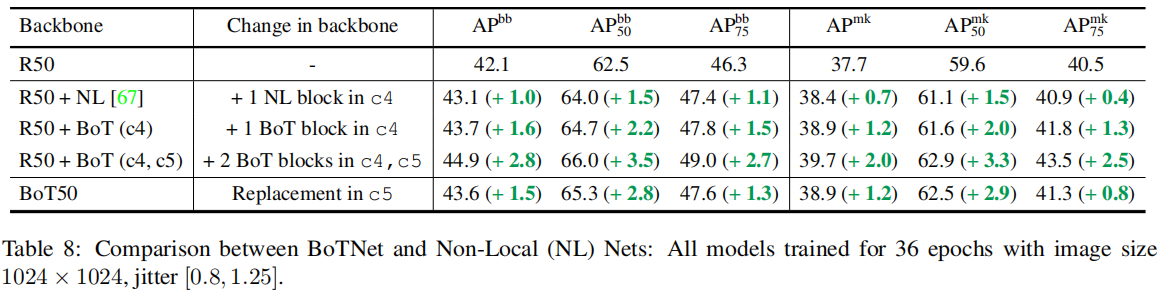
另外,作者还将所提方法与非局部注意力机制进行了对比,结果见上表。可以看到:BoT模块带来的性能提升要比NL模块的提升更大;此外还可以看到:同时替换c4与c5还可以取得进一步的性能提升。
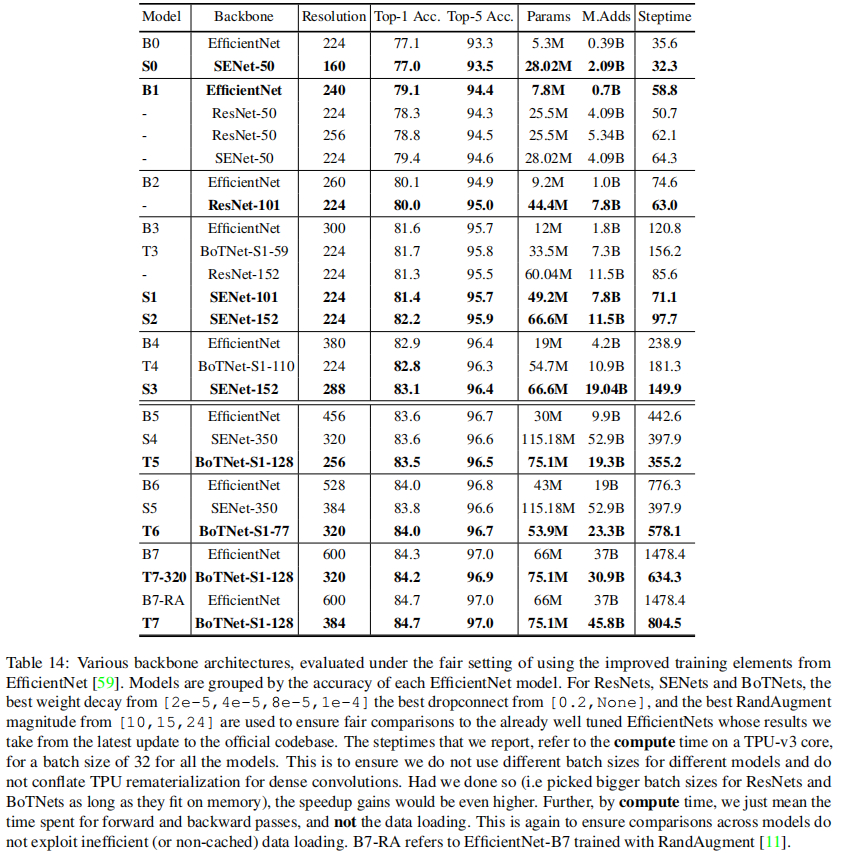
最后,我们再来看一下在图像分类任务上所提方法与其他方案(包含SENet、EfficientNet、ViT、DeiT)的性能对比,结果见上表与下表。可以看到:BoTNet取得了比DeiT-384更好的结果,这说明:混合模型可以同时利用卷积与自注意力的特性,取得优于纯注意力模型的效果。
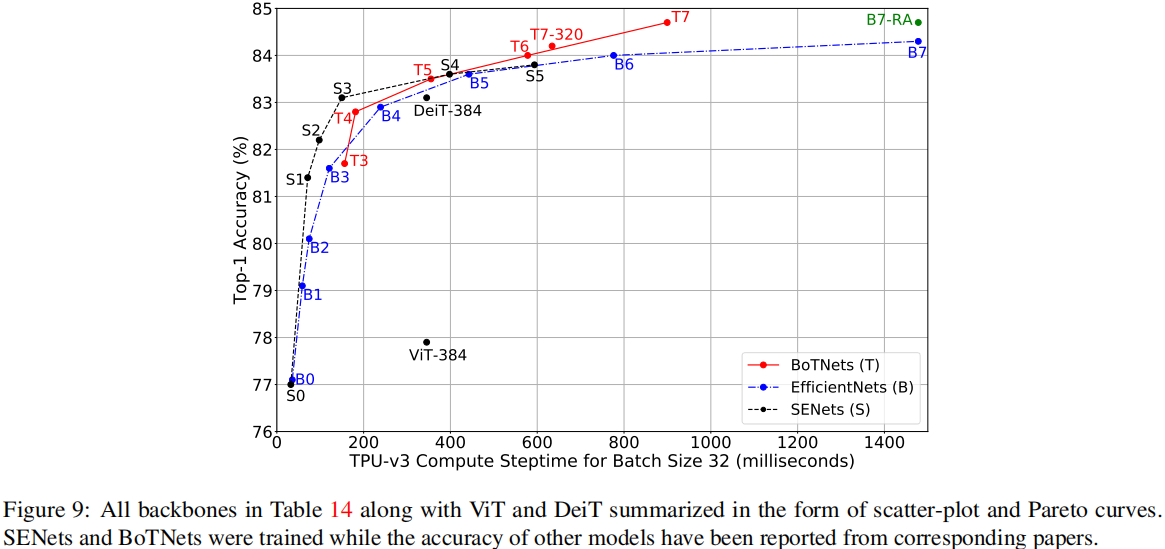
全文到此结束,更多消融实验分析建议查看原文,强烈建议感兴趣的同学去研读一下原文。
Code
另外吐槽一点:本文尚未提供预训练模型,不过作者提供了tensorflow的实现。这里提供一下核心的code,实现如下。
def MHSA(featuremap, pos_enc_type='relative', use_pos=True):
q = group_pointwise(
featuremap, proj_factor=1, name='q_proj', heads=heads,
target_dimension=bottleneck_dimension)
k = group_pointwise(
featuremap, proj_factor=1, name='k_proj', heads=heads,
target_dimension=bottleneck_dimension)
v = group_pointwise(
featuremap, proj_factor=1, name='v_proj', heads=heads,
target_dimension=bottleneck_dimension)
assert pos_enc_type in ['relative', 'absolute']
o = relpos_self_attention(
q=q, k=k, v=v, relative=use_pos, fold_heads=True)
return o
def group_pointwise(
featuremap, proj_factor=1, name='grouppoint',
heads=4, target_dimension=None):
"""1x1 conv with heads."""
with tf.variable_scope(name, reuse=tf.AUTO_REUSE):
in_channels = featuremap.shape[-1]
if target_dimension is not None:
proj_channels = target_dimension // proj_factor
else:
proj_channels = in_channels // proj_factor
w = tf.get_variable(
'w',
[in_channels, heads, proj_channels // heads],
dtype=featuremap.dtype,
initializer=tf.random_normal_initializer(stddev=0.01))
out = tf.einsum('bHWD,Dhd->bhHWd', featuremap, w)
return out
def relative_logits(q):
"""Compute relative position enc logits."""
with tf.variable_scope('relative', reuse=tf.AUTO_REUSE):
bs, heads, h, w, dim = q.shape
int_dim = dim.value
# Note: below, we passed stddev arg as mean for the initializer.
# Providing code as is, with this small error.
# right way: normal_initializer(stddev=int_dim**-0.5)
# Relative logits in width dimension.
rel_emb_w = tf.get_variable(
'r_width', shape=(2*w - 1, dim),
dtype=q.dtype,
initializer=tf.random_normal_initializer(int_dim**-0.5))
rel_logits_w = relative_logits_1d(
q=q, rel_k=rel_emb_w,
transpose_mask=[0, 1, 2, 4, 3, 5])
# Relative logits in height dimension.
rel_emb_h = tf.get_variable(
'r_height', shape=(2*h - 1, dim),
dtype=q.dtype,
initializer=tf.random_normal_initializer(int_dim**-0.5))
rel_logits_h = relative_logits_1d(
q=tf.transpose(q, [0, 1, 3, 2, 4]),
rel_k=rel_emb_h,
transpose_mask=[0, 1, 4, 2, 5, 3])
return rel_logits_h + rel_logits_w
def relpos_self_attention(
*, q, k, v, relative=True, fold_heads=False):
"""2D self-attention with rel-pos. Add option to fold heads."""
bs, heads, h, w, dim = q.shape
int_dim = dim.value
q = q * (dim ** -0.5) # scaled dot-product
logits = tf.einsum('bhHWd,bhPQd->bhHWPQ', q, k)
if relative:
logits += relative_logits(q)
weights = tf.reshape(logits, [-1, heads, h, w, h * w])
weights = tf.nn.softmax(weights)
weights = tf.reshape(weights, [-1, heads, h, w, h, w])
attn_out = tf.einsum('bhHWPQ,bhPQd->bHWhd', weights, v)
if fold_heads:
attn_out = tf.reshape(attn_out, [-1, h, w, heads * dim])
return attn_out
下载
在极市平台公众号回复“BoTNet”,即可获得论文与code下载链接(注:暂无预训练模型):
