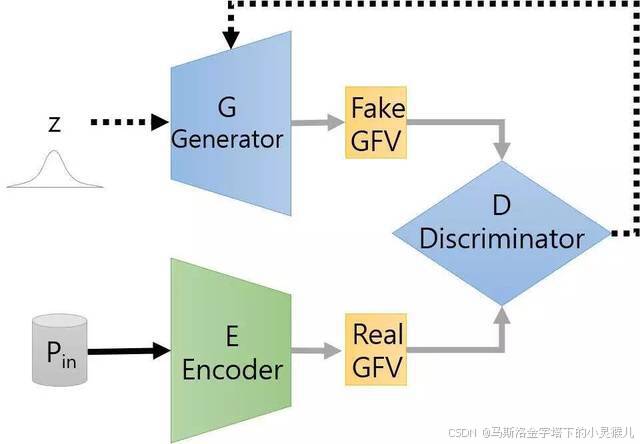
⽣成对抗⽹络(Generative Adversarial Network,简称GAN)是⾮监督式学习的⼀种⽅法,通过两个神经⽹络相互博弈的⽅式进⾏学习。 其本质是从数据分布上模仿另⼀批数据体。
论⽂地址:https://arxiv.org/pdf/1406.2661.pdf
系统组成:⽣成器 (⽣成)、鉴别器 (对抗)
鉴别器 和 ⽣成器 可以根据数据特点进⾏设计。
训练过程
1. 准备要模仿对象的数据;
2. 定义模型:定义⽣成器模型和鉴别器模型(⼆分类模型);
3. 训练模型:同时训练⽣成器和鉴别器。
GAN⽹络的核⼼思想
G:⽣成
⽣成器 ---> 模拟/⽣成样本 (本质上,只是在对⼝型!)
输⼊⼀个噪声
输出⼀个样本
D:鉴别
鉴别器 --> 判定是真样本还是假的样本 (⼆分类任务)
A:对抗 — 对抗训练
鉴别器的训练⽬标:
规规矩矩的⼆分类
鉴别真假
给我真样本,那就输出真
给我假样本,那就输出假
输⼊:
从数据集中获取的样本 --> 真
通过⽣成器⽣成的样本 --> 假
损失:交叉熵
⽣成器的训练⽬标:
骗过鉴别器
⾃⼰⽣成的样本,让鉴别器觉得是真的
训练过程:
输⼊:噪声
输出:样本(假)
损失:
把⽣成的样本给鉴别器,得到鉴别器的输出
损失就是衡量鉴别器的输出跟真标签之间的差距
在训练鉴别器时,⽣成器只是正向传播,⽣成器不应该参与训练
在训练⽣成器时,鉴别器只是正向传播,鉴别器不应该参与训练
对抗:踩在对⽅的肩上,提升⾃⼰
GAN代码流程
import torch
from torch import nn
from torch.nn import functional as F
from torchvision import datasets
from torchvision import transforms
from torch.utils.data import DataLoader
from matplotlib import pyplot as plt
from matplotlib import gridspec
import numpy as np
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
from IPython import display
# 判断是否有GPU
device = "cuda:0" if torch.cuda.is_available() else "cpu"
#1. 准备数据(模仿对象、真品)
"""
加载数据
- 模仿的对象
- 真品
"""
data = datasets.MNIST(root="data",
train=True,
transform = transforms.Compose(transforms=[transforms.ToTensor(),
transforms.Normalize(mean=[0.5], std=[0.5])]),
download=True)
# 封装成 DataLoader
data_loader = DataLoader(dataset=data, batch_size=100, shuffle=True)
#2. 定义⽣成器模型
"""
定义⽣成器
"""
class Generator(nn.Module):
"""
定义⼀个图像⽣成
输⼊:⼀个向量
输出:⼀个向量(代表图像)
"""
def __init__(self, in_features=100, out_features=28 * 28):
"""
挂载超参数
"""
# 先初始化⽗类,再初始化⼦类
super(Generator, self).__init__()
self.in_features = in_features
self.out_features = out_features
# 第⼀个隐藏层
self.hidden0 = nn.Linear(in_features=self.in_features, out_features=256)
# 第⼆个隐藏层
self.hidden1 = nn.Linear(in_features=256, out_features=512)
# 第三个隐藏层
self.hidden2 = nn.Linear(in_features=512, out_features=self.out_features)
def forward(self, x):
# 第⼀层 [b, 100] --> [b, 256]
h = self.hidden0(x)
h = F.leaky_relu(input=h, negative_slope=0.2)
# 第⼆层 [b, 256] --> [b, 512]
h = self.hidden1(h)
h = F.leaky_relu(input=h, negative_slope=0.2)
# 第三层 [b, 512] --> [b, 28 * 28]
h = self.hidden2(h)
# 压缩数据的变化范围
o = torch.tanh(h)
return o
generator = Generator()
X = torch.randn(2,100)
y = generator(X) # [2,784]
y.veiw(2,1,28,28)
#3. 定义鉴别器(⼆分类分类器)
"""
定义⼀个鉴别器
"""
class Discriminator(nn.Module):
"""
本质:⼆分类分类器
输⼊:⼀个对象
输出:真品还是赝品
"""
def __init__(self, in_features=28*28, out_features=1):
super(Discriminator, self).__init__()
self.in_features=in_features
self.out_features=out_features
# 第⼀个隐藏层
self.hidden0= nn.Linear(in_features=self.in_features, out_features=512)
# 第⼆个隐藏层
self.hidden1= nn.Linear(in_features=512, out_features=256)
# 第三个隐藏层
self.hidden2= nn.Linear(in_features=256, out_features=32)
# 第四个隐藏层
self.hidden3= nn.Linear(in_features=32, out_features=self.out_features)
def forward(self, x):
# 第⼀层
h = self.hidden0(x)
h = F.leaky_relu(input=h, negative_slope=0.2)
h = F.dropout(input=h, p=0.2)
# 第⼆层
h = self.hidden1(h)
h = F.leaky_relu(input=h, negative_slope=0.2)
h = F.dropout(input=h, p=0.2)
# 第三层
h = self.hidden2(h)
h = F.leaky_relu(input=h, negative_slope=0.2)
h = F.dropout(input=h, p=0.2)
# 第四层
h = self.hidden3(h)
# 输出概率
o = torch.sigmoid(h)
return o
discriminator = Discriminator(in_features=28*28, out_features=1)
X = torch.randn(2,28*28) # 2个样本输⼊
discriminator(X) # 输出为2个样本为真都概率
#4. 定义辅助函数
"""
获取数据的标签
"""
def get_real_data_labels(size):
"""
获取真实数据的标签:!
"""
labels = torch.ones(size, 1, device=device)
return labels
def get_fake_data_labels(size):
"""
获取虚假数据的标签:0
"""
labels = torch.zeros(size, 1, device=device)
return labels
"""
噪声⽣成器
"""
def get_noise(size):
"""
给⽣成器准备数据
- 100维度的向量
"""
X = torch.randn(size, 100, device=device)
return X
#5. 训练过程
"""
定义优化器
"""
# 定义⼀个⽣成器的优化器
g_optimizer = torch.optim.Adam(params=generator.parameters(), lr=1e-4)
# 定义⼀个鉴别的优化器
d_optimizer = torch.optim.Adam(params=discriminator.parameters(), lr=1e-4)
"""
定义⼀个损失函数
"""
loss_fn = nn.BCELoss() # ⼆分类交叉熵
# 定义训练轮次
num_epochs = 1000
# 获取⼀批测试数据, 可以⽤来监测训练效果
num_test_samples = 16
test_noise = get_noise(num_test_samples)
"""
训练过程
"""
for epoch in range(1, num_epochs+1):
print(f"当前正在进⾏ 第 {epoch} 轮 ....")
# 设置训练模式
generator.train()
discriminator.train()
# 遍历真实的图像
for batch_idx, (batch_real_data, _) in enumerate(data_loader):
# 1, 先训练鉴别器
# 1.1 准备数据
# 图像转向量 [b, 1, 28, 28] ---> [b, 784]
real_data = batch_real_data.view(batch_real_data.size(0), -1).to(device=device)
noise = get_noise(real_data.size(0))
fake_data = generator(noise).detach()
# 1.2 训练过程
# 鉴别器的优化器梯度清空
d_optimizer.zero_grad()
# 对真实数据鉴别
real_pred = discriminator(real_data)
# 计算真实数据的误差
real_loss = loss_fn(real_pred, get_real_data_labels(real_data.size(0)))
# 真实数据的梯度回传
real_loss.backward()
# 对假数据鉴别
fake_pred = discriminator(fake_data)
# 计算假数据的误差
fake_loss = loss_fn(fake_pred, get_fake_data_labels(fake_data.size(0)))
# 假数据梯度回传 (第⼆次梯度回传,会将梯度累加)
fake_loss.backward()
# 梯度更新
d_optimizer.step()
# print(f"鉴别器的损失:{real_loss + fake_loss}")
# 2, 再训练⽣成器
# 获取⽣成器的⽣成结果
fake_pred = generator(get_noise(real_data.size(0)))
# ⽣产器梯度清空
g_optimizer.zero_grad()
# 把假数据让鉴别器鉴别⼀下
d_pred = discriminator(fake_pred)
# 计算损失
g_loss = loss_fn(d_pred, get_real_data_labels(d_pred.size(0)))
# 梯度回传
g_loss.backward()
# 参数更新
g_optimizer.step()
# print(f"⽣成器误差:{g_loss}")
# 每训练⼀轮,查看⽣成器的效果
generator.eval()
with torch.no_grad():
# 正向推理
img_pred = generator(test_noise)
img_pred = img_pred.view(img_pred.size(0), 28, 28).cpu().data
# 画图
display.clear_output(wait=True)
# 设置画图的⼤⼩
fig = plt.figure(1, figsize=(12, 8))
# 划分为 4 x 4 的 ⽹格
gs = gridspec.GridSpec(4, 4)
# 遍历每⼀个
for i in range(4):
for j in range(4):
# 取每⼀个图
X = img_pred[i * 4 + j, :, :]
# 添加⼀个对应⽹格内的⼦图
ax = fig.add_subplot(gs[i, j])
# 在⼦图内绘制图像
ax.matshow(X, cmap=plt.get_cmap("Greys"))
# ax.set_xlabel(f"{label}")
ax.set_xticks(())
ax.set_yticks(())
plt.show()