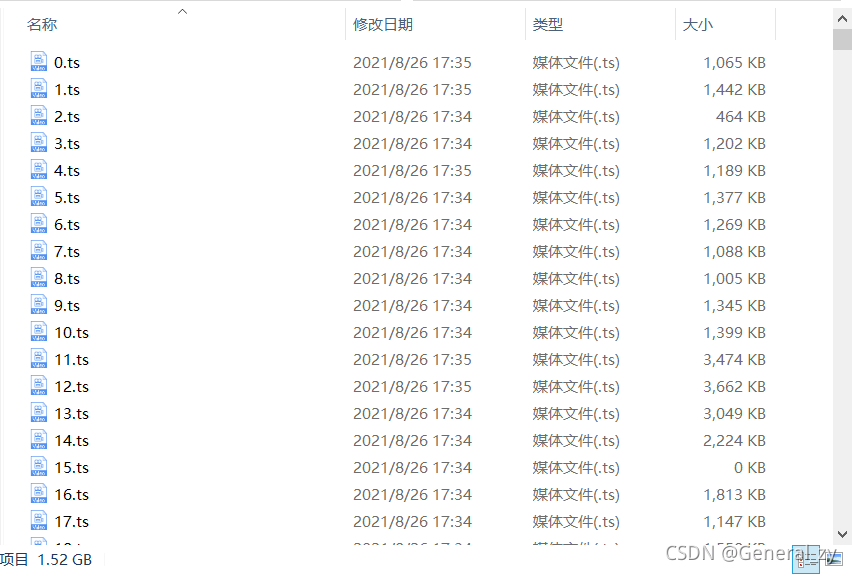
影视作品存储格式
- 网页中的小视频往往以
<video src="#"></video>存在,拿到src中的视频地址即可下载;
- 大视频如电视剧,电影则先由厂商转码做清晰度处理,然后再进行切片,每片只有几秒钟,视频的播放顺序一般存储在m3u8文件中;

爬取方法
- 爬取m3u8文件;
- 根据m3u8文件爬取视频;
- 合并视频;
实际操作
以91看剧网的《名侦探柯南》电影迷宫的十字路口为例子!
- 查看页面源码找到包含m3u8的信息(有坑)
- 抓包工具找到的m3u8接口
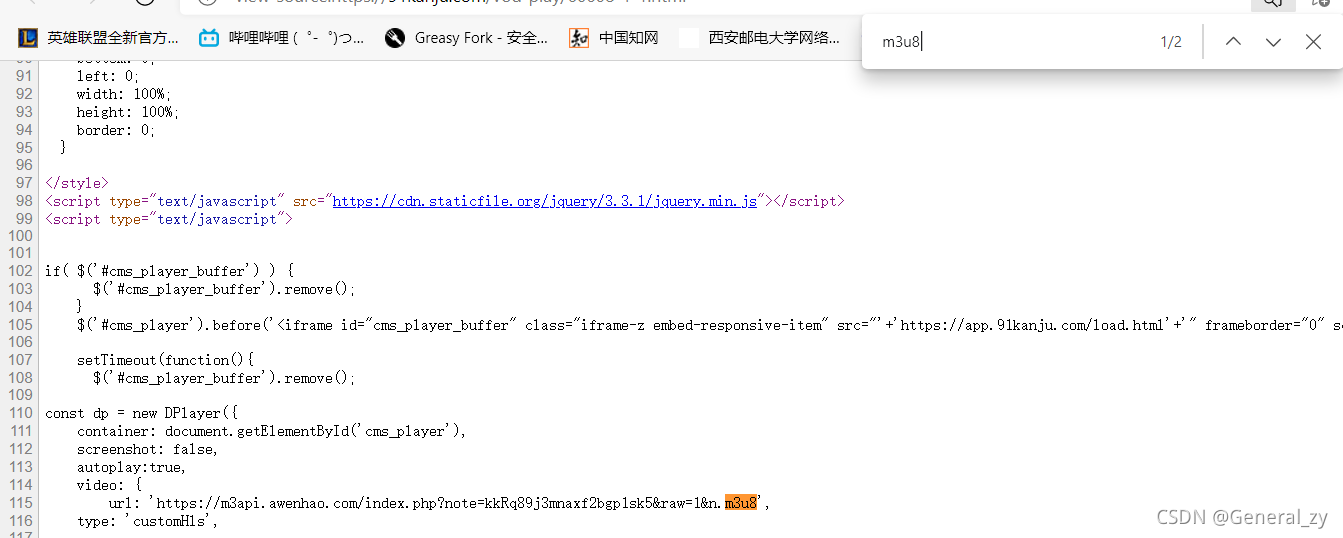

https://m3api.awenhao.com/index.php?note=kkRq89j3mnaxf2bgp1sk5&raw=1&n.m3u8
https://m3api.awenhao.com/index.php?note=kkRpk9hzr2ay6g75et8nd&raw=1&n.m3u8
note是服务端生成随机码,且具有过期时间;
所以需要先爬取页面源码,再正则筛选生成的m3u8接口url;
- 获取m3u8
import requests
import os
# 正则匹配
re_obj = re.compile(r"url: '(?P<url>.*?)',", re.S)
url = 'https://91kanju.com/vod-play/60608-1-1.html'
res1 = requests.get(url, headers=headers)
m3u8_url = re_obj.search(res.text).group('url')
res1.close()
# 下载m3u8文件
if not os.path.exists('./m3u8D'):
os.mkdir('./m3u8D')
res2 = requests.get(url=m3u8_url, headers=headers)
with open('./m3u8D/名侦探柯南.m3u8', 'wb') as f:
f.write(res2.content)
res2.close()
- 根据m3u8中的视频url进行爬取
def get_url():
urls = []
with open('./m3u8D/名侦探柯南.m3u8', 'r', encoding='utf-8') as f:
for line in f:
# 去掉空格,换行符
line = line.strip()
# 去掉以#开头的行
if line.startswith('#'):
continue
urls.append(line)
return urls
def task(url, n):
res3 = requests.get(url=url,headers=headers)
with open('./m3u8D/%s.ts' % n, 'wb') as f:
f.write(res3.content)
if __name__ == '__main__':
url_list = get_url()
with ThreadPoolExecutor(30) as t:
for n, url in enumerate(url_list):
t.submit(task,url=url,n=n)
print('ok')
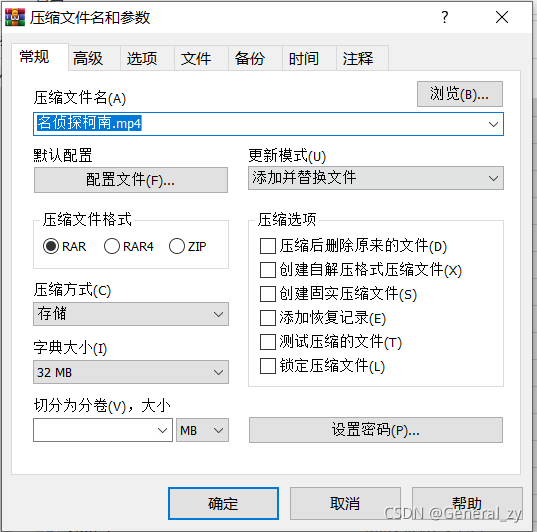
- 合并ts文件
文件名后缀改为.mp4
压缩方式改为存储