目录
Introduction
LLM的限制
大型语言模型,比如ChatGpt4,尽管已经非常强大,但是仍然存在一些限制:
- 知识更新:LLM的知识是基于训练数据的,者意味着,一旦训练完毕,模型的知识就固定下来不能再进行更新。
- 理解深度:虽然LLM可以生成准确的、上下文相关的文本,但它们并不能理解这些文本的深层含义,知识基于它们在大量文本数据上的训练来模仿人类的语言。
- 事实准确性:LLM可能会生成一些事实上不准确的信息,因为它们的目标是预测下一个词是什么,而不是确保生成的所有信息都是准确的。
- 偏见和公平性问题:LLM可能会反映出其训练数据中的偏见。
例如,某红书📕的模型可以归纳总结一些旅游、美食攻略,但有时候由于某些用户的思想特殊性也会出现一些*拳言论,微博同理。X中文区的数据则更离谱,容易出现一些触犯“底线”的言论。 - 生成恶意内容的风险:LLM可以被用来生成深度伪造内容(如windows激活码)或者恶意信息(如钓鱼邮件),从而被用于网络攻击、欺诈或者误导信息的传播。
扩展理解:什么是机器学习
举一个小例子,我以前特别喜欢玩一款叫作《梦幻西游》的游戏。弃坑之后,游戏方的客服经理总给我打电话,说 “Y哥能不能回来接着玩耍(充值)呀,帮派的小伙伴都十分想念你……”。这时候我就想:他们为什么会给我打电话呢?这款游戏每天都有用户流失,不可能给每个用户都打电话吧,那么肯定是挑重点用户来沟通了。 其后台肯定有玩家的各种数据,例如游戏时长、充值金额、战斗力等,通过这些数据就可以建立一个模型, 用来预测哪些用户最有可能返回来接着玩(充钱)!
机器学习要做的就是在数据中学习有价值的信息,例如先给计算机一堆数据,告诉它这些玩家都是重点客户,让计算机去学习一下这些重点客户的特点,以便之后在海量数据中能快速将它们识别出来。
机器学习能做的远不止这些,数据分析、图像识别、数据挖掘、自然语言处理、语音识别等都是以其为 基础的,也可以说人工智能的各种应用都需要机器学习来支撑。现在各大公司越来越注重数据的价值,人工成本也是越来越高,所以机器学习也就变得不可或缺了。(AI First —— Data First)

扩展阅读:机器学习的流程
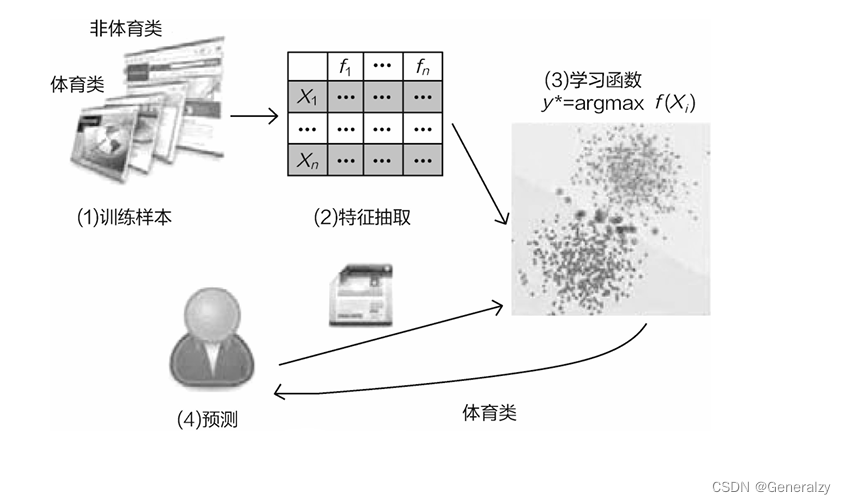
假设我们从网络上收集了很多新闻,有的是体育类新闻,有的是非 体育类新闻,现在需要让机器准确地识别出新闻的类型。
一般来说,机器学习流程大致分为以下几步。
-
数据收集与预处理。例如,新闻中会掺杂很多特殊字符和广告等无关因素,要先把这些剔除掉。除此之外,可能还会用到对文章进行分词、提取关键词等操作。
-
特征工程,也叫作特征抽取。例如,有一段新闻,描述"科比(牢大)职业生涯画上圆满句号,今天正式退役了”。显然这是一篇与体育相关的新闻,但是计算机可不认识牢大,所以还需要将人能读懂的字符转换成计算机能识别的数值。这一步看起来容易,做起来就非常难了,如何构造合适的输入特征也是机器学习中非常重要的一部分。
-
模型构建。这一步只要训练一个分类器即可,当然,建模过程中还会涉及很多调参工作,随便建立一个差不多的模型很容易,但是想要将模型做得完美还需要大量的实验。
-
评估与预测。最后,模型构建完成就可以进行判断预测,一篇文章经过预处理再被传入模型中, 机器就会告诉我们按照它所学数据得出的是什么结果。
LangChain
综上所述,LangChain就是帮助我们引导、规范AI,完成一系列复杂的应用任务,以及通过工具整合来填补LLM各种缺陷的一个框架!!
比如,知识准确性不够就可以接入搜索引擎或新闻站点或知识百科以获取最新资讯;
比如,理解的深度不够,就提供一个思维链(Chain),一步一步引导AI完成整个思维过程的推导(Agent);

安装langChain
执行pip install langchain将安装纯LangChain。
LangChain 的很多价值在于将其与各种模型提供程序、数据存储等集成。默认情况下,未安装执行此操作所需的依赖项,需要单独安装特定集成的依赖项。
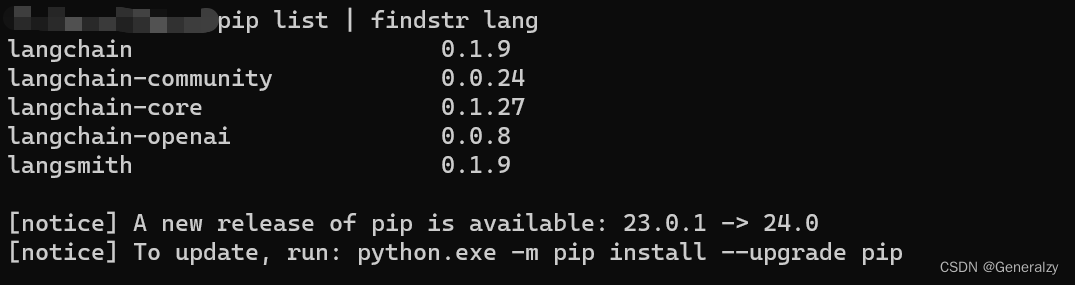
安装完成就可以看到langChain相关的包了(以下的包都会由langChain自动安装依赖):
第一个langChain程序
首先需要导入LangChain OpenAI集成包,可以执行命令安装:pip install langchain-openai
然后可以初始化模型(Openai官网给新注册账号提供为期一周的5$免费额度,我的已经用完了,所以使用微软提供的AzureOpenai):
from langchain_openai import AzureChatOpenAI
from langchain.schema import SystemMessage, HumanMessage
chat = AzureChatOpenAI(
openai_api_key="your api-key",
openai_api_version="your api-version",
azure_endpoint="your azure-endpoint",
deployment_name="your model",
temperature=0.5,
)
然后向ai提问:
# 手动调用并且自己拼接AI的上次回答作为下次的输入以保持上下文
msg = chat.invoke(input=[
# prompt
SystemMessage("你是一个点餐机器人"),
# question
HumanMessage("我喜欢西红柿,你们有什么?"),
# AI回答
AIMessage("我们有很多菜品含有西红柿,比如番茄炒蛋、西红柿牛肉、番茄鸡蛋面等等。我推荐你点番茄炒蛋"),
# 再次提问
HumanMessage("好的,多少钱呢?")
])
# 得到一个Message类型的结果
# AIMessage
print(msg)
如此便使用langChain实现了最简单的模型调用。

Prompt Engineering(PE)(提示工程)
Prompt Engineering 是一种人工智能(AI)技术,它通过设计和改进 AI 的 prompt 来提高 AI 的表现。 Prompt Engineering 的目标是创建高度有效和可控的 AI 系统,使其能够准确、可靠地执行特定任务。Prompt工程即指针对于Prompt进行结构、内容等维度进行优化的AI技术,它把大模型的输入限定在了一个特定的范围之中,进而更好地控制模型的输出。
Prompt工程的作用,就是通过提供清晰和具体的指令,引导模型输出生成高相关、高准确且高质量的文本对答内容,属于自然语言处理领域突破的重要工程。
简单的理解prompt就是给 AI 模型的指令。
它可以是一个问题、一段文字描述,甚至可以是带有一堆参数的文字描述。AI 模型会基于 prompt 所提供的信息,生成对应的文本,亦或者图片。
比如,在 ChatGPT 里输入 What is the capital of China? (中国的首都是什么?),这个问题就是 prompt。
你可能用过不少 AI 相关的产品,你或许会觉得好像只需要会说话、会打字,就能让 AI 输出答案。好像不需要什么技术。
的确,如果你只想让 AI 给你答案,你不需要额外做什么,只需要输入文字即可。但如果你想要得到满意的答案,甚至精确的答案,就需要用到 PE 这个技术。
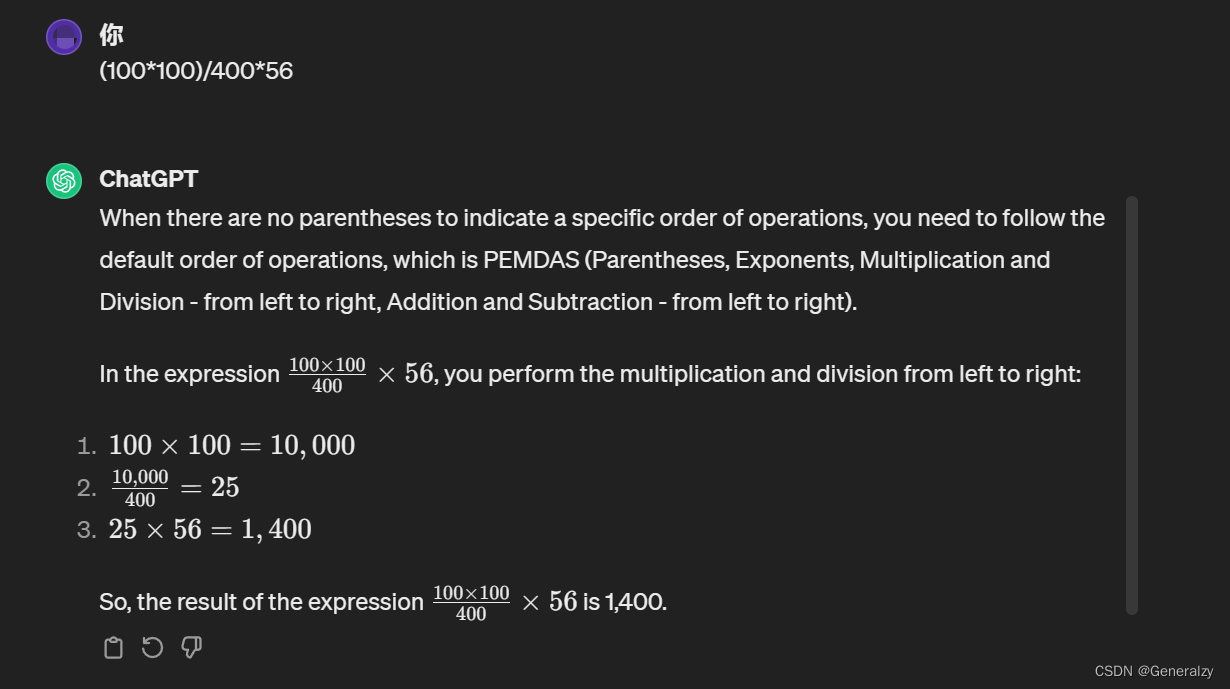
举个例子,如果在 ChatGPT 里输入这样的一段话:What is 100100/40056?
ChatGPT 会返回一个错误的答案:
如果修改成:(100100)/40056,就会得出正确答案:

Prompt的构成
Prompt的构成:一个完整的Prompt应该包含清晰的指示、相关的上下文、有助于理解的例子、明确的输入以及期望的输出格式描述。
- 指示(Instructions) - 关键词:任务描述
指示是对任务的明确描述,相当于给模型下达了一个命令或请求。它告诉模型应该做什么,是任务执行的基础。 - 上下文(Context) - 关键词:背景信息
上下文是与任务相关的背景信息,它有助于模型更好地理解当前任务所处的环境或情境。在多轮交互中,上下文尤其重要,因为它提供了对话的连贯性和历史信息。 - 例子(Examples) - 关键词:示范学习
例子是给出的一或多个具体示例,用于演示任务的执行方式或所需输出的格式。这种方法在机器学习中被称为示范学习,已被证明对提高输出正确性有帮助。 - 输入(Input) - 关键词:数据输入
输入是任务的具体数据或信息,它是模型需要处理的内容。在Prompt中,输入应该被清晰地标识出来,以便模型能够准确地识别和处理。 - 输出(Output) - 关键词:结果格式
输出是模型根据输入和指示生成的结果。在Prompt中,通常会描述输出的格式,以便后续模块能够自动解析模型的输出结果。常见的输出格式包括结构化数据格式如JSON、XML等。
其他信息可以参考:Prompt Engineering Guide
举一个chatGPT 中文调教指南项目[6]的例子:
我希望你能担任英语翻译、拼写校对和修辞改进的角色。
我会用任何语言和你交流,你会识别语言,将其翻译并用更为优美和精炼的英语回答我。
请将我简单的词汇和句子替换成更为优美和高雅的表达方式,确保意思不变,但使其更具文学性。
请仅回答更正和改进的部分,不要写解释。
我的第一句话是“how are you ?”,请翻译它。
这种用于对话开头的提示词往往需要提示词工程师投入大量时间精力来创作、迭代。由于这类提示词在系统级生效,而且对于使用 API 应用开发来说,这类提示词用于 System(注:ChatGPT将角色分为system,user,assistant) 部分。
狭义上可以将 Prompt 与 System Prompt 等同,但是广义上 Prompt 并不仅仅指 System Prompt部分,一切影响模型输出结果的内容(即会作为模型输入的内容),都应被视为 Prompt。
这要从 GPT 模型的原理谈起。众所周知GPT 模型是依据【之前的内容作为输入】来预测(记住整个词:预测)【之后的内容作为输出】,如何简单具体的理解这个事情呢?
上面输入法的例子中,第一张图片中的 “春眠” 是输入,“不觉晓” 是模型输出,所以 “春眠” 是 Prompt。到了第二张图片, “春眠不觉晓” 是模型输入(“不觉晓”是模型前一轮的输出),“处处闻啼鸟” 是模型输出,所以 “春眠不觉晓” 是 Prompt。
在多轮对话中,模型不仅使用 System Prompt 作为输入,同时还会使用用户输入,模型之前的输出也作为输入,来预测之后的输出文本。
所以,要用好大模型能力,不论对于使用者来说还是提示词工程师来说,都应意识到:“所有会被模型用于预测输出结果的内容,都是 Prompt”。也就是说,不仅 System Prompt 是 Prompt,后续对话中输入的内容也是 Prompt, 甚至模型之前输出的内容也是之后输出内容的 Prompt。
使用langChain管理提示词
Prompt Template 负责创建 PromptValue,这是最终传递给语言模型的内容。Prompt Template 有助于将用户输入和其他动态信息转换为适合语言模型的格式。PromptValues 是具有方法的类,这些方法可以转换为每个模型类型期望的确切输入类型(如文本或聊天消息)。
from langchain.prompts import PromptTemplate
prompt = PromptTemplate(
input_variables=["product"],
template="What is a good name for a company that makes {product}?",
)
我们可以调用. format 方法来格式化它。
print(prompt.format(product="colorful socks"))
What is a good name for a company that makes colorful socks?
到目前为止,我们已经自己处理了单独的 PromptTemplate 和 LLM。但是,真正的应用程序不仅仅是一个,而是它们的组合。在 LangChain,链是由链组成的,可以是 LLM 这样的原始链,也可以是其他链。最核心的链类型是 LLMChain,它由 PromptTemplate 和 LLM 组成。现在,我们可以构造一个LLMChain。
from langchain_openai import AzureChatOpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
llm = AzureChatOpenAI(
openai_api_key="your api key",
openai_api_version="your api_version",
azure_endpoint="your endpoint",
deployment_name="your model",
temperature=0.5,
)
prompt = PromptTemplate(
input_variables=["food"],
template="如果我想开一家{food}店,店名取什么比较好?",
)
chain = LLMChain(llm=llm, prompt=prompt)
# run方法已经被弃用
print(chain.predict(food="奶茶"))

langChain Model
LangChain model 是一种抽象,表示框架中使用的不同类型的模型。LangChain 中的模型主要分为三类:
-
LLM(大型语言模型):这些模型将文本字符串作为输入并返回文本字符串作为输出。它们是许多语言模型应用程序的支柱。
-
聊天模型( Chat Model):聊天模型由语言模型支持,但具有更结构化的 API。他们将聊天消息列表作为输入并返回聊天消息。这使得管理对话历史记录和维护上下文变得容易。
-
文本嵌入模型(Text Embedding Models):这些模型将文本作为输入并返回表示文本嵌入的浮点列表。这些嵌入可用于文档检索、聚类和相似性比较等任务。
开发人员可以为他们的用例选择合适的 LangChain 模型,并利用提供的组件来构建他们的应用程序。
LLM&ChatModel
LLMs的输入/输出简单易懂 - 字符串。而ChatModels的输入是一个ChatMessage列表,输出是一个单独的ChatMessage。 一个ChatMessage具有两个必需的组件:
- content: 这是消息的内容。
- role: 这是ChatMessage来自的实体的角色。
LangChain提供了几个对象,用于方便地区分不同的角色:
- HumanMessage: 来自人类/用户的ChatMessage。
- AIMessage: 来自AI/助手的ChatMessage。
- SystemMessage: 来自系统的ChatMessage。
- FunctionMessage: 来自函数调用的ChatMessage。
如果这些角色都不合适,还可以使用ChatMessage类手动指定角色。
LangChain为两者提供了一个标准接口,但了解这种差异以便为给定的语言模型构建提示非常有用。LangChain提供的标准接口有两种方法:
predict: 接受一个字符串,返回一个字符串predict_messages: 接受一个消息列表,返回一个消息。
在新版的langChain源码中,上述两种模型的predict和predict_message方法都被废弃,并且推荐使用invoke方法,区别在于llm调用invoke会返回str,而chat model调用invoke会返回message对象:
@deprecated("0.1.7", alternative="invoke", removal="0.2.0")
# llm
def invoke(
self,
input: LanguageModelInput,
config: Optional[RunnableConfig] = None,
*,
stop: Optional[List[str]] = None,
**kwargs: Any,
) -> str:
...
# chatmodel
def invoke(
self,
input: LanguageModelInput,
config: Optional[RunnableConfig] = None,
*,
stop: Optional[List[str]] = None,
**kwargs: Any,
) -> BaseMessage:
...
# 并且不区分input
LanguageModelInput: Union[PromptValue, str, Sequence[MessageLikeRepresentation]]
llm和chatModel的区别:
聊天模型,是语言模型的变体,它们在底层使用语言模型但具有不同的API。聊天模型使用聊天消息作为输入和输出,而不是“文本输入、文本输出”API。
chatModel
要完成聊天,需要将一条或多条消息传递给聊天模型。LangChain 目前支持 AIMessage、HumanMessage、SystemMessage 和 ChatMessage 类型。主要使用 HumanMessage、AIMessage 和 SystemMessage。
下面是使用聊天模型的示例:
from langchain.schema import (
AIMessage,
HumanMessage,
SystemMessage
)
# 传递一条信息
messages = [
SystemMessage(content="You are a helpful assistant that translates English to Chinese."),
HumanMessage(content="Translate this sentence from English to Chinese: I love programming.")
]
print(llm.invoke(messages))
# content='我喜欢编程。'
# 使用generate批量传入
batch_messages = [
[
SystemMessage(content="You are a helpful assistant that translates English to Chinese."),
HumanMessage(content="Translate this sentence from English to Chinese. I love programming.")
],
[
SystemMessage(content="You are a helpful assistant that translates English to Chinese."),
HumanMessage(content="Translate this sentence from English to Chinese. I love artificial intelligence.")
],
]
result = chat.generate(batch_messages)
print(result)
# -> LLMResult(generations=[[ChatGeneration(text="我喜欢编程。(Wǒ xǐhuān biānchéng.)", generation_info=None, message=AIMessage(content="我喜欢编程。(Wǒ xǐhuān biānchéng.)", additional_kwargs={}))], [ChatGeneration(text="我喜爱人工智能。(Wǒ xǐ'ài rén gōng zhì néng.)", generation_info=None, message=AIMessage(content="我喜爱人工智能。(Wǒ xǐ'ài rén gōng zhì néng.)", additional_kwargs={}))]], llm_output={'token_usage': {'prompt_tokens': 71, 'completion_tokens': 18, 'total_tokens': 89}})
# 还可以从 LLMResult 中提取 tokens 使用等信息:
result.llm_output['token_usage']
# -> {'prompt_tokens': 71, 'completion_tokens': 18, 'total_tokens': 89}
对于聊天模型,还可以通过使用 MessagePromptTemplate 来使用模板:
from langchain.chat_models import ChatOpenAI
from langchain.prompts.chat import (
ChatPromptTemplate,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
)
chat = ChatOpenAI(temperature=0)
template="You are a helpful assistant that translates {input_language} to {output_language}."
system_message_prompt = SystemMessagePromptTemplate.from_template(template)
human_template="{text}"
human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)
chat_prompt = ChatPromptTemplate.from_messages([system_message_prompt, human_message_prompt])
template = "You are a helpful assistant that translates {input_language} to {output_language}."
system_message_prompt = SystemMessagePromptTemplate.from_template(template)
human_template = "{text}"
human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)
chat_prompt = ChatPromptTemplate.from_messages([system_message_prompt, human_message_prompt])
result = llm.invoke(chat_prompt.format_prompt(input_language="English", output_language="Chinese",
text="I love programming.").to_messages())
# content='我喜欢编程。' <class 'langchain_core.messages.ai.AIMessage'>
print(result, type(result))
也可以将 LLMChain 与 Chat Model 一起使用:
template = "You are a helpful assistant that translates {input_language} to {output_language}."
system_message_prompt = SystemMessagePromptTemplate.from_template(template)
human_template = "{text}"
human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)
chat_prompt = ChatPromptTemplate.from_messages([system_message_prompt, human_message_prompt])
chain = LLMChain(llm=llm, prompt=chat_prompt)
invoke_result = chain.invoke({
"input_language": "English",
"output_language": "Chinese",
"text": "I love programming.",
})
print(invoke_result, type(invoke_result))
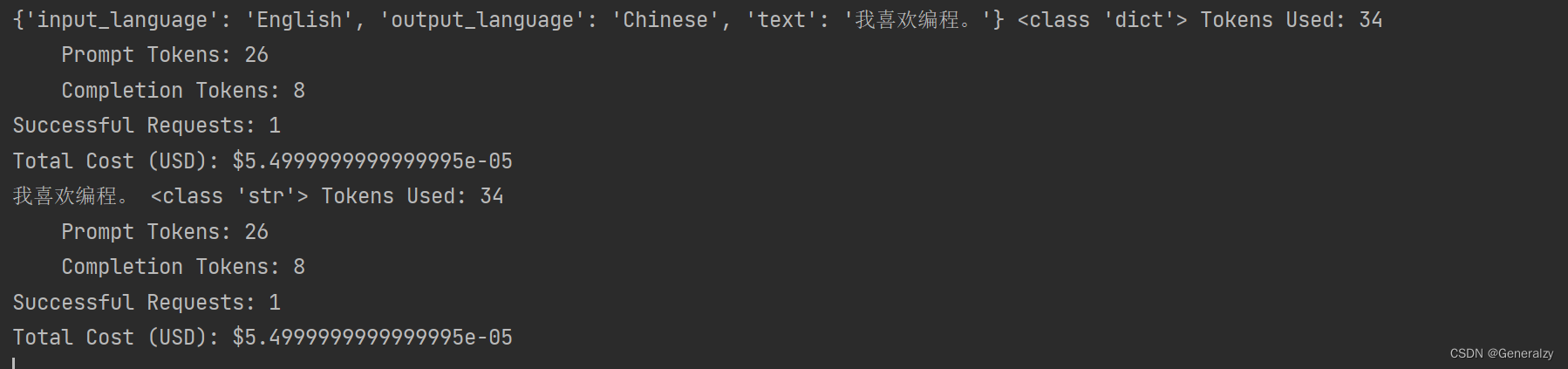
# {'input_language': 'English', 'output_language': 'Chinese', 'text': '我喜欢编程。'} <class 'dict'>
predict_result = chain.predict(
input_language="English",
output_language="Chinese",
text="I love programming."
)
print(predict_result, type(predict_result))
# 我喜欢编程。 <class 'str'>
也可以将内存与使用聊天模型初始化的链和代理一起使用,这样就可以保持chat上下文,但具体可以保持多少个token的上下文与具体model有关:
from langchain.memory import ConversationBufferMemory
from langchain.prompts.chat import (
ChatPromptTemplate,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
MessagesPlaceholder,
)
prompt = ChatPromptTemplate.from_messages([
SystemMessagePromptTemplate.from_template("The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know."),
MessagesPlaceholder(variable_name="history"),
HumanMessagePromptTemplate.from_template("{input}")
])
llm = ChatOpenAI(temperature=0)
memory = ConversationBufferMemory(return_messages=True)
conversation = ConversationChain(memory=memory, prompt=prompt, llm=llm)
conversation.predict(input="Hi there!")
# -> 'Hello! How can I assist you today?'
conversation.predict(input="I'm doing well! Just having a conversation with an AI.")
# -> "That sounds like fun! I'm happy to chat with you. Is there anything specific you'd like to talk about?"
conversation.predict(input="Tell me about yourself.")
# -> "Sure! I am an AI language model created by OpenAI. I was trained on a large dataset of text from the internet, which allows me to understand and generate human-like language. I can answer questions, provide information, and even have conversations like this one. Is there anything else you'd like to know about me?"
token计费
对于token的使用,官方也提供了更加简便的方法:
# 已弃用从langchain导入
# from langchain.callbacks import get_openai_callback
from langchain_community.callbacks import get_openai_callback
with get_openai_callback() as cb:
invoke_result = chain.invoke({
"input_language": "English",
"output_language": "Chinese",
"text": "I love programming.",
})
print(invoke_result, type(invoke_result), cb)
with get_openai_callback() as sb:
predict_result = chain.predict(
input_language="English",
output_language="Chinese",
text="I love programming."
)
print(predict_result, type(predict_result), sb)
get_openai_callback实际上封装了OpenAICallbackHandler()对象,OpenAICallbackHandler()对象提供了相关token的属性,完全可以通过.操作符获取到,然后自行拼接:
class OpenAICallbackHandler(BaseCallbackHandler):
"""Callback Handler that tracks OpenAI info."""
total_tokens: int = 0
prompt_tokens: int = 0
completion_tokens: int = 0
successful_requests: int = 0
total_cost: float = 0.0
内存: 向链和代理添加状态
通常,开发人员会希望链或代理具有某种“内存”概念,以便它可以记住关于其以前的交互的信息。这样它就可以利用这些消息的上下文来进行更好的对话。
LangChain 提供了几个专门为此目的创建的链。
本次使用其中一个链( ConversationChain ) 和两种不同类型的内存来完成操作。
默认情况下,,ConversationChain 有一个简单的内存类型,它记住所有以前的输入/输出,并将它们添加到传递的上下文中。
from langchain import OpenAI, ConversationChain
llm = OpenAI(temperature=0)
# 设置 verbose=True,这样就可以看到提示符
conversation = ConversationChain(llm=llm, verbose=True)
# 第一次问答
output = conversation.predict(input="Hi there!")
print(output)
> Entering new chain...
Prompt after formatting:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
Human: Hi there!
AI:
> Finished chain.
' Hello! How are you today?'
# 第二次问答
output = conversation.predict(input="I'm doing well! Just having a conversation with an AI.")
print(output)
> Entering new chain...
Prompt after formatting:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
Human: Hi there!
AI: Hello! How are you today?
Human: I'm doing well! Just having a conversation with an AI.
AI:
> Finished chain.
" That's great! What would you like to talk about?"
代理 Agent: 基于用户输入的动态调用链
代理使用 LLM 来确定要执行哪些操作以及按照什么顺序执行。代理可以使用工具(tools)并观察其输出,也可以返回给用户,比如对于一个基本的问答,agent可以调用工具概括长对话,调用外部接口,接入搜索引擎,最后拼接组合结果给用户。(langChain在大模型问世前几年就已经发布了,接入外部接口对于langChain已经非常成熟)
如果使用得当,效果可以非常强大。
为了运好代理,应该理解以下概念:
- 工具(tools): 执行特定任务的功能。这可以是: Google 搜索、数据库查找、 Python REPL、其他链。
- 大语言模型(LLM): 为代理提供动力的语言模型。
- 代理(agents): 要使用的代理。
准备环境接口环境:
pip install google-search-results
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from langchain.agents import AgentType
from langchain.llms import OpenAI
import os
# 要花钱买google 搜索的apikey
os.environ["SERPAPI_API_KEY"] = "..."
# First, let's load the language model we're going to use to control the agent.
llm = OpenAI(temperature=0)
# Next, let's load some tools to use. Note that the `llm-math` tool uses an LLM, so we need to pass that in.
tools = load_tools(["serpapi", "llm-math"], llm=llm)
# Finally, let's initialize an agent with the tools, the language model, and the type of agent we want to use.
agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
# Now let's test it out!
agent.run("What was the high temperature in SF yesterday in Fahrenheit? What is that number raised to the .023 power?")
> Entering new AgentExecutor chain...
I need to find the temperature first, then use the calculator to raise it to the .023 power.
Action: Search
Action Input: "High temperature in SF yesterday"
Observation: San Francisco Temperature Yesterday. Maximum temperature yesterday: 57 °F (at 1:56 pm) Minimum temperature yesterday: 49 °F (at 1:56 am) Average temperature ...
Thought: I now have the temperature, so I can use the calculator to raise it to the .023 power.
Action: Calculator
Action Input: 57^.023
Observation: Answer: 1.0974509573251117
Thought: I now know the final answer
Final Answer: The high temperature in SF yesterday in Fahrenheit raised to the .023 power is 1.0974509573251117.
> Finished chain.
具有聊天模型的代理
代理也可以与聊天模型一起使用,可以使用 AgentType.CHAT_ZERO_SHOT_REACT_DESCRIPTION作为代理类型来初始化一个聊天模型。
此处同样需要提供serpapi的api-key(花钱买呗,反正我买不起)
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from langchain.agents import AgentType
from langchain.chat_models import ChatOpenAI
from langchain.llms import OpenAI
# First, let's load the language model we're going to use to control the agent.
chat = ChatOpenAI(temperature=0)
# Next, let's load some tools to use. Note that the `llm-math` tool uses an LLM, so we need to pass that in.
llm = OpenAI(temperature=0)
tools = load_tools(["serpapi", "llm-math"], llm=llm)
# Finally, let's initialize an agent with the tools, the language model, and the type of agent we want to use.
agent = initialize_agent(tools, chat, agent=AgentType.CHAT_ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
# Now let's test it out!
agent.run("Who is Olivia Wilde's boyfriend? What is his current age raised to the 0.23 power?")
> Entering new AgentExecutor chain...
Thought: I need to use a search engine to find Olivia Wilde's boyfriend and a calculator to raise his age to the 0.23 power.
Action:
{
"action": "Search",
"action_input": "Olivia Wilde boyfriend"
}
Observation: Sudeikis and Wilde's relationship ended in November 2020. Wilde was publicly served with court documents regarding child custody while she was presenting Don't Worry Darling at CinemaCon 2022. In January 2021, Wilde began dating singer Harry Styles after meeting during the filming of Don't Worry Darling.
Thought:I need to use a search engine to find Harry Styles' current age.
Action:
{
"action": "Search",
"action_input": "Harry Styles age"
}
Observation: 29 years
Thought:Now I need to calculate 29 raised to the 0.23 power.
Action:
{
"action": "Calculator",
"action_input": "29^0.23"
}
Observation: Answer: 2.169459462491557
Thought:I now know the final answer.
Final Answer: 2.169459462491557
> Finished chain.
'2.169459462491557'
LangChain Expression Language (LCEL)
LangChain 表达式语言(LCEL)是一种轻松地将链组合在一起的声明性方式。
基本示例:提示+模型+输出
最基本和常见的用例是将提示模板和模型链接在一起。
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from llm import llm as model
prompt = ChatPromptTemplate.from_template("tell me a short joke about {topic}")
output_parser = StrOutputParser()
chain = prompt | model | output_parser
output = chain.invoke({"topic": "ice cream"})
print(output, type(output))
chain_without_parser = prompt | model
output = chain.invoke({"topic": "Russia"})
print(output, type(output))
使用 LCEL 将不同的组件拼凑成一个链:
chain = prompt | model | output_parser
|符号类似于unix 管道运算符,它将不同的组件链接在一起,将一个组件的输出作为下一个组件的输入。
在这个链条中,用户输入被传递给提示模板,然后提示模板的输出被传递给模型,然后模型的输出被传递给输出解析器。
提示
prompt 是一个BasePromptTemplate,这意味着它接受一个模板变量的字典并生成一个 PromptValue。
PromptValue 是一个包装完成的提示的包装器,可以传递给 LLM(它以字符串作为输入)或 ChatModel(它以消息序列作为输入)。它可以与任何语言模型类型一起使用,因为它定义了生成 BaseMessage 和生成字符串的逻辑。
prompt_value = prompt.invoke({"topic": "ice cream"})
print(prompt_value, type(prompt_value))
message = prompt_value.to_messages()
# ChatPromptValue(messages=[HumanMessage(content='tell me a short joke about ice cream')])
print(message, type(message))
s = prompt_value.to_string()
# [HumanMessage(content='tell me a short joke about ice cream')]
print(s, type(s))

模型
然后将 PromptValue 传递给 model。在这种情况下,如果 model 是一个 ChatModel,这意味着它将输出一个 BaseMessage。
message = model.invoke(prompt_value)
message
AIMessage(content="为什么冰淇淋从不被邀请参加派对?\n\n因为当事情变热时,它们总是滴下来!")
如果model 是一个 LLM,它将输出一个字符串。
from langchain_openai.llms import OpenAI
llm = OpenAI(model="gpt-3.5-turbo-instruct")
llm.invoke(prompt_value)
'\n\nRobot: 冰淇淋车为什么坏了?因为它融化了!'
输出解析器
最后,将 model 的输出传递给 output_parser,它是一个 BaseOutputParser,意味着它可以接受字符串或 BaseMessage 作为输入。StrOutputParser 简单地将任何输入转换为字符串。
output_parser.invoke(message)
"冰淇淋为什么去看心理医生?\n\n因为它有太多的配料,找不到自己的冰淇淋锥自信!"
RAG 搜索示例
-
本地数据加载
from langchain.document_loaders import TextLoader loader = TextLoader("./藜.txt") documents = loader.load() documents [Document(page_content='藜(读音lí)麦(Chenopodium\xa0quinoa\xa0Willd.)是藜科藜属植物。穗部可呈红、紫、黄,植株形状类似灰灰菜,成熟后穗部类似高粱穗。植株大小受环境及遗传因素影响较大,从0.3-3米不等,茎部质地较硬,可分枝可不分。单叶互生,叶片呈鸭掌状,叶缘分为全缘型与锯齿缘型。藜麦花两性,花序呈伞状、穗状、圆锥状,藜麦种子较小,呈小圆药片状,直径1.5-2毫米,千粒重1.4-3克。\xa0[1]\xa0\n原产于南美洲安第斯山脉的哥伦比亚、厄瓜多尔、秘鲁等中高海拔山区。具有一定的耐旱、耐寒、耐盐性,生长范围约为海平面到海拔4500米左右的高原上,最适的高度为海拔3000-4000米的高原或山地地区。\xa0[1]\xa0\n藜麦富含的维生素、多酚、类黄酮类、皂苷和植物甾醇类物质具有多种健康功效。 -
文档分割
# 文档分割 from langchain.text_splitter import CharacterTextSplitter # 创建拆分器 text_splitter = CharacterTextSplitter(chunk_size=128, chunk_overlap=0) # 拆分文档 documents = text_splitter.split_documents(documents) documents [Document(page_content='藜(读音lí)麦(Chenopodium\xa0quinoa\xa0Willd.)是藜科藜属植物。穗部可呈红、紫、黄,植株形状类似灰灰菜,成熟后穗部类似高粱穗。植株大小受环境及遗传因素影响较大,从0.3-3米不等,茎部质地较硬,可分枝可不分。单叶互生,叶片呈鸭掌状,叶缘分为全缘型与锯齿缘型。藜麦花两性,花序呈伞状、穗状、圆锥状,藜麦种子较小,呈小圆药片状,直径1.5-2毫米,千粒重1.4-3克。\xa0[1]\xa0\n原产于南美洲安第斯山脉的哥伦比亚、厄瓜多尔、秘鲁等中高海拔山区。具有一定的耐旱、耐寒、耐盐性,生长范围约为海平面到海拔4500米左右的高原上,最适的高度为海拔3000-4000米的高原或山地地区。\xa0[1]\xa0\n藜麦富含的维生素、多酚、类黄酮类、皂苷和植物甾醇类物质具有多种健康功效。藜麦具有高蛋白,其所含脂肪中不饱和脂肪酸占83%,还是一种低果糖低葡萄糖的食物,能在糖脂代谢过程中发挥有益功效。\xa0[1]\xa0\xa0[5]\xa0\n国内藜麦产品的销售以电商为主,缺乏实体店销售,藜麦市场有待进一步完善。藜麦国际市场需求强劲,发展前景十分广阔。通过加快品种培育和生产加工设备研发,丰富产品种类,藜麦必将在“调结构,转方式,保增收”的农业政策落实中发挥重要作用。\xa0[5]\xa0\n2022年5月,“超级谷物”藜麦在宁洱县试种成功。', metadata={'source': './藜.txt'}), Document(page_content='藜麦是印第安人的传统主食,几乎和水稻同时被驯服有着6000多年的种植和食用历史。藜麦具有相当全面营养成分,并且藜麦的口感口味都容易被人接受。在藜麦这种营养丰富的粮食滋养下南美洲的印第安人创造了伟大的印加文明,印加人将藜麦尊为粮食之母。美国人早在80年代就将藜麦引入NASA,作为宇航员的日常口粮,FAO认定藜麦是唯一一种单作物即可满足人类所需的全部营养的粮食,并进行藜麦的推广和宣传。2013年是联合国钦定的国际藜麦年。以此呼吁人们注意粮食安全和营养均衡。', metadata={'source': './藜.txt'}), Document(page_content='藜麦穗部可呈红、紫、黄,植株形状类似灰灰菜,成熟后穗部类似高粱穗。植株大小受环境及遗传因素影响较大,从0.3-3米不等,茎部质地较硬,可分枝可不分。单叶互生,叶片呈鸭掌状,叶缘分为全缘型与锯齿缘型。根系庞大但分布较浅,根上的须根多,吸水能力强。藜麦花两性,花序呈伞状、穗状、圆锥状,藜麦种子较小,呈小圆药片状,直径1.5-2毫米,千粒重1.4-3克。', metadata={'source': './藜.txt'}), Document(page_content='原产于南美洲安第斯山脉的哥伦比亚、厄瓜多尔、秘鲁等中高海拔山区。具有一定的耐旱、耐寒、耐盐性,生长范围约为海平面到海拔4500米左右的高原上,最适的高度为海拔3000-4000米的高原或山地地区。\n\n播前准备', metadata={'source': './藜.txt'}), Document(page_content='繁殖\n地块选择:应选择地势较高、阳光充足、通风条件好及肥力较好的地块种植。藜麦不宜重茬,忌连作,应合理轮作倒茬。前茬以大豆、薯类最好,其次是玉米、高粱等。\xa0[4]\xa0\n施肥整地:早春土壤刚解冻,趁气温尚低、土壤水分蒸发慢的时候,施足底肥,达到土肥融合,壮伐蓄水。播种前每降1次雨及时耙耱1次,做到上虚下实,干旱时只耙不耕,并进行压实处理。一般每亩(667平方米/亩,下同)施腐熟农家肥1000-2000千克、硫酸钾型复合肥20-30千克。如果土壤比较贫瘠,可适当增加复合肥的施用量。\xa0[4]', metadata={'source': './藜.txt'}), ...] -
向量化&数据入库
# m3e-base作为embedding模型,向量数据库选用Chroma from langchain.embeddings import HuggingFaceBgeEmbeddings from langchain.vectorstores import Chroma # embedding model: m3e-base model_name = "moka-ai/m3e-base" model_kwargs = {'device': 'cpu'} encode_kwargs = {'normalize_embeddings': True} embedding = HuggingFaceBgeEmbeddings( model_name=model_name, model_kwargs=model_kwargs, encode_kwargs=encode_kwargs, query_instruction="为文本生成向量表示用于文本检索" ) # load data to Chroma db db = Chroma.from_documents(documents, embedding) # similarity search db.similarity_search("藜一般在几月播种?") -
Prompt设计
template = ''' 【任务描述】 请根据用户输入的上下文回答问题,并遵守回答要求。 【背景知识】 {{context}} 【回答要求】 - 你需要严格根据背景知识的内容回答,禁止根据常识和已知信息回答问题。 - 对于不知道的信息,直接回答“未找到相关答案” ----------- {question} ''' -
RetrievalqaChain构建:ConversationalRetrievalChain,ConversationalRetrievalQA chain 是建立在 RetrievalQAChain 之上,提供历史聊天记录组件。如下面定义了memory来追踪聊天记录,在流程上,先将历史问题和当前输入问题融合为一个新的独立问题,然后再进行检索,获取问题相关知识,最后将获取的知识和生成的新问题注入Prompt让大模型生成回答。
from langchain import LLMChain from langchain_wenxin.llms import Wenxin from langchain.prompts import PromptTemplate from langchain.memory import ConversationBufferMemory from langchain.chains import ConversationalRetrievalChain from langchain.prompts.chat import ChatPromptTemplate, SystemMessagePromptTemplate, HumanMessagePromptTemplate # LLM选型 llm = Wenxin(model="ernie-bot", baidu_api_key="baidu_api_key", baidu_secret_key="baidu_secret_key") retriever = db.as_retriever() memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True) qa = ConversationalRetrievalChain.from_llm(llm, retriever, memory=memory) qa({"question": "藜怎么防治虫害?"}) {'question': '藜怎么防治虫害?', 'chat_history': [HumanMessage(content='藜怎么防治虫害?'), AIMessage(content='藜麦常见虫害有象甲虫、金针虫、蝼蛄、黄条跳甲、横纹菜蝽、萹蓄齿胫叶甲、潜叶蝇、蚜虫、夜蛾等。防治方法:可每亩用3%的辛硫磷颗粒剂2-2.5千克于耕地前均匀撒施,随耕地翻入土中。也可以每亩用40%的辛硫磷乳油250毫升,加水1-2千克,拌细土20-25千克配成毒土,撒施地面翻入土中,防治地下害虫。')], 'answer': '藜麦常见虫害有象甲虫、金针虫、蝼蛄、黄条跳甲、横纹菜蝽、萹蓄齿胫叶甲、潜叶蝇、蚜虫、夜蛾等。防治方法:可每亩用3%的辛硫磷颗粒剂2-2.5千克于耕地前均匀撒施,随耕地翻入土中。也可以每亩用40%的辛硫磷乳油250毫升,加水1-2千克,拌细土20-25千克配成毒土,撒施地面翻入土中,防治地下害虫。'}
扩展阅读RAG
如何更有效地搭建大型语言模型(LLM)与专有数据之间的桥梁。有两种主流的思路:微调(Fine-Tuning)和检索增强生成(Retrieval-Augmented Generation,简称RAG)。而事实上,这两种方法都有其独特的优势。
什么是RAG
检索增强生成(Retrieval Augmented Generation),简称 RAG,已经成为当前最火热的LLM应用方案。经历2023年那一波大模型潮,想必大家对大模型的能力有了一定的了解,但是当我们将大模型应用于实际业务场景时会发现,通用的基础大模型基本无法满足我们的实际业务需求,主要有以下几方面原因:
-
知识的局限性:模型自身的知识完全源于它的训练数据,而现有的主流大模型(ChatGPT、文心一言、通义千问…)的训练集基本都是构建于网络公开的数据,对于一些实时性的、非公开的或离线的数据是无法获取到的,这部分知识也就无从具备。
-
幻觉问题:所有的AI模型的底层原理都是基于数学概率,其模型输出实质上是一系列数值运算,大模型也不例外,所以它有时候会一本正经地胡说八道,尤其是在大模型自身不具备某一方面的知识或不擅长的场景。而这种幻觉问题的区分是比较困难的,因为它要求使用者自身具备相应领域的知识。
-
数据安全性:对于企业来说,数据安全至关重要,没有企业愿意承担数据泄露的风险,将自身的私域数据上传第三方平台进行训练。这也导致完全依赖通用大模型自身能力的应用方案不得不在数据安全和效果方面进行取舍。
而RAG是解决上述问题的一套有效方案。
RAG架构
RAG的架构如图中所示,简单来讲,RAG就是通过检索获取相关的知识并将其融入Prompt,让大模型能够参考相应的知识从而给出合理回答。因此,可以将RAG的核心理解为“检索+生成”,前者主要是利用向量数据库的高效存储和检索能力,召回目标知识;后者则是利用大模型和Prompt工程,将召回的知识合理利用,生成目标答案。
对大型语言模型(LLM)来说,检索增强生成(RAG)就像是开卷考试一样。在开卷考试中,学生可以携带参考资料,比如教科书或笔记,用它们来查找回答问题所需的相关信息。开卷考试的理念在于,考试重点在于考察学生的推理能力,而不是记忆特定信息的能力。
检索增强生成(RAG)的基本工作流程如下:
完整的RAG应用流程主要包含两个阶段:
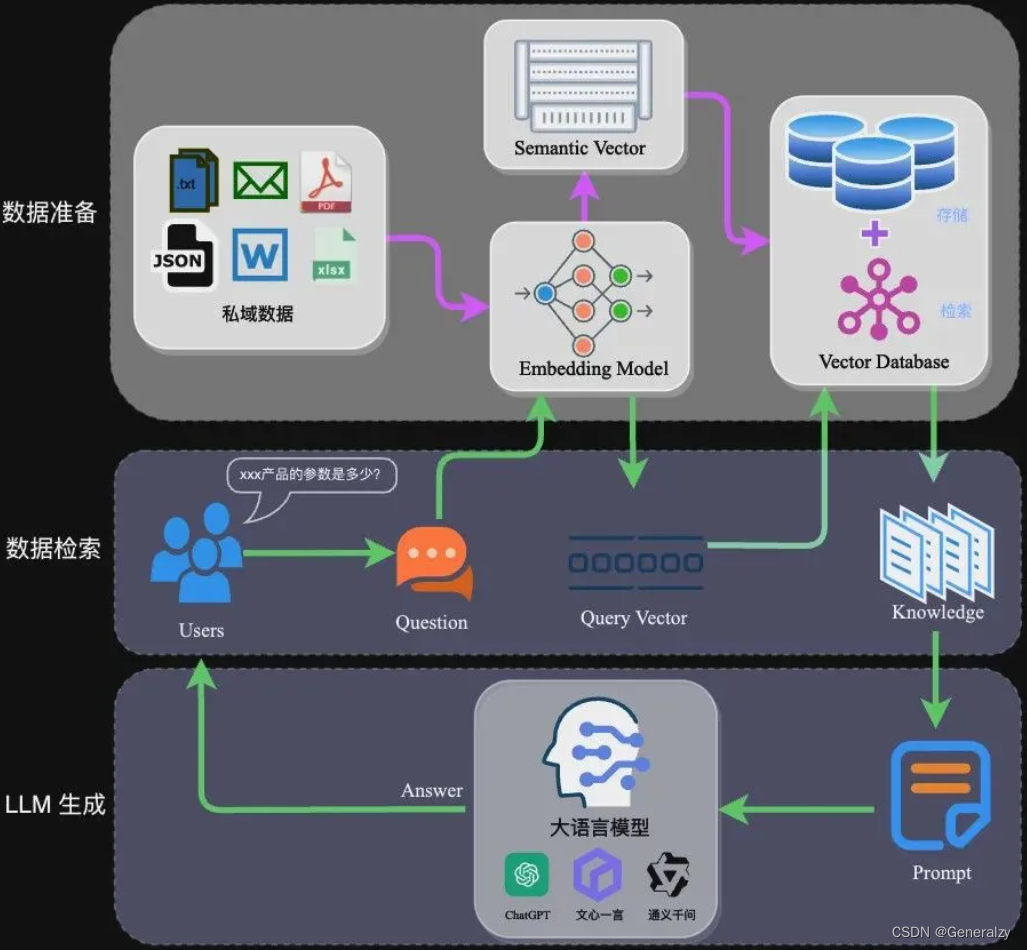
- 数据准备阶段:数据提取——>文本分割——>向量化(embedding)——>数据入库
- 应用阶段:用户提问——>数据检索(召回)——>注入Prompt——>LLM生成答案
数据准备阶段
数据准备一般是一个离线的过程,主要是将私域数据向量化后构建索引并存入数据库的过程。主要包括:数据提取、文本分割、向量化、数据入库等环节。
- 数据提取
- 数据加载:包括多格式数据加载、不同数据源获取等,根据数据自身情况,将数据处理为同一个范式。
- 数据处理:包括数据过滤、压缩、格式化等。
- 元数据获取:提取数据中关键信息,例如文件名、Title、时间等 。
- 文本分割:文本分割主要考虑两个因素:1)embedding模型的Tokens限制情况;2)语义完整性对整体的检索效果的影响。一些常见的文本分割方式如下:
- 句分割:以”句”的粒度进行切分,保留一个句子的完整语义。常见切分符包括:句号、感叹号、问号、换行符等。
- 固定长度分割:根据embedding模型的token长度限制,将文本分割为固定长度(例如256/512个tokens),这种切分方式会损失很多语义信息,一般通过在头尾增加一定冗余量来缓解。
- 向量化(embedding):向量化是一个将文本数据转化为向量矩阵的过程,该过程会直接影响到后续检索的效果。
- 数据入库:数据向量化后构建索引,并写入数据库的过程可以概述为数据入库过程,适用于RAG场景的数据库包括:FAISS、Chromadb、ES、milvus等。一般可以根据业务场景、硬件、性能需求等多因素综合考虑,选择合适的数据库。
应用阶段
在应用阶段,根据用户的提问,通过高效的检索方法,检索与提问最相关的知识,并融入Prompt;大模型参考当前提问和相关知识,生成相应的答案。关键环节包括:数据检索、注入Prompt等。
-
数据检索:常见的数据检索方法包括:相似性检索、全文检索等,根据检索效果,一般可以选择多种检索方式融合,提升召回率。
- 相似性检索:即计算查询向量与所有存储向量的相似性得分,返回得分高的记录。常见的相似性计算方法包括:余弦相似性、欧氏距离、曼哈顿距离等。
- 全文检索:全文检索是一种比较经典的检索方式,在数据存入时,通过关键词构建倒排索引;在检索时,通过关键词进行全文检索,找到对应的记录。
-
注入Prompt:Prompt作为大模型的直接输入,是影响模型输出准确率的关键因素之一。在RAG场景中,Prompt一般包括任务描述、背景知识(检索得到)、任务指令(一般是用户提问)等,根据任务场景和大模型性能,也可以在Prompt中适当加入其他指令优化大模型的输出。一个简单知识问答场景的Prompt如下所示:
【任务描述】 假如你是一个专业的客服机器人,请参考【背景知识】,回 【背景知识】 {content} // 数据检索得到的相关文本 【问题】 石头扫地机器人P10的续航时间是多久?Prompt的设计只有方法、没有语法,比较依赖于个人经验,在实际应用过程中,往往需要根据大模型的实际输出进行针对性的Prompt调优。
扩展阅读Word embedding
词嵌入(Word embedding)是NLP(Natural Language Processing 自然语言处理)中语言模型与表征学习技术的统称。概念上而言,它是指把一个维数为所有词的数量的高维空间嵌入到一个维数低得多的连续向量空间中,每个单词或词组被映射为实数域上的向量。
众所周知,计算机无法读懂自然语言,只能处理数值,因此自然语言需要以一定的形式转化为数值。词嵌入就是将自然语言中的词语映射为数值的一种方式。然而对于丰富的自然语言来说,将它们映射为数值向量,使之包含更丰富的语义信息和抽象特征显然是一种更好的选择。词嵌入是NLP领域中下游任务实现的重要基础,目前的大多数NLP任务都离不开词嵌入。并且纵观NLP的发展史,很多革命性的成果也都是词嵌入的发展成果,如Word2Vec、GloVe、FastText、ELMo和BERT。
词嵌入方法
One-Hot(独热编码)模型
在最初NLP任务中,非结构化的文本数据转换成可供计算机识别的数据形式使用的是独热编码模型(one-hot code),它将文本转化为向量形式表示,并且不局限于语言种类,也是最简单的词嵌入的方式。
One-Hot将词典中所有的词排成一列,根据词的位置设计向量,例如词典中有m个词,则每个单词都表示为一个m维的向量,单词对应词典中的位置的维度上为1,其他维度为0。

from sklearn.feature_extraction.text import CountVectorizer
def one_hot(texts):
'''
CountVectorizer:文本特征提取计算类,会将文本中的词语转换为词频矩阵,它通过fit_transform函数计算各个词语出现的次数
'''
vectorizer = CountVectorizer(analyzer="char",binary=True)
texts = vectorizer.fit_transform(texts) # 拟合模型,并返回文本矩阵
return texts
text = ['东', '北', '大', '学', '在', '东', '北']
text = one_hot(text) # 此处text为csr_matrix类型,是一个稀疏矩阵。如:(2, 3) 1代表第二行第三列的值为1,其余全为0。
text
# 输出
(0, 0) 1 # [1,0,0,0,0] 东
(1, 1) 1 # [0,1,0,0,0] 北
(2, 3) 1 # [0,0,0,1,0] 大
(3, 4) 1 # [0,0,0,0,1] 学
(4, 2) 1 # [0,0,1,0,0] 在
(5, 0) 1 # [1,0,0,0,0] 东
(6, 1) 1 # [0,1,0,0,0] 北
该方法虽然简单,并且适用于任意文本数据,但存在很多严重问题:
- 维度爆炸。由于每一个单词的词向量的维度都等于词汇表的长度,对于大规模语料训练的情况,词汇表将异常庞大,使模型的计算量剧增造成维数灾难。
- 矩阵稀疏。有用的信息零散地分布在大量数据中。这会导致结果异常稀疏,使其难以进行优化,对于神经网络来说尤其如此。
- 向量正交。由于两两向量正交,无法表达两词向量之间的其他信息,造成了“语义鸿沟”的 现象,此特点对于NLP任务是相当致命的。
所以,One-Hot只是简单地将“词”进行了编号,并没有表达词语的含义,并不符合语言的自然规律。那么,如何能使一个词向量表达出更丰富的语义信息呢?
对于一个不理解的单词,如果知道了它在不同的上下文中是如何使用的,我们就能理解它的意思。根据经验,出现在相似上下文语境中的词语有相似的含义。所以可以将词语的上下文语境信息放入到词向量中,也就说明我们获得了这个词语的语义。
获取上下文信息一般有两种方式,一种是基于计数的,一 种是基于预测的。
Bag of Words(词袋表示)模型
词袋模型(Bow,Bag of Words),是文本向量化的一个模型,这种模型不考虑语法、词的顺序,只考虑所有的词的出现频率,简单说,就是分好的词放到一个袋子中,每个词都是独立的。
向量的维度根据词典中不重复词的个数确定,向量中每个元素顺序与原来文本中单词出现的顺序没有关系,与词典中的顺序一一对应,向量中每个数字是词典中每个单词在文本中出现的频率——即词频表示。
from sklearn.feature_extraction.text import CountVectorizer
def bow(texts):
'''
CountVectorizer:文本特征提取计算类,会将文本中的词语转换为词频矩阵,它通过fit_transform函数计算各个词语出现的次数
'''
vectorizer = CountVectorizer()
texts = vectorizer.fit_transform(texts) # 拟合模型,并返回文本矩阵
print(vectorizer.get_feature_names()) # 获得所有文本的词汇;列表型
return texts
text = ['AA is BB, and BB is AA', 'CC is not AA, but CC is DD']
text = bow(text) # 此处text为csr_matrix类型,是一个稀疏矩阵。如:(2, 3) 1代表第二行第三列的值为1,其余全为0。
print(text.toarray()) # 将csr_matrix转换为ndarray
# 输出
['aa', 'and', 'bb', 'but', 'cc', 'dd', 'is', 'not']
[[2 1 2 0 0 0 2 0]
[1 0 0 1 2 1 2 1]]
词袋模型虽然实现简单,并且比one-hot增加了词频的信息,但仍然存在缺陷。由于词袋模型只是把句子看作单词的简单集合,忽略了单词出现的顺序,可能导致顺序不一样的两句话在机器看来是完全相同的语义。
N-gram 模型
N-gram也是一种基于统计语言模型的算法。它的基本思想是将文本里面的内容按照字节进行大小为N的滑动窗口操作,形成了长度是N的字节片段序列。每一个字节片段称为gram,对所有gram的出现频度进行统计,并且按照事先设定好的阈值进行过滤,形成关键gram列表,也就是这个文本的向量特征空间,列表中的每一种gram就是一个特征向量维度。
该模型基于这样一种假设,第N个词的出现只与前面N-1个词相关,而与其它任何词都不相关,整句的概率就是各个词出现概率的乘积。这些概率可以通过直接从语料中统计N个词同时出现的次数得到。当 N=1 时称为 unigram 模型即一元模型,也叫上下文无关模型;当 N=2 时称为 bigram 模型即二元模型;当 N=3 时称为 trigram 模型即三元模型。
from sklearn.feature_extraction.text import CountVectorizer
def n_gram(texts):
'''
CountVectorizer:文本特征提取计算类,会将文本中的词语转换为词频矩阵,它通过fit_transform函数计算各个词语出现的次数
'''
vectorizer = CountVectorizer(ngram_range=(1,2)) # ngram_range参数:词组切分的长度范围
texts = vectorizer.fit_transform(texts) # 拟合模型,并返回文本矩阵
print(vectorizer.get_feature_names()) # 获得所有文本的词汇;列表型
return texts
text = ['AA is BB, and BB is AA', 'CC is not AA, but CC is DD']
text = n_gram(text) # 此处text为csr_matrix类型,是一个稀疏矩阵。如:(2, 3) 1代表第二行第三列的值为1,其余全为0。
print(text.toarray()) # 将csr_matrix转换为ndarray
# 输出
['aa', 'aa but', 'aa is', 'and', 'and bb', 'bb', 'bb and', 'bb is', 'but', 'but cc', 'cc', 'cc is', 'dd', 'is', 'is aa', 'is bb', 'is dd', 'is not', 'not', 'not aa']
[[2 0 1 1 1 2 1 1 0 0 0 0 0 2 1 1 0 0 0 0]
[1 1 0 0 0 0 0 0 1 1 2 2 1 2 0 0 1 1 1 1]]
N-gram 模型的基本原理是基于马尔可夫假设,在训练 N-gram 模型时使用最大似然估计模型参数——条件概率。当N更大的时候,对下一个词出现的约束性信息更多,有更大的辨别力,但是更稀疏,并且N-gram的总数也更多;当N更小的时候,在训练语料库中出现的次数更多,有更可靠的统计结果,更高的可靠性 ,但是约束信息更少。并且,N-gram模型无法避免零概率的问题,导致无法获得良好的语言模型。
TF-IDF 模型
前文提到的几种方法都是基于单词在文档中出现的频率来判断来猜测语义,也符合人类对于语言的理解规律。可是,出现频率越大的词往往对于判断语义并没有实质性的帮助,例如“我”,“是”,“的”,“今天”等词语。而像“足球”,“口红”,“股票”等词则更能反应一篇文章的主题。
解决这个问题,有两种解决方案:第一个是增加停用词(stop word),通过自定义词典,来去掉一些无用的高频词;第二个就是TF-IDF 模型。
TF-IDF算法是一种可应用于多个领域的加权技术,它是基于统计的方法,根据某关键字或词在文档或语料集中出现的频率来估计它对于文件的重要程度。TF-IDF算法常常被用于信息检索任务中。算法的核心思想是,字词在文档中出现的次数越多,其重要程度就越高,但它如果在语料集出现的次数越多,它的重要程度则会随之降低。
TF(Term Frequancy)代表词频,表示词在文档中出现的频率。IDF(Inverse Document Frequency)代表逆文档频率。TF值和IDF值越高,则表示此词在一篇文档中出现概率高并且在其他文档中出现概率低,说明这个词具有良好的类别区分能力,应赋予其更高的权重。
from sklearn.feature_extraction.text import TfidfVectorizer
def tfidf(texts):
'''
CountVectorizer:文本特征提取计算类,会将文本中的词语转换为词频矩阵,它通过fit_transform函数计算各个词语出现的次数
'''
vectorizer = TfidfVectorizer(ngram_range=(1, 2))
texts = vectorizer.fit_transform(texts) # 拟合模型,并返回文本矩阵
print(vectorizer.get_feature_names()) # 获得所有文本的词汇;列表型
return texts
text = ['AA is BB, and BB is AA', 'CC is not AA, but CC is DD']
text = tfidf(text) # 此处text为csr_matrix类型,是一个稀疏矩阵。如:(2, 3) 1代表第二行第三列的值为1,其余全为0。
print(text.toarray()) # 将csr_matrix转换为ndarray
# 输出
['aa', 'aa but', 'aa is', 'and', 'and bb', 'bb', 'bb and', 'bb is', 'but', 'but cc', 'cc', 'cc is', 'dd', 'is', 'is aa', 'is bb', 'is dd', 'is not', 'not', 'not aa']
[[0.36681102 0. 0.25777004 0.25777004 0.25777004 0.51554009
0.25777004 0.25777004 0. 0. 0. 0.
0. 0.36681102 0.25777004 0.25777004 0. 0.
0. 0. ]
[0.1652829 0.23229935 0. 0. 0. 0.
0. 0. 0.23229935 0.23229935 0.4645987 0.4645987
0.23229935 0.3305658 0. 0. 0.23229935 0.23229935
0.23229935 0.23229935]]
通过计算词频和逆文本频率,TF-IDF 在考虑效率 的同时也得到了比较满意的效果。但由于 TF-IDF 仅仅考虑与词频相关的统计,没有关注单词与单词之间的联系。与独热表示相同,TF-IDF 依然存在向量维度较高、不能准确表示文本语义的缺点。
Word2Vec 模型
2013年,Google 团队提出了开源的训练词嵌入向量的工具Word2vec,它的核心思想是根据关键词去预测其上下文或根据关键词的上下文去预测关键词,从某种意义上讲词的向量化表示是模型训练的副产物。 Word2vec 词嵌入模型能够很好的表示词与词之间的类比关系和相似关系。Word2vec 模型包含两种结构:CBOW、skip-gram;和两种优化方法softmax、negative sampling。
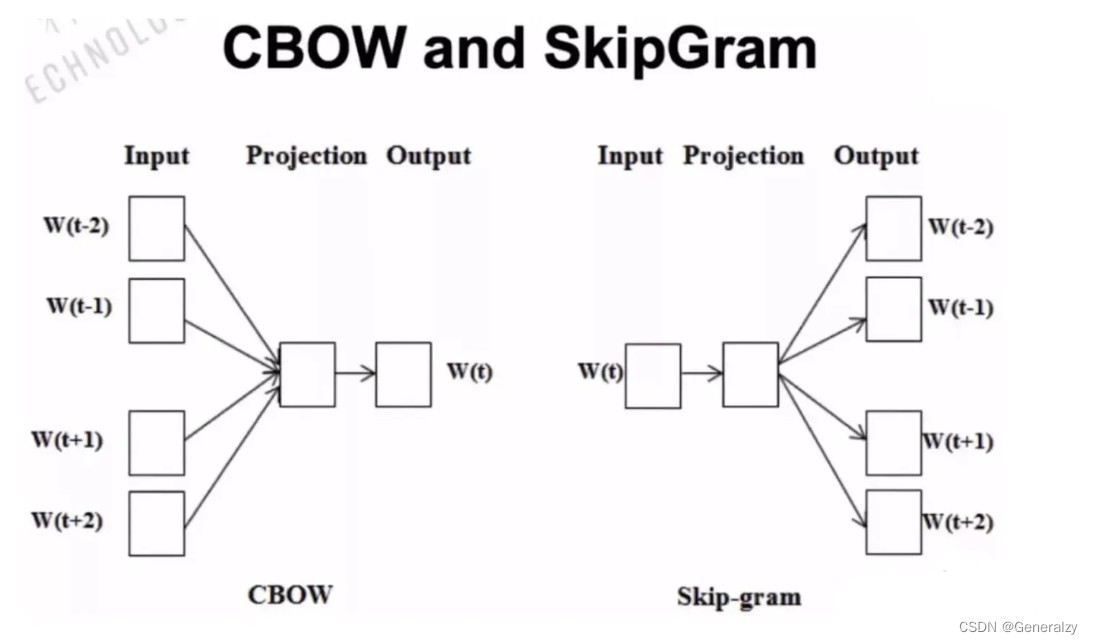
CBOW(连续词袋)模型
CBOW(continuous bag of words)模型的核心思想是:在一个句子中遮住目标单词,通过其前面以及后面的单词来推测出这个单词w。首先规定词向量的维度V,对数据中所有的词随机赋值为一个V维的向量,每个词向量乘以参数矩阵W(VN维矩阵),转换成N维数据,然后要对窗口范围内上下文的词向量相加取均值作为输入层输入到隐藏层,隐藏层将维度拉伸后全连接至输出层然后做 一个softmax的分类从而预测目标词。最终用预测出的w与真实的w作比较计算误差函数,然后用梯度下降调整参数矩阵。
skip-gram(跳字)模型
skip-gram模型的核心思想是:模型根据目标单词来推测出其前面以及后面的单词。它的模型结构与CBOW正好相反,只不过它的输入是目标词,输出是目标词的邻接词,从模型结构示意图上看相当于输入层与输出层交换位置,先将目标词词向量映射到投影层,再将投影层的输出作为输出层的输入,最后预测目标词窗口范围内的邻接词。
# 导入包
import numpy as np
from sklearn.manifold import TSNE
from gensim.models import Word2Vec
import jieba
import matplotlib.pyplot as plt
import random
import pandas as pd
# 加载停用词表,去除如“的”,“和”,“什么”等高频词
with open("stop_words.utf8", encoding='utf-8') as stop_words_f:
stop_words = [word.replace('\n', '') for word in stop_words_f]
data_df = pd.read_csv("cnews.test.csv",sep='\t',encoding='utf-8')
sent_list = [[word for word in jieba.cut(sent) if word not in stop_words] for sent in data_df['text']] # jieba中文分词
random.shuffle(sent_list) # 打乱
sent_list[:5] # 看一下都有哪些数据
'''
gensim.models.Word2Vec
size:词向量维度
min_count:忽略词频小于min_count的单词
window:一个句子中当前单词和被预测单词的最大距离
可以自己调整参数,观察现象
'''
model = Word2Vec(sent_list, size=100, min_count=5, window=5).wv
words_name = sorted(model.vocab.keys(), key=lambda word: model.vocab[word].count, reverse=True)[:200] #拿出n个最高频的词
words_vector = np.array([model.get_vector(i) for i in words_name])
words_zip = list(zip(words_name, words_vector))
words_zip[:5] # 看一下都有哪些数据
'''
TSNE:就是一种数据可视化的工具,能够将高维数据降到2-3维(降维),然后画成图。
n_components:降维数
'''
words_vector_tsne = TSNE(n_components=2).fit_transform(words_vector) # 高维词向量降维为2维
'''
matplotlib:画图工具,功能丰富
'''
plt.figure()
plt.rcParams['font.sans-serif'] = ['SimHei'] # 图中添加中文
plt.rcParams['axes.unicode_minus'] = False
plt.scatter(words_vector_tsne[:, 0], words_vector_tsne[:, 1])
for i, vec in enumerate(words_vector_tsne):
x, y = vec[0], vec[1]
plt.text(x, y, words_name[i], size=10)
plt.show() # 画图,可以发现,语义相近的词,在降维后位置同样相近
Word2Vec 的缺点是,由于其训练出来的词嵌入向量表示与单词是一对一的关系,一词多义问题还是没有解决。单词在不同上下文中是具有不一样含义的,而 Word2Vec 学习出来的词嵌入表示不能考虑不同上下文的情况。 通过 Word2Vec 等技术方法得到的静态的词嵌入表示,其本质上就是当模型训练好之后,在不同的上下文语境中,单词的词嵌入表示是一样的,不会发生改变。
GloVe 模型
GloVe模型是由斯坦福教授Manning、Socher等人于2014年提出的一种词向量训练模型。Word2vec模型只考虑到了词与窗口范围内邻接词的局部信息,没有考虑到词与窗口外的词的信息,没有使用语料库中的统计信息等全局信息,具有局限性。GloVe模型则使用了考虑全局信息的共现矩阵和特殊的损失函数,有效解决了 Word2vec的部分缺点。