- 熵 (Entropy):用于评估信息的随机性,常用于决策树和聚类算法。
- 交叉熵 (Cross-Entropy):用于衡量两个概率分布之间的差异,在分类问题中常用。
信息论作为处理信息量和信息传输的数学理论,在机器学习中具有广泛的应用。本文将围绕熵(Entropy)和交叉熵(Cross-Entropy),探讨它们的定义、公式推导、应用场景及代码实现。
1. 熵 (Entropy)
1.1 定义
熵衡量信息的不确定性或随机性。它可以理解为“信息的平均量”,即某一分布下每个事件的信息量的期望值。
1.2 数学公式
对于一个离散随机变量 X,取值为 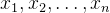
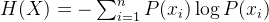
其中:
是事件
的概率;
- log 通常以 2 为底(信息量以比特为单位)或以 e 为底(信息量以 nat 为单位)。
1.3 推导过程
熵的来源可以从信息量(Information Content)定义出发:
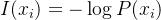
熵是信息量的加权平均值,因而有:
![H(X) = \mathbb{E}[I(x)] = -\sum_{i=1}^n P(x_i) \log P(x_i)](/image/aHR0cHM6Ly9sYXRleC5jc2RuLm5ldC9lcT9IJTI4WCUyOSUyMCUzRCUyMCU1Q21hdGhiYiU3QkUlN0QlNUJJJTI4eCUyOSU1RCUyMCUzRCUyMC0lNUNzdW1fJTdCaSUzRDElN0QlNUVuJTIwUCUyOHhfaSUyOSUyMCU1Q2xvZyUyMFAlMjh4X2klMjk%3D)
1.4 应用场景
- 决策树算法:选择分裂点时使用熵减少量(信息增益)。
- 聚类算法:评估聚类后类别分布的随机性。
- 语言模型:评估文本序列的不确定性。
1.5 熵的Python代码实现
import numpy as np
# 定义熵函数
def entropy(p):
return -np.sum(p * np.log2(p))
# 示例概率分布
p = np.array([0.5, 0.25, 0.25])
print("熵:", entropy(p))
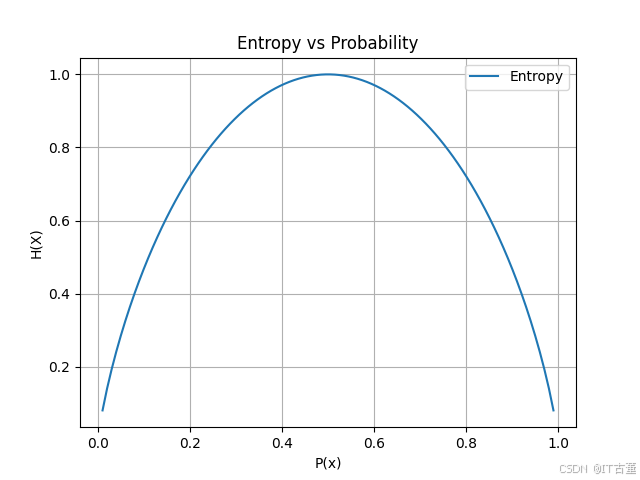
熵: 1.51.6 图示
熵的图示展示了单一事件概率分布变化时的熵值变化。
import matplotlib.pyplot as plt
import numpy as np
p = np.linspace(0.01, 0.99, 100)
entropy_values = -p * np.log2(p) - (1 - p) * np.log2(1 - p)
plt.plot(p, entropy_values, label='Entropy')
plt.xlabel('P(x)')
plt.ylabel('H(X)')
plt.title('Entropy vs Probability')
plt.legend()
plt.grid()
plt.show()
2. 交叉熵 (Cross-Entropy)
2.1 定义
交叉熵用于衡量两个概率分布之间的差异。给定真实分布 P 和预测分布 Q,其定义为:
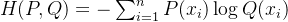
当 P 和 Q 相等时,交叉熵退化为熵。
2.2 推导过程
交叉熵的来源是 Kullback-Leibler (KL) 散度:
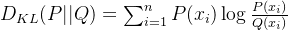
其中:
说明交叉熵包含了真实分布的熵和两分布之间的 KL 散度。
2.3 应用场景
- 分类问题:在机器学习中作为目标函数,尤其是多分类问题中的 Softmax 回归。
- 语言模型:衡量生成模型输出的分布与目标分布的匹配度。
- 聚类算法:评估聚类后的分布与目标分布的差异。
2.4 交叉熵的Python代码实现
import numpy as np
# 定义交叉熵函数
def cross_entropy(p, q):
return -np.sum(p * np.log2(q))
# 示例真实分布和预测分布
p = np.array([1, 0, 0]) # 实际类别
q = np.array([0.7, 0.2, 0.1]) # 预测分布
print("交叉熵:", cross_entropy(p, q))
交叉熵: 0.51457317282975832.5 图示
交叉熵的图示对比了真实分布和不同预测分布间的差异。
import matplotlib.pyplot as plt
import numpy as np
def cross_entropy(p, q):
return -np.sum(p * np.log2(q))
p = np.array([1, 0, 0])
q_values = [np.array([0.7, 0.2, 0.1]), np.array([0.4, 0.4, 0.2])]
ce_values = [cross_entropy(p, q) for q in q_values]
labels = ['Q1 (Closer)', 'Q2 (Further)']
plt.bar(labels, ce_values, color=['blue', 'orange'])
plt.title('Cross-Entropy Comparison')
plt.ylabel('Cross-Entropy')
plt.show()
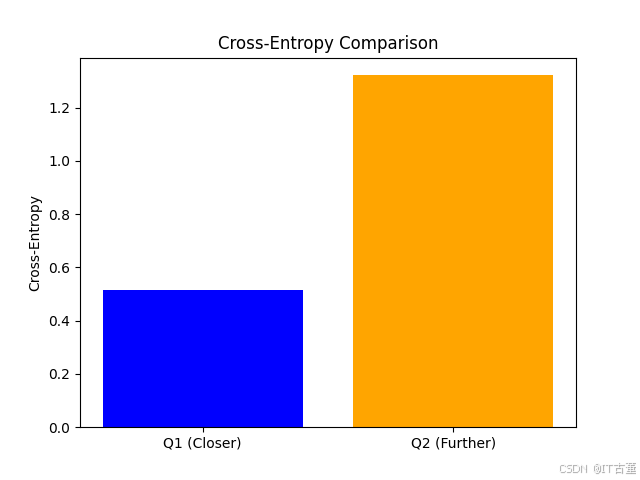
3. 实际案例:分类问题中的交叉熵
在图像分类中,交叉熵是常用的损失函数。对于一个三类分类问题:
- 真实类别为 [1, 0, 0]。
- 模型预测的概率分布为 [0.7, 0.2, 0.1]。
交叉熵计算结果为 0.514,比完全随机预测([1/3, 1/3, 1/3])的交叉熵小,表明模型预测效果更好。
总结
熵和交叉熵是信息论中的核心概念,其在机器学习中的重要性不可忽视。通过公式理解、代码实现和图示分析,我们可以更好地掌握这些工具,并有效地将其应用于实际问题中。
拓展阅读
【机器学习】数学知识:对数-CSDN博客
【机器学习】机器学习中用到的高等数学知识-2.概率论与统计 (Probability and Statistics)_机器学习概率-CSDN博客