一、HBase是什么
HBase是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可以在廉价PC Server上搭建起大规模结构化存储集群。
1、HBase的基本架构
一、HBase是什么
HBase是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可以在廉价PC Server上搭建起大规模结构化存储集群。
1、HBase的基本架构
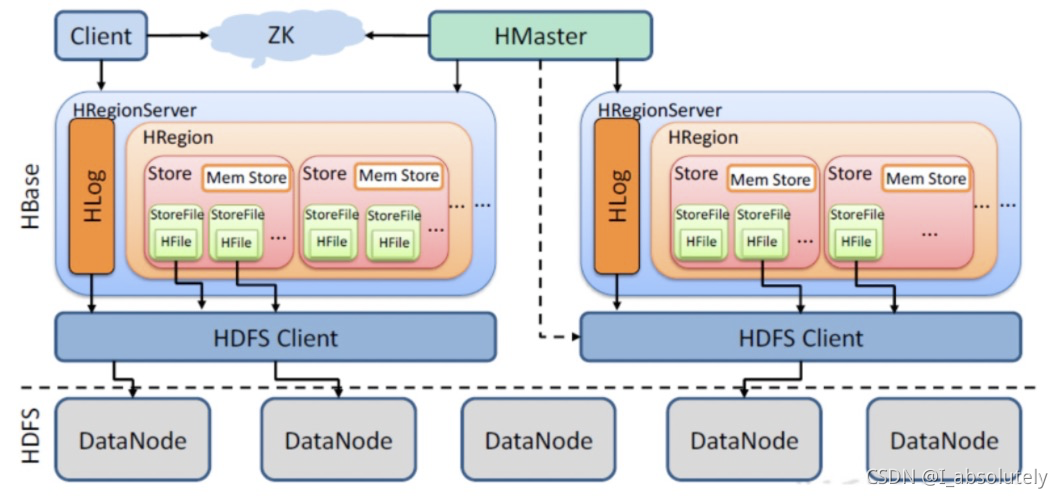
典型的主从架构
-
Master
Master是所有Region Server 的管理者,其实现类为HMaster,主要作用
- 对于表的操作:create、delete、alter
- 对于Region Server的操作:分配Region到每个RegionServer,监控每个RegionServer的状态,负载均衡和故障转移
-
RegionServer
RegionServer为Region的管理者,其实现类为HRegionServer,主要作用如下:
- 对于数据的操作:get、put、delete
- 对于Region的操作:splitRegion、compactRegion
-
Zookeeper
- HBase通过Zookeeper实现Master的高可用、RegionServer的监控、元数据的入口以及集群配置的维护等工作。
-
HDFS
- HDFS为HBase提供最终的底层数据存储服务,同时为HBase提供高可用的支持
-
StoreFile
- 保存实际数据的物理文件,StoreFile以File的形式存储在HDFS上。每个Store会有一个或多个StoreFile(HFile),数据在每个StoreFile中都是有序的
-
MemStore
- 写缓存,由于HFile中的数据要求有序的,所以数据存储在Memstore中,排好序后,等到达刷写时机才会刷写到HFile,每次刷写都会形成一个新的HFile
-
WAL
- 为了解决数据在内存中丢失的情况,数据会先写在一个叫做Write-Ahead log的文件中,然后再写入MemStore中。所以在系统出现故障的时候,数据可以通过这个日志文件重建
2、HBase的基本架构
从HBase的底层物理存储结构(K-V)来看,HBase更像是一个multi-dimensional map。
(1)Name Space
命名空间,类似于关系型数据库DataBase的概念,每个命名空间下有多个表。HBase有两个自带的命名空间,分别为hbase和default,hbase中存放的是HBase的内置表,default是用户默认使用的命名空间。
(2)Table
HBase定义表时只需要声明列族即可。
特点:
- 大:单表可以数十亿行,数百万列
- 无模式:同一个表的不同行可以有截然不同的列
- 面向列:存储、权限控制、检索均面向列
- 稀疏:空列不占用存储,表是稀疏的
- 多版本:每个单元中的数据可以有多个版本,默认版本号是插入的时间戳
- 数据类型单一:数据都是字符串,没有类型
(3)Region
在HBase中一个Table横向分成多个分区,每个分区叫做一个Region,不同的Region分布在不同的服务器上实现分布式的存取。Region是HBase中分布式存储和负载均衡的最小单元。
(4)Rowkey
HBase表中每行数据都由一个Rowkey和多个Column(列)组成,数据按照Rowkey进行字典序排序,只能根据Rowkey进行检索。
注意:HBase只有Rowkey索引,没有二级索引。
(5)Column
HBase 中的每个列都由Column Family(列族)和Column Qualifier(列限定符)进行限定。
(6)Timestamp
用于标识数据不同版本。
二、HBase操作
1、写流程
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LLzwDHEI-1630326558056)(/Users/juzi/Library/Application Support/typora-user-images/image-20210830193850739.png)]](/image/aHR0cHM6Ly9pLWJsb2cuY3NkbmltZy5jbi9ibG9nX21pZ3JhdGUvNDYyYWU1MWEzYzFhZTExZGVlZGI4MGY5NWM2NWQ1NzAucG5n)
写流程:
-
Client先访问Zookeeper,获取hbase:meta 表位于哪个RegionServer
-
Client访问对应的RegionServer,获取到base:meta表,根据读请求的namespace:table/rowkey,查询出目标数据位于哪个RegionServer的哪个Region中。并将Table的Region信息和meta表的位置信息缓存在客户端的meta cache中,方便下次访问
-
Client请求目标的RegionServer
-
将数据追加写入到WAL
-
对数据写入到对应的MemStore,数据会在MemStore中排序
-
向Client发送ack
-
等达到MemStore的刷写时机后,将数据刷写到HFile
2、Flush
MemStore的刷写时机:
- 当某个MemStore的大小达到了hbase.hregion,memstore.flush.size(默认128M),其所在的region中所有的memstore都会刷写;当memstore的大小达到hbase.hregion,memstore.flush.size(默认128M) * hbase.hregion.memstore.block.multiplier(默认4)时,会阻止继续往该memstore写数据
- 当RegionServer中MemStore的总大小达到java.heapsize * hbase.regionserver.global.memstore.size(默认0.4)* hbase.regionserver.global.memstore.size.lower.limit(默认0.95),region会按照memstore大小一次进行刷写,直到regionserver中总的memstore值小于上述值
- 到达自动刷写的时间,也会触发flush。hbase.regionserver.optionalcacheflushinterval(默认1小时)
- 当WAL文件的数量超过hbase.regionserver.max.logs,region会按照时间顺序依次进行刷写,直到WAL文件数量减小到hbase.regionserver.max.logs以下
3、读流程
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AW28Eshg-1630326558056)(/Users/juzi/Library/Application Support/typora-user-images/image-20210830195250971.png)]](/image/aHR0cHM6Ly9pLWJsb2cuY3NkbmltZy5jbi9ibG9nX21pZ3JhdGUvMjdjOWQ5ZWY2Y2JmNmMyYmEzY2U0MTQwNzRjYzRmNTEucG5n)
读流程:
- Client 先访问zookeeper,获取hbase:meta 表位于哪个Region Server
- 访问对应的Region Server,获取hbase:meta 表,根据读请求的namespace:table/rowkey,查询 出目标数据位于哪个Region Server 中的哪个Region 中。并将该table 的region 信息以及meta 表的位置信息缓存在客户端的meta cache,方便下次访问
- 与目标Region Server 进行通讯
- 分别在Block Cache(读缓存),MemStore 和Store File(HFile)中查询目标数据,并将查到的所有数据进行合并。此处所有数据是指同一条数据的不同版本(time stamp)或者不同的类型(Put/Delete)
- 将从文件中查询到的数据块(Block,HFile 数据存储单元,默认大小为64KB)缓存到BlockCache
- 将合并后的最终结果返回给客户端
4、StoreFile Compaction
- Minor Compaction:会将临近的若干个较小的HFile合并成一个较大的HFile,但不会