前言
预处理阶段:js在编译代码时有一个预处理阶段,这个过程会将原本的代码进行分割处理;
源程序 ---> 预处理块+ 剩余代码块
预处理块中的代码会优先于剩余代码块中的代码执行
什么是变量提升,函数提升
变量提升:当声明一个变量时,这个声明过程会被预处理机制塞入到预处理块中优先执行,这就是变量提升,使用var定义的变量拥有变量提升
函数提升:当声明一个函数时,这个声明过程会被预处理机制塞入到预处理块中优先执行,这就是函数提升,使用function定义的函数拥有函数提升
提升的判断:当一个变量和函数在正常的顺序中没有声明但被调用时就可能产生“提升”
变量提升
变量提升,将变量名放入预编译的词法环境 var a(undefined)
console.log(a);
var a = 1;以上的代码会产生变量提升,它等价于下面的代码,
{// 模拟预处理块
var a;
}
// 正常执行的剩余代码块
console.log(a); // undefined
a = 1;因为变量提升的缘故,a会在打印执行前被声明,所以会打印成undefined
函数提升
函数提升,将函数体放入预编译的词法环境 function b(){}
console.log(b);
function b(){
console.log('b')
};以上的代码会产生函数提升,它等价于下面的代码,
{// 模拟预处理块
function b(){
console.log('b')
};
}
// 正常执行的剩余代码块
console.log(b);function声明的函数都存在函数提升,所以可以在声明函数之前使用函数(先写出函数的用法,在完成函数的实现)
关于变量提升和函数提升的判断
了解了基本的变量提升和函数提升,接下来开始区分一些二者的区别和同时在场的优先级
1.变量赋值的函数
console.log(a);
var a = function(){
console.log('a')
};很显然这是由var声明的变量,拥有变量提升,只不过它的值是一个函数体
{// 模拟预处理块
var a;
}
// 正常执行的剩余代码块
console.log(a); // undefined
a = function(){
console.log('a')
};所以这个a会打印成undefined
2.优先级判断
console.log(b);
var b = function(){
console.log('b1')
};
function b(){
console.log('b2')
};
console.log(b);函数提升的优先级是比变量提升的优先级大的,当出现声明同名的变量和函数时,在预处理块中最终都会变成函数,
{// 模拟预处理块
var b;
function b(){
console.log('b2')
};
}
// 正常执行的剩余代码块
console.log(b);// 能打印'b2'的函数
b = function(){
console.log('b1')
};
console.log(b);// 能打印'b1'的函数除了上面这种优先级的理解方式,还有下面这种,将function声明拆成了两个部分,先声明函数名,在赋值函数体,而变量的声明在它们之间
{// 模拟预处理块
function b
var b;
b = function(){
console.log('b2')
};
}
// 正常执行的剩余代码块
console.log(b);// 能打印'b2'的函数
b = function(){
console.log('b1')
};
console.log(b);// 能打印'b1'的函数tips:以上两种方式的结果是一样的,采用哪种分析方式都可以
3.同名参数名,变量名,函数名的优先级判断
同名参数名,变量名的判断
var foo = 'hello';
(function(foo){
console.log(foo);
var foo = foo || 'world';
console.log(foo);
})(foo);
console.log(foo);这里只分析了立即执行函数内的预处理
var foo = 'hello';
(function(foo){
// 模拟立即执行函数内的预处理块
{
var foo;
foo = foo; //传入的参数('hello')
}
// 正常执行的剩余代码块
console.log(foo);
foo = foo || 'world';
console.log(foo);
})(foo);
console.log(foo);所以最后连续打印了3个hello,传入的参数会在预处理中声明后赋值给同名变量,foo不为undefined,后面的赋值就不会变成world
当同名参数名,变量名,函数名同时存在
function fn (m){
console.log(m);
var m = 1;
function m(){
}
console.log(m);
}
fn(10)同样有两种理解方式
function fn (m){
// 模拟预处理块
{
var m;
m = m;// 传入的参数(10)
function m(){
}
};
}
// 正常执行的剩余代码块
console.log(m);// function(){}
m = 1;
console.log(m);// 1
}
fn(10)function fn (m){
// 模拟预处理块
{
function m
var m;
m = m;// 传入的参数(10)
m = function(){
}
};
}
// 正常执行的剩余代码块
console.log(m);// function(){}
m = 1;
console.log(m);// 1
}
fn(10)可以看到这个函数的输出和传入的参数没有任何关系,因为传入的参数会在函数提升的前面(函数体赋值的前面),导致传入的参数被覆盖
总结
所以可以得出同名参数名,变量名,函数名的预处理顺序为:
变量提升---参数传递---函数提升 (声明函数名---变量提升---参数传递---函数体赋值)
所以最终这个名称会被函数夺取,这就是函数提升优先级最高的原因
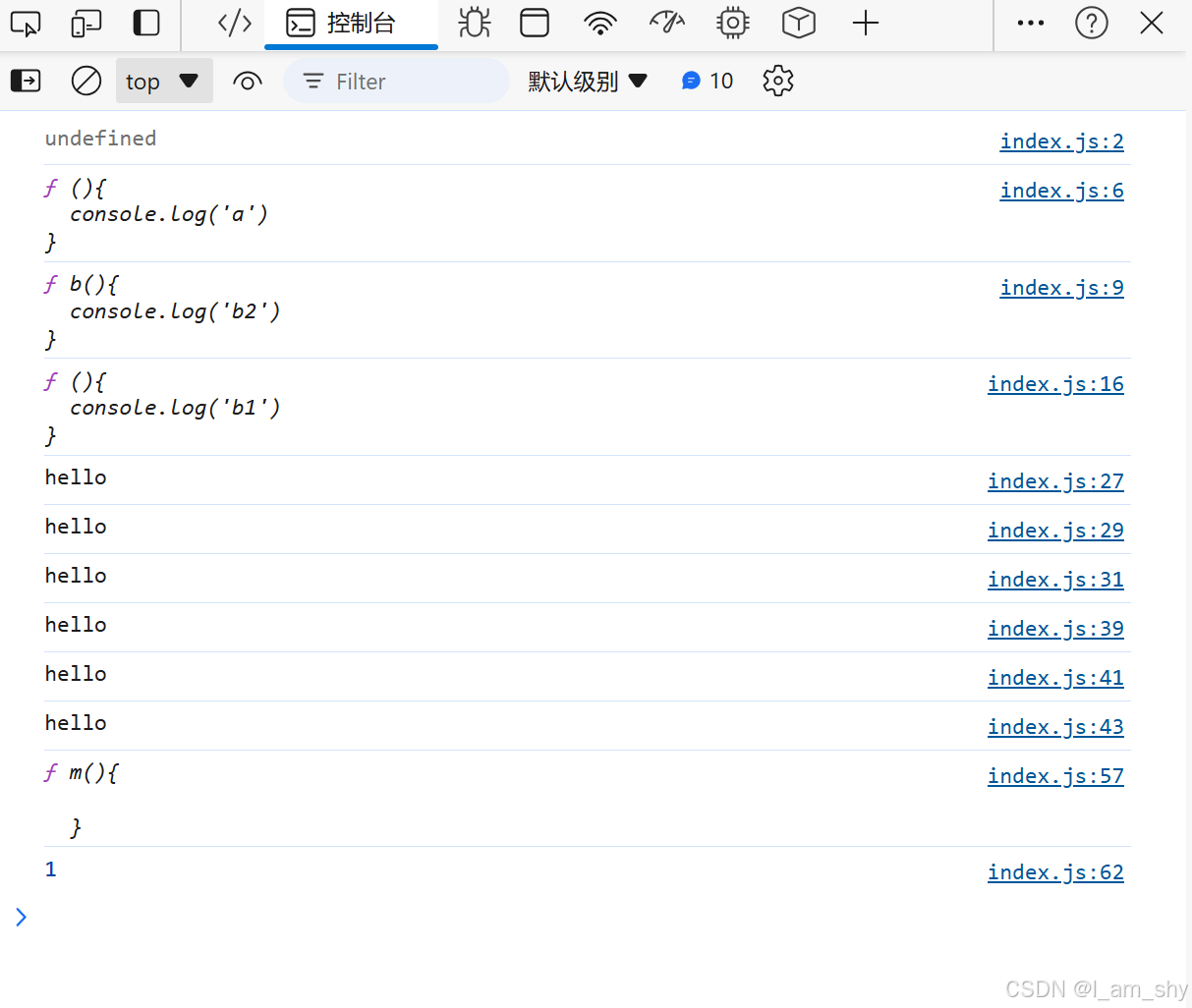
完整代码和运行结果展示
// 变量提升,将变量名放入预编译的词法环境 var a(undefined)
console.log(a);
var a = function(){
console.log('a')
};
console.log(a);
// 函数提升,将函数体放入预编译的词法环境 function b(){}
console.log(b);
var b = function(){
console.log('b1')
};
function b(){
console.log('b2')
};
console.log(b);
// function b 函数名提升
// var b 变量名提升
// b = (){} 函数体初始化
// 因为函数体初始化总在变量名之后,所以每次都是优先预编译成函数
// 结合自执行函数
var foo = 'hello';
(function(foo){
console.log(foo);
var foo = foo || 'world';
console.log(foo);
})(foo);
console.log(foo);
// 依次输出 hello hello hello
// 预编译后
var foo = 'hello';
(function (foo) {
var foo; // undefined;
foo= 'hello'; //传入的foo的值
console.log(foo); // hello
foo = foo || 'world';// 因为foo有值所以没有赋值world
console.log(foo); //hello
})(foo);
console.log(foo);// hello,打印的是var foo = 'hello' 的值(变量作用域)
// function m(){
// console.log('m');
// };
// var m;
// m =1;
// function m(){
// }
// console.log(m)
function fn (m){
console.log(m);
var m = 1;
function m(){
}
console.log(m);
}
fn(10)
// function m
// var m
// 参数m
// m = (){}
// m = 1
// function > parmas > var