手把手教你入门绘图超强的AI绘画程序Stable Diffusion,用户只需要输入一段图片的文字描述,即可生成精美的绘画。给大家带来了全新Stable Diffusion保姆级教程资料包(文末可获取)
图生图功能初识
1.1 传统意义上的喂参考图
我们都知道,模型在运算时是根据我们提供的提示内容来确定绘图方向,如果没有提示信息,模型只能根据此前的学习经验来自行发挥。在之前的文生图篇,我们介绍了如何通过提示词来控制图像内容,但想要实现准确的出图效果,只靠简短的提示词是很难满足实际需求的。
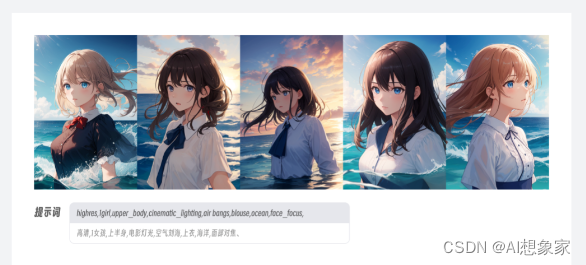
AI绘画的随机性导致我们使用大段的提示词来精确描述我们想要的画面内容,但毕竟文字能承载的信息量有限,即使我们写了一大段咒语,模型也未必能准确理解,不排除有时候还会出现前后语义冲突的情况。其实这个过程就像甲方给我们明确设计方向,除了重复沟通想要的画面内容外,有没有什么比口述更高效的沟通方式呢?这个时候,有经验的甲方会先去找几张目标风格的竞品图,让我们直接按照参考图的感觉走。
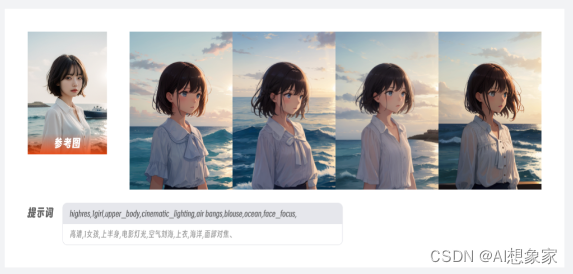
【感觉】这个词听起来似乎虚无缥缈,但在AI绘画领域是有实际道理的,因为图像能承载的信息要比文字多得多。以上面这张图为例,如果用提示词描述,可能写上几百字都难以向模型解释清楚画面的内容,但图生图不同,模型会自动从参考图上提取像素信息,并将其作为特征向量准确映射到最终的绘图结果上,通过这样的方式能最大程度还原参考图中的提示信息,实现更稳定准确的出图效果。
因此,传统意义上的图生图就是将提示词和参考图中的图像信息进行综合考虑并进行绘图的过程。
1.2 真正强大的图像重绘
当然,如果仅仅是喂图功能,Stable Diffusion的图生图板块并不值得我们单独花一篇文章来讲解,它的真正价值在于提供了丰富的操作工具将图像可控性提升到了新的层次。
我们先来回顾下平时使用文生图进行AI绘画的过程:编写提示词进行绘图,然后根据出图结果再不断优化提示词和各类参数进行抽奖,最终得到一张比较满意的图片。而图生图则是直接根据现有图片进行优化调整,因此图生图的操作过程可以简单理解成省去了前期文生图的抽奖过程,直接在现有图像约束的基础上进行的二次重绘。

需要注意的是,配合参考图进行图生图的过程是需要将参考图先逆向推导为潜空间的数据,再和提示词综合考虑绘制成图像。因此相比没有逆向推导过程的文生图,图生图的绘制会占用更多的系统资源,根据这个原理,我们也就能理解使用参考图的尺寸越大,在逆向推导的过程中消耗的资源也会越多。

在Stable Diffusion中,我们可以通过蒙版和局部重绘等功能来控制只对图像特定部分的区域进行重绘,并设置各类参数来控制重绘的效果。此外通过选择不同的绘图模型和调整图像尺寸,我们也能甚至还能实现画风转换、图像无损放大等更多玩法。相较于其他AI绘画工具,Stable Diffusion中的图生图并非单纯的喂参考图,而是可以在现有图片的基础上通过人工干预来实现更加稳定可控的图像重绘。
图生图工具解析
在WebUI的功能导航栏中选择图生图模块,我们可以看到它的页面布局和文生图基本类似,同样有提示词输入框、操作按钮和参数设置项,不同的是这里多了提示词反推、支持上传图片的二级功能模块和对应的参数设置项。
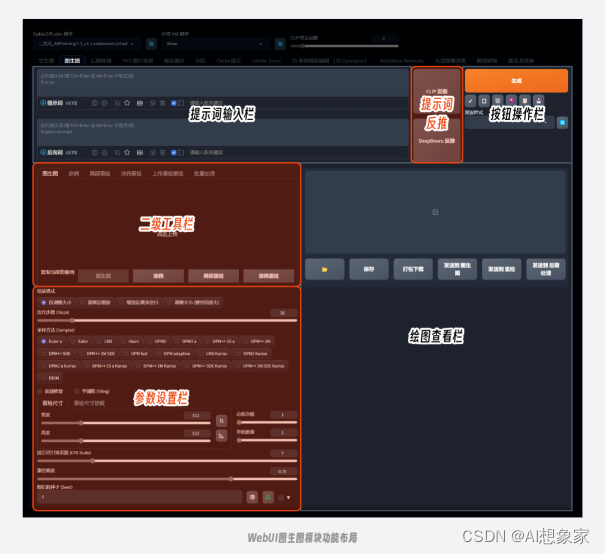
2.1 提示词反推
先来看提示词反推的功能:即根据提供的图片自动反推出匹配的文本关键词,也就是我们俗称的图生文功能。WebUI这里提供了Clip反推和DeepBooru反推2种反推操作,其区别在于:
Clip反推:推导出的文本倾向于自然语言的描述方式,即完整的描述短句,该功能的特点是可以描述出画面中对象间的关系
DeepBooru反推:推导结果更多的是单词或短句,比较类似我们平时书写提示词的方式,该功能更倾向于描述对象特征

不难看出,通过Clip和DeepBooru反推的提示词中包含不少错误标签,需要人工进行二次筛选。其实,WebUI在图生图模块内置提示词反推是为了在上传图片后可直接获取相应的参考关键词,以便后面更好的通过提示词来控制重绘图像内容。但实际上我们平时反推提示词时更常使用的是秋叶整合包中自带的Tagger插件,该插件除了生成的提示词准确度和稳定更高,还提供了关键词分析和排名展示,属于Stable Diffusion的必备插件之一。
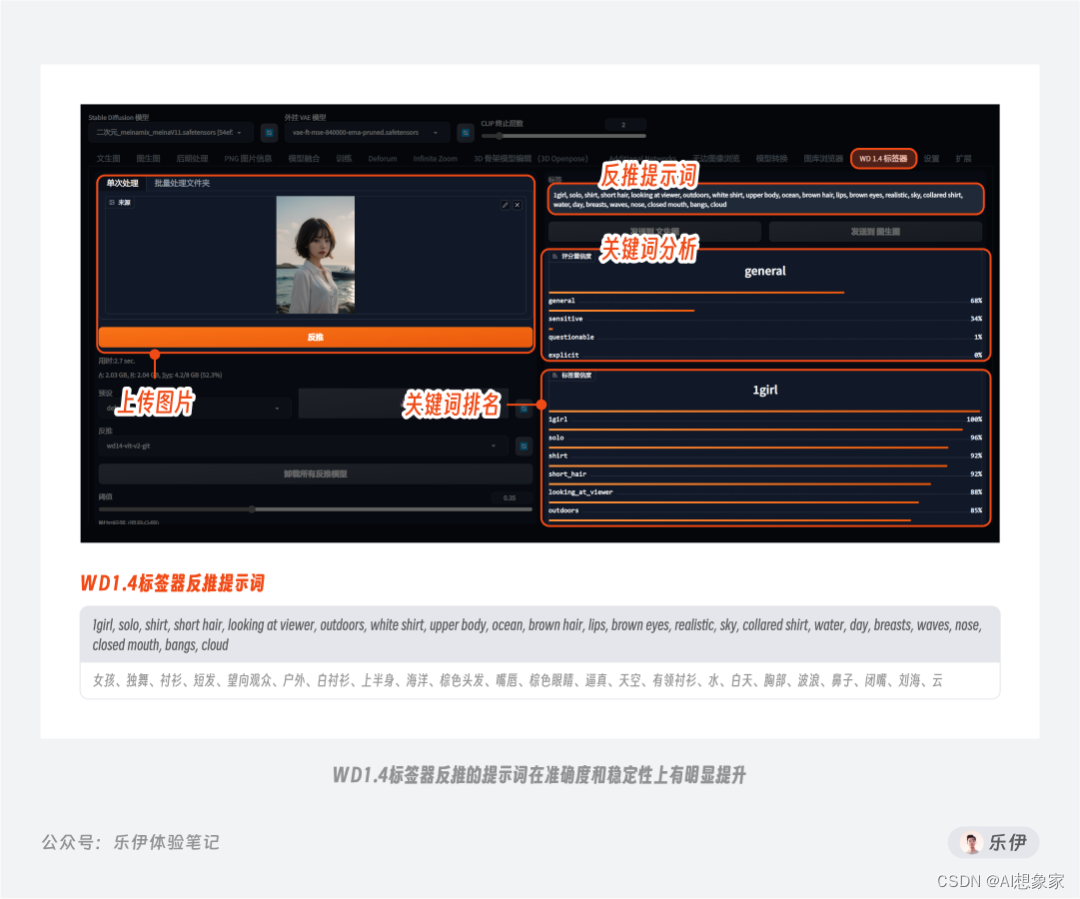
在Stable Diffusion中有非常多类似的开源插件可以有效提升绘图效率,但不属于本篇文章重点,这里就不过多介绍了。
2.2 二级工具栏概览
在图生图模块中为我们内置了许多二级工具栏,