文章目录
GPT-Fathom: Benchmarking Large Language Models to Decipher the Evolutionary Path towards GPT-4 and Beyond

探秘GPT-3到GPT-4进化之路
1、SFT:早期GPT进化的推动者
SFT只在较弱的基础模型上管用,用在更强的模型上收效甚微。类似现象在开源模型身上也可见(这个评测还测了Llama1和2、PaLM2-L、Claude 2等模型):
在初代Llama-65B之上,SFT成功提升了它在MMLU基准上的性能,但是,所有使用了SFT改进的Llama2-70B在Open LLM Leaderboard榜单上却只表现出微小的进步。
总结:在GPT3阶段,SFT技术对模型的进化起到了关键作用。
2、RLHF和SFT:编码能力提升的功臣
顺着GPT3.5系列接着看,从text-davinci-002开始,OpenAI开始引入新技术基于PPO算法的RLHF,得到text-davinci-003。
此时,它在大部分基准上的表现和前代模型持平或略变差,说明作用不是特别明显(在开源模型身上也是如此)。
但有一个除外:编码任务,最高足足增加了近30分。
LLM仍可以通过SFT和RLHF,不断将内在能力(但需要多次尝试)转化成一次性解决问题的能力,不断逼近LLM的能力上限。
3、代码加入预训练,对推理帮助最大
在GPT4进化之路上,还出现了2个特别的模型:
code-cushman-001 (Codex-12B) 和code-davinci-002。
前者是OpenAI初次尝试使用代码数据训练模型,尽管它的规模较小,但也取得了不错的代码能力。后者是GPT3.5的基座模型,它是在GPT3的基础上使用RLHF+代码训练的结果,也就是文本和代码混合预训练。
可以看到,它大幅超越GPT-3(不止是编码能力)、在一些推理任务上(如BBH)表现甚至可以超过后面的gpt-3.5-turbo-0613。
4、“跷跷板”现象
通过比较2023年3月和2023年6月的OpenAI API模型,我们确实可以发现这一现象:
与gpt-3.5-turbo-0301相比,升级后的gpt-3.5-turbo-0613在HumanEval上表现出色(53.9 -> 80.0),但在MATH上却大幅下降(32.0 -> 15.0)。
gpt-4-0613在DROP上的表现优于gpt-4-0314 (78.7 -> 87.2) ,但在MGSM上也出现了直线下降(82.2 -> 68.7) 。
作者认为:
“跷跷板现象”可能成为LLM通往AGI之路的绊脚石,因为AGI强调“通用智能”,要在所有task上都有优异的性能,要求模型不能“偏科”。在此,他们也呼吁社区重视这个问题,共同推进大模型平衡发展的研究。
论文地址
https://arxiv.org/abs/2309.16583
项目链接
https://github.com/GPT-Fathom/GPT-Fathom
Reference
https://mp.weixin.qq.com/s/-AWkDzAzoyQNmgYXuC6B4w
Easter Egg (彩蛋)
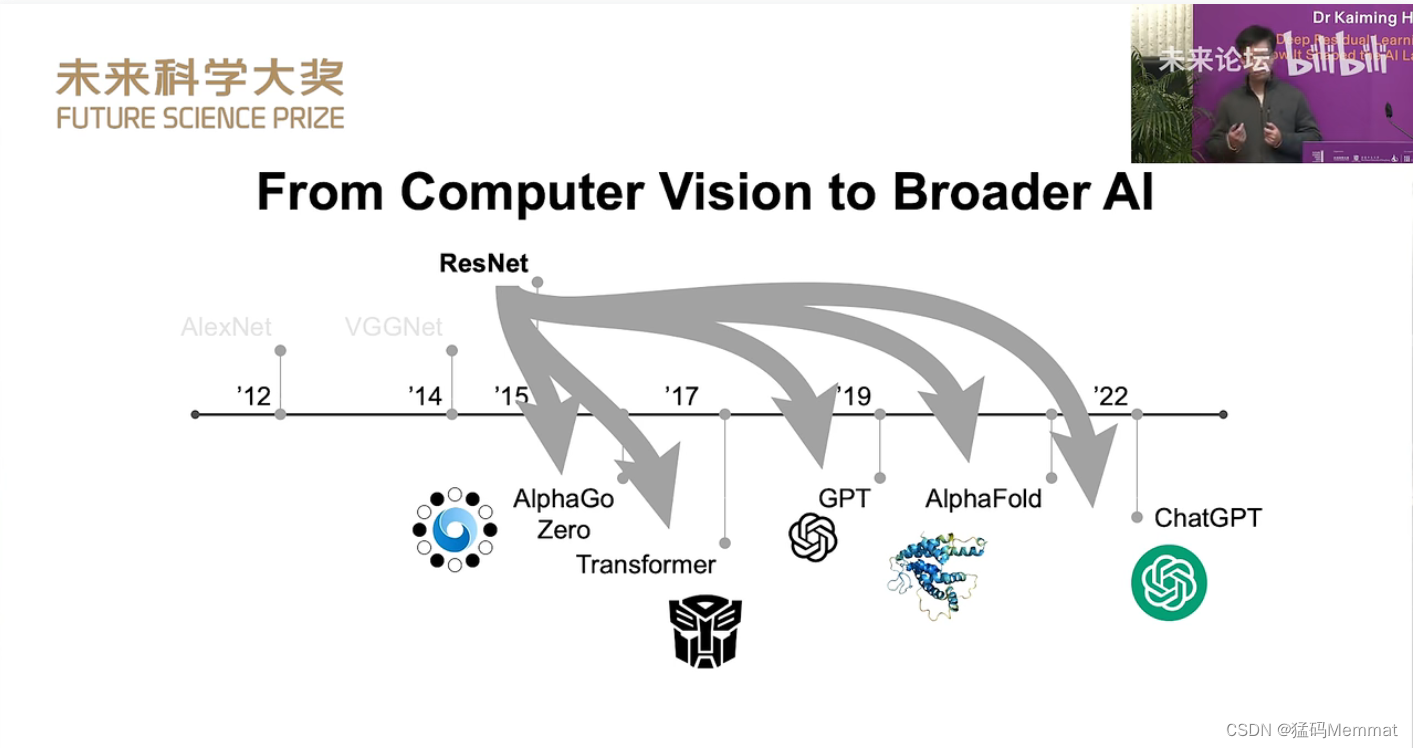
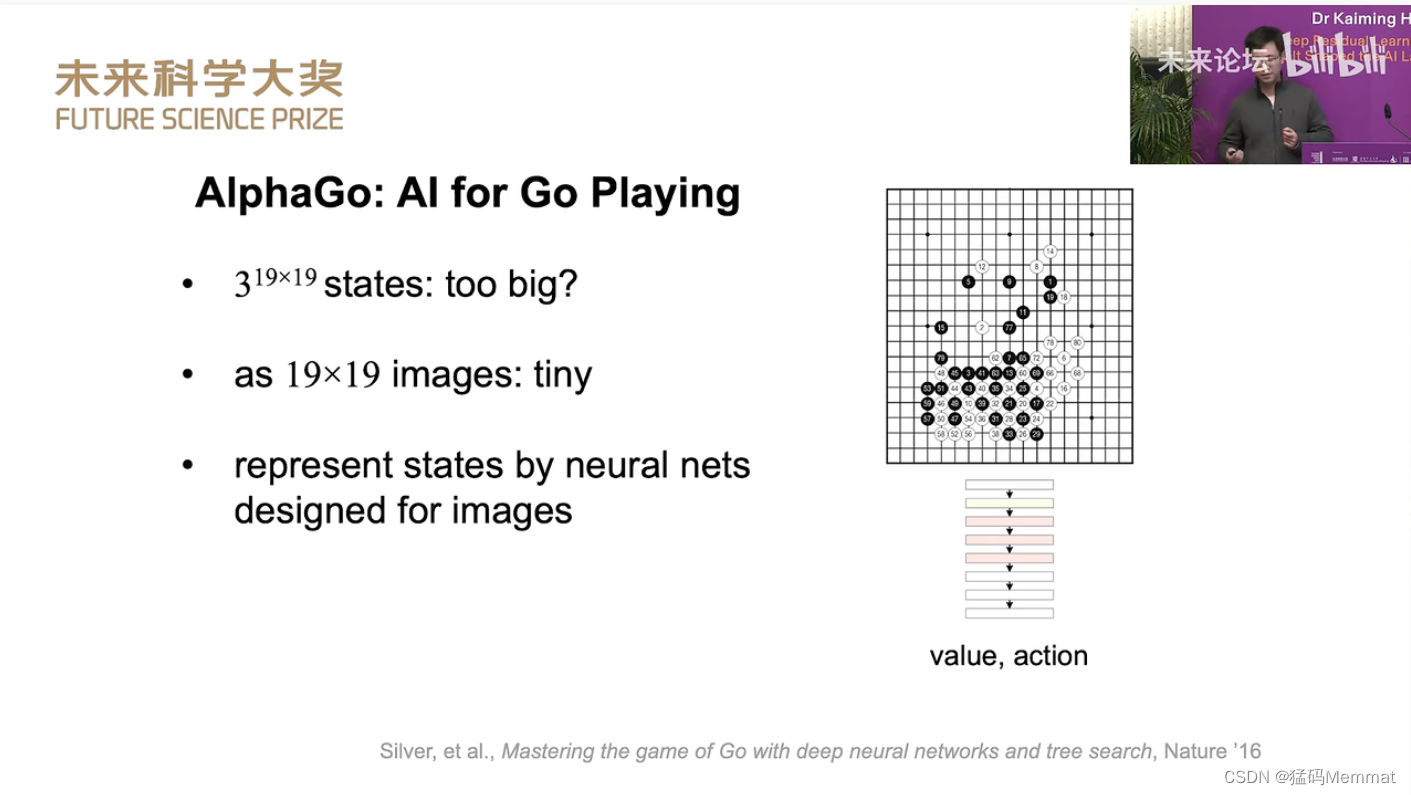
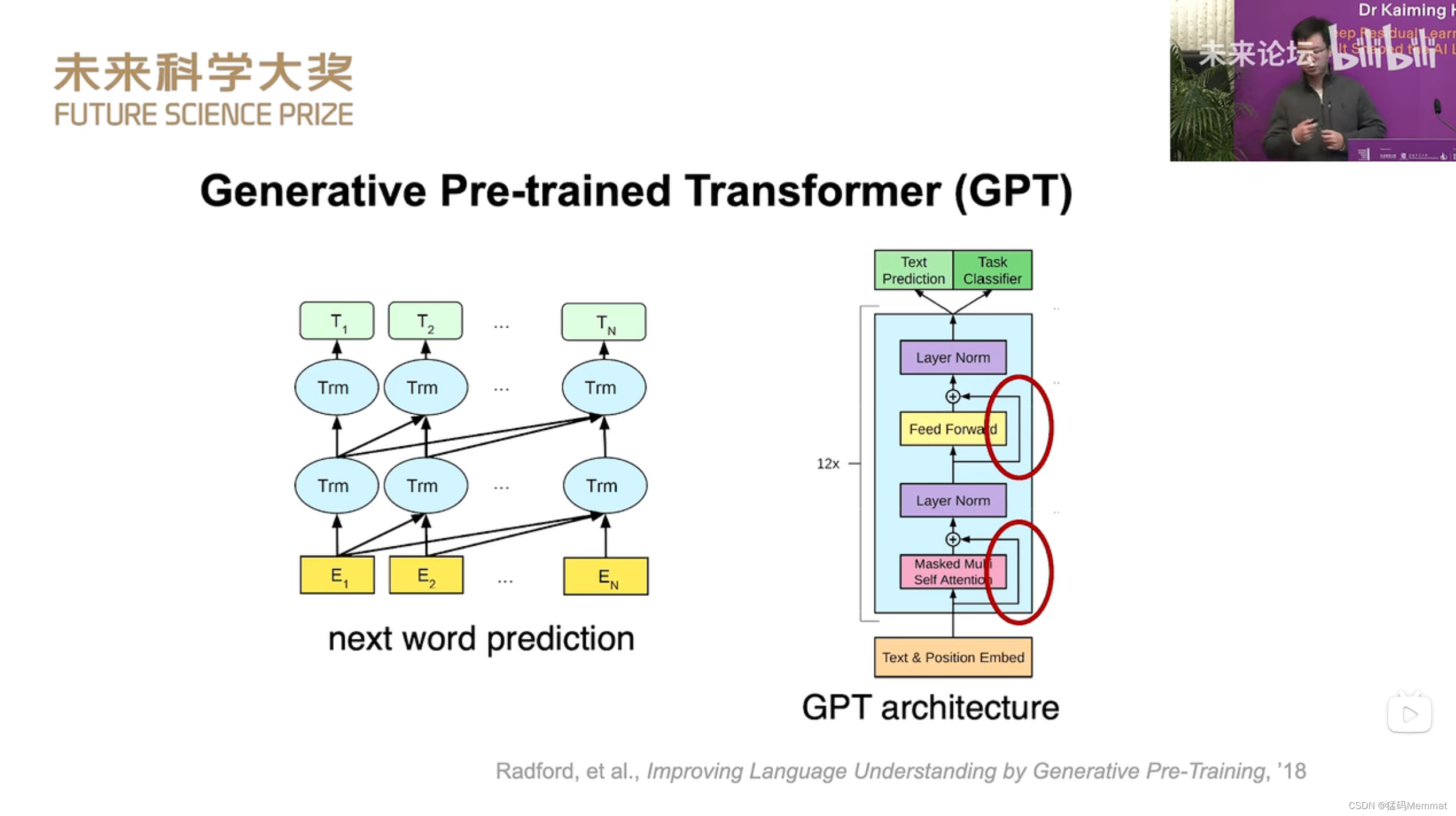
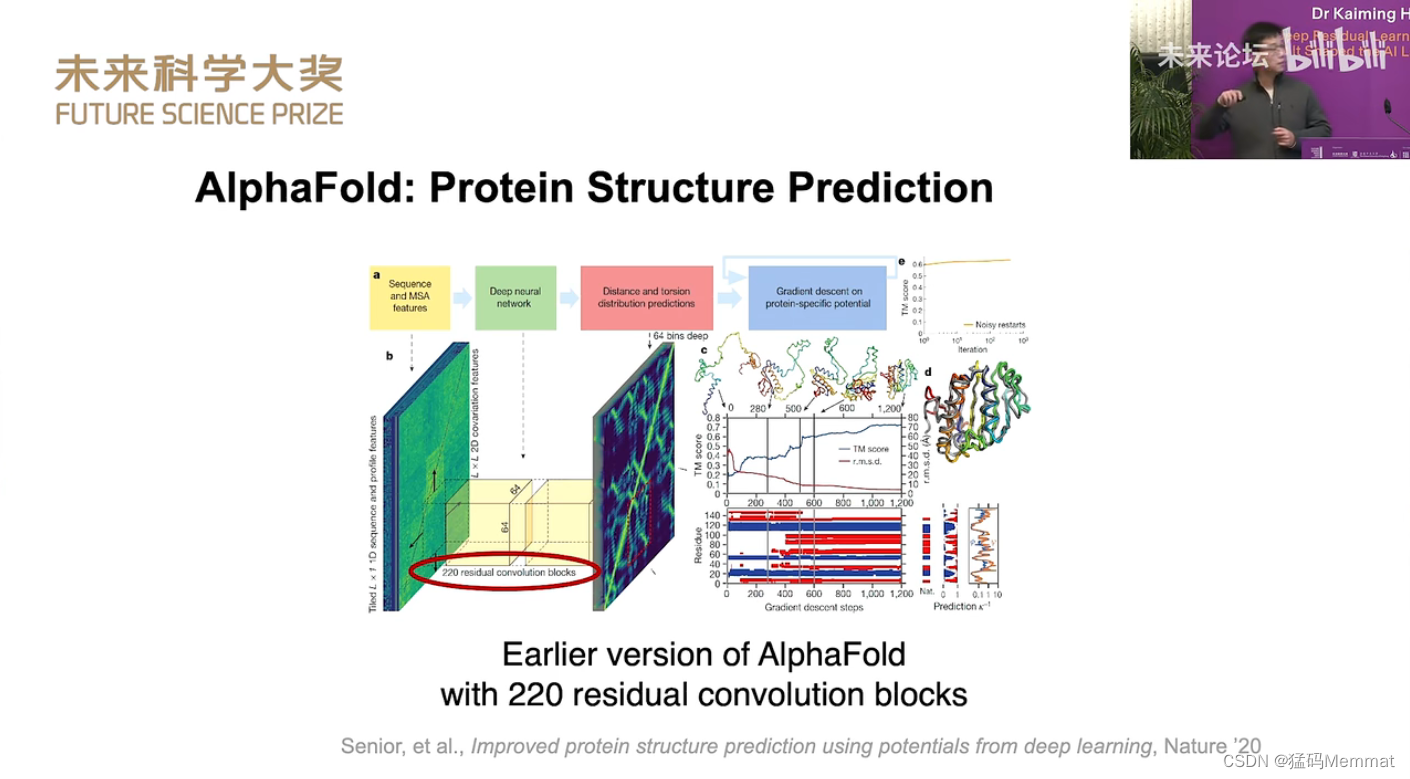
2023未来科学大奖获奖者学术报告会。何恺明博士:深度残差学习及其如何塑造人工智能模式。