finl是做流式计算的大数据工具
官网:Apache Flink Documentation | Apache Flink
Flink官方提供了Java、Scala、Python语言接口用以开发Flink应用程序
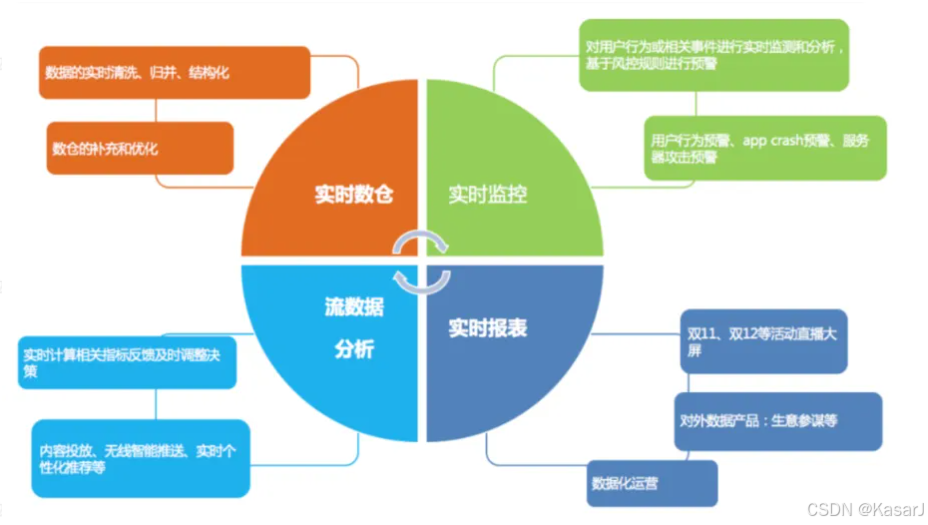
Fink的应用场景:
Standalone集群模式安装部署
Flink支持多种安装模式。
local(本地)——本地模式
standalone——独立模式,Flink自带集群,开发测试环境使用
standaloneHA—独立集群高可用模式,Flink自带集群,开发测试环境使用
yarn——计算资源统一由Hadoop YARN管理,生产环境测试
下载链接:
https://archive.apache.org/dist/flink/flink-1.13.1/flink-1.13.1-bin-scala_2.11.tgz
安装之后要配置环境变量
export FLINK_HOME=自己fink的位置
export PATH=$PATH:$FLINK_HOME/bin
export HADOOP_CONF_DIR=hadoop的位置修改配置文件:
cd到flink的conf文件下flink/conf/flink-conf.yaml
jobmanager.rpc.address: bigdata01
taskmanager.numberOfTaskSlots: 2
web.submit.enable: true
#历史服务器 如果HDFS是高可用,则复制core-site.xml、hdfs-site.xml到flink的conf目录下 hadoop11:8020 -> hdfs-cluster
jobmanager.archive.fs.dir: hdfs://bigdata01:9820/flink/completed-jobs/
historyserver.web.address: bigdata01
historyserver.web.port: 8082
historyserver.archive.fs.dir: hdfs://bigdata01:9820/flink/completed-jobs/flink/conf/masters
bigdata01:8081flink/conf/workers
bigdata01
bigdata02
bigdata03将资料下的flink-shaded-hadoop-2-uber-2.7.5-10.0.jar放到flink的lib目录下
将配置分发给三台虚拟机
xsync.sh /opt/installs/flink
xsync.sh /etc/profile启动
#启动HDFS
start-dfs.sh
#启动集群
start-cluster.sh
#启动历史服务器
historyserver.sh start假如 historyserver 无法启动,也就没有办法访问 8082 服务,原因大概是你没有上传 关于 hadoop 的 jar 包到 lib 下:
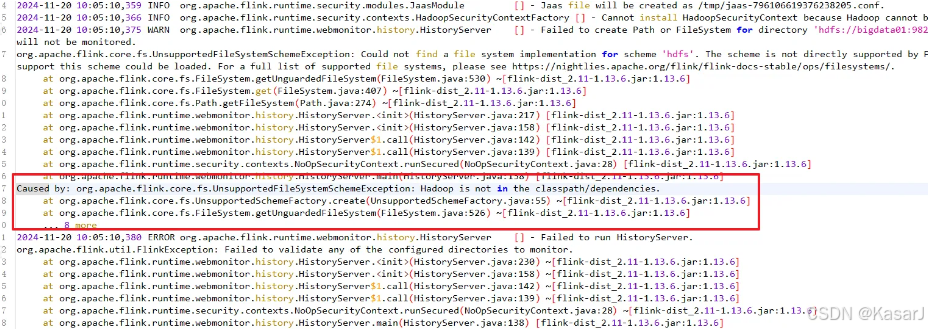
将刚才的jar包拉进flink中
就可使用ui
http://bigdata01:8081 -- Flink集群管理界面 当前有效,重启后里面跑的内容就消失了
能够访问8081是因为你的集群启动着呢
http://bigdata01:8082 -- Flink历史服务器管理界面,及时服务重启,运行过的服务都还在
能够访问8082是因为你的历史服务启动着