随着互联网的迅猛发展,网络早已融进人们日常生活的方方面面,我们的个人隐私在互联网时代几乎已经不是秘密。在数据时代,如何保护自己的隐私呢?差分隐私又是什么?小编用一篇文章带领大家了解什么是差分隐私,背后技术原理以及如何在MindSpore中实现差分隐私。
如果大家看不懂也没关系,本周末晚八点(2020.6.7 20:00),MindSpore抖音直播间(抖音号:MindSpore梯度森林会)将会为大家详细讲解!
差分隐私的背景
20 世纪90 年代,美国马萨诸塞州发生了著名的隐私泄露事件。该州集团保险委员会(GIC)发布了“经过匿名化处理的”医疗数据,用于公共医学研究。在数据发布之前,为了防止隐私泄露问题,特地删除了数据中所有的个人敏感信息,例如身份证号、姓名、住址。然而在1997 年,卡内基梅隆大学的博士Latanya Sweeney将匿名化的GIC数据库(包含了每位患者生日、性别、邮编)与选民登记记录相连后,成功破解了这份匿名数据,并找到了当时的马萨诸塞州州长William Weld的医疗记录。
30年后,在2018年又发生了多起隐私数据泄露事件。Facebook用户隐私数据泄露被罚款16亿美元,圆通10亿快递信息泄露,万豪酒店5亿用户开房信息泄露,华住酒店5亿条用户数据疑似泄露,国泰航空940万乘客数据等等,隐私泄露问题层出不穷,隐私保护当是重中之重。
隐私保护的目的
我们希望,数据使用隐私保护技术后,可以安全发布,攻击者难以去匿名化,同时又最大限度的保留原始数据的整体信息,保持其研究价值。当前的研究热点主要在两个方面:
-
隐私保护技术能提供何种强度的保护,能够抵御何种强度的攻击;
-
如何在保护隐私的同时,最大限度地保留原数据中的有用信息。
差分隐私的基本概念
差分隐私是Dwork在2006年针对统计数据库的隐私泄露问题提出的一种新的隐私定义,目的是使得数据库查询结果对于数据集中单个记录的变化不敏感。简单来说,就是单个记录在或者不在数据集中,对于查询结果的影响微乎其微。那么攻击者就无法通过加入或减少一个记录,观察查询结果的变化来推测个体的具体信息。
举个例子,当不使用差分隐私技术时,我们查询A医院数据库,查询今日就诊的100个病人患病情况,返回10人患肺癌,同时查询99个病人患病情况,返回9个人患肺癌,那就可以推测剩下1个人张三患有肺癌,这个就暴露了张三的个人隐私了。使用差分隐私技术后,查询A医院的数据库,查询今日就诊的100个病人患病情况,返回肺癌得病率9.80%,查询今日就诊的99个病人患病情况,返回肺癌得病率9.81%,因此无法推测剩下1个人张三是否患有肺癌。
在机器学习中,机器学习算法一般是用大量数据并更新模型参数,学习数据特征。理想情况下,这些算法学习到一些泛化性较好的模型。然而,机器学习算法并不会区分通用特征还是个体特征。当我们用机器学习来完成某个重要的任务,例如肺癌诊断,发布的机器学习模型可能在无意中透露训练集中的个体特征,恶意攻击者可能从发布的模型获得关于张三的隐私信息,因此使用差分隐私技术来防止机器学习模型泄露个人隐私数据是十分必要的。
差分隐私的定义

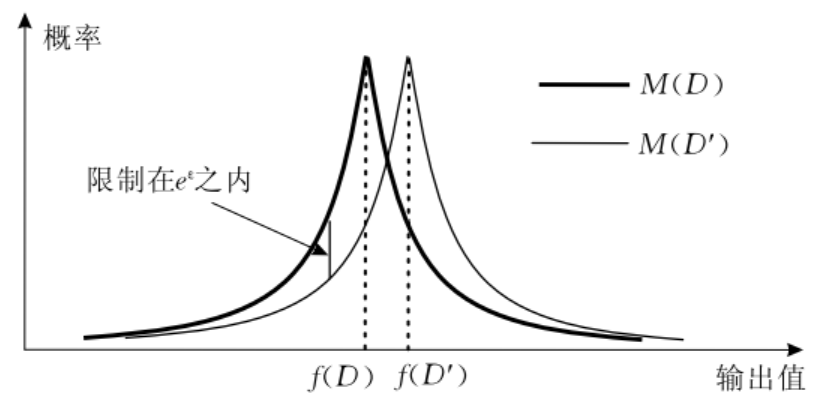
图1 随机算法在邻近数据集上的概率
差分隐私有两个重要的优点:
-
差分隐私假设攻击者能够获得除目标记录以外的所有其他记录信息,这些信息的总和可以理解为攻击者能够掌握的最大背景知识,在这个强大的假设下,差分隐私保护无需考虑攻击者所拥有的任何可能的背景知识。
-
差分隐私建立在严格的数学定义上,提供了可量化评估的方法。因此差分隐私保护技术是一种公认的较为严格和健壮的隐私保护机制。
如何实现差分隐私
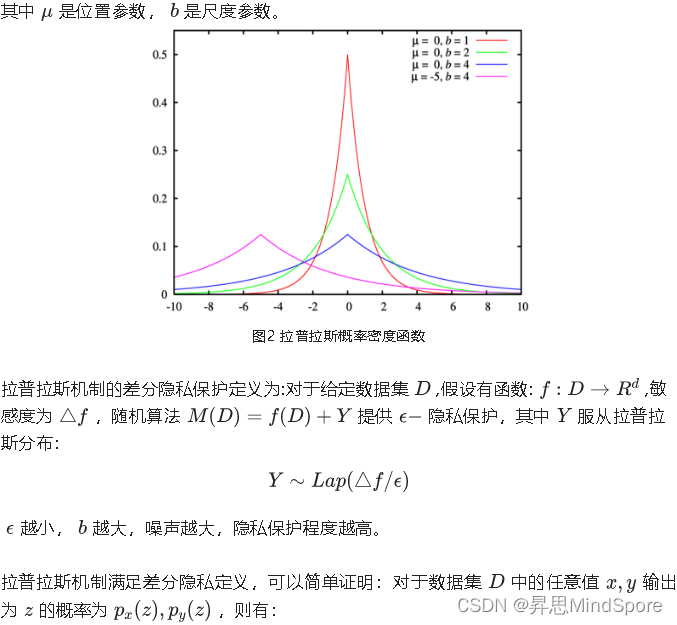
差分隐私如此优秀,那具体怎么实现呢?一个很自然而然的想法是“加噪声”。差分隐私可以通过加适量的干扰噪声来实现,目前常用的添加噪音的机制有拉普拉斯机制和指数机制。其中拉普拉斯机制用于保护数值型的结果,指数机制用于保护离散型的结果。
那什么叫适量的噪声,多少才是合适的,如何衡量呢?加入噪声的量和数据集是有关系的,年龄数据集的数据间差异就没有工资数据集的数据差异大,要添加的噪声的量就不一致。敏感度是决定该加多少噪声的重要因素。
敏感度
敏感度指数据集中删除任意一条记录对查询结果产生的最大影响。在差分隐私中有两种敏感度,全局敏感度和局部敏感度。


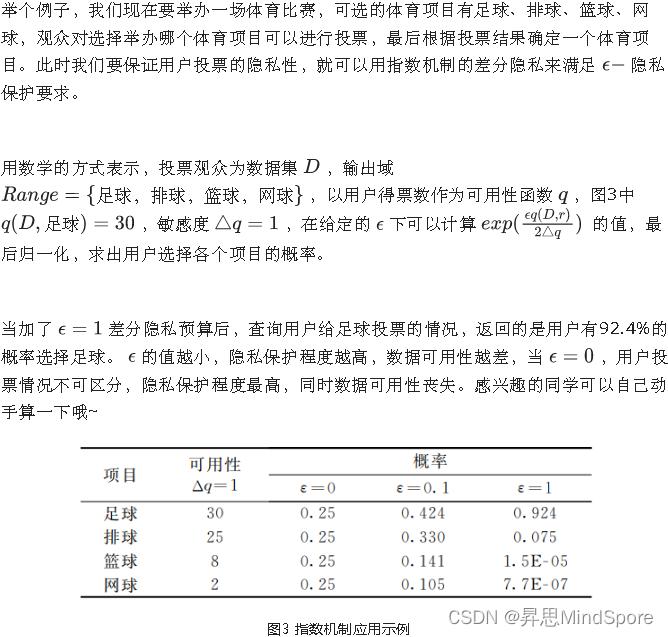

差分隐私的应用
看了以上的数学推到是不是头昏眼花了呢,其实简单来说,差分隐私的本质是"加噪",任何需要隐私保护的算法都可以使用差分隐私,由于差分隐私的串并联原理,只要算法中的每一个步骤都满足差分隐私要求,那么这个算法的最终结果将满足差分隐私特性。因此,差分隐私可以在算法流程中的任意步骤。
其实差分隐私在1977年就提出了,但是真正让它声名大噪的是2016年苹果软件工程副总裁克雷格•费德里希(Craig Federighi)在WWDC大会上宣布苹果使用本地化差分隐私技术来保护IOS、MAC用户隐私。在多个场景中成功部署差分隐私,在保护用户隐私的同时,提升用户体验。
例如,使用差分隐私技术收集用户统计用户在不同语言环境中的表情符号使用情况,改进QuickType对表情符号的预测能力。根据用户键盘输入学习新单词、外来词,更新设备内字典改善用户键盘输入体验。又例如,根据使用差分隐私技术收集用户在Safari应用使用中高频的高内存占用型、高耗能型域名,在IOS和macOS High Sieera系统里在这些网站加载时提供更多资源,以提升用户浏览体验。另外,谷歌也利用本地化差分隐私保护技术从Chrome浏览器每天采集超过1400万用户行为统计数据。
除了工业界的工程应用,差分隐私的学术研究更为广泛。目前推荐系统、社交网络分析、知识迁移、联邦学习等场景下都有差分隐私的踪迹。
MindSpore中的差分隐私实现
在MindArmour的差分隐私模块Differential-Privacy中,实现了差分隐私优化器。目前支持基于高斯机制的差分隐私SGD、Momentum优化器,同时还提供RDP(R'enyi Differential Privacy)用于监测差分隐私预算。
这里以LeNet模型为例,说明如何在MindSpore上使用差分隐私优化器训练神经网络模型。
本例面向CPU、GPU、Ascend 910 AI处理器你可以在这里下载完整的样例代码<https://gitee.com/mindspore/mindarmour/blob/master/example/mnist_demo/lenet5_dp_model_train.py
导入需要的库文件
下列是我们需要的公共模块及MindSpore的模块。
import os
import argparse
import mindspore.nn as nn
from mindspore import context
from mindspore.train.callback import ModelCheckpoint
from mindspore.train.callback import CheckpointConfig
from mindspore.train.callback import LossMonitor
from mindspore.nn.metrics import Accuracy
from mindspore.train.serialization import load_checkpoint, load_param_into_net
import mindspore.dataset as ds
import mindspore.dataset.transforms.vision.c_transforms as CV
import mindspore.dataset.transforms.c_transforms as C
from mindspore.dataset.transforms.vision import Inter
import mindspore.common.dtype as mstype
from mindarmour.diff_privacy import DPModel
from mindarmour.diff_privacy import DPOptimizerClassFactory
from mindarmour.diff_privacy import PrivacyMonitorFactory
from mindarmour.utils.logger import LogUtil
from lenet5_net import LeNet5
from lenet5_config import mnist_cfg as cfg配置环境信息
1.使用parser模块,传入运行必要的信息,如运行环境设置、数据集存放路径等,这样的好处是,对于经常变化的配置,可以在运行代码时输入,使用更加灵活。
parser = argparse.ArgumentParser(description='MindSpore MNIST Example')
parser.add_argument('--device_target', type=str, default="Ascend", choices=['Ascend', 'GPU', 'CPU'],
help='device where the code will be implemented (default: Ascend)')
parser.add_argument('--data_path', type=str, default="./MNIST_unzip",
help='path where the dataset is saved')
parser.add_argument('--dataset_sink_mode', type=bool, default=False, help='dataset_sink_mode is False or True')
parser.add_argument('--micro_batches', type=float, default=None,
help='optional, if use differential privacy, need to set micro_batches')
parser.add_argument('--l2_norm_bound', type=float, default=1,
help='optional, if use differential privacy, need to set l2_norm_bound')
parser.add_argument('--initial_noise_multiplier', type=float, default=0.001,
help='optional, if use differential privacy, need to set initial_noise_multiplier')
args = parser.parse_args()2.配置必要的信息,包括环境信息、执行的模式、后端信息及硬件信息。
context.set_context(mode=context.PYNATIVE_MODE,device_target=args.device_target, enable_mem_reuse=False)预处理数据集
加载数据集并处理成MindSpore数据格式。
def generate_mnist_dataset(data_path, batch_size=32, repeat_size=1,num_parallel_workers=1, sparse=True):
"""
create dataset for training or testing
"""
# define dataset
ds1 = ds.MnistDataset(data_path)
# define operation parameters
resize_height, resize_width = 32, 32
rescale = 1.0 / 255.0
shift = 0.0
# define map operations
resize_op = CV.Resize((resize_height, resize_width),
interpolation=Inter.LINEAR)
rescale_op = CV.Rescale(rescale, shift)
hwc2chw_op = CV.HWC2CHW()
type_cast_op = C.TypeCast(mstype.int32)
# apply map operations on images
if not sparse:
one_hot_enco = C.OneHot(10)
ds1 = ds1.map(input_columns="label", operations=one_hot_enco,
num_parallel_workers=num_parallel_workers)
type_cast_op = C.TypeCast(mstype.float32)
ds1 = ds1.map(input_columns="label", operations=type_cast_op,
num_parallel_workers=num_parallel_workers)
ds1 = ds1.map(input_columns="image", operations=resize_op,
num_parallel_workers=num_parallel_workers)
ds1 = ds1.map(input_columns="image", operations=rescale_op,
num_parallel_workers=num_parallel_workers)
ds1 = ds1.map(input_columns="image", operations=hwc2chw_op,
num_parallel_workers=num_parallel_workers)
# apply DatasetOps
buffer_size = 10000
ds1 = ds1.shuffle(buffer_size=buffer_size)
ds1 = ds1.batch(batch_size, drop_remainder=True)
ds1 = ds1.repeat(repeat_size)
return ds1建立模型
这里以LeNet模型为例,你也可以根据需求建立训练自己的模型。
from mindspore import nn
from mindspore.common.initializer import TruncatedNormal
def conv(in_channels, out_channels, kernel_size, stride=1, padding=0):
weight = weight_variable()
return nn.Conv2d(in_channels, out_channels,
kernel_size=kernel_size, stride=stride, padding=padding,
weight_init=weight, has_bias=False, pad_mode="valid")
def fc_with_initialize(input_channels, out_channels):
weight = weight_variable()
bias = weight_variable()
return nn.Dense(input_channels, out_channels, weight, bias)
def weight_variable():
return TruncatedNormal(0.02)
class LeNet5(nn.Cell):
"""
Lenet network
"""
def __init__(self):
super(LeNet5, self).__init__()
self.conv1 = conv(1, 6, 5)
self.conv2 = conv(6, 16, 5)
self.fc1 = fc_with_initialize(16*5*5, 120)
self.fc2 = fc_with_initialize(120, 84)
self.fc3 = fc_with_initialize(84, 10)
self.relu = nn.ReLU()
self.max_pool2d = nn.MaxPool2d(kernel_size=2, stride=2)
self.flatten = nn.Flatten()
def construct(self, x):
x = self.conv1(x)
x = self.relu(x)
x = self.max_pool2d(x)
x = self.conv2(x)
x = self.relu(x)
x = self.max_pool2d(x)
x = self.flatten(x)
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
x = self.relu(x)
x = self.fc3(x)
return x加载LeNet网络,定义损失函数、配置checkpoint、用上述定义的数据加载函数generate_mnist_dataset载入数据。
network = LeNet5()
net_loss = nn.SoftmaxCrossEntropyWithLogits(is_grad=False, sparse=True, reduction="mean")
config_ck = CheckpointConfig(save_checkpoint_steps=cfg.save_checkpoint_steps,
keep_checkpoint_max=cfg.keep_checkpoint_max)
ckpoint_cb = ModelCheckpoint(prefix="checkpoint_lenet",
directory='./trained_ckpt_file/',
config=config_ck)
ds_train = generate_mnist_dataset(os.path.join(args.data_path, "train"),
cfg.batch_size,
cfg.epoch_size)引入差分隐私
1.配置差分隐私优化器的参数。
-
设置数据集batch size。
-
实例化差分隐私工厂类。
-
设置差分隐私的噪声机制,目前支持固定标准差的高斯噪声机制:Gaussian和自适应调整标准差的自适应高斯噪声机制:AdaGaussian。
-
设置优化器类型,目前支持SGD和Momentum。
-
设置差分隐私预算监测器RDP,用于观测每个step中的差分隐私预算 的变化。
gaussian_mech = DPOptimizerClassFactory(args.micro_batches)
gaussian_mech.set_mechanisms('Gaussian',
norm_bound=args.l2_norm_bound,
initial_noise_multiplier=args.initial_noise_multiplier)
net_opt = gaussian_mech.create('Momentum')(params=network.trainable_params(),
learning_rate=cfg.lr,
momentum=cfg.momentum)
rdp_monitor = PrivacyMonitorFactory.create('rdp',
num_samples=60000,
batch_size=16,
initial_noise_multiplier=5,
target_delta=0.5,
per_print_times=10)2.将LeNet模型包装成差分隐私模型,只需要将网络传入DPModel即可。
model = DPModel(micro_batches=args.micro_batches,
norm_clip=args.l2_norm_bound,
dp_mech=gaussian_mech.mech,
network=network,
loss_fn=net_loss,
optimizer=net_opt,
metrics={"Accuracy": Accuracy()})3.模型训练与测试。
LOGGER.info(TAG, "============== Starting Training ==============")
model.train(cfg['epoch_size'], ds_train, callbacks=[ckpoint_cb, LossMonitor(), rdp_monitor],
dataset_sink_mode=args.dataset_sink_mode)
LOGGER.info(TAG, "============== Starting Testing ==============")
ckpt_file_name = 'trained_ckpt_file/checkpoint_lenet-10_1875.ckpt'
param_dict = load_checkpoint(ckpt_file_name)
load_param_into_net(network, param_dict)
ds_eval = generate_mnist_dataset(os.path.join(args.data_path, 'test'), batch_size=cfg.batch_size)
acc = model.eval(ds_eval, dataset_sink_mode=False)
LOGGER.info(TAG, "============== Accuracy: %s ==============", acc)4.结果展示
不加差分隐私的Lenet模型精度稳定在99%,加了自适应差分隐私AdaDP的Lenet模型收敛,精度稳定在96%,加了非自适应差分隐私DP的LeNet模型收敛,精度稳定在94%左右。

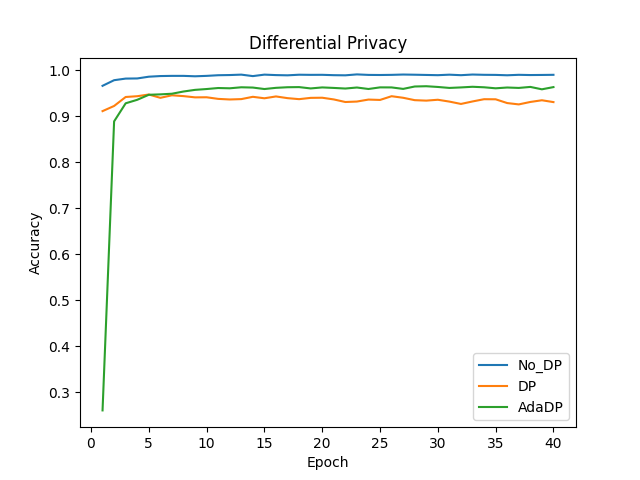
图4 训练结果对比展示