测试数据
用户ID,物品ID,评分
1,101,5.0
1,102,3.0
1,103,2.5
2,101,2.0
2,102,2.5
2,103,5.0
2,104,2.0
3,101,2.5
3,104,4.0
3,105,4.5
3,107,5.0
4,101,5.0
4,103,3.0
4,104,4.5
4,106,4.0
5,101,4.0
5,102,3.0
5,103,2.0
5,104,4.0
5,105,3.5
5,106,4.0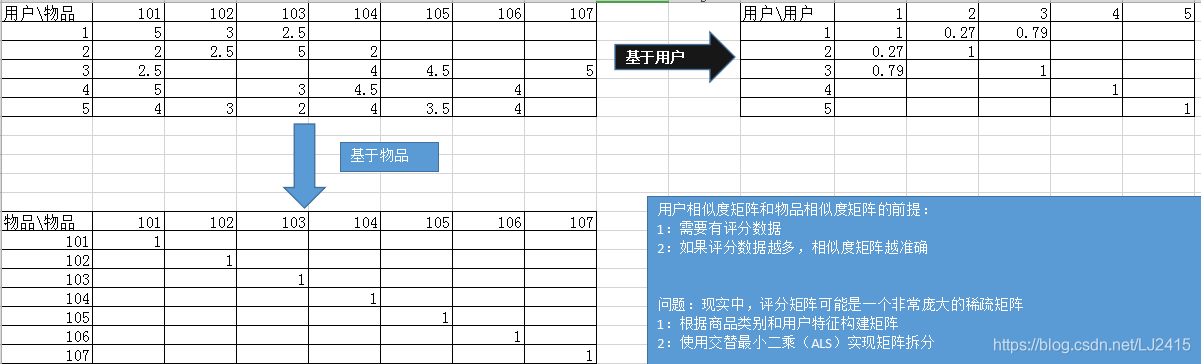
(余弦相似度)基于用户id的智能推荐算法
package ml
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.mllib.linalg.distributed.{CoordinateMatrix, MatrixEntry, RowMatrix}
import org.apache.spark.rdd.RDD
/**
* 基于用户的协调过滤
*/
object UserBasedCF {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName(this.getClass.getSimpleName).setMaster("local[*]")
//创建一个sparkContext
val sc = new SparkContext(conf)
//读取数据
val data: RDD[String] = sc.textFile(args(0))
//使用模式匹配,返回矩阵基础数据
/**
* 这里的每一项都是(i:Long , j:Long , value:double)标示行列值得元组
* 其中i标示坐标,j标示列坐标,value是值
*/
val parseData: RDD[MatrixEntry] = data.map(_.split(",")
match {
case Array(user, item, rate) => MatrixEntry(user.toLong, item.toLong, rate.toDouble)
})
//构造评分矩阵
val ratings: CoordinateMatrix = new CoordinateMatrix(parseData)
val entries: Array[MatrixEntry] = ratings.entries.collect()
entries.foreach(println(_))
println("-------------------------------------------------------")
//得到某个用户对所有物品的评分,以用户1为例
val ratingsOfUser1 = ratings.entries.filter(_.i == 1).map(x=>(x.j,x.value)).sortBy(_._1).collect()
println("用户1对所有物品的评分")
for (s <- ratingsOfUser1) println(s)
/**
* (101,5.0)
* (102,3.0)
* (103,2.5)
*/
println("-------------------------------------------------------")
/**
* 输出, 用户与用户的相似度矩阵
* 因为协同过滤需要基于列,所有需要对数据进行转置
* 坐标矩阵可以通过transpose()方法对矩阵进行转置操作
*/
val matrix: RowMatrix = ratings.transpose().toRowMatrix()
//进行计算,得到用户的相似度矩阵
val similarties = matrix.columnSimilarities()
println("输出用户相似度矩阵:")
similarties.entries.collect().map(x=>{
println(s"${x.i} -> ${x.j} ----------->${x.value}")
})
/**
* 1 -> 4 ----------->0.6111914276294735
* 2 -> 3 ----------->0.25256410947267416
* 1 -> 2 ----------->0.754776694478251
* 4 -> 5 ----------->0.8364197355878605
* 3 -> 5 ----------->0.5937461121628563
* 2 -> 4 ----------->0.647494259163196
* 2 -> 5 ----------->0.6247714305641069
* 1 -> 5 ----------->0.6261698609836083
* 3 -> 4 ----------->0.4429194874175847
* 1 -> 3 ----------->0.23981435961206427
*/
println("-------------------------------------------------------")
/**
* 得到用户1相对于其他用户的相似度
*/
val similartiesOfUser1 = similarties.entries.filter(_.i == 1).sortBy(_.value,false).collect()
println("用户1相对于其他用户的相似度")
for (s <- similartiesOfUser1) println(s)
/**
* MatrixEntry(1,2,0.754776694478251)
* MatrixEntry(1,5,0.6261698609836083)
* MatrixEntry(1,4,0.6111914276294735)
* MatrixEntry(1,3,0.23981435961206427)
*/
sc.stop()
}
}
(余弦相似度)基于物品的推荐推荐算法:
package ml
import org.apache.spark.mllib.linalg
import org.apache.spark.mllib.linalg.SparseVector
import org.apache.spark.mllib.linalg.distributed.{CoordinateMatrix, IndexedRow, MatrixEntry, RowMatrix}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* 建立物品的相似度,来进行推荐
*/
object ItemBasedCF {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName(this.getClass.getSimpleName).setMaster("local[*]")
//创建一个sparkContext
val sc = new SparkContext(conf)
//读取数据
val data: RDD[String] = sc.textFile(args(0))
//使用模式匹配,返回矩阵基础数据
/**
* 这里的每一项都是(i:Long , j:Long , value:double)标示行列值得元组
* 其中i标示坐标,j标示列坐标,value是值
*/
val parseData: RDD[MatrixEntry] = data.map(_.split(",")
match {
case Array(user, item, rate) => MatrixEntry(user.toLong, item.toLong, rate.toDouble)
})
//构造评分矩阵
val ratings: CoordinateMatrix = new CoordinateMatrix(parseData)
//
val matrix: RowMatrix = ratings.toRowMatrix()
/**
* 需求,为某一个用户推荐商品,基本的逻辑是:首先得到某个用户评价或者(买过的)商品,
* 然后计算其他商品与该商品的相识度,并且排序,从高到低,把不在用户评价或者购买的
* 商品里的其他商品推荐给用户
* 例如:为用户3推荐商品
* 第一步:得到用户3评价过(买过)的商品,take(5)表示取出所有的5个用户.
* 2 :表示第三个用户,下标从0开始,
* 解释:SparseVector表示稀疏矩阵
*/
val vector: linalg.Vector = matrix.rows.take(5)(3)
/**表示take()(?) [物品][评分] 用户id
* 0 //[101,103,104,106],[5.0,3.0,4.5,4.0] -->4
* 1 //[101,102,103,104],[2.0,2.5,5.0,2.0] -->2
* 2 //[101,102,103],[5.0,3.0,2.5] -->1
* 3 //[101,104,105,107],[2.5,4.0,4.5,5.0] --> 3
* 4 //[101,102,103,104,105,106],[4.0,3.0,2.0,4.0,3.5,4.0]--> 5
*/
val prefs: SparseVector = vector.asInstanceOf[SparseVector]
println(vector)
//等待用户3评价或者买过的商品ID
val indices: Array[Int] = prefs.indices
println(indices.toBuffer)//ArrayBuffer(101, 104, 105, 107)
//得到用户3评价或者买过的商品id和评分
val tuples = (indices zip prefs.values)//拉链操作
for (s <- tuples) println(s)
println("*************************************************")
//计算物品之间的相似度
val similarities = matrix.columnSimilarities()
val indexeds: RDD[(Int, linalg.Vector)] = similarities.toIndexedRowMatrix().rows.map{
case IndexedRow(index,vector) => (index.toInt,vector)
}
println(indexeds.collect().toBuffer)
/**计算物品之间的相识度结果
* (101,[102,103,104,105,106,107],[0.7441734693215796,0.7833120998030602,0.8016376680394155,0.5072239805613437,0.7287986971610244,0.28629916715693415])),
*
* (102,[103,104,105,106],[0.7937081485534128,0.4602902615272406,0.37401734853129354,0.4307748951706429])),
*
* (103,[104,105,106],[0.6313826635223763,0.18458640943124396,0.5314940034527338]))
*
* (104,[105,106,107],[0.7484228431419984,0.8013876853447537,0.5333333333333333])),
*
* (105,[106,107],[0.4341215710622296,0.7893522173763263])),
*/
//得到其他用户购买的商品和用户id =3 购买的商品的相似度
val tupleRDD: RDD[(Int, Double)] = sc.parallelize(tuples)
// println(tupleRDD.collect().toList.toBuffer)
//ArrayBuffer((101,2.5), (104,4.0), (105,4.5), (107,5.0))
val value: RDD[(Int, Double)] = tupleRDD.join(indexeds).flatMap {
case (i, (p, vector: SparseVector)) => (vector.indices zip vector.values)
}
//3 ----[101,104,105,107],[2.5,4.0,4.5,5.0]
println(value.collect().toList.toBuffer)
/**用户3购买过的商品
* (105,0.7484228431419984),
* (106,0.8013876853447537),
* (107,0.5333333333333333)
*
* (102,0.7441734693215796),
* (103,0.7833120998030602),
* (104,0.8016376680394155),
* (105,0.5072239805613437),
* (106,0.7287986971610244),
* (107,0.28629916715693415)
*
* (106,0.4341215710622296),
* (107,0.7893522173763263)
*/
//其他用户购买过,但是不在用户id3购买的商品列表中的商品和评分
val ij: RDD[(Int, Double)] = value.filter{
case (item,pref) => (!indices.contains(item))
}
println(ij.collect().toList.toBuffer)
// ArrayBuffer((106,0.8013876853447537), (102,0.7441734693215796), (103,0.7833120998030602), (106,0.7287986971610244), (106,0.4341215710622296))
//将这些商品的评分进行求和,并降序排序
val ijTopN: RDD[(Int, Double)] = ij.reduceByKey(_+_).sortBy(_._2,false)
println("推荐的结果是: ")
println(ijTopN.collect().toBuffer)
//ArrayBuffer((106,1.9643079535680077), (103,0.7833120998030602), (102,0.7441734693215796))
sc.stop()
}
}