AIGC实战——世界模型(World Model)
0. 前言
世界模型 (World Model) 展示了如何通过在生成的想象环境中进行实验来训练模型(而不是在真实环境中进行训练),从而学习如何执行特定任务。世界模型很好的说明了如何将生成模型与其他机器学习技术(如强化学习)相结合使用解决实际问题。
该架构的关键组成部分是生成模型,它可以根据当前状态和动作构建下一个可能状态的概率分布。该模型通过随机运动建立对基本物理环境的了解之后,该模型能够完全依靠自身对环境的内部表示来自我训练一个新任务。在本章中,我们将详细介绍世界模型,了解智能体如何学习尽可能快地驾驶汽车在虚拟赛道上行驶。
1. 强化学习
强化学习 (Reinforcement Learning, RL) 是机器学习的一个领域,旨在训练一个智能体在给定环境中以达到特定目标,以取得最大化的预期利益。
判别模型和生成模型都旨在通过观测数据集来最小化损失函数,而强化学习旨在最大化智能体在给定环境中的长期奖励。通常,我们将强化学习视为机器学习的三个主要分支之一,另外两个是监督学习(使用标记数据进行预测)和无监督学习(从无标签数据中学习结构)。
接下来,我们首先介绍与强化学习相关的一些关键概念:
- 环境 (
Environment):智能体在其中运行的世界。它定义了一组规则,这些规则决定了在给定智能体当前动作和当前游戏状态的情况下,游戏状态的更新过程和奖励分配。例如,如果我们训练强化学习算法下国际象棋,那么构成环境的规则将控制某个动作如何影响下个游戏状态,并确定如何评估一个给定位置是否会被将军,并在获胜之后奖励获胜玩家1分 - 智能体 (
Agent):在环境中执行动作的实体 - 状态 (
State):表示智能体可能遇到的特定情况的数据。例如,特定的棋盘配置,以及附带的游戏信息 - 动作 (
Action):智能体可以采取的可行行动 - 奖励 (
Reward):在采取动作后由环境返回给智能体的值。智能体的目标是最大化长期的奖励总和。例如,在一局国际象棋中,将死对方王的动作的奖励1分,而其他所有动作都没有奖励,而有些游戏会在整个游戏过程中不断获得奖励 - 回合 (
Episode):智能体在环境中的一轮运行过程 - 时间步 (
Timestep):对于离散事件环境,所有状态、动作和奖励都带有下标,用以表示它们在时间步 t t t 上的值
这些概念之间的关系如下图所示。
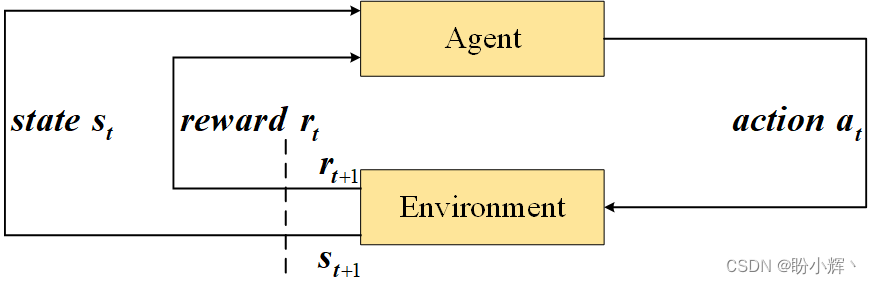
环境首先通过当前游戏状态
s
0
s_0
s0 进行初始化。在时间步
t
t
t,智能体接收当前游戏状态
s
t
s_t
st,并根据此状态决定下一个最佳动作
a
t
a_t
at,并执行该动作。根据这个动作,环境计算下一个状态
s
t
+
1
s_{t+1}
st+1 和奖励
r
t
+
1
r_{t+1}
rt+1,并将它们传递回给智能体,以开始下一个循环。循环会一直到满足回合的结束条件(例如,经过给定的时间步或智能体胜利/失败)为止。
在给定环境中,为了设计一个智能体以最大化奖励总和,我们可以构建一个包含一组规则的智能体,用于应对任何给定的游戏状态。然而,随着环境变得更加复杂,这种方法很快就会失效,而且由于规则是硬编码的,因此无法构建具有超越人类的智能体。而强化学习的过程则是创建一个智能体,该智能体能够通过在复杂的环境中重复游戏来自行学习最佳策赂。
2. OpenAI Gym
接下来,我们首先介绍 OpenAI Gym,其包含 CarRacing 环境,我们将使用此环境模拟一辆绕赛道行驶的赛车。
2.1 CarRacing 环境
CarRacing 是通过 Gymnasium 库提供的一个环境。Gymnasium 是一个用于开发强化学习算法的 Python 库,包含了多个经典的强化学习环境,如 CartPole 、Pong 以及 Atari 游戏等。
2.2 GYMNASIUM
Gymnasium 是 OpenAI Gym 库的一个分支,自 2021 年起,Gym 的进一步开发已转移到 Gymnasium。
所有环境都提供了 step 方法,通过该方法可以提交一个给定的动作;环境将返回下一个状态和奖励,通过该方法能够应用智能体选定的动作,并返回下一个状态和奖励,可以反复使用智能体选择的动作调用 step 方法,在环境中完成一个回合;reset 方法用于将环境恢复到初始状态;render 方法可以渲染环境,用于调试并改进模型。
在 CarRacing 环境中,状态、动作、奖励和回合的定义如下:
- 状态:尺寸为
64 × 64的RGB图像,描绘了赛道和汽车的俯视图 - 动作:包含
3个值,方向盘转向 (-1到1)、加速度 (0到1) 和刹车 (0到1),智能体必须在每个时间步设置这三个值 - 奖励:每个时间步都会得到一个负的惩罚值
-0.1,并且如果前进到新的赛道块,则会得到一个正的奖励值1000/N,其中N表示赛道的总块数 - 回合:当汽车行驶完整个赛道、驶出环境边界或超过
3000个时间步后,回合结束
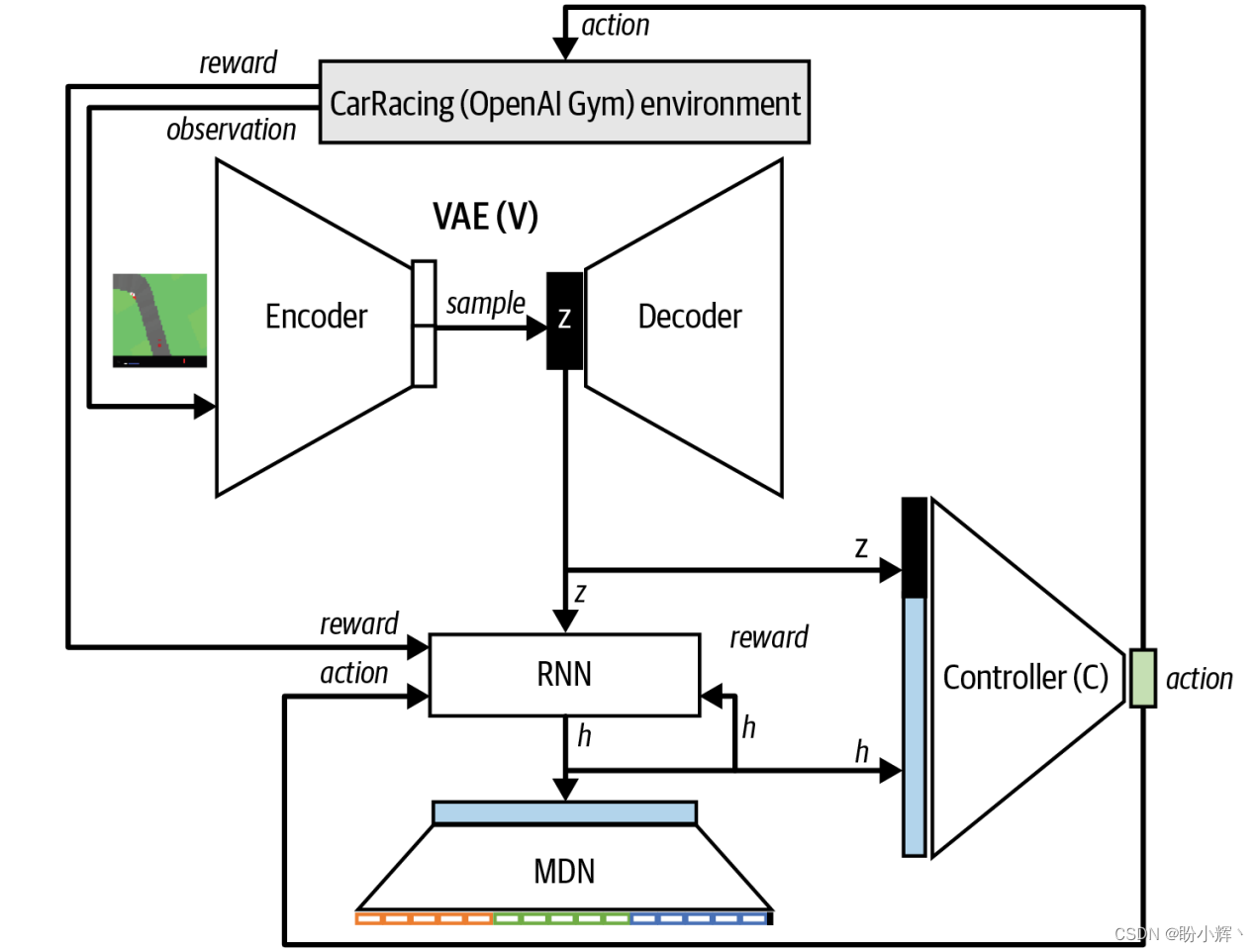
3. 世界模型架构
接下来,在详细介绍每个组件之前,我们首先对世界模型架构和训练过程进行简要介绍。模型架构由以下三个不同的部分组成,如下图所示:
V:VAE(variational autoencoder,变分自编码器)M:MDN-RNN(recurrent neural network with a mixture density network,混合全连接网络的循环神经网络)C:控制器 (controller)
3.1 VAE
在驾驶汽车时,我们并不会主动分析视野中的每个像素,而是将视觉信息压缩成少量的潜在实体,例如道路的平坦程度、即将到来的弯道以及车辆相对于道路的位置,以根据这些信息决定下一步的动作。
VAE 通过最小化重建误差和 KL 散度,可以将高维输入图像压缩成一个近似遵循标准高斯分布的潜随机变。这确保了潜空间是连续的,并且我们能够很容易从中采样生成有意义的新观测值。
在赛车示例中,VAE 将尺寸为 64 × 64 × 3 (RGB) 的输入图像压缩成一个 32 维的遵循正态分布的随机变量,该变由参数 mu 和 logvar 参数化。其中,logvar 是分布的方差的对数。我们可以从该分布中采样,生成表示当前状态的潜向量 z。然后将其传递给神经网络的下一个部分,MDN-RNN。
3.2 MDN-RNN
在驾驶时,我们并不会对每个后续观察感到意外。如果当前观察表明前方是一个左转弯,我们会将方向盘向左转,并且期望下一个观测表明车辆仍然保持在道路中间。
如果不具备这种能力,那么驾驶时汽车可能会在道路上摇摆不定,因为无法看到前进的方向是否偏离了道路中央,如果不采取措施,在下一时间步偏离会越来越严重。
在世界模型中,这种能力由 MDN-RNN 提供,MDN-RNN 网络能够根据前一个潜状态和前一个动作来预测下一个潜状态的分布。具体来说,MDN-RNN 是一个包含 256 个隐藏单元的长短期记忆 (Long Short Term Memory, LSTM) 层,后面跟着一个混合全连接网络 (Mixture Density Network, MDN) 输出层,因此它能够从几种正态分布中提取下—个隐状态。
“世界模型”也可以应用于手写生成任务,如下图所示,下一次笔尖可以落在红色区域内的任意一点。
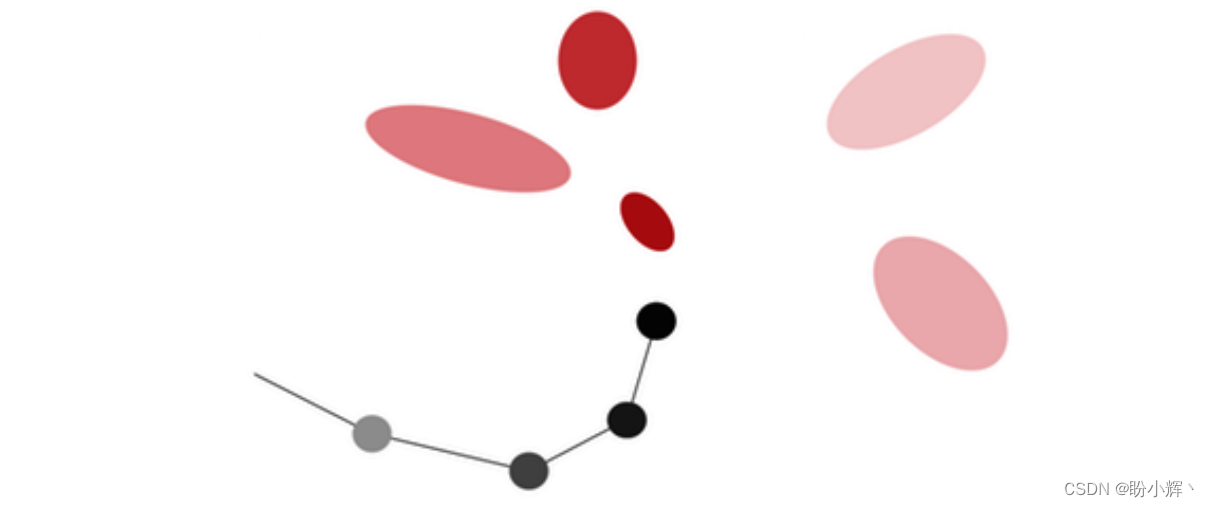
在赛车示例中,下一个观测到的隐状态中的每个元素都可以从五个正态分布中抽取。
3.3 控制器
控制器可以用于选择动作。控制器是一个全连接神经网络,输入是从 VAE 编码的分布中抽样得到的当前潜在状态 z 和全连接网络 (Recurrent Neural Network, RNN) 的隐藏状态。输出神经元对应于三个动作(转向、加速、刹车),并且经过缩放以落入适当的范围内。
控制器使用强化学习进行训练,因为没有训练数据集能告诉我们某个动作是好的还是坏的,智能体通过重复实验自己学习。
“World Models” 的关键是,它展示了如何在智能体自身的生成环境模型(而不是 OpenAI Gym 提供的环境)中进行强化学习。换句话说,这种强化学习只需依靠智能体想象的环境,而不需要真实的环境。
为了理解这三个组件的不同角色以及它们如何协同工作,我们考虑以下示例:
VAE查看最新的尺寸为64 × 64 × 3的观测图像,并预测这是一条直行道路,前方有一个很小的左转弯,汽车朝着道路的方向行驶 (z)RNN:基于该描述 (z) 和控制器在上一个时间步选择的动作,更新隐藏状态 (h),以便下一个观察预测仍然是一条笔直的道路- 控制器:基于来自
VAE的描述 (z) 和来自RNN的当前隐藏状态 (h),神经网络输出下一个动作
然后将控制器的动作传递给环境,环境返回更新后的观测图像,并不断重复此过程。
4. 世界模型训练
训练过程包括以下五个步骤:
- 收集随机
rollout数据。在这个阶段,智能体并不关心给定任务,而只是使用随机动作探索环境。使用OpenAI Gym模拟多个回合,并存储每个时间步的观察状态、动作和奖励。目的是建立一个关于环境工作方式的数据集,之后VAE可以从中学习以高效地捕捉状态为潜在向量。然后,MDN-RNN可以学习隐向量如何随时间的推移而变化 - 训练
VAE。使用随机收集的数据,在观测图像上训练VAE - 收集数据用于训练
MDN-RNN:在VAE训练完成后,我们将其用于将每个收集到的观测值编码为为mu和logvar向量,并将其与当前动作和奖励一起保存 - 训练
MDN-RNN:每批为100个回合,并加载在第3步中生成的每个时间步相应的mu、logvar、动作和奖励。然后,根据mu和logvar向量中采样一个z向量。给定当前的z向量、动作和奖励,训练MDN-RNN预测下一个z向量和奖励 - 训练控制器。利用训练好的
VAE和RNN,训练控制器,使其在给定RNN的当前z和隐藏状态h的情况下输出一个动作。控制器使用进化算法CMA-ES作为优化器。如果矩阵权重生成的动作能够提高任务的总体得分,则该算法会给予奖励,以便后代也有可能继承这种所期望的行为
接下来,我们参考 GitHub 上“世界模型”的 TensorFlow 实现,详细介绍每一步骤。
4.1 收集随机 rollout 数据
第一步是使用一个智能体采取随机动作从环境中收集 rollout 数据。我们最终希望智能体学习如何采取最佳动作,这一步用于提供智能体学习世界的运作方式以及其动作如何(起初是随机的)影响后续观测数据。
我们可以通过启动多个 Python 进程并行捕获多个回合,每个进程运行一个单独的环境实例来同时捕获多个回合。可以通过在终端上运行以下命令来收集数据:
python WorldModels/extract.py --parallel_processes --max_trials --max_frames
使用的超参数如下:
parallel_processes:要运行的并行进程数(例如,如果您的计算机具有≥8个核心,则为8)max_trials:每个进程应总共运行的回合数(例如,125,因此8个进程将创建总共1,000个回合)max_frames:每个回合的最大时间步数(例如,300)
下图显示了一个回合内第 40 至 59 帧的状态,汽车靠近一个弯道,并随机选择动作和奖励。请注意,当汽车在新的赛道块上移动时,奖励会从 -0.1 变为 3.22,否则保持不变。

4.2 训练 VAE
现在,我们根据收集的数据构建一个生成模型 VAE,VAE 的目的是使我们能够将一个 64 × 64 × 3 的图像压缩为一个遵循正态分布的随机变量 z,其分布由向量 mu 和 logvar 参数化,每个向量的长度都是 32。可以通过在终端上运行以下命令来训练 VAE:
python WorldModels/extract.py --vae_batch_size --z_size --vae_num_epoch
使用的超参数如下:
vae_batch_size:训练VAE时使用的批大小(每批的观测数,例如100)- z_size:潜向量
z的长度,也是mu和logvar变量的长度(例如32) vae_num_epoch:训练时的迭代次数(例如10)
4.2.1 VAE 结构
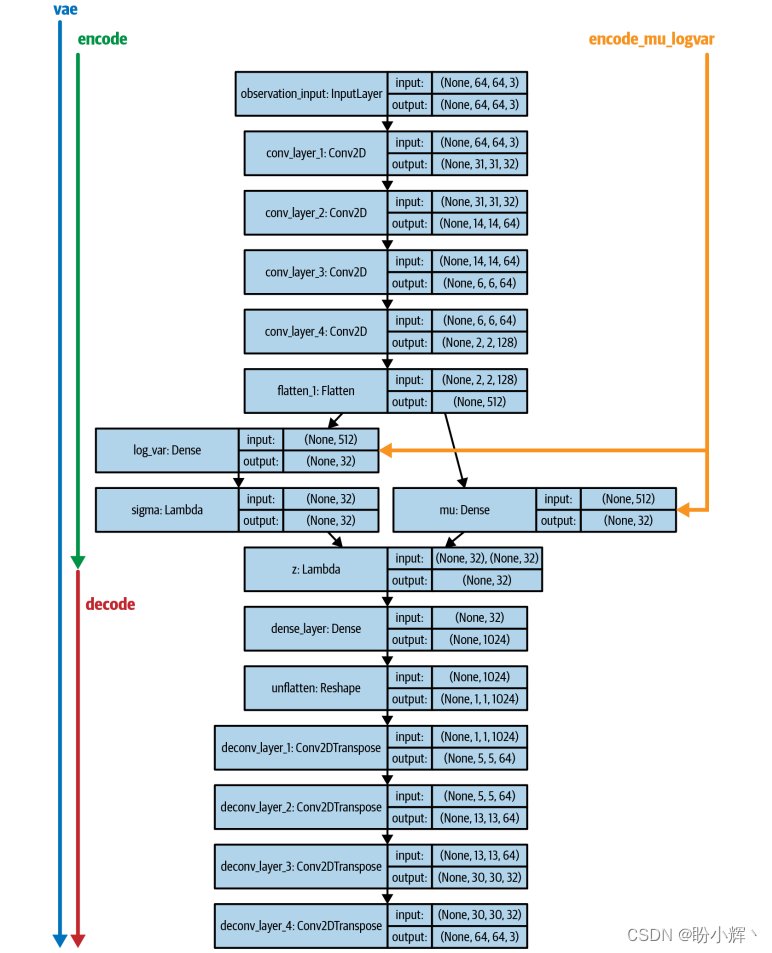
Keras 不仅允许我们定义将被端到端训练的 VAE 模型,还允许定义单独定义编码器和解码器的额外子模型。当我们想要编码特定图像或解码给定的 z 向量时,这些子模型将非常有用。我们将定义 VAE 模型和三个子模型,如下所示:
VAE:完整的、端到端VAE模型,接受尺寸为64 × 64 × 3的图像作为输入,并输出一个重建的64 × 64 × 3图像encode_mu_logvar;模型接受尺寸为64 × 64 × 3的图像作为输入,并输出对应于此输入的mu和logvar向量,将同一输入图像多次输入到该模型将产生相同的mu和logvar向量Encode:模型接受尺寸64 × 64 × 3的图像作为输入,并输出一个采样得到的z向量。将同一输入图像多次输入到该模型将每次产生不同的z向量,因为即使mu和log_var的值恒定,随机采样得到的z向量每次也会有所不同Decode:模型接受一个z向量作为输入,并返回重建的尺寸为64 ×64 × 3的图像。
模型和子模型架构如下图所示。
4.2.2 探索 VAE
接下来,我们观察 VAE 和每个子模型的输出,以了解如何使用 VAE 生成全新的赛道观测。
如果将观测图像输入 VAE,它就能够准确地重建原始图像,如下图所示,这可以直观的检查 VAE 是否正常工作。

4.2.3 编码器模型
如果将观察图像输入到 encode_mu_logvar 模型,就可以输出用于描述多元正态分布的 mu 和 logvar 向量。encoder 模型还会进一步从该分布中采样特定的z向量。编码器模型的两个输出如下图所示。
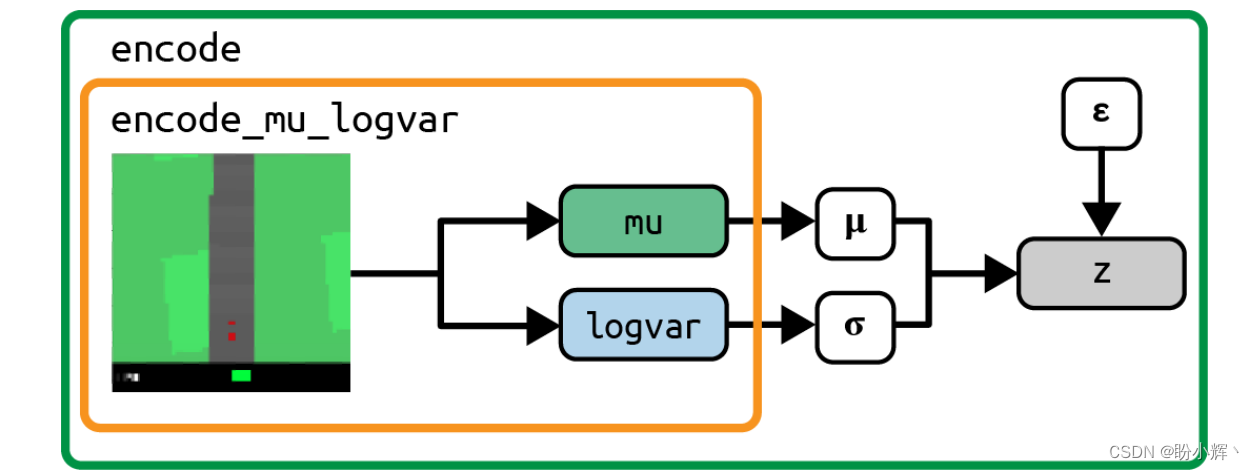
潜变量 z 是从由 mu 和 logvar 定义的高斯分布中采样得到的,方法是从标准高斯分布中采样,然后对采样向量进行缩放和平移:
eps = tf.random_normal(shape=tf.shape(mu))
sigma = tf.exp(logvar * 0.5)
z = mu + eps * sigma
4.2.4 解码器模型
解码器模型接受一个 z 向量作为输入,并重建原始图像。在下图中,我们对 z 的两个维度进行线性插值,以展示每个维度如何编码赛道的特征,例如, z[4] 控制着最靠近车辆的赛道的左/右方向,而 z[7] 控制了前方左转弯的急缓程度。
这表明 VAE 学习的潜空间是连续的,可以用来生成智能体从未观察过的全新赛道段。
4.3 收集数据用于训练 MDN-RNN
接下来,我们可以使用训练好的 VAE,为 MDN-RNN 生成训练数据。
在这一步中,我们将所有随机 rollout 数据都输入到 encode_mu_logvar 模型中,并存储与每个观测相对应的 mu 和 logvar 向量。我们将使用这些编码数据,以及已经收集到的动作、奖励用于训练 MDN-RNN,该过程如下图所示。
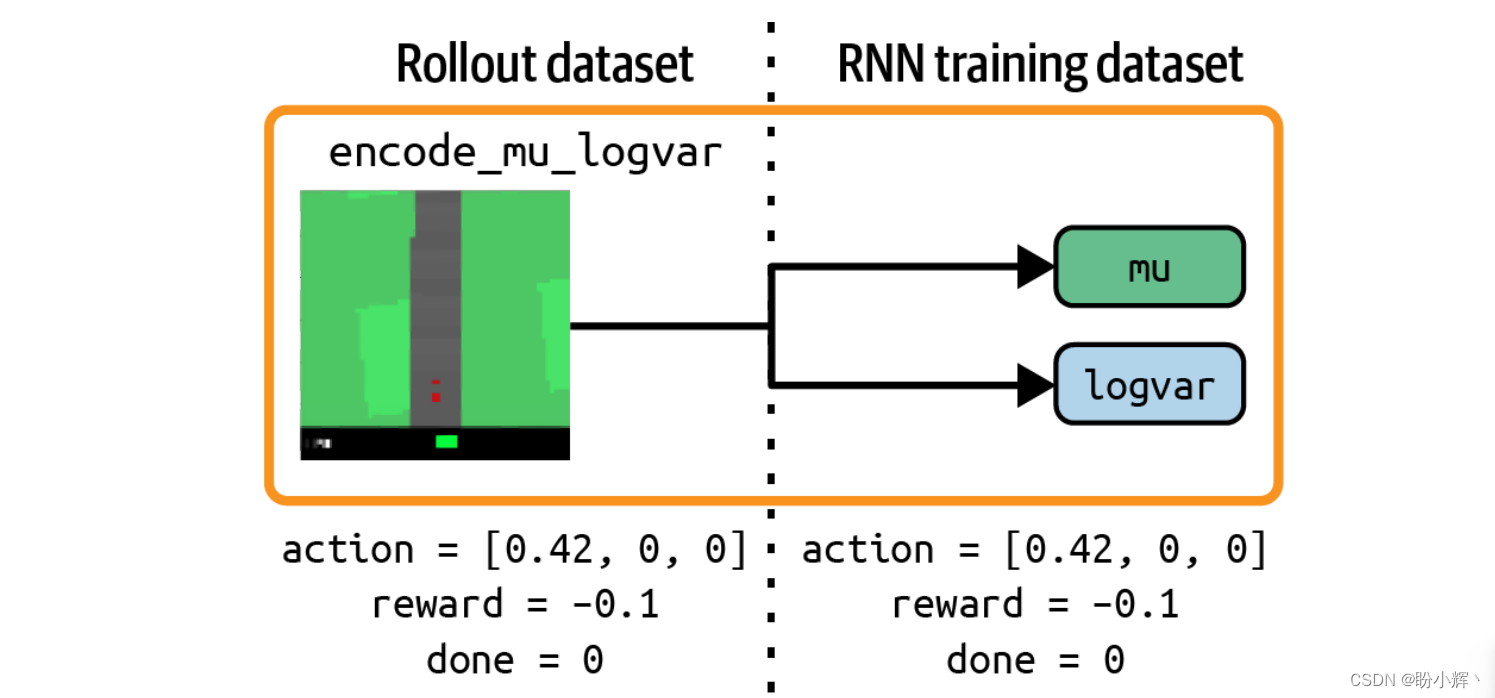
4.4 训练MDN-RNN
现在,我们可以训练 MDN-RNN 根据当前的 z 向量、当前动作和上一个奖励,预测下一个 z 向量的分布和奖励。然后,我们可以使用 RNN 内部的隐藏状态(可以看作是模型对环境动态的当前理解)作为控制器输入的一部分,以预测要采取的下一个动作。可以通过在终端上运行以下命令来训练 MDN-RNN:
python WorldModels/rnn_train.py --rnn_batch_size --rnn_num_steps
超参数如下:
rnn_batch_size:训练MDN-RNN时使用的批大小(每批数据含有多少个序列,例如100)rnn_num_steps:训练的总迭代次数(例如4000)
4.4.1 MDN-RNN 架构
MDN-RNN 架构如下图所示。
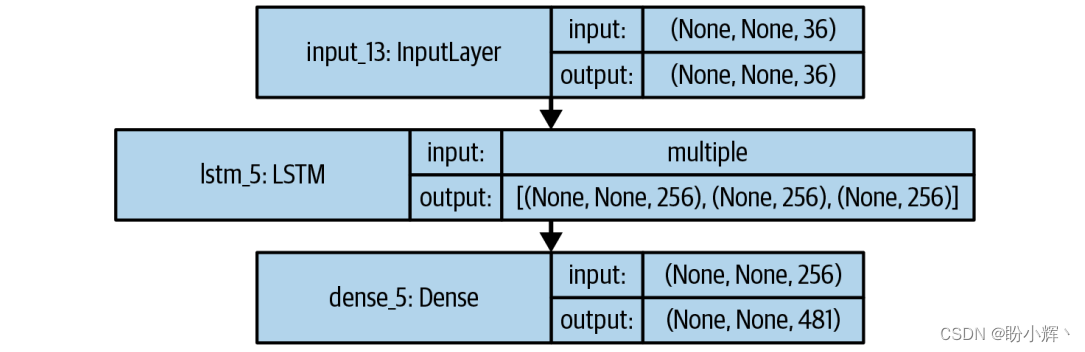
MDN-RNN 由一个 LSTM 层和一个全连接层组成。其中,LSTM 将编码的 z 向量(长度为 32),当前动作(长度为 3) 和先前的奖励(长度为 1) 连接起来,作为输入。LSTM 层的输出是一个长度为 256 的向量,每个值对应于该层中的一个 LSTM 单元。这个向量被传递给 MDN,并由该层将长度为 256 的向量转换为长度为 481 的向量。
下图解释了 MDN-RNN 输出的组成,MDN 的目的是根据以下条件进行建模:下一个 z 可以按照一定的概率从几种可能的分布中得出。在赛车游戏中,我们选择了五个正态分布。为了定义这些分布,对于 32 维的 z 中的每个维度,五个混合密度中的每一个都需要一个 mu 和一个 logvar,以及一个表示该密度被选择的概率 (logpi)。因此,共有 5×3×32 = 480 个参数,而最后一个参数用于预测奖励,更具体地说,是下一个时间步奖励的对数概率。

4.4.2 从 MDN-RNN 中采样
我们可以按照以下过程从 MDN 的输出中采样,以生成下一个时间步的 z 和奖励的预测:
- 将
481维的输出向量分割成3个变量 (logpi、mu和logvar) 和奖励值 - 取
logpi的自然指数,经过缩放后,以便将其解释为32个概率分布,这些分布对应于5个混合分布的索引 - 对于
z的每个32个维度,从由logpi创建的分布中采样(即针对z的每个维度,决定应使用5个分布中的哪一个) - 选择好分布之后,获取该分布对应的
mu和logvar的值 - 对于每个
z维度,为该维度选择的参数mu和logvar所确定的正态分布中采样一个值
MDN-RNN 的损失函数是 z 向量重构损失和奖励损失之和。其中,z 向量重构损失是 MDN-RNN 预测的分布相对于真实 z 值的负对数似然,而奖励损失是预测奖励与真实奖励之间的均方误差。
4.5 训练控制器
最后一步是使用名为协方差矩阵适应进化策略 (covariance matrix adaptation evolution strategy, CMA-ES) 的进化算法来训练控制器(即输出所选动作的网络)。通过终端运行以下命令即可开始训练控制器:
python WorldModels/train.py --controller_num_worker --controller_num_worker_trial --controller_num_episode --controller_eval_steps
超参数如下:
controller_num_worker:并行测试解的进程数controller_num_worker_trial:在每一代中,每个进程需要测试的解的数量controller_num_episode:测试每个解的回合数,用于计算平均奖励controller_eval_steps:在评估当前最佳参数集合时,两次评估之间的代数
4.5.1 控制器架构
控制器的架构是一个没有隐藏层的全连接神经网络,将输入向量直接连接到动作向量。
输入向量是当前 z 向量(长度为 32 )和 LSTM 的当前隐藏状态(长度为 256 )的连接,形成长度为 288 的向量。由于我们将每个输入单元直接连接到3个输出动作单元,所以需要调整的权重总数为 288 × 3 = 864,再加上 3 个偏置权重,总共为 867。
训练此网络并不是一个监督学习问题,我们不是在尝试预测正确的动作。因为我们并没有包含正确动作的训练集,因为对于给定环境状态来说,我们并不知道最优动作是什么,这就是强化学习问题与众不同的地方。我们需要智能体通过在环境中进行实验,并根据接收到的反馈更新其权重来发现权重的最优值。
进化策略是解决强化学习问题的一种常见选择,因为其简单、高效且可扩展。本节中,我们将使用 CMA-ES 策略。
4.5.2 CMA-ES
进化策略通常使用以下过程:
- 创建一个智能体种群,并随机初始化每个智能体要优化的参数
- 循环以下步骤:
- 在环境中评估每个智能体,返回多个回合中的平均奖励
- 用奖励最高的智能体繁殖新的智能体,创建新的种群成员
- 在新成员的参数中添加随机性
- 更新智能体种群,加人新的智能体,并移除表现不佳的智能体
这类似于自然界中动物进化的过程,因此被称为进化策略 (evolutionary strategie)。在此过程中,“繁殖”是指将现有的得分最高的智能体组合起来,使得下一代更有可能产生高质量的结果,类似于它们的父代。与其他强化学习一样,需要在贪婪地寻找局部最优解和探索参数空间中未知区域之间取得平衡。因此,重要的是向种群中添加随机性,以确保搜索领域不会过于狭窄。
CMA-ES 只是进化策略的一种。简而言之,它通过维护一个正态分布,并通过从中采样参数来生成新的智能体。在每一代中,它更新分布的均值,以最大化从上一时间步中采样到高分智能体的概率。同时,它还会根据给定的前一个平均值更新分布的协方差矩阵,以最大化采样到高分智能体的概率。可以将其视为一种自然形成的梯度下降方法,但它的优点是无需计算或估计梯度。
下图展示了在一个简单数据集上该算法的一代演化过程。在这个例子中,试图找到一个高度非线性的函数在二维空间中的最小值。图像中红色/黑色区域的函数值大于白色/黄色部分的函数值。
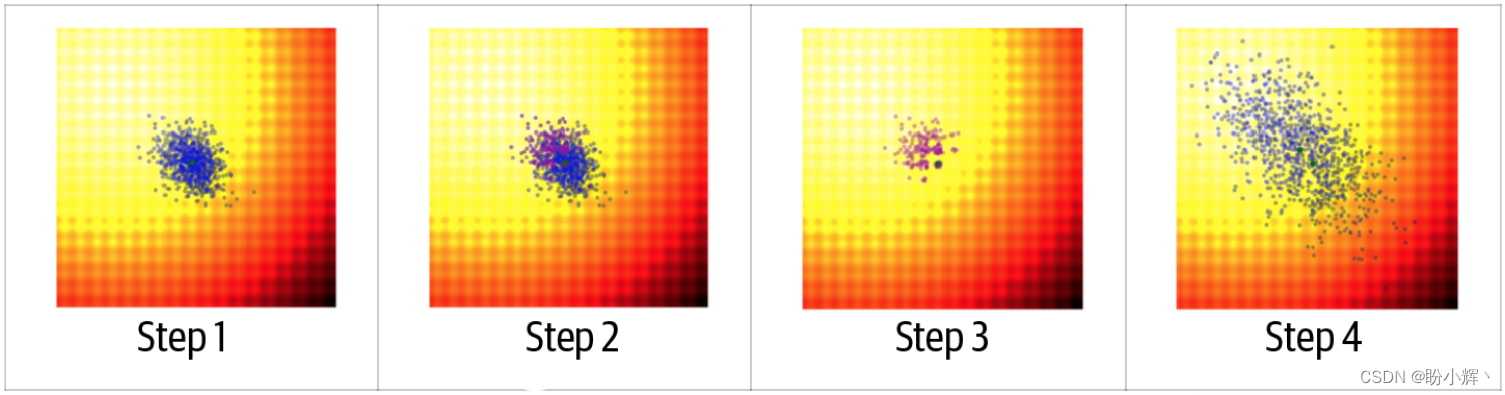
步骤如下:
- 从随机生成的二维正态分布开始,并从中采样一系列候选候选智能体,如蓝色部分所示
- 计算每个候选智能体的函数值,并选出最佳的25%,如紫色部分所示,我们将这个点集称为
P - 将新正态分布的均值设为
P中所有点的均值。这可以看作是繁殖阶段,在此阶段,我们只使用最佳候选智能体生成一个新的均值。将新正态分布的协方差矩阵设为P中各点的协方差矩阵,但在计算协方差时使用的是现有均值而不是P中各点的当前均值。现有均值与P中所有点的均值之间的差异越大,下一个正态分布的方差就越大。这会在寻找最优参数的过程中产生动量的效果 - 然后可以使用更新后的均值和协方差矩阵,从新的正态分布中采样新的候选智能体
下图展示了该过程几代的情况。可以看到,随着均值朝着最小值移动时,当移动的步幅较大时,协方差变大;而当均值稳定在真正的最小值时,协方差变小。

对于赛车任务来说,我们没有一个明确的定义要最大化的函数,而是有一个包含 867 个参数的环境,我们需要通过优化这些参数来确定智能体的得分。最初,一些参数组合可能会因为随机机会而生成更高的得分,而且算法会逐渐地推动正态分布朝着能够在环境中获得高分的参数集合的方向移动。
4.5.3 并行化 CMA-ES
CMA-ES 的一个巨大优势是它可以很容易地并行化。算法最耗时的部分是计算给定参数集的得分,因为它需要在环境中模拟具有这些参数的智能体。但这个过程可以并行化,因为各个模拟之间没有依赖关系。
在实际中,我们采用了主从设置,其中一个主进程负责将需要测试的参数集并行发送到多个从属进程,从属节点将结果返回给主节点,然后由主节点求结果的累计和,再将所得的总结果传递给 CMA-ES 对象。
主节点进程将要测试的参数集并行发送给多个从节点进程。从节点将结果返回给主节点,主节点累积结果,然后将该代的整体结果传递给 CMA-ES 对象。该对象根据上图所示要求更新正态分布的均值和协方差矩阵,并向主节点提供新的要测试的候选智能体,然后不断循环此过程,如下图所示:
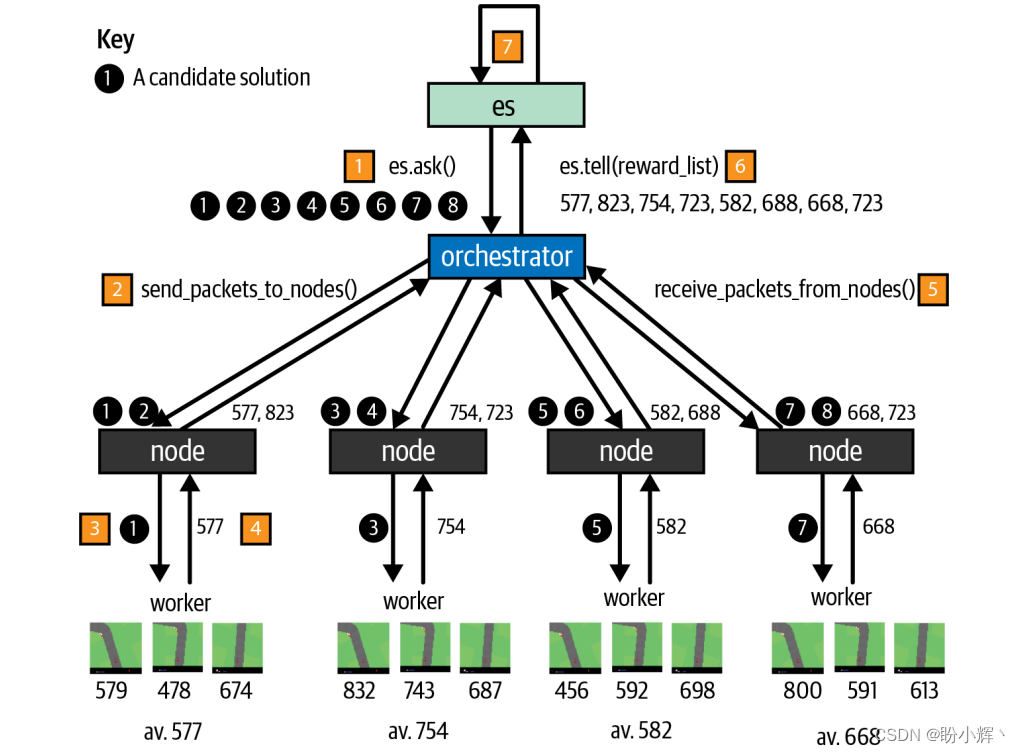
- 主节点向
CMA-ES对象 (es) 请求一组要测试的参数 - 主节点按照从节点的数量进行分割,这里,每个四个从节点进程都分配两组参数进行测试
- 从节点运行工作进程,依次利用每组参数运行多个回合,这里,我们为每组参数运行三个回合
- 对每个回合的奖励求平均,每组参数得到一个分数
- 从节点将得分列表返回给主节点
- 主节点将所有得分汇总在一起,将该列表发送给
es对象 es对象使用奖励列表来计算新的正态分布,如上图所示
经过大约 200 代的训练,赛车任务的平均奖励得分可以达到 840 左右。
5. 在生成环境中训练
控制器的训练过程使用 Gym CarRacing 环境,来模拟从一个状态转移到下一个状态的 step 方法,该方法给定环境的当前状态和选择的动作,计算下一个状态和奖励。
step 方法的功能与模型中的 MDN-RNN 非常相似。给定当前 z 和选择的动作,从 MDN-RNN 中采样输出下一个 z 和奖励的预测。
实际上,可以将 MDN-RNN 视为一种环境,但是它在 z 空间而不是原始图像空间中进行操作。这意味着我们实际上可以用 MDN-RNN 的生成环境代替真实环境,由 MDN-RNN 生成环境,然后在其中训练控制器。
换句话说,MDN-RNN 通过最初的随机 rollout 数据集已经学习到了关于真实环境的一般情况,因此在训练控制器时可以代替真实环境。这意味着智能体可以通过思考如何在生成环境中最大化奖励来训练自己学会新任务,而无需在真实世界中测试策略。然后,它在第一次执行以前从未尝试过的任务时就能够有出色的表现。
比较在真实环境和生成环境中进行训练的体系结构,如下图所示。
在生成环境体系结构中,控制器的训练完全在 z 空间中进行,无需解码 z 向量为可识别的赛道图像。当然,为了以可视化的形式显示智能体的表现,我们也可以显示出赛道图像,但这对于训练本身并非必要。
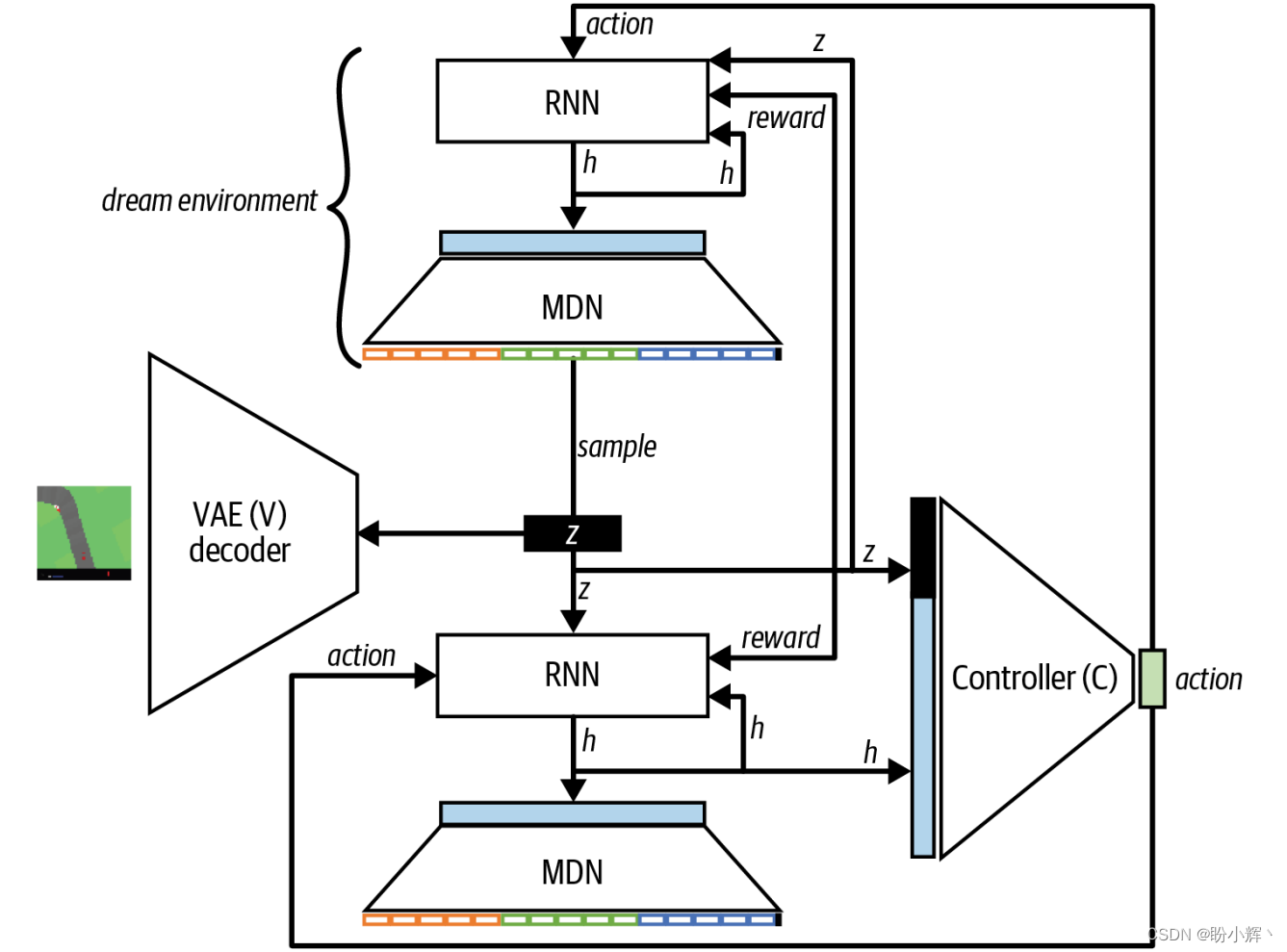
完全在 MDN-RNN 生成环境中训练智能体的挑战之一是过拟合。虽然
智能体在生成环境中发现了某个有奖励的策赂,但由于 MDN-RNN 未能完整
地捕捉到真实环境在特定条件下的行为,因此该策赂不能很好地推广到真实
环境,此时就会发生过拟合。
可以通过添加一个控制模型不确定性的温度参数来缓解过拟合问题。增加这个参数,通过 MDN-RNN 采样 z 时的方差就会被放大,从而在生成环境中训练时会出现更多不稳定的 rollout。控制器在产生更安全、更好地理解状态的策赂时会收到更高的奖励,因此更有可能生成普遍适合真实环境的一般性策赂。然而,增加温度参数时需要谨慎,以免使环境过于动荡,导致控制器无法学习任何策略,因为生成环境无法随着时间的推移保持足够的一致性。
需要注意的是,控制器从未在真实环境中尝试过该任务。它只是在真实环境中随机游走(用于训练 VAE 和 MDN-RNN 生成环境模型),然后使用生成环境来训练控制器。使用生成式世界模型作为强化学习方法的关键优势是,在生成环境中进行的每一代训练比在真实环境中快得多。这是因为 MDN-RNN 对 z 和奖励的预测比 Gym 环境对 z 和奖励的计算速度更快。
小结
在本节中,学习了变分自编码器 (variational autoencoder, VAE)如何应用于强化学习环境中,使智能体能够摆脱真实环境的束缚,通过在自己生成的环境中测试策略来学习有效的策略。训练 VAE 学习环境的潜表示,然后将其用作输入传递到循环神经网络中,在潜空间内预测未来轨迹。智能体可以使用这个生成模型生成环境,通过进化方法反复测试策略,以便得到能够很好的推广到真实环境中的策略。
系列链接
AIGC实战——生成模型简介
AIGC实战——深度学习 (Deep Learning, DL)
AIGC实战——卷积神经网络(Convolutional Neural Network, CNN)
AIGC实战——自编码器(Autoencoder)
AIGC实战——变分自编码器(Variational Autoencoder, VAE)
AIGC实战——使用变分自编码器生成面部图像
AIGC实战——生成对抗网络(Generative Adversarial Network, GAN)
AIGC实战——WGAN(Wasserstein GAN)
AIGC实战——条件生成对抗网络(Conditional Generative Adversarial Net, CGAN)
AIGC实战——自回归模型(Autoregressive Model)
AIGC实战——改进循环神经网络
AIGC实战——像素卷积神经网络(PixelCNN)
AIGC实战——归一化流模型(Normalizing Flow Model)
AIGC实战——能量模型(Energy-Based Model)
AIGC实战——扩散模型(Diffusion Model)
AIGC实战——GPT(Generative Pre-trained Transformer)
AIGC实战——Transformer模型
AIGC实战——ProGAN(Progressive Growing Generative Adversarial Network)
AIGC实战——StyleGAN(Style-Based Generative Adversarial Network)
AIGC实战——VQ-GAN(Vector Quantized Generative Adversarial Network)
AIGC实战——基于Transformer实现音乐生成
AIGC实战——MuseGAN详解与实现
AIGC实战——多模态模型DALL.E 2
AIGC实战——多模态模型Flamingo