一、背景介绍


特点与改进
-
模型架构:YOLOv5采用了更高效的网络结构设计,结合了CSPNet(Cross Stage Partial Network)和PANet(Path Aggregation Network),旨在减少计算量的同时提高检测精度。
-
自动学习锚框:相较于之前的版本,YOLOv5能够根据训练数据集自动调整锚框(anchor boxes),从而适应不同的应用场景。
-
数据增强:引入了多种数据增强技术,如马赛克数据增强(Mosaic Data Augmentation),这有助于提升模型对不同尺度和视角下物体的识别能力。
-
易于使用:YOLOv5提供了非常友好的接口和文档支持,使得开发者可以更容易地进行模型训练、验证以及部署。它支持PyTorch框架,具有良好的兼容性和扩展性。
-
性能表现:YOLOv5在保持高精度的同时,实现了更快的推理速度,适用于实时目标检测任务。它能够在多种硬件平台上运行,从高性能GPU到嵌入式设备。
二、Yolov5的主要内容
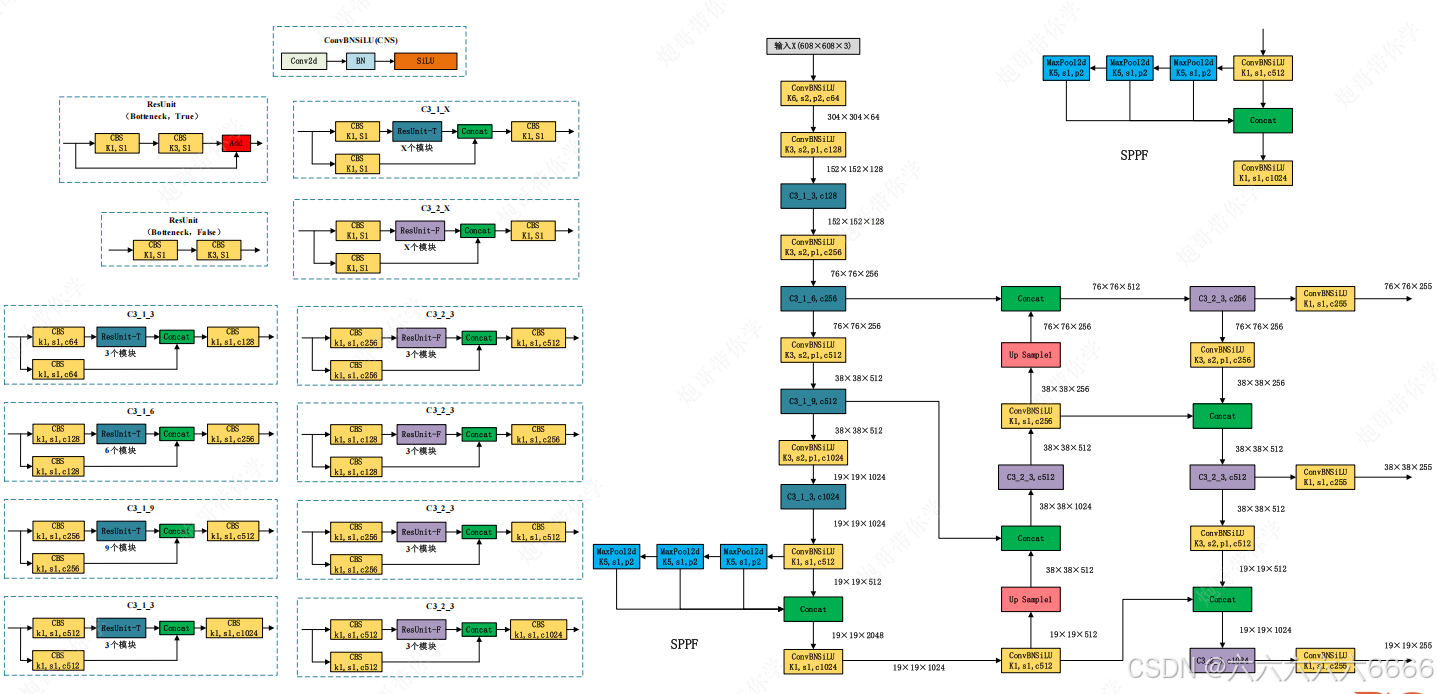
1、yolov5是一种单阶段目标检测算法,主要算法思路如下
- 输入端:Mosaic增强、自适应锚框计算、自适应图片缩放。
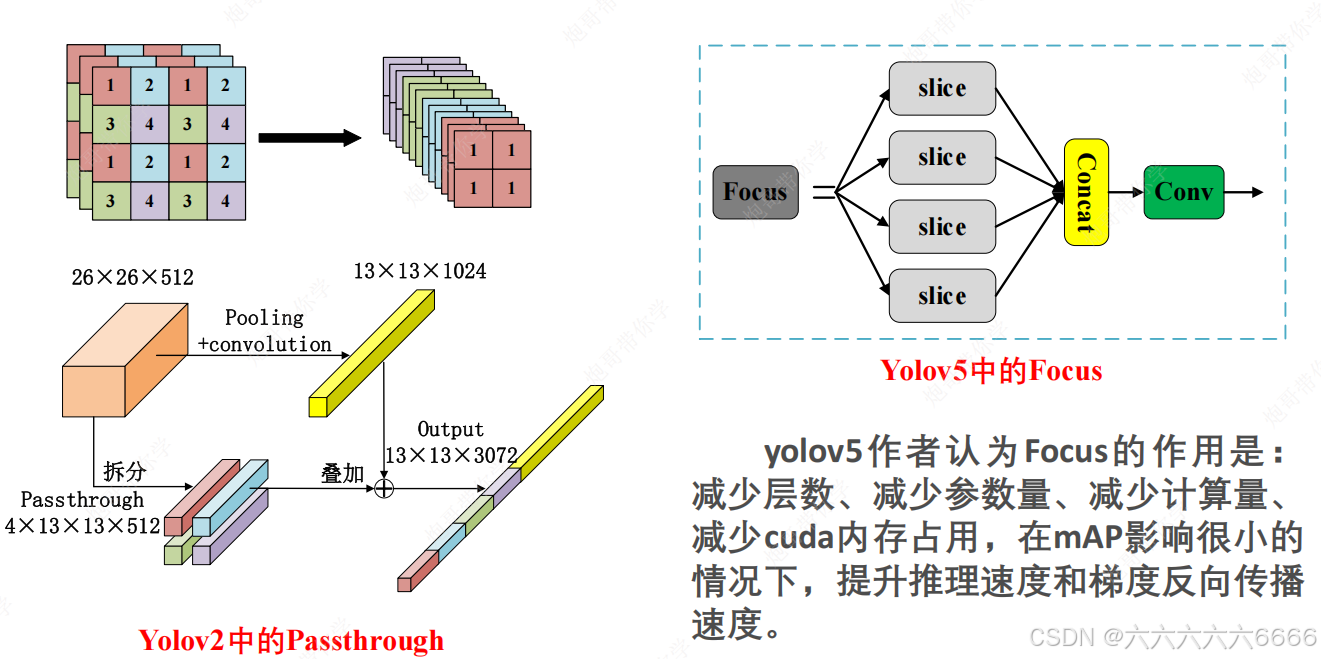
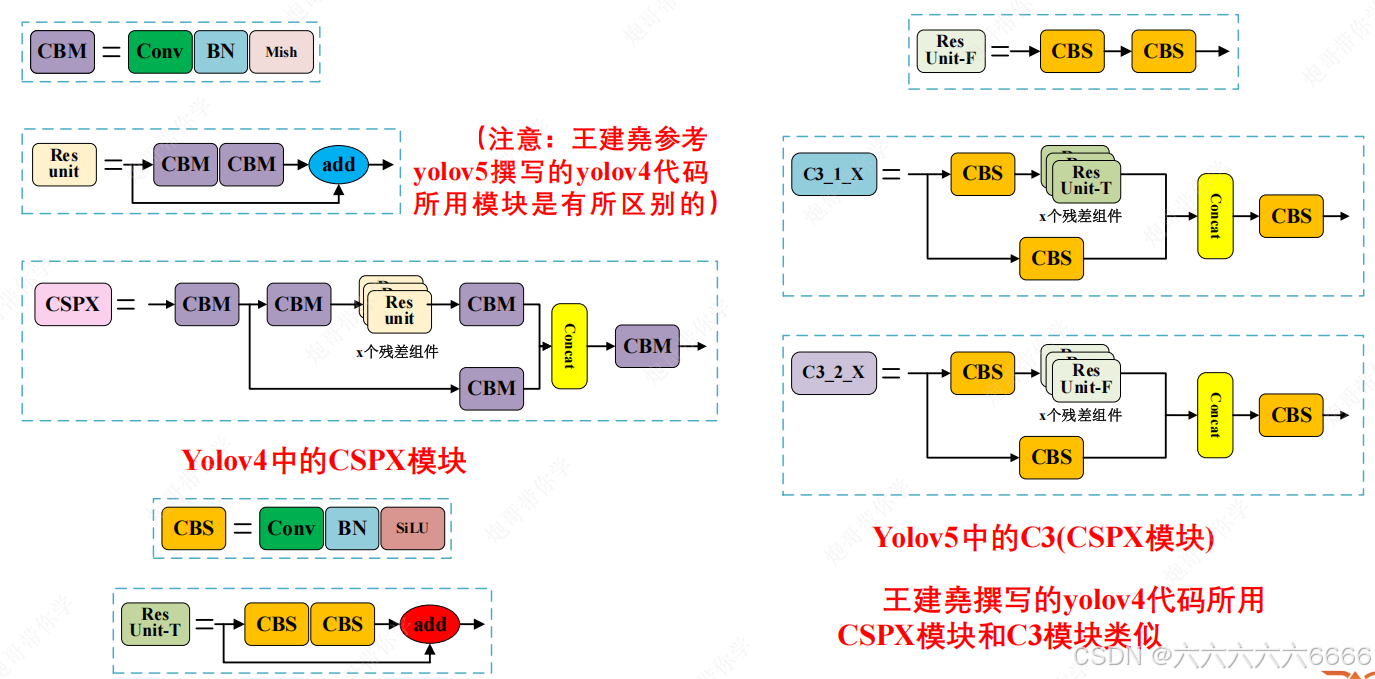
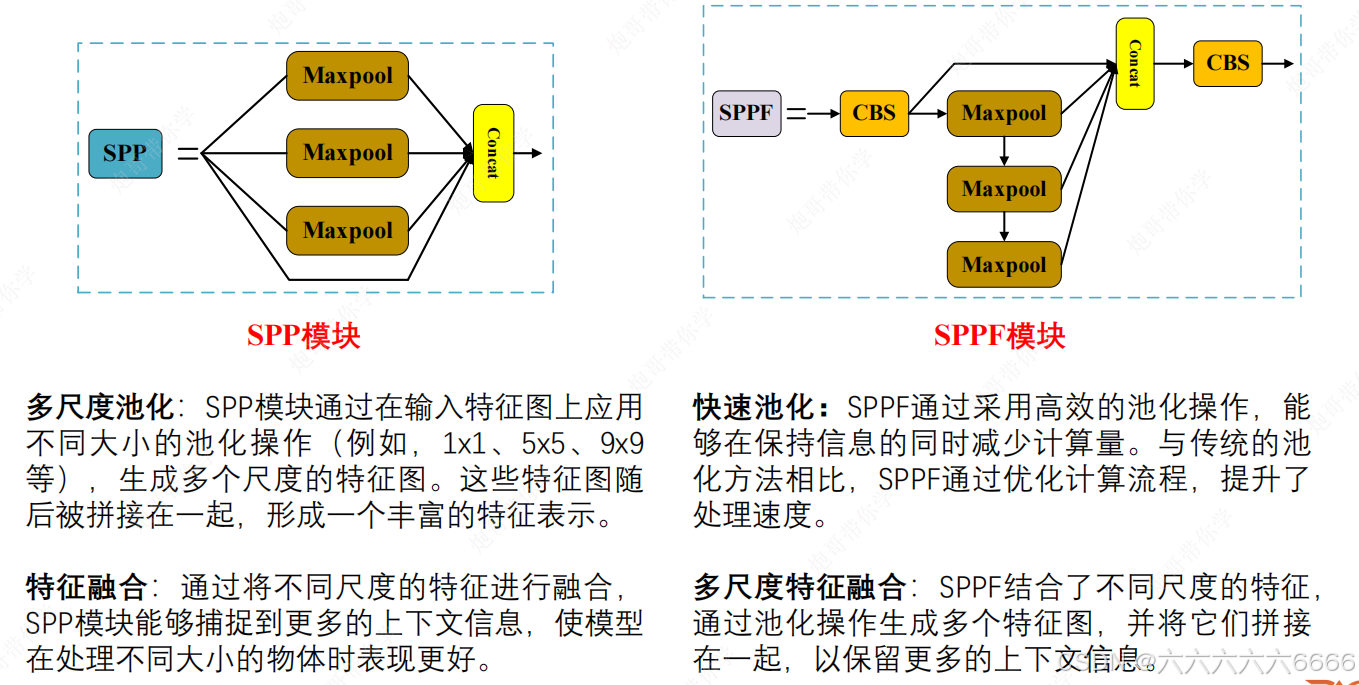
- 基准网络:Focus结构与CSP结构(C3结构),SPP(SPPF)。
- Neck网络:采用FPN+PAN结构。
- Head输出层:分类+定位于一体。
- 目标框回归。
- 正负样本匹配。
- 损失函数:分类损失+置信度损失+定位损失。
2、Mosaic增强
马赛克增强(mosaic augmentation)是当下十分强大的数据增强之一,可以显著提升图像中的目标实例的丰富度、图像自身的检测难度,这对于提升模型的性能起到了极大的积极作用。对于YOLO系列,最早使用马赛克增强的是由知名的ultralytics团队实现的YOLOv3,随后在官方的YOLOv4和5中,马赛克增强也被使用。
马赛克增强的思想十分简单,就是随机将4张不同的图像拼接在一起,组合成一张新的图像,不妨将此图像称为“马赛克图像”,如图所示

为了更好地理解这一强大的增强技术,我们举一个例子,假定输入图像的尺寸是640×640,首先,准备一个1280×1280的空白图像,依次将四张图像的最长边缩放到640,短边做相应比例的变换;其次,随机选一个中心点,依次将四张图像拼接上去;最后,使用空间扰动增强随机从这张1280×1280的马赛克图像抽取出640×640的图像来。相较于一般的图像,马赛克图像因融合了四张图像的信息,不仅丰富了其中的目标类型和数量,也加大了该图像的检测难度。很多时候,从数据的角度切入去增加一些学习的难度,往往对模型的性能是有益的。
3、自适应锚框
- 提高检测精度:通过与数据集中目标尺寸匹配的锚框设置,模型能够更准确地定位和分类对象。
- 优化训练效率:自适应的锚框减少了无效或低效的检测匹配,提高了正样本的比例,帮助模型更快收敛。
自适应锚框计算过程:
- 统计数据集中的目标框:通过遍历数据集,收集所有目标框的宽高比信息。
- 聚类分析:使用 k-means聚类 或改进的kmeans算法,基于宽高比对目标框进行聚类,得到多个锚框。
- 距离度量:通常采用IoU作为距离指标,以更好地反映锚框与目标框的匹配程度。
- 确定最佳锚框:聚类完成后,选择与数据集目标特征匹配度最高的锚框集合,作为模型训练的默认锚框。
- 自动调整:YOLOv5在训练时会自动计算和推荐适合数据集的锚框配置,以帮助用户更快地开始训练,并获得更好的检测效果。
4、自适应图片缩放
- 计算长边缩放比例:假设原图尺寸为(523, 699)(设定为32的倍 数)计算长边缩放比例: r = 416 / 699 = 0.5951
- 将原图等比例缩放:(523,699) ---> (311, 416)
-
高padding = (320 - 311) / 2 = 4.5,所以推理阶段的分辨率为( 320 , 416) 填充为(416,416);
- H侧上下需要填充的大小 pad = (416 - 311) / 2 = 52.5