序言:
在大型电商、购物、直播活动期间,对于火爆流量的激增,如何保障业务稳定并且做到资源不浪费,自动回收。
场景:kubernetes 原生容器化承载业务流量(非云环境)
方案:kubernetes自带HPA、KPA、VPA板块
板块选择
一、KPA板块
KPA(Knative Pod Autoscaler)基于请求数对Pod自动扩缩容,KPA的主要限制在于它不支持基于CPU的自动扩缩容。
- 根据并发请求数实现自动扩缩容
- 设置扩缩容边界实现自动扩缩容
扩缩容边界是指应用程序提供服务的最小和最大Pod数量。通过设置应用程序服务的最小和最大Pod数量实现自动扩缩容。
二、HPA板块
国内HPA介绍地址:
https://kubernetes.p2hp.com/docs/tasks/run-application/horizontal-pod-autoscale/
水平扩缩容意味着更多的pod被创建和清理,支持平均 CPU 利用率、平均内存利用率或你指定的任何其他自定义等指标,自动伸缩Replication Controller、Deployment 或者Replica Set 中的 Pod 数量。
- 基于kube-controller-manager控制器定义的服务启动参数horizontal-pod-autoscaler-sync-period(default 15s)周期性检测CPU的使用率
- HorizontalPodAutoscaler 被实现为 Kubernetes API 资源和控制器。
- HorizontalPodAutoscaler 的常见用途是将其配置为从聚合 API
(metrics.k8s.io、custom.metrics.k8s.io 或 external.metrics.k8s.io)获取指标。
注意:metrics.k8s.io API 通常由名为 Metrics Server 的插件提供,需要单独启动,部署方案:
https://blog.csdn.net/binqian/article/details/144170031
优缺点
优点:
- 支持滚动升级时扩缩
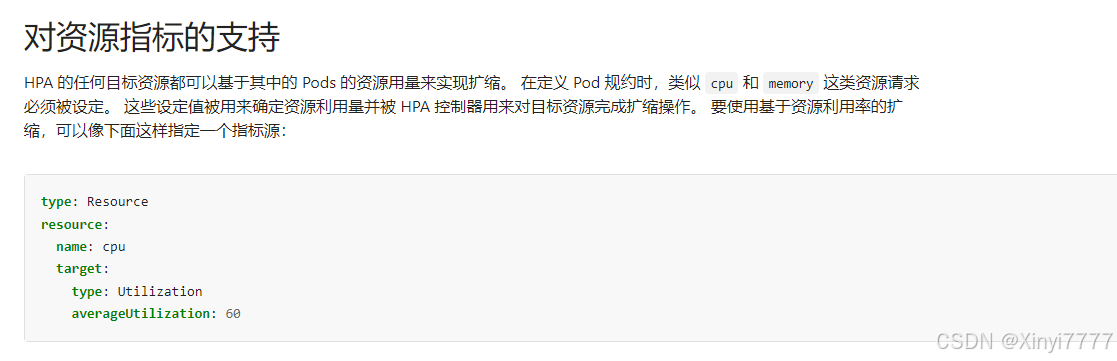
- HPA 的任何目标资源都可以基于其中的 Pods 的资源用量来实现扩缩。
- 支持容器资源指标
- 可扩展性强,支持自定义指标
- 单独对 Metrics API 的支持


缺点:
- HPA的流程涉及到POD从0到1流程的创建,流程中的网络问题比较敏感
- 现有场景都是依赖Metric Server去动态监测
- 水平扩展需要临时或者长期有足够的空闲资源
- 现有常用的副本控制器不支持 DaemonSet
- 参与自动伸缩的副本控制器不得指定副本数量,容易导致HPA异常
核心参数
- ScaleTargetRef:指定 HPA 将要作用的资源对象,如 Deployment、Replica Set 或 RC 的名称。
- MinReplicas:最小副本数,即使在负载很低时也不会低于这个数量。
- MaxReplicas:最大副本数,即使在负载很高时也不会超过这个数量。
- Metrics:定义用于触发伸缩的度量标准和目标值。常见:targetCPUUtilizationPercentage
用例说明
---
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: xxxx #自定义名称
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment #指定要自动缩放的目标对象,这里是一个Deployment
name: xxxx #指定deployment的标签name
minReplicas: 1
maxReplicas: 5
#自动扩缩的副本数,最大5,最小1
targetCPUUtilizationPercentage: 50 #CPU利用率的阀值50%
压力测试
本机环境如下:
业务yaml
[root@k8s-docker-master ~]# cat hpa-test.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: centos-test
labels:
test: centos
spec:
replicas:
selector:
matchLabels:
test: centos
template:
metadata:
labels:
test: centos
spec:
containers:
- name: centos
image: centos:7
command: ["/bin/bash", "-c", "yum -y install epel-release;yum -y install stress;sleep 3600"]
resources:
limits:
cpu: "1"
memory: 512Mi
---
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: hpa-centos7
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: centos-test
minReplicas: 1
maxReplicas: 3
targetCPUUtilizationPercentage: 50
[root@k8s-docker-master ~]# kubectl apply -f hpa-test.yaml
deployment.apps/centos-test configured
horizontalpodautoscaler.autoscaling/hpa-centos7 created
[root@k8s-docker-master ~]# kubectl get pod -A | grep centos-test
default centos-test-594d5479c8-tf44w 1/1 Running 0 4m37s
[root@k8s-docker-master ~]# kubectl get horizontalpodautoscaler -A
NAMESPACE NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
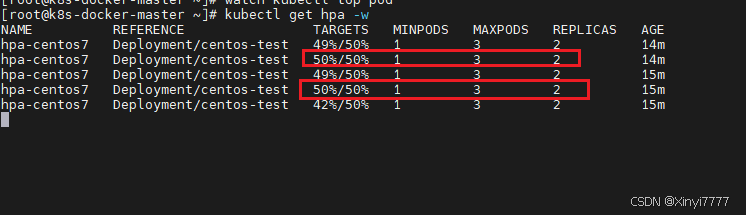
default hpa-centos7 Deployment/centos-test 0%/50% 1 3 1 66s
满足阈值的开始扩容,低于开始缩容,这里显示REPLICAS数值为2不跳动是因为扩容很快,缩容很慢导致。建议弄一个新的环境去压力测试。


三、VPA板块
VPA 全称 Vertical Pod Autoscaler,即垂直 Pod 自动扩缩容,它根据容器资源使用率自动设置 CPU 和内存的requests, 以便为每个 Pod 提供适当的资源。
既可以缩小过度请求资源的容器,也可以根据其使用情况随时提升资源不足的容量
使用 VPA 的意义:
- Pod 资源用其所需,提升集群节点使用效率;
- 不必运行基准测试任务来确定 CPU 和内存请求的合适值;
- VPA可以随时调整CPU和内存请求,无需人为操作,因此可以减少维护时间。
注意:VPA目前还没有生产就绪,在使用之前需要了解资源调节对应用的影响。
VPA架构图
VPA 主要包括两个组件:
1)VPA Controller
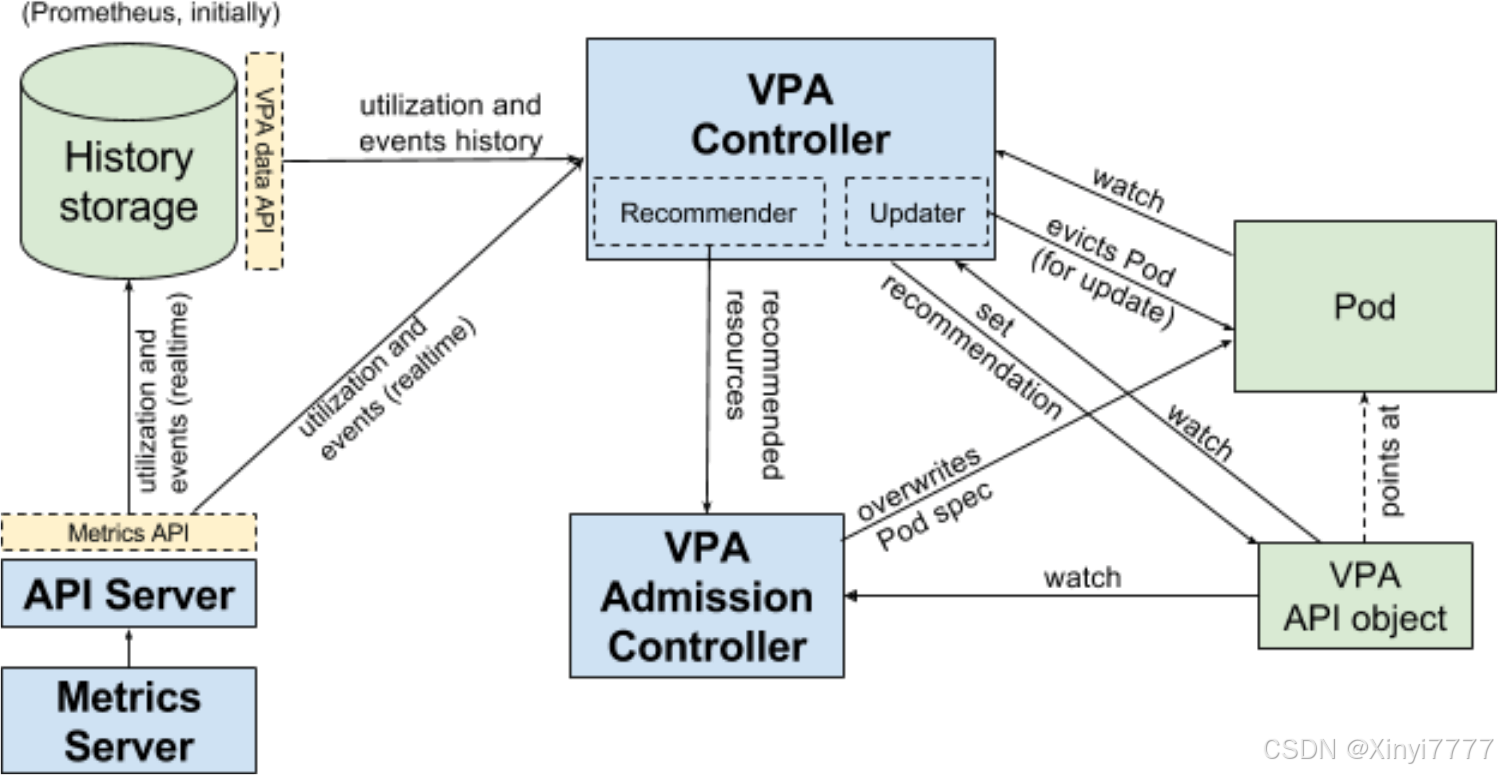
- Recommendr:给出 pod 资源调整建议
- Updater:对比建议值和当前值,不一致时驱逐 Pod (evicts pods)
2)VPA Admission Controller - Pod 重建时将 Pod 的资源请求量修改为推荐值
utilization and events history(获取历史使用率和事件)
utilization and events (realtime)(获取实时使用率和事件)
工作流程
VPA只监听pod和利用Updater驱除pod,推荐数值
真正执行覆写(overwrites pod spec)是VPA Admission Crotroller
流程如下:
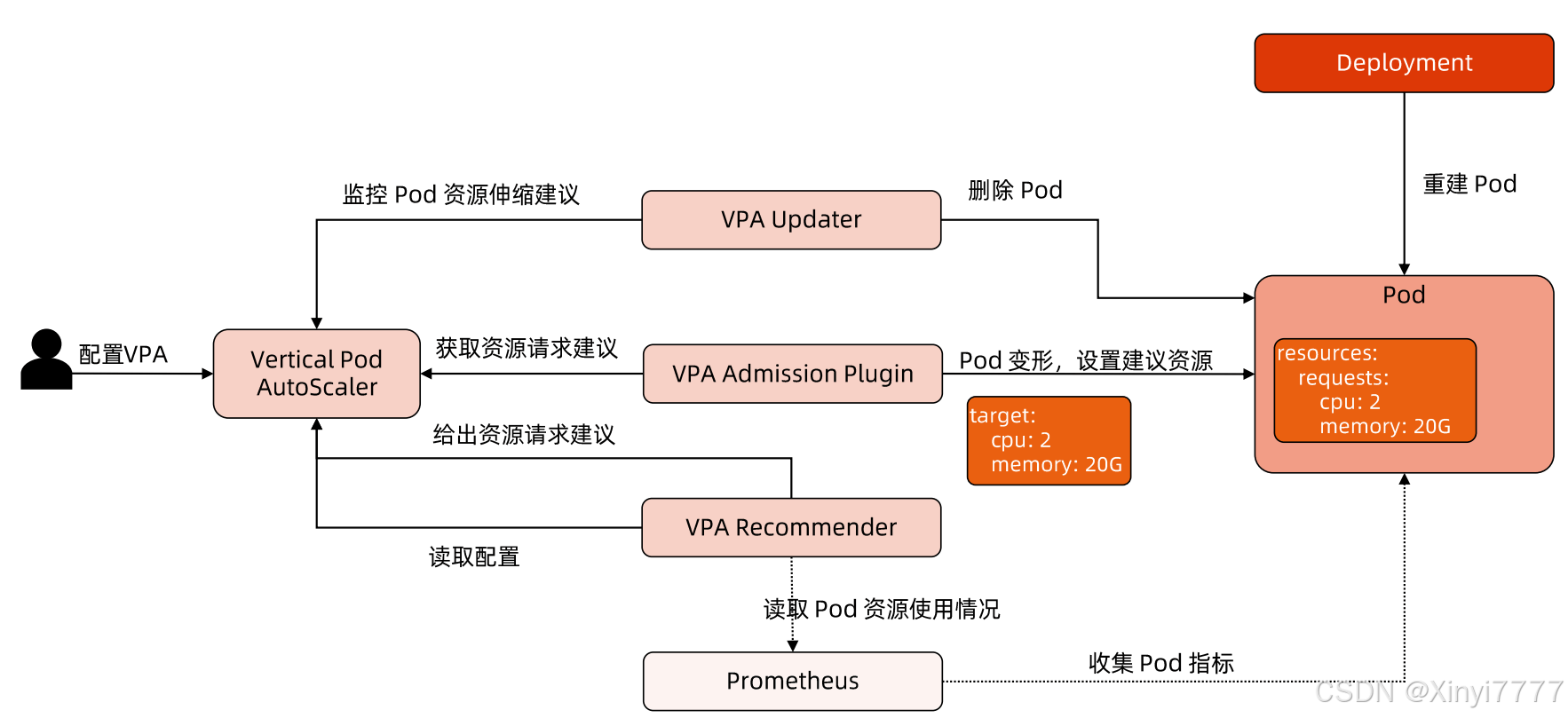
- 若资源使用率发生变化,Recommender会对当前资源使用情况和历史资源使用情况,进行分析计算资源使用的阈值,若对比计算值和当前值不一致会给出资源调整建议(set
recommendation过程) - Updater根据建议调用API去除pod
- pod被驱除后就会触发副本控制器进行重建,在这重建过程中VPA Admission
Crotroller会监听拦截,根据Recommended resources来调整资源 - VPA Admission Crotroller执行overwrites pod spec更改pod资源信息对pod进行重建

VPA优缺点
优点:
- VPA自动对集群内资源进行计算调度,降低运维成本
- VPA垂直扩展便于pod资源管理
- VPA类似于资源动态分配,能准确的使用掉分配的资源,不造成浪费
缺点:
- VPA成熟度不足,涉及到重建pod,容易调度到其他node节点
- VPA 不会驱除无副本控制器管理下的pod
- 不能和前者监控CPU、内存为度量的HPA同时运行(若HPA有定制化或者外部资源可以)
- 强依赖admission webhook准入控制器,不能跟其他admission webhook冲突
- VPA会处理绝大多数的OOM事件,但无法做到100%
- VPA未应用在大型集群的经验,生态范围太小
- VPA 通过Remmonder计算的阈值可能会超过当前node的资源上线,导致pod重建后pending,无法正常调度
- 多个VPA同时调度同一个pod 会造成未定义的行为
总体上来说,弊端偏大,特别是对pod重建具有对业务很大的冲击性,容易导致业务崩溃,据说在v1.26版本后有新功能实现可以缓解破坏性重建pod带来的风险
用例说明(待更新)