1.今天我们来讲下一个非常有用的东西,代理ip池,结果就是一个任务每隔一定时间去到 目标ip代理提供网站(www.bugng.com)去爬取可用数据存到mysql数据库,并且检测数据库已有数据是否可用,不可用就删除。
2. 编写 提取代理ip到数据库 的爬虫
2.1准备mysql表
CREATE TABLE `t_ips` (
`id` int(10) NOT NULL AUTO_INCREMENT COMMENT '主键',
`ip` varchar(15) COLLATE utf8_unicode_ci DEFAULT NULL COMMENT 'ip',
`port` int(10) NOT NULL COMMENT 'port',
`type` int(10) NOT NULL DEFAULT '0' COMMENT '0:http 1:https',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=421 DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci COMMENT='ip表';2.2创建爬虫工程,编写items.py(对应数据库的字段)
import scrapy
class IpsItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
ip = scrapy.Field()
port = scrapy.Field()
httpType = scrapy.Field()2.3编写settings.py
# -*- coding: utf-8 -*-
####################自已的配置################
MAX_PAGE = 2 ##抓取的代理ip网址 的 页数
#0 : http 1:https
TYPE = 0 ### 代理ip类型
URL = 'http://www.bugng.com/gnpt?page=' ### 代理ip网址
TIMER_STOP_TIME = 20 ### 定时器暂停执行时间
######################################
BOT_NAME = 'ips'
SPIDER_MODULES = ['ips.spiders']
NEWSPIDER_MODULE = 'ips.spiders'
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'
ITEM_PIPELINES = {
'ips.pipelines.IpsPipeline': 300,
}
# 禁止重试
RETRY_ENABLED = False
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'csdn (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# 减小下载超时:
DOWNLOAD_TIMEOUT = 2
# 禁止cookies:
COOKIES_ENABLED = False
# 延迟下载 防止被ban
DOWNLOAD_DELAY=22.4编写spider
这里用到了bs4,需要自行安装
# -*- coding: utf-8 -*-
import scrapy
import logging
from bs4 import BeautifulSoup
from ips.items import IpsItem
from ips.settings import *
class XicispiderSpider(scrapy.Spider):
name = 'xiciSpider'
allowed_domains = ['xicidaili.com']
start_urls = ['http://xicidaili.com/']
### 开始 放入url
def start_requests(self):
req = []
for i in range(1,MAX_PAGE):
### 代理ip网址的第几页的 url
req.append(scrapy.Request(URL + str(i-1)))
return req
## 每一页url的 解析回调函数,利用bs4解析
def parse(self, response):
print('@@@@@@@@@ 开始解析 '+response.url)
try:
soup = BeautifulSoup(str(response.body, encoding = "utf-8"),'html.parser')
trs = soup.find('table',{'class':'table'}).find_all('tr')
for tr in trs[1:]:
tds = tr.find_all('td')
cur = 0
item = IpsItem()
item['httpType'] = TYPE
for td in tds:
if cur == 0:
item['ip'] = td.text
if cur == 1:
item['port'] = td.text
cur = cur +1
yield item #### 给pipline处理
except Exception as e:
logging.log(logging.WARN, '@@@@@@@@@ start parser ' + str(e))2.5编写pipline
这里需要安装 : pip install mysqlclient
这里插入数据库之前做两个校验:
1.数据是否存在
2.数据是否可用
# -*- coding: utf-8 -*-
import MySQLdb
import MySQLdb.cursors
from twisted.enterprise import adbapi
import logging
import requests
class IpsPipeline(object):
def __init__(self):
dbargs = dict(
host='你的数据库ip',
db='数据库名称',
user='root',
passwd='数据库密码',
charset='utf8',
cursorclass=MySQLdb.cursors.DictCursor,
use_unicode=True,
)
self.dbpool = adbapi.ConnectionPool('MySQLdb', **dbargs)
##处理每个yeild的item
def process_item(self, item, spider):
res = self.dbpool.runInteraction(self.insert_into_table, item)
return item
def insert_into_table(self, conn, item):
ip = item['ip']
port = item['port']
# 先查询存不存在
if self.exsist(item,conn):
return
# 查询 此代理ip是否可用,可用就加入数据库
if self.proxyIpCheck(item['ip'],item['port']) is False:
print("此代理ip不可用,proxy:",item['ip'],':',str(item['port']))
return
sql = 'insert into t_ips (ip,port,type) VALUES ('
sql = sql + '"' + item['ip'] + '",'
sql = sql + str(item['port']) + ','
sql = sql + str(item['httpType']) + ','
sql = sql[0:-1]
sql = sql + ')'
try:
conn.execute(sql)
print(sql)
except Exception as e:
logging.log(logging.WARNING, "sqlsqlsqlsqlsqlsqlsql error>> " + sql)
def exsist(self,item,conn):
sql = 'select * from t_ips where ip="' + item['ip'] + '" and port=' + str(item['port']) + ''
try:
# 执行SQL语句
conn.execute(sql)
# 获取所有记录列表
results = conn.fetchall()
if len(results) > 0: ## 存在
#print("此ip已经存在@@@@@@@@@@@@")
return True
except:
return False
return False
##判断代理ip是否可用
def proxyIpCheck(self,ip, port):
server = ip + ":" + str(port)
proxies = {'http': 'http://' + server, 'https': 'https://' + server}
try:
r = requests.get('https://www.baidu.com/', proxies=proxies, timeout=1)
if (r.status_code == 200):
return True
else:
return False
except:
return False2.6 测试爬虫 scrapy crwal 爬虫名
3. 到此我们的 提取代理ip到数据库的 爬虫就写好了,接下来就是我们的任务定时器的编写
#####在我们的爬虫项目的settings.py文件的同级目录新建一个start.py文件
import os
import pymysql
import threading
from settings import *
##定时器调用的run方法
def run():
clearIpPool()
### 循环定时器,不然执行一次就over了
timer = threading.Timer(TIMER_STOP_TIME, run)
timer.start()
########从这里开始执行
print("ip池定时器开始,间隔时间:",str(TIMER_STOP_TIME),'s')
########开启定时器 TIMER_STOP_TIME为settings.py中的配置
timer = threading.Timer(TIMER_STOP_TIME,run)
timer.start()
def clearIpPool():
print("定时器执行,清扫ip数据库池")
## 利用 系统scrapy命令重新爬取代理ip
os.system('scrapy crawl xiciSpider --nolog')
# 遍历数据库 去除无用的代理ip
removeUnSafeProxyFromDB()
print("定时器执行完毕")
###### 查询数据库,找出无用的代理ip并且删除
def removeUnSafeProxyFromDB():
# 打开数据库连接
db = pymysql.connect("39.108.112.254", "root", "abc123|||456", "xici")
# 使用cursor()方法获取操作游标
cursor = db.cursor()
# SQL 查询语句
sql = "SELECT * FROM t_ips"
try:
# 执行SQL语句
cursor.execute(sql)
# 获取所有记录列表
results = cursor.fetchall()
for row in results:
id = row[0]
ip = row[1]
port = row[2]
if proxyIpCheck(ip, str(port)) is False:
print("此代理ip不可用,proxy:",ip, ':', str(port))
## 执行删除
sql = "DELETE FROM t_ips WHERE id = "+str(id)
# 执行SQL语句
cursor.execute(sql)
print(sql)
# 提交修改
db.commit()
return
except:
print("Error: unable to fetch data")
# 关闭数据库连接
db.close()
#####检测代理ip是否可用
def proxyIpCheck(ip, port):
server = ip + ":" + str(port)
proxies = {'http': 'http://' + server, 'https': 'https://' + server}
try:
r = requests.get('https://www.baidu.com/', proxies=proxies, timeout=1)
if (r.status_code == 200):
return True
else:
return False
except:
return False4.如果你是windows平台,cmd执行运行 python start.py , 任务就会一直执行,除非关掉cmd
5.如果你是linux平台,最好编写一个.sh文件 来执行,还可以把这个.sh搞成开机启动等等
6.我的结果图
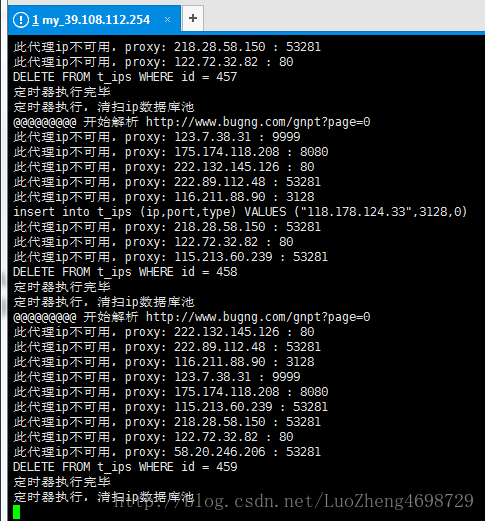
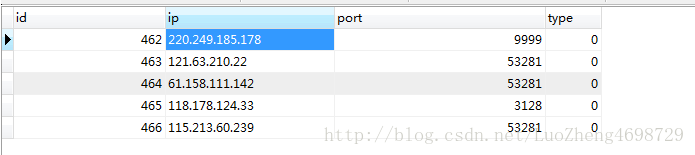
这里我就爬取了一页数据,大家可以修改settings.py的MAX_PAGE值,此值就是要爬取的页数。谢谢大家,有啥问题加我qq讨论。
老生常谈:深圳有爱好音乐的会打鼓(吉他,键盘,贝斯等)的程序员和其它职业可以一起交流加入我们乐队一起嗨。我的QQ:657455400