目录
三、模拟实现unordered_map和unordered_set
一、unordered系列关联式容器介绍
在C++98中,stl提供了一红黑树为底层的一系列关联式容器,如set和map。这些容器在搜索数据时的效率可以达到logN,即最差情况下需要比较红黑树的高度次。但是,当树中的节点非常多的时候,它的搜索效率其实也不是非常理想。而最理想的搜索效率,就是能够在进行非常少的比较次数的情况下就找到对应元素,即O(1)。
因此,在C++11中,stl又提供了4个unordered系列的关联式容器,这4个容器与红黑树结构的关联式容器使用方式基本类似,但是其底层结构完全不同。,使用的是哈希结构,其搜索效率可以达到O(1)。
二、unordered容器简单介绍
从接口上看,unordered容器和stl中的其他容器保持着高度的一致,所以大家只要会使用stl中的其他容器,学习unordered系列容器的使用成本就会非常低。因此,在这里只是简单的介绍一下unordered系列容器的部分使用,重点并不在这上面
1.unordered_map
从名字上就可以看出来,unordered_map其实就是与map相对应的一个容器。学过map就知道,map的底层是一个红黑树,通过中序遍历的方式可以以有序的方式遍历整棵树。而unordered_map,正如它的名字一样,它的数据存储其实是无序的,这也和它底层所使用的哈希结构有关。而在其他功能上,unordered_map和map基本上就是一致的。
1.1 unordered_map的特点
(1)unordered_map是用于存储<key, value>键值对的关联式容器,它允许通过key快速的索引到对应的value。
(2)在内部,unorder_map没有对<key, value>按照任何特定的顺序排序,为了能在常数范围内找到key所对应的value,unordered_map将相同哈希值的<key, value>键值对放在相同的桶中。
(3)unordered_map容器的搜索效率比map快,但它在遍历元素自己的范围迭代方面效率就比较低。
(4)它的迭代器只能向前迭代,不支持反向迭代。
1.2unordered_map和map的模板区别


从大结构上看,unordered_map和map的模板其实没有太大差距。学习了map和set我们就应该知道,map是通过T来告诉红黑树要构造的树的存储数据类型的,unordered_map也是一样的,但是它的参数中多了Hash和Pred两个参数,这两个参数都传了仿函数,主要和哈希结构有关。这里先不过多讲解。
2.unordered_set
unordered_set其实也是一样的,从功能上来看和set并没有什么区别,只是由于地层数据结构的不同,导致unordered_set的数据是无序的,但是查找效率非常高。
2.1unordered_set和set的模板区别


很明显,unordered_set相较于set,多了Hash和Pred两个参数。这两个参数都是传了仿函数,和unordered_map与map之间的关系都是一样的,这里先不过多讲解。
3.效率对比
前文中也说了,unordered_map和unordered_set从功能上来讲,与map和set并没有太大的差别。除了数据是否有序外,主要就体现搜索效率上。这里为了方便测试,所以就直接用unordered_set和set进行对比。
3.1 插入效率对比
首先写出下面的测试代码:

通过这段代码,测试set和unordered_set在插入时效率差距。
运行该程序:
可以看到,在插入10w个数时,unordered_set的插入效率略高与set。
此时我们再将需要插入的数据增加到100w个再看看:
此时差距进一步扩大。此处set的插入效率比unordered_set效率低的原因就在于set的底层是一棵红黑树,在插入数据时可能需要进行旋转,当需要插入的数据越多,需要旋转的次数也就越多。而unordered_set的底层是哈希桶,虽然在插入中也需要调整,但是效率损失上就比set低。
当然,插入效率虽然有差距,但并不算大。而前文也说过了,unordered_set和set的主要效率差距体现在搜索上。因此我们再来对unordered_set和set的搜索效率进行对比。
3.2 搜索效率对比
首先在插入效率对比代码的基础上添加如下代码:
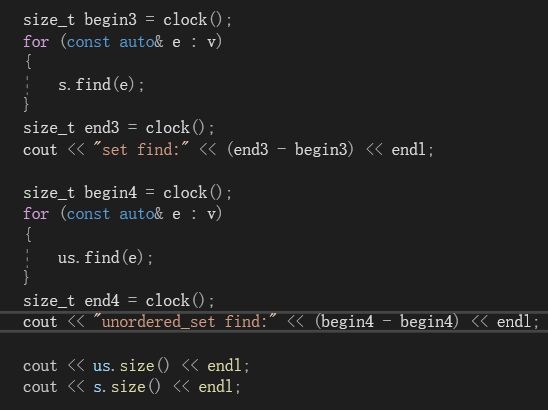
首先用10w个数来测试:
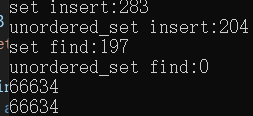
当传入10w个随机数时,一共生成了6w个不同的随机数,此时set的find效率就很明显低于unordered_set。
再传入100w个随机数进行测试:
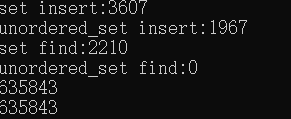
可以看到,当传入100w个随机数时,一共生成了63w个不同的随机数。但是可以发现,此时set的搜索效率已经很低了。但是unordered_set的搜索依然为0。这也就证明了使