学习时间:2022.04.22~2022.04.25
5. 基于深度学习的语言模型
5.1 从NNLM到词嵌入
从语言模型到词嵌入Word Embedding。一些基于CNN或RNN的结构本节并未提及,可见:深度学习NLP的各类模型及应用总结。
5.1.1 神经网络语言模型 NNLM
Neural Network Language Model,NNLM,生于2003,火于2013。
NNLM依然是一个概率语言模型,它通过神经网络来计算概率语言模型中每个参数。与N-gram模型一样是求 P ( X n ∣ X 1 n − 1 ) P(X_n|X_1^{n-1}) P(Xn∣X1n−1) ,NNML通过输入一段文本,预测下一个单词的方式来建立模型。采用的是MLP+tanh+softmax模型,使用交叉熵作为损失函数,反向传播算法进行训练。
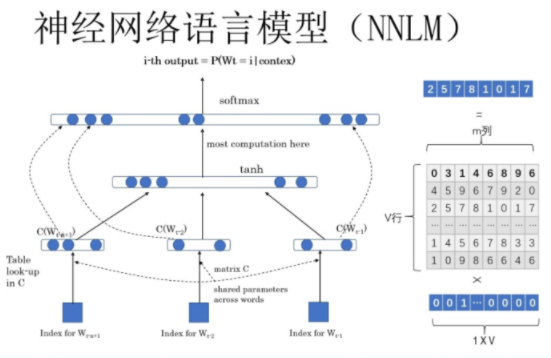
模型解释:
- 输入层:将context(w)每个词映射成一个长度为m的词向量(长度训练者指定,一般使用tf.random_normal随机初始化生成nxm的矩阵),词向量在开始是随机的,也是超参数参与网络训练;
- 使用随机初始化的方法建立一个 ∣ m ∣ × N |m|×N ∣m∣×N个词大小的查找表(lookup table);
- context(w):可以称之为上下文窗口长度,类似N-gram取多少个词作为添加。例如上下文窗口长度为 c = 3 c=3 c=3,则循环取四个词,前三个为特征值,最后一个为目标值;
- 投影层:将所有的上下文此项来给你拼接成一个长向量,作为目标w的特征向量。长度为 m ( n − 1 ) m(n-1) m(n−1);
- 隐藏层:拼接后的向量会经过一个规模为h的隐藏层,论文中使用tanh激活函数;
- 输出层:最后输出会通过softmax输出所有n个词的大小概率分布。
缺陷:
- 计算复杂度过大,参数较多(word2vec是一种改进的办法);仍然限制于N的大小,最好的就是不限制N的数量,且跟前后任意词汇都可能产生依赖,那么基于循环神经网络的RNNLM就是解决办法,因为RNN天生的结构就是针对序列前后任意长度的依赖的。
- 模型优化不够,输出的类别较多导致训练过慢、自回归语言模型,无法获取下文信息、早期方案,应用较少,一般python工具不会集成;
5.1.2 基于循环神经网络的语言模型 RNNLM
Recurrent Neural Network Language Model,RNNLM。
引入了RNN,形成了一个根据上下文,预测下一个词语概率的模型,所以以后想要预测某个句子S的概率,就可以按照模型计算多个时刻的P,相乘,即可得到句子的概率。天生的结构能处理任意长度的序列的依赖,可以不用人为限制模型输入长度。缺陷是计算和训练时间长。
5.1.3 Word2Vec
Word2Vec是2013年Google发布的工具,也可以说是一个产生词向量的一群模型组合。该工具主要包含两个词向量的生成模型,跳字模型(skip-gram)和连续词袋模型(continuous bag of words,CBOW),以及两种高效训练(优化加速)的方法:负采样(negative sampling)和层序softmax(hierarchical softmax)。Word2vec 本质上是一种降维操作——把词语从one-hot形式的表示降维到Word2vec表示的词嵌入。
由于 Word2vec 会考虑上下文,跟之前的Embedding方法相比,效果要更好;比之前的Embedding方法维度更少,所以速度更快;通用性很强,可以用在各种NLP任务中。但由于词和向量是一对一的关系,所以多义词的问题无法解决;word2vec是一种静态的方式,虽然通用性强,但是无法针对特定任务做动态优化。
需要说明的是:Word2vec 是上一代的产物(18年之前),18年之后想要得到最好的效果,已经不使用Word Embedding的方法了,所以也不会用到 Word2vec。
1. 词向量的生成模型
即Word2Vec如何计算得到词向量,一次计算只能采用一种方式。
个人理解:两种方式本质上都是一样的,网络结构、权重 W W W的大小和位置都一样。
(1)连续词袋模型CBOW
核心思想是从一个句子里面把一个词抠掉,在上下文已知的情况下,预测被抠掉的这个词出现的概率。
eg:把 {“The”,“cat”,“over”,“the”,“puddle”} 作为上下⽂,希望从这些词中预测或者⽣成中心词“jumped”。
CBOW模型的网络图如下,是一个简单的3层神经网络(输入层到Projection层没有非线性变换):
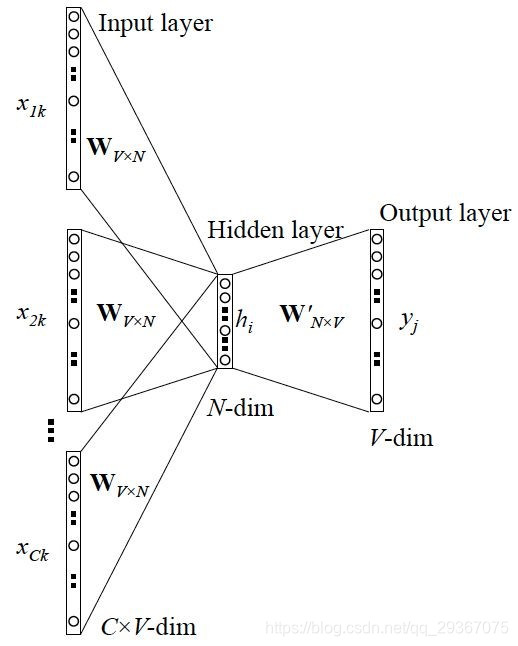
- 输入层:输入上下文单词的onehot(不包括单词本身),假设单词向量空间维度为 V × 1 V×1 V×1,上下文单词个数为 C C C;
- 隐藏/投影层:所有onehot分别乘共享的输入权重 W W W(初始化权重矩阵 W W W为 N × V N×V N×V矩阵, N N N为自己设定的数),所得的向量相加求平均作为隐层向量,Size为 N × 1 N×1 N×1;
- 输出层:隐藏层计算得到的 N × 1 N×1 N×1向量作为隐藏层的输入向量,乘输出权重矩阵 W ′ W' W′( W ′ W' W′为 V × N V×N V×N矩阵),得到 V × 1 V×1 V×1的输出向量,最后经过激活函数Softmax得到 V − d i m V-dim V−dim的概率分布,其中概率最大的index所指示的单词为预测出的中间词(也是one hot);
- 损失函数:预测得到的one hot与真实的one hot进行对比,采用交叉熵损失函数,通过梯度下降反向传播更新参数 W W W,这也是我们通过训练最终需要的权重矩阵。
(2)跳字模型Skip-Gram
与CBOW正好相反,Skip-Gram是输入某个单词,要求网络预测它的上下文单词。相当于给你一个词,让你猜前面和后面可能出现什么词。
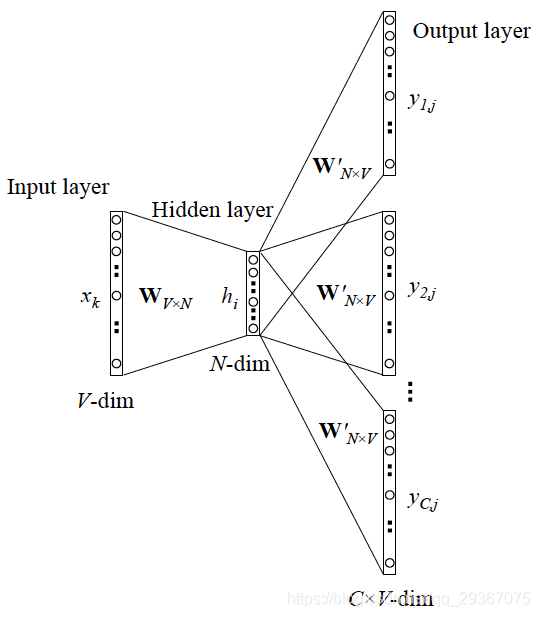
- 我们拥有的词汇库大小是 V V V(one hot的维数),预测模型输出的的窗口大小是 C C C, C = 2 R C=2R C=2R,我们的嵌入词向量的低维维度是 N N N;
- 输入层:1个词的one-hot的原始词向量( V × 1 V×1 V×1);由于嵌入词向量矩阵是唯一的,所以从输入层到隐藏层的权重 W W W(词向量矩阵, N × V N×V N×V)是唯一的,共享的;
- 隐藏/投影层:这一层输出经过 W W W加权处理的矩阵 N × 1 N×1 N×1;从隐藏层到输出层的权重矩阵 W ′ W' W′是 V × N V×N V×N矩阵;
- 输出层:矩阵和权重相乘得到 V × C V×C V×C矩阵的输出,最后经过softmax处理得到所有单词的one hot概率形式;
- 损失函数:同样,根据预测得到的one hot与真实的one hot进行对比,采用交叉熵损失函数,通过梯度下降反向传播更新参数 W W W和 W ′ W' W′。最后所得的权重矩阵 W W W就是我们所求的嵌入词向量Embedding矩阵。
有一点需要说明的是,因为一个中心词对应的上下文词可能有多个,所以正样本会有多个pair对<input_word,output_context1>,<input_word,output_context2>等,所以相同的语料,skip-gram比cbow训练的要更久。
2. 优化模型的加速方法
利用softmax求概率值时,每一次的训练我们都需要将词表里的每一个词都计算一遍(对所有的词进行排序,然后取最大值),这样遍历整个词表的操作会在大语料库计算时变得异常耗时、困难。因此,word2vec还有两个加速运算的机制,层次softmax和负采样。
两种方法好像没必要同时使用:层次Softmax和负采样能同时应用在Word2Vec模型中吗。
(1)Hierarchical Softmax
详细解释:word2vec原理(二) 基于Hierarchical Softmax的模型。
原理:为了避免隐藏层到输出的softmax层这里的庞大计算量,采用哈夫曼树来代替从隐藏层到输出softmax层的映射。哈夫曼树的所有内部节点就类似之前神经网络投影层的神经元,其中,根节点的词向量对应我们的投影后的词向量,而所有叶子节点就类似于之前神经网络softmax输出层的Vector,叶子节点的个数就是词汇表的大小。
在哈夫曼树中,隐藏层到输出层的Softmax映射不是一下子完成的,而是沿着哈夫曼树一步步完成的,因此这种Softmax取名为"Hierarchical Softmax"。其时间复杂度就从 O ( n ) O(n) </