五、聚类的质量评价
聚类分析是将一个数据集分解成若于个子集,每个子集称为一个簇,所有子集形成的集合称为该对象集的一个聚类。一个好的聚类算法应该产生高质量的簇和高质量的聚类,即簇内相似度总体最高,同时簇间相似度总体最低。鉴于许多聚类算法,包括 k k k-平均算法, DBSCAN算法等都要求用户事先指定聚类中簇的数目 k k k,因此,下面首先讨论k的简单估计方法。
(一)簇的数目估计
许多聚类算法,比如
k
k
k-平均算法,甚至DIANA算法等,都需要事先指定簇的数目
k
k
k,并且
k
k
k的取值会极大地影响聚类的质量,然而事先确定簇的数目
k
k
k并非易事。我们可以先考虑两种极端情况。
(1)把整个数据集
S
S
S当作一个簇,即令
k
=
1
k=1
k=1,这样做看上去既简单又方便,但这种聚类分析结果没有任何价值。
(2)把数据集
S
S
S的每个对象当作一个簇,即令
k
=
∣
S
∣
=
n
k=|S|=n
k=∣S∣=n,这样就产生了最为细粒度的聚类。因此,每个簇都不存在簇内差异,簇内相似度就达到最高。但这种聚类并不能为
S
S
S提供任何关于
S
S
S的概括性描述。
由此可知,簇的数目
k
k
k至少应该满足
2
≤
k
≤
n
−
1
2≤k≤n-1
2≤k≤n−1,但簇数
k
k
k具体取什么值最为恰当仍然是含糊不清的。
一般认为,
k
k
k的取值可以通过数据集分布的形状和尺度,以及用户要求的聚类分辨率来进行估计,且学者们已经有许多不同的估计方法,比如肘方法 (elbow method),交叉验证法以及基于信息论的方法等。
一种简单而常用的
k
k
k值经验估计方法认为,对于具有
n
n
n个对象的数据集,其聚类的簇数
k
k
k取
n
2
\begin{aligned}\sqrt\frac{n}{2}\end{aligned}
2n 为宜。这时,在平均期望情况下每个簇大约有
2
n
\sqrt{2n}
2n 个对象。在此基础上,还有人提出了进一步附加限制,即簇数
k
<
n
k<\sqrt{n}
k<n。
比如,设
n
=
8
n=8
n=8,则簇数
k
=
2
k=2
k=2 为宜,且在平均情况下每个簇有4个点,而根据附加的经验公式
k
<
2.83
k<2.83
k<2.83。利用这两个关于簇数
k
k
k的经验公式,似乎也从一个侧面说明,例10-5中
k
=
2
k=2
k=2 是最恰当的簇数。
(二)外部质量评价
如果我们已经很好地通过估计得到了聚类的簇数
k
k
k,就可以使用一种或多种聚类方法, 比如,
k
k
k-平均算法,凝聚层次算法或者DBSCAN算法等对已知数据集进行聚类分析,并得到多种不同的聚类结果。现在的问题是哪-种方法的聚类结果更好一些,或者说,如何比较由不同方法产生的聚类结果,这就是聚类的质量评价。
目前,对聚类的质量评价已有许多方法可供选择,但一般可以分为两大类,即外部 (extrinsic) 质量评价和内部 (intrinsic) 质量评价。
外部质量评价假设数据集已经存在一种理想的聚类 (通常由专家构建),并将其作为常用的基准方法与某种算法的聚类结果进行比较,其比较评价主要有聚类熵和聚类精度两种常用方法。
1、聚类熵方法
假设数据集
S
=
{
X
1
,
X
2
,
…
,
X
n
}
S=\{X_1,X_2,…,X_n\}
S={X1,X2,…,Xn},且
T
=
{
T
1
,
T
2
,
…
,
T
m
}
T=\{T_1,T_2,…,T_m\}
T={T1,T2,…,Tm} 是由专家给出的理想标准聚类,而
C
=
{
C
1
,
C
2
,
…
,
C
k
}
C=\{C_1,C_2,…,C_k\}
C={C1,C2,…,Ck} 是由某个算法关于
S
S
S的一个聚类,则对于簇
C
i
C_i
Ci相对于基准聚类
T
T
T的聚类熵定义为
E
(
C
i
∣
T
)
=
−
∑
j
=
1
m
∣
C
i
∩
T
j
∣
∣
C
i
∣
log
2
∣
C
i
∩
T
j
∣
∣
C
i
∣
(10-20)
E(C_i|T)=-\sum_{j=1}^m\frac{|C_i\cap T_j|}{|C_i|}\log_2\frac{|C_i\cap T_j|}{|C_i|}\tag{10-20}
E(Ci∣T)=−j=1∑m∣Ci∣∣Ci∩Tj∣log2∣Ci∣∣Ci∩Tj∣(10-20) 而
C
C
C关于基准
T
T
T的整体聚类熵定义为所有簇
C
i
C_i
Ci关于基准
T
T
T的聚类熵的加权平均值,即
E
(
C
)
=
1
∑
i
=
1
k
∣
C
i
∣
∑
i
=
1
k
∣
C
i
∣
×
E
(
C
i
∣
T
)
(10-21)
E(C)=\frac{1}{\mathop{\sum}\limits_{i=1}^k|C_i|}\sum_{i=1}^k|C_i|\times E(C_i|T)\tag{10-21}
E(C)=i=1∑k∣Ci∣1i=1∑k∣Ci∣×E(Ci∣T)(10-21) 聚类熵方法认为,
E
(
C
)
E(C)
E(C) 值越小,其
C
C
C相对于基准
T
T
T的聚类质量就越高。
值得注意的是,公式 (10-21) 的右端第1项的分母
∑
i
=
1
k
∣
C
i
∣
\begin{aligned}\sum_{i=1}^k|C_i|\end{aligned}
i=1∑k∣Ci∣ 是每个簇中元素个数之和,且不能用
n
n
n去替换。因为,只有当
C
C
C是一个划分聚类时,分母才为
n
n
n,而一般的聚类方法,比如DBSCAN的聚类,其分母可能小于
n
n
n。
2、聚类精度
聚类精度 (precision) 评价的基本思想是使用簇中数目最多的类别作为该簇的类别标记,即对于簇
C
i
C_i
Ci,如果存在
T
j
T_j
Tj使
∣
C
i
∩
T
j
∣
=
max
{
∣
C
i
∩
T
1
∣
,
∣
C
i
∩
T
2
∣
,
⋯
,
∣
C
i
∩
T
m
∣
}
|C_i\cap T_j|=\max\{|C_i\cap T_1|,|C_i\cap T_2|,\cdots,|C_i\cap T_m|\}
∣Ci∩Tj∣=max{∣Ci∩T1∣,∣Ci∩T2∣,⋯,∣Ci∩Tm∣},则认为
C
i
C_i
Ci的类别为
T
j
T_j
Tj。因此,簇
C
i
C_i
Ci关于基准
T
T
T的精度定义为
J
(
C
i
∣
T
)
=
max
{
∣
C
i
∩
T
1
∣
,
∣
C
i
∩
T
2
∣
,
⋯
,
∣
C
i
∩
T
m
∣
}
∣
C
i
∣
(10-22)
J(C_i|T)=\frac{\max\{|C_i\cap T_1|,|C_i\cap T_2|,\cdots,|C_i\cap T_m|\}}{|C_i|}\tag{10-22}
J(Ci∣T)=∣Ci∣max{∣Ci∩T1∣,∣Ci∩T2∣,⋯,∣Ci∩Tm∣}(10-22) 而
C
C
C关于基准
T
T
T的整体精度定义为所有簇
C
i
C_i
Ci关于基准
T
T
T的聚类精度的加权平均值,即
J
(
C
)
=
1
∑
i
=
1
k
∣
C
i
∣
∑
i
=
1
k
∣
C
i
∣
×
J
(
C
i
∣
T
)
(10-23)
J(C)=\frac{1}{\mathop{\sum}\limits_{i=1}^k|C_i|}\sum_{i=1}^k|C_i|\times J(C_i|T)\tag{10-23}
J(C)=i=1∑k∣Ci∣1i=1∑k∣Ci∣×J(Ci∣T)(10-23) 聚类精度方法认为,
J
(
C
)
J(C)
J(C) 值越大,其聚类
C
C
C相对于基准
T
T
T的聚类质量就越高。
此外,一般将
1
−
J
(
C
)
1-J(C)
1−J(C) 称为
C
C
C关于基准
T
T
T的整体错误率。因此,聚类精度
J
(
C
)
J(C)
J(C) 大或整体错误率
1
−
J
(
C
)
1-J(C)
1−J(C) 小,都说明聚类算法将不同类别的对象较好地聚集到了不同的簇中,即聚类准确性高。
(三)内部质量评价
内部质量评价没有已知的外在基准,仅仅利用数据集
S
S
S和聚类
C
C
C的固有特征和量值来评价一个聚类
C
C
C的质量。即一般通过计算簇内平均相似度、簇间平均相似度或整体相似度来评价聚类效果。
内部质量评价与聚类算法有关,聚类的有效性指标主要用来评价聚类效果的优劣或判断簇的最优个数,理想的聚类效果是具有最小的簇内距离和最大的簇间距离,因此,聚类有效性一般都通过簇内距离和簇间距离的某种形式的比值来度量。这类指标常用有CH指标、Dunn指标、I指标、Xie-eni指标等。
1、CH指标
CH指标是Calinski-Harabasz指标的简写,它先计算每个簇的各点与其簇中心的距离平方和来度量类内的紧密度;再计算各个簇中心点与数据集中心点距离平方和来度量数据集的分离度,而分离度与紧密度的比值就是CH指标。
设
X
‾
i
\overline{X}_i
Xi表示簇
C
C
C的中心点 (均值),
X
‾
\overline{X}
X表示数据集
S
S
S的中心点,
d
(
X
‾
i
,
X
‾
)
d(\overline{X}_i,\overline{X})
d(Xi,X) 为
X
‾
i
\overline{X}_i
Xi到
X
‾
\overline{X}
X的某种距离函数,则聚类
C
C
C中簇的紧密度定义为
Trace
(
A
)
=
∑
i
=
1
k
∑
X
j
∈
C
i
d
(
X
j
,
X
‾
i
)
2
(10-24)
\text{Trace}(A)=\sum_{i=1}^k\sum_{X_j\in C_i}d(X_j,\overline{X}_i)^2\tag{10-24}
Trace(A)=i=1∑kXj∈Ci∑d(Xj,Xi)2(10-24) 因此,Trace(A)是聚类
C
C
C的簇内中心距离平方和之和。而聚类
C
C
C的分离度定义为
Trace
(
B
)
=
∑
i
=
1
k
∣
C
i
∣
d
(
X
‾
i
,
X
‾
)
2
(10-25)
\text{Trace}(B)=\sum_{i=1}^k|C_i|d(\overline{X}_i,\overline{X})^2\tag{10-25}
Trace(B)=i=1∑k∣Ci∣d(Xi,X)2(10-25) 即Trace(B)是聚类
C
C
C的每个簇中心点到
S
S
S的中心点距离平方的加权和。
由此,若令
N
=
∑
i
=
1
k
∣
C
i
∣
\begin{aligned}N=\sum_{i=1}^k|C_i|\end{aligned}
N=i=1∑k∣Ci∣ 则CH指标可定义为
V
CH
(
k
)
=
Trace
(
B
)
/
(
k
−
1
)
Trace
(
A
)
/
(
N
−
k
)
(10-26)
V_{\text{CH}}(k)=\frac{\text{Trace}(B)/(k-1)}{\text{Trace}(A)/(N-k)}\tag{10-26}
VCH(k)=Trace(A)/(N−k)Trace(B)/(k−1)(10-26) 公式 (10-26) 一般在以下两种情况下使用:
(1)评价两个算法所得聚类哪个更好。
假设用两个算法对数据集
S
S
S进行聚类分析,分别得到两个不同的聚类 (都包含
k
k
k个簇), 则CH值大者对应的聚类更好,因为CH值越大意味着聚类中的每个簇自身越紧密,且簇与簇之间更分散。
(2)评价同一算法所得两个簇数不同的聚类哪个更好。
假设某个算法对于数据集
S
S
S进行聚类分析,分别得到簇数为
k
1
k_1
k1和
b
2
b_2
b2的两个聚类,则CH值大的聚类结果更好,同时说明该聚类对应的簇数更恰当。因此,反复应用公式 (10-26) 还可以求得一个数据集
S
S
S聚类的最佳簇数。
2、Dunn指标
Dunn指标使用簇
C
i
C_i
Ci与簇
C
j
C_j
Cj之间的最小距离
d
s
(
C
i
,
C
j
)
d_s(C_i,C_j)
ds(Ci,Cj) 来计算簇间分离度,同时使用所有簇中最大的簇直径
max
{
Φ
(
C
1
)
,
Φ
(
C
2
)
,
.
.
.
,
Φ
(
C
k
)
}
\max\{\varPhi(C_1), \varPhi(C_2),...,\varPhi(C_k)\}
max{Φ(C1),Φ(C2),...,Φ(Ck)} 来刻画簇内的紧密度,则Dunn指标就是前者与后者比值的最小值,即
V
D
(
k
)
=
min
i
≠
j
d
s
(
C
i
,
C
j
)
max
{
Φ
(
C
1
)
,
Φ
(
C
2
)
,
.
.
.
,
Φ
(
C
k
)
}
(10-27)
V_D(k)=\min_{i≠j}\frac{d_s(C_i,C_j)}{\max\{\varPhi(C_1), \varPhi(C_2),...,\varPhi(C_k)\}}\tag{10-27}
VD(k)=i=jminmax{Φ(C1),Φ(C2),...,Φ(Ck)}ds(Ci,Cj)(10-27) Dunn值越大,则簇与簇之间的间隔越远,对应的聚类就越好。类似CH评价指标,Dunn指标既可以用于评价不同算法所得聚类的优劣,也可用于评价同一算法所得簇数不同的聚类哪个更好,即可以用于寻求
S
S
S的最佳簇数。
六、离群点挖掘
离群点 (Outlier) 是数据集中明显偏离大部分数据的特殊数据。前面介绍的分类、聚类等数据挖掘算法,其重点是发现适用于大部分数据的常规模式,因此,许多数据挖掘算法都试图降低或消除离群数据的影响,并在实施挖掘时将离群点作为噪音而剔除或忽略掉,但在许多实际应用场合,人们怀疑离群点的偏离并非由随机因素产生,而可能是由其他完全不同的机制产生,需要将其挖掘出来特别分析利用。比如,在安全管理、风险控制等应用领域,识别离群点的模式比正常数据的模式显得更有应用价值。
(一)相关问题概述
Outlier一词通常翻译为离群点,也翻译为异常。但在不同的应用场合还有许多别名,如孤立点、异常点、新颖点、偏离点、例外点、噪音、异常数据等。离群点挖掘在中文文献中又有异常数据挖掘、异常数据检测、离群数据挖掘、例外数据挖掘和稀有事件挖掘等类似术语。
1、离群点的产生
(1)数据来源于欺诈、入侵、疾病爆发、不寻常的实验结果等引起的异常。比如,某人话费平均200元左右,某月突然增加到数千元;某人的信用卡通常每月消费5000元左右,而某个月消费超过3万等。这类离群点在数据挖掘中通常都是相对有趣的,应用的重点之一。
(2)数据变量固有变化引起,反映了数据分布的自然特征,如气候变化、顾客新的购买模式、基因突变等。也是有趣的重点领域之一。
(3)数据测量和收集误差,主要是由于人为错误、测量设备故障或存在噪音。例如,一个学生某门课程的成绩为—100,可能是由于程序设置默认值引起的;一个公司的高层管理人员的工资明显高于普通员工的工资看上去像是一个离群点,但却是合理的数据。
2、离群点挖掘问题
通常,离群点挖掘问题可分解成3个子问题来描述。
(1)定义离群点
由于离群点与实际问题密切相关,明确定义什么样的数据是离群点或异常数据,是离群点挖掘的前提和首要任务,一般需要结合领域专家的经验知识,才能对离群点给出恰当的描述或定义。
(2)挖掘离群点
离群点被明确定义之后,用什么算法有效地识别或挖掘出所定义的离群点则是离群点挖掘的关键任务。离群点挖掘算法通常从数据能够体现的规律角度为用户提供可疑的离群点数据,以便引起用户的注意。
(3)理解离群点
对挖掘结果的合理解释、理解并指导实际应用是离群点挖掘的目标。由于离群点产生的机制是不确定的,离群点挖掘算法检测出来的“离群点”是否真正对应实际的异常行为,不可能由离群点挖掘算法来说明和解释,而只能由行业或领域专家来理解和解释说明。
3、离群点的相对性
离群点是数据集中明显偏离大部分数据的特殊数据,但 “明显”以及“大部分”都是相对的,即离群点虽与众不同,但却具有相对性。因此,在定义和挖掘离群点时需要考虑一下几个问题。
(1)全局或局部的离群点
一个数据对象相对于它的局部近邻对象可能是离群的,但相对于整个数据集却不是离群的。如身高1.9米的同学在我校数学专业1班就是一个离群点,但在包括姚明等职业球员在内的全国人民中就不是了。
(2)离群点的数量
离群点的数量虽是未知的,但正常点的数量应该远远超过离群点的数量,即离群点的数量在大数据集中所占的比例应该是较低的,一般认为离群点数应该低于5%甚至低于1%。
(3)点的离群因子
不能用“是”与“否”来报告对象是否为离群点,而应以对象的偏离程度,即离群因子 (Outlier Factor) 或离群值得分 (Outlier Score) 来刻画一个数据偏离群体的程度,然后将离群因子高于某个阈值的对象过滤出来,提供给决策者或领域专家理解和解释,并在实际工作中应用。
(二)基于距离的方法
1、基本概念
定义10-11 设有正整数
k
k
k,对象
X
X
X的
k
k
k-最近邻距离是满足以下条件的正整数
d
k
(
X
)
d_k(X)
dk(X):
(1)除
X
X
X以外,至少有
k
k
k个对象
Y
Y
Y满足
d
(
X
,
Y
)
≤
d
k
(
X
)
d(X,Y)≤d_k(X)
d(X,Y)≤dk(X)。
(2)除
X
X
X以外,至多有
k
−
1
k-1
k−1 个对象
Y
Y
Y满足
d
(
X
,
Y
)
<
d
k
(
X
)
d(X,Y)<d_k(X)
d(X,Y)<dk(X)。
其中
d
(
X
,
Y
)
d(X,Y)
d(X,Y) 是对象
X
X
X与
Y
Y
Y之间的某种距离函数。
一个对象的 k k k-最近邻的距离越大,越可能远离大部分数据对象,因此可以将对象 X X X的 k k k-最近邻距离 d k ( X ) d_k(X) dk(X) 当作它的离群因子。
定义10-12 令 D ( X , k ) = { Y ∣ d ( X , Y ) ≤ d k ( X ) ∧ Y ≠ X } D(X,k)=\{Y|d(X,Y)≤d_k(X)\wedge Y≠X\} D(X,k)={Y∣d(X,Y)≤dk(X)∧Y=X},则称 D ( X , k ) D(X,k) D(X,k) 是 X X X的 k k k-最近邻域 (Domain)。
从定义10-12可知, D ( X , k ) D(X,k) D(X,k) 是以 X X X为中心,距离 X X X不超过 d k ( X ) d_k(X) dk(X) 的对象 Y Y Y所构成的集合。值得特别注意的是, X X X不属于它的 k k k-最近邻域,即 X ∉ D ( X , k ) X\notin D(X,k) X∈/D(X,k)。特别地, X X X的 k k k-最近邻域 D ( X , k ) D(X,k) D(X,k) 包含的对象个数可能远远超过 k k k,即 ∣ D ( X , k ) ∣ ≥ k |D(X,k)|≥k ∣D(X,k)∣≥k。
定义10-13 设有正整数
k
k
k,对象
X
X
X的
k
k
k-最近邻离群因子定义为
OF
1
(
X
,
k
)
=
∑
Y
∈
D
(
X
,
k
)
d
(
X
,
Y
)
∣
D
(
X
,
k
)
∣
(10-28)
\text{OF}_1(X,k)=\frac{\mathop{\sum}\limits_{Y\in D(X,k)}d(X,Y)}{|D(X,k)|}\tag{10-28}
OF1(X,k)=∣D(X,k)∣Y∈D(X,k)∑d(X,Y)(10-28)
2、算法描述
对于给定的数据集和最近邻距离的个数 k k k,我们可利用以上公式计算每个数据对象的 k k k-最近邻离群因子,并将其从大到小排序输出,其中离群因子较大的若干对象最有可能是离群点,一般要由决策者或行业领域专家进行分析判断,它们中的哪些点真的是离群点。
算法10-8 基于距离的离群点检测算法
输入:数据集 S S S、最近邻距离的个数 k k k
输出:疑似离群点及对应的离群因子降序排列表
(1)REPEAT
(2)取 S S S中一个未被处理的对象 X X X
(3)确定 X X X的 k k k-最近邻域 D ( X , k ) D(X,k) D(X,k)
(4)计算 X X X的 k k k-最近邻离群因子 OF 1 ( X , k ) \text{OF}_1(X,k) OF1(X,k)
(5)UNTIL S S S中每个点都已经处理
(6)对 OF 1 ( X , k ) \text{OF}_1(X,k) OF1(X,k)降序排列,并输出 ( X , OF 1 ( X , k ) ) (X,\text{OF}_1(X,k)) (X,OF1(X,k))
3、计算实例
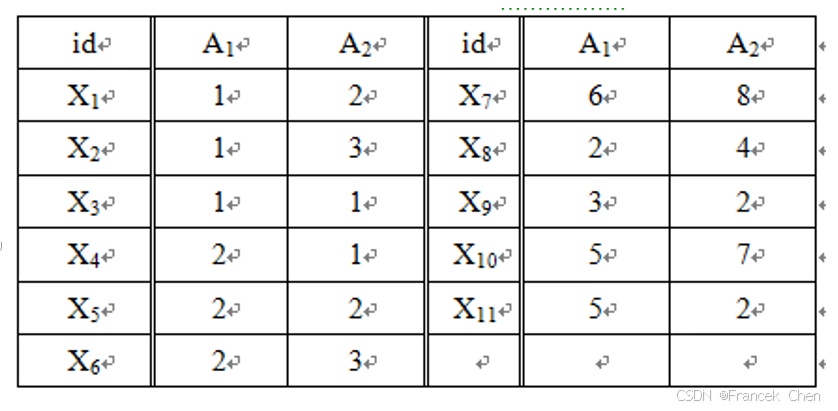
例10-12 设有11个点的二维数据集 S S S由表10-10给出,令 k = 2 k=2 k=2,试用欧几里得距离平方计算 X 7 , X 10 , X 11 X_7, X_{10},X_{11} X7,X10,X11 到其它所有点的离群因子。
解:为了直观地理解算法原理,将
S
S
S中的数据对象展示在下图 (10-27) 的平面上。
下面分别计算指定的点和其它点的离群因子。
(1)计算对象
X
7
X_7
X7的离群因子
从图可以看出,距离
X
7
=
(
6
,
8
)
X_7=(6,8)
X7=(6,8) 最近的一个点为
X
10
=
(
5
,
7
)
X_{10}=(5,7)
X10=(5,7),且
d
(
X
7
,
X
10
)
=
1.41
d(X_7,X_{10}) =1.41
d(X7,X10)=1.41,其它最近的点可能是
X
11
=
(
5
,
2
)
X_{11}=(5,2)
X11=(5,2),
X
9
=
(
3
,
2
)
X_9=(3,2)
X9=(3,2),
X
8
=
(
2
,
4
)
X_8=(2,4)
X8=(2,4);
经计算得
d
(
X
7
,
X
11
)
=
6.08
d(X_7,X_{11})=6.08
d(X7,X11)=6.08,
d
(
X
7
,
X
9
)
=
6.71
d(X_7,X_9)=6.71
d(X7,X9)=6.71,
d
(
X
7
,
X
8
)
=
5.66
d(X_7,X_8)=5.66
d(X7,X8)=5.66
因为
k
=
2
k=2
k=2,所以
d
2
(
X
7
)
=
5.66
d_2(X_7)=5.66
d2(X7)=5.66,故根据定义10-11得
D
(
X
7
,
2
)
=
{
X
10
,
X
8
}
D(X_7,2)=\{X_{10},X_8\}
D(X7,2)={X10,X8}
按照公式 (10-28),
X
7
X_7
X7的离群因子
OF
1
(
X
7
,
2
)
=
∑
Y
∈
N
(
X
7
,
2
)
d
(
X
7
,
Y
)
∣
N
(
X
7
,
k
)
∣
=
d
(
X
7
,
X
10
)
+
d
(
X
7
,
X
8
)
2
=
1.41
+
5.66
2
=
3.54
\begin{aligned} \text{OF}_1(X_7,2)&=\frac{\mathop{\sum}\limits_{Y\in N(X_7,2)}d(X_7,Y)}{|N(X_7,k)|}=\frac{d(X_7,X_{10})+d(X_7,X_8)}{2}\\[3ex] &=\frac{1.41+5.66}{2}=3.54 \end{aligned}
OF1(X7,2)=∣N(X7,k)∣Y∈N(X7,2)∑d(X7,Y)=2d(X7,X10)+d(X7,X8)=21.41+5.66=3.54(2)计算对象
X
10
X_{10}
X10的离群因子
OF
1
(
X
10
,
2
)
=
2.83
\text{OF}_1(X_{10},2)=2.83
OF1(X10,2)=2.83
(3)计算对象 X 11 X_{11} X11的离群因子 OF 1 ( X 11 , 2 ) = 2.5 \text{OF}_1(X_{11},2)=2.5 OF1(X11,2)=2.5
(4)计算对象 X 5 X_{5} X5的离群因子 OF 1 ( X 5 , 2 ) = 1 \text{OF}_1(X_{5},2)=1 OF1(X5,2)=1
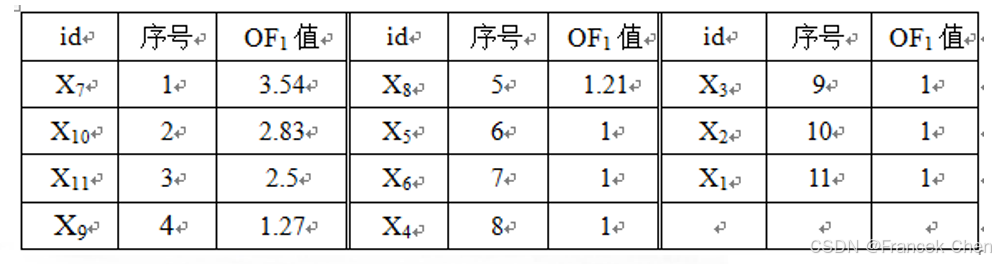
类似地,可以计算得到其余对象的离群因子,见下表 (10-11)。
4、离群因子阈值
按照
k
k
k-最近邻的理论,离群因子越大,越有可能是离群点,因此,必须指定一个阈值来区分离群点和正常点。最简单的方法就是指定离群点个数,但这种方法过于简单,有时会漏掉一些真实的离群点或者把过多的正常点也归于可能的离群点,给领域专家或决策者对离群点的理解和解释带来困难。
(1)离群因子分割阈值法首先将离群因子降序排列,同时把数据对象按照离群因子重新编升序号。
(2)以离群因子
OF
1
(
X
,
k
)
\text{OF}_1(X,k)
OF1(X,k) 为纵坐标,以离群因子顺序号为横坐标,即以 (序号,
OF
1
\text{OF}_1
OF1值) 为点在平面上标出,并连接形成一条非增的折线,并从中找到折线急剧下降与平缓下降交叉的点对应离群因子作为阈值,离群因子小于等于这个阈值的对象为正常对象,其它就是可能的离群点。
例10-13 对例10-12的数据集 S S S,其离群因子按降序排列与序号汇总在表10-11中。试根据离群因子分割阈值法找到离群点的阈值。
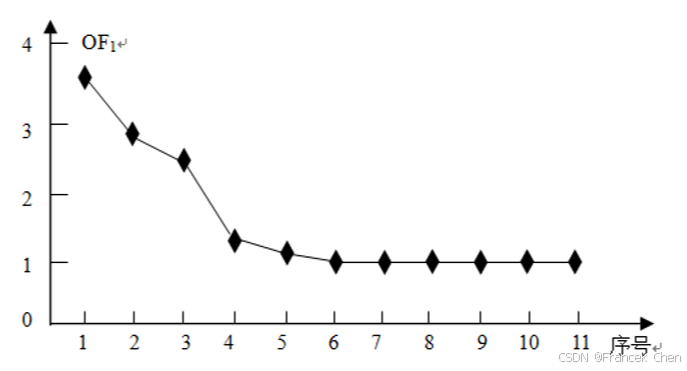
解:首先以表10-11的 (序号, OF 1 \text{OF}_1 OF1值) 作为平面上的点,在平面上标出并用折线连接。如下图10-28。
然后观察图10-28可以发现,第4个点,即 (4, 1.27) 左边的折线下降非常陡,而右端的折线则下降非常平缓,因此,选择离群因子1.27作为阈值。由于
X
7
、
X
10
X_7、X_{10}
X7、X10 和
X
11
X_{11}
X11 的离群因子分别是3.54,2.83和2.5,它们都大于1.27,因此,这3个点最有可能是离群点,而其余点就是普通点。
再观察图10-27可以发现,
X
7
、
X
10
X_7、X_{10}
X7、X10 和
X
11
X_{11}
X11 的确远离左边密集的多数对象,因此,将它们当作数据集
S
S
S的离群点是合理的。
5、算法评价
基于距离的离群点检测方法最大的优点是原理简单且使用方便,其不足点主要体现在以下几个方面。
(1)参数
k
k
k的选择缺乏简单有效的方法来确定,检测结果对参数
k
k
k敏感性程度也没有大家一致接受的分析结果。
(2)时间复杂性为
O
(
∣
S
∣
2
)
O(|S|^2)
O(∣S∣2),对于大规模数据集缺乏伸缩性。
(3)由于使用全局离群因子阈值,在具有不同密度区域的数据集中挖掘离群点困难。
(三)基于相对密度的方法
距离的方法一种全局离群点检查方法,但不能处理不同密度区域的数据集,即无法检测出局部密度区域内的离群点,而实际应用中数据并非都是单一密度分布的。当数据集含有多种密度分布或由不同密度子集混合而成时,类似距离这种全局离群点检测方法通常效果不佳,因为一个对象是否为离群点不仅取决于它与周围数据的距离大小,而且与邻域内的密度状况有关。
1、相对密度的概念
从密度邻域的角度看,离群点是在低密度区域中的对象,因此,需要引进对象的局部邻域密度及相对密度的概念。
定义10-14 (1)一个对象
X
X
X的
k
k
k-最近邻局部密度 (density) 定义为
dsty
(
X
,
k
)
=
∣
D
(
X
,
k
)
∣
∑
Y
∈
D
(
X
,
k
)
d
(
X
,
Y
)
(10-29)
\text{dsty}(X,k)=\frac{|D(X,k)|}{\mathop{\sum}\limits_{Y\in D(X,k)}d(X,Y)}\tag{10-29}
dsty(X,k)=Y∈D(X,k)∑d(X,Y)∣D(X,k)∣(10-29) (2)一个对象
X
X
X的
k
k
k-最近邻局部相对密度 (relative density)
rdsty
(
X
,
k
)
=
∑
Y
∈
D
(
X
,
k
)
dsty
(
X
,
k
)
/
∣
D
(
X
,
k
)
∣
dsty
(
X
,
k
)
(10-30)
\text{rdsty}(X,k)=\frac{\mathop{\sum}\limits_{Y\in D(X,k)}\text{dsty}(X,k)/|D(X,k)|}{\text{dsty}(X,k)}\tag{10-30}
rdsty(X,k)=dsty(X,k)Y∈D(X,k)∑dsty(X,k)/∣D(X,k)∣(10-30) 其中
D
(
X
,
k
)
D(X,k)
D(X,k) 就是对象
X
X
X的
k
k
k-最近邻域 (定义10-12给出),
∣
D
(
X
,
k
)
∣
|D(X,k)|
∣D(X,k)∣ 是该集合的对象个数。
2、算法描述
以
rdsty
(
X
,
k
)
\text{rdsty}(X,k)
rdsty(X,k) 作为离群因子
OF
2
(
X
,
k
)
\text{OF}_2(X,k)
OF2(X,k),其计算分两步
(1)根据近邻个数
k
k
k,计算每个对象
X
X
X的
k
k
k-最近邻局部密度
dsty
(
X
,
k
)
\text{dsty}(X,k)
dsty(X,k)
(2)计算
X
X
X的近邻平均密度以及
k
k
k-最近邻局部相对密度
rdsty
(
X
,
k
)
\text{rdsty}(X,k)
rdsty(X,k)
一个数据集由多个自然簇构成,在簇内靠近核心点的对象的相对密度接近于1,而处于簇的边缘或是簇的外面的对象的相对密度相对较大。因此,相对密度值越大就越可能是离群点。
算法10-9 基于相对密度的离群点检测算法
输入:数据集 S S S、最近邻个数 k k k
输出:疑似离群点及对应的离群因子降序排列表
(1)REPEAT
(2)取 S S S中一个未被处理的对象 X X X
(3)确定 X X X的 k k k-最近邻域 D ( X , k ) D(X,k) D(X,k)
(4)利用 D ( X , k ) D(X,k) D(X,k)计算 X X X的密度 dsty ( X , k ) \text{dsty}(X,k) dsty(X,k)
(5)UNTIL S S S中每个点都已经处理
(6)REPEAT
(7)取 S S S中第一个对象 X X X
(8)确定 X X X的相对密度 rdsty ( X , k ) \text{rdsty}(X,k) rdsty(X,k),并赋值给 OF 2 ( X , k ) \text{OF}_2(X,k) OF2(X,k)
(9)UNTIL S S S中所有对象都已经处理
(10)对 OF 2 ( X , k ) \text{OF}_2(X,k) OF2(X,k)降序排列,并输出 ( X , OF 2 ( X , k ) ) (X,\text{OF}_2(X,k)) (X,OF2(X,k))
例10-14 对于例10-12给出的二维数据集 S S S (详见表10-10),令 k = 2 k=2 k=2,试用欧几里得距离计算 X 7 , X 10 , X 11 X_7, X_{10},X_{11} X7,X10,X11 等对象基于相对密度的离群因子。
解:因为
k
=
2
k=2
k=2,所以我们需要所有对象的2-最近邻局部密度。
(1)找出表10-11中每个数据对象的2-最近邻域
D
(
X
i
,
2
)
D(X_i,2)
D(Xi,2)。
按照例10-12的相同计算方法可得
D
(
X
1
,
2
)
=
{
X
2
,
X
3
,
X
5
}
,
D
(
X
2
,
2
)
=
{
X
1
,
X
6
}
,
D
(
X
3
,
2
)
=
{
X
1
,
X
4
}
,
D
(
X
4
,
2
)
=
{
X
3
,
X
5
}
,
D
(
X
5
,
2
)
=
{
X
1
,
X
4
,
X
6
,
X
9
}
,
D
(
X
6
,
2
)
=
{
X
2
,
X
5
,
X
8
}
,
D
(
X
7
,
2
)
=
{
X
10
,
X
8
}
,
D
(
X
8
,
2
)
=
{
X
2
,
X
6
}
,
D
(
X
9
,
2
)
=
{
X
5
,
X
4
,
X
6
}
,
D
(
X
10
,
2
)
=
{
X
7
,
X
8
}
,
D
(
X
11
,
2
)
=
{
X
9
,
X
5
}
\begin{aligned} &D(X_1,2)=\{X_2,X_3,X_5\},D(X_2,2)=\{X_1,X_6\},\ \ \ \ \ \ \ \ \ \ \ \ \ \ D(X_3,2)=\{X_1,X_4\},\\ &D(X_4,2)=\{X_3,X_5\},\ \ \ \ \ \ \ D(X_5,2)=\{X_1,X_4,X_6,X_9\},D(X_6,2)=\{X_2,X_5,X_8\},\\ &D(X_7,2)=\{X_{10},X_8\},\ \ \ \ \ D(X_8,2)=\{X_2,X_6\},\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ D(X_9,2)=\{X_5,X_4,X_6\},\\ &D(X_{10},2)=\{X_7,X_8\},\ \ \ \ \ D(X_{11},2)=\{X_9,X_5\} \end{aligned}
D(X1,2)={X2,X3,X5},D(X2,2)={X1,X6}, D(X3,2)={X1,X4},D(X4,2)={X3,X5}, D(X5,2)={X1,X4,X6,X9},D(X6,2)={X2,X5,X8},D(X7,2)={X10,X8}, D(X8,2)={X2,X6}, D(X9,2)={X5,X4,X6},D(X10,2)={X7,X8}, D(X11,2)={X9,X5}
(2)计算每个数据对象的局部密度 dsty ( X i , 2 ) \text{dsty}(X_i,2) dsty(Xi,2):
① 计算
X
1
X_1
X1的密度
由于
D
(
X
1
,
2
)
=
{
X
2
,
X
3
,
X
5
}
D(X_1,2)=\{X_2,X_3,X_5\}
D(X1,2)={X2,X3,X5},因此经计算有
d
(
X
1
,
X
2
)
=
1
d(X_1,X_2)=1
d(X1,X2)=1,
d
(
X
1
,
X
3
)
=
1
d(X_1,X_3)=1
d(X1,X3)=1,
d
(
X
1
,
X
5
)
=
1
d(X_1,X_5)=1
d(X1,X5)=1;
根据公式 (10-29) 得:
dsty
(
X
1
,
2
)
=
∣
D
(
X
1
,
2
)
∣
∑
Y
∈
N
(
X
1
,
2
)
d
(
X
1
,
Y
)
=
∣
N
(
X
1
,
2
)
∣
d
(
X
1
,
X
2
)
+
d
(
X
1
,
X
3
)
+
d
(
X
1
,
X
5
)
=
3
1
+
1
+
1
=
1
\begin{aligned} \text{dsty}(X_1,2)&=\frac{|D(X_1,2)|}{\mathop{\sum}\limits_{Y\in N(X_1,2)}d(X_1,Y)}\\[3ex] &=\frac{|N(X_1,2)|}{d(X_1,X_2)+d(X_1,X_3)+d(X_1,X_5)}\\[3ex] &=\frac{3}{1+1+1}=1 \end{aligned}
dsty(X1,2)=Y∈N(X1,2)∑d(X1,Y)∣D(X1,2)∣=d(X1,X2)+d(X1,X3)+d(X1,X5)∣N(X1,2)∣=1+1+13=1
② 计算
X
2
X_2
X2的密度
由于
D
(
X
2
,
2
)
=
{
X
1
,
X
6
}
D(X_2,2)=\{X_1,X_6\}
D(X2,2)={X1,X6},因此经计算的
d
(
X
2
,
X
1
)
=
1
d(X_2,X_1) =1
d(X2,X1)=1,
d
(
X
2
,
X
6
)
=
1
d(X_2,X_6) =1
d(X2,X6)=1;
根据公式 (10-29) 得:
dsty
(
X
2
,
2
)
=
∣
D
(
X
2
,
2
)
∣
∑
Y
∈
N
(
X
2
,
2
)
d
(
X
2
,
Y
)
=
2
1
+
1
=
1
\begin{aligned} \text{dsty}(X_2,2)&=\frac{|D(X_2,2)|}{\mathop{\sum}\limits_{Y\in N(X_2,2)}d(X_2,Y)}=\frac{2}{1+1}=1 \end{aligned}
dsty(X2,2)=Y∈N(X2,2)∑d(X2,Y)∣D(X2,2)∣=1+12=1
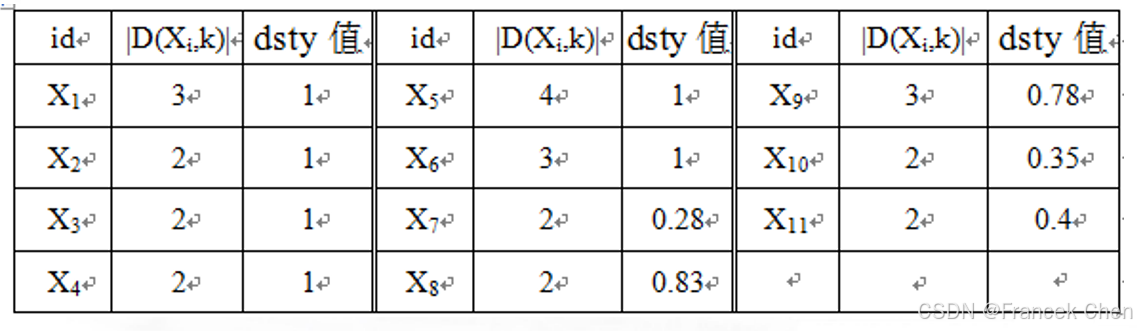
类似可计算其他数据对象的局部密度,见下表10-12。
(3)计算每个对象
X
i
X_i
Xi的相对密度
rdsty
(
X
i
,
2
)
\text{rdsty}(X_i, 2)
rdsty(Xi,2),并将其作为离群因子
OF
2
\text{OF}_2
OF2。
① 计算
X
1
X_1
X1的相对密度
利用表10-12中每个对象的密度值,根据相对密度公式 (10-30) 有:
rdsty
(
X
1
,
2
)
=
∑
Y
∈
N
(
X
1
,
2
)
dsty
(
Y
,
2
)
/
∣
N
(
X
1
,
2
)
∣
dsty
(
X
1
,
2
)
=
(
1
+
1
+
1
)
/
3
1
=
1
=
OF
2
(
X
1
,
2
)
\begin{aligned} \text{rdsty}(X_1,2)&=\frac{\mathop{\sum}\limits_{Y\in N(X_1,2)}\text{dsty}(Y,2)/|N(X_1,2)|}{\text{dsty}(X_1,2)}\\[3ex] &=\frac{(1+1+1)/3}{1}=1=\text{OF}_2(X_1,2) \end{aligned}
rdsty(X1,2)=dsty(X1,2)Y∈N(X1,2)∑dsty(Y,2)/∣N(X1,2)∣=1(1+1+1)/3=1=OF2(X1,2)
② 类似计算可得
X
2
、
X
3
、
…
、
X
11
X_2、X_3、…、X_{11}
X2、X3、…、X11 的相对密度值。
比如
X
5
X_5
X5的相对密度:
rdsty
(
X
5
,
2
)
=
∑
Y
∈
N
(
X
5
,
2
)
dsty
(
Y
,
2
)
/
∣
N
(
X
5
,
2
)
∣
dsty
(
X
5
,
2
)
=
(
1
+
1
+
1
+
0.79
)
/
4
1
=
0.95
=
OF
2
(
X
5
,
2
)
\begin{aligned} \text{rdsty}(X_5,2)&=\frac{\mathop{\sum}\limits_{Y\in N(X_5,2)}\text{dsty}(Y,2)/|N(X_5,2)|}{\text{dsty}(X_5,2)}\\[3ex] &=\frac{(1+1+1+0.79)/4}{1}=0.95=\text{OF}_2(X_5,2) \end{aligned}
rdsty(X5,2)=dsty(X5,2)Y∈N(X5,2)∑dsty(Y,2)/∣N(X5,2)∣=1(1+1+1+0.79)/4=0.95=OF2(X5,2) 结果汇总于下表10-13。
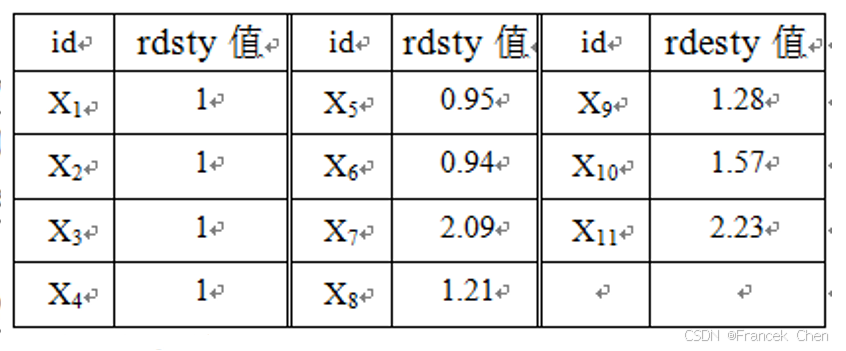
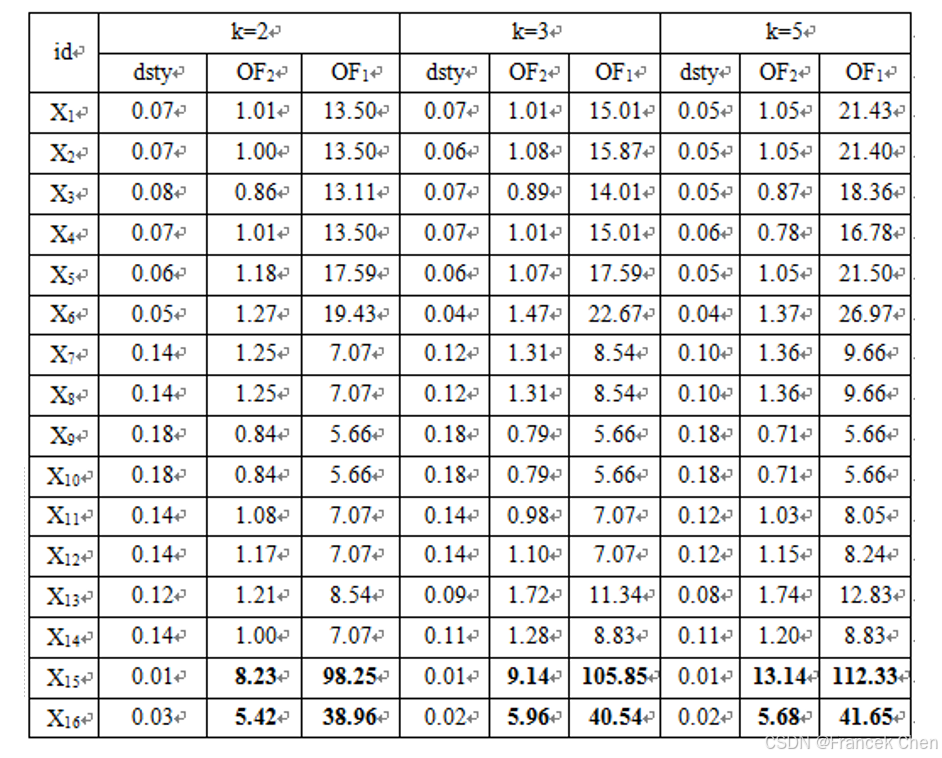
例10-15 设有表10-14所示的数据集,请采用欧式距离对
k
=
2
,
3
,
5
k=2,3,5
k=2,3,5,计算每个点的
k
k
k-最近邻局部密度,
k
k
k-最近邻局部相对密度 (离群因子
OF
2
\text{OF}_2
OF2) 以及基于
k
k
k-最近邻距离的离群因子
OF
1
\text{OF}_1
OF1。
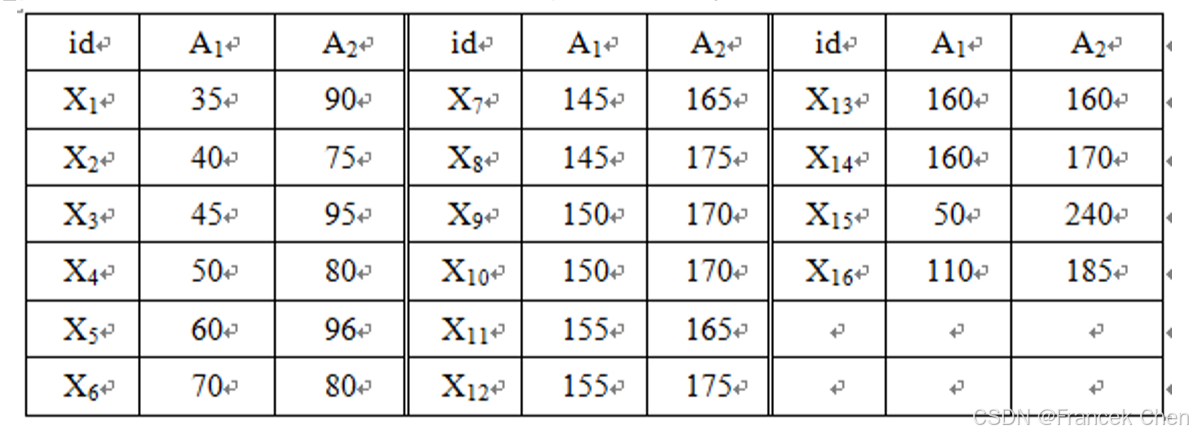
解:(1)为了便于理解,可将
S
S
S的点的相对位置在二维平面标出 (图10-30)。
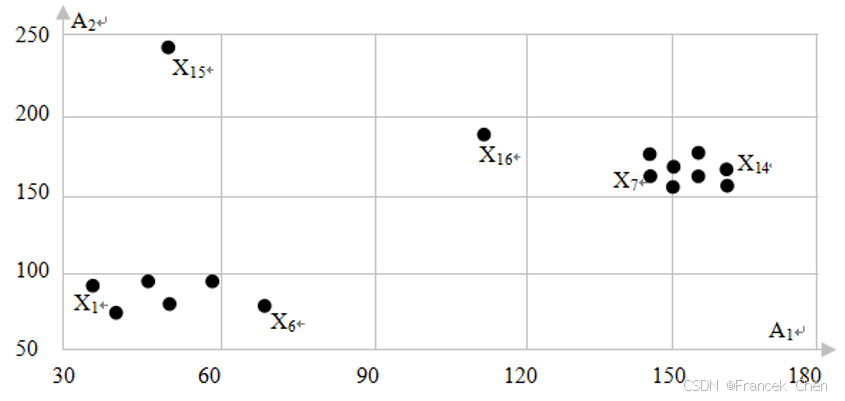
(2)分别利用基于距离和相对密度的算法10-8和10-9。分别计算每个对象的
k
k
k-最近邻局部密度
dsty
\text{dsty}
dsty、
k
k
k-最近邻局部相对密度 (离群因子
OF
2
\text{OF}_2
OF2) 以及基于
k
k
k-最近邻距离的离群因子
OF
1
\text{OF}_1
OF1,其结果汇总于表10-15。
(3)简单分析
① 从图10-30可以看出,
X
15
X_{15}
X15和
X
16
X_{16}
X16是
S
S
S中两个明显的离群点,基于距离和相对密度的方法都能较好的将其挖掘出来;
② 从这个例子来看,两种算法对
k
k
k的没有预想的那么敏感,也许是离群点
X
15
X_{15}
X15和
X
16
X_{16}
X16与其它对象分离十分明显的缘故。
③从表10-15看出,不管
k
k
k取2、3或5,
X
1
X_1
X1所在区域的
dsty
\text{dsty}
dsty 值都明显低于
X
7
X_7
X7所在区域的
dsty
\text{dsty}
dsty 值,这与图10-30显示的区域密度一致。但两个区域的相对密度值
OF
2
\text{OF}_2
OF2 却几乎没有明显的差别了。这是相对密度的性质决定的,即对于均匀分布的数据点,其核心点相对密度都是1,而不管点之间的距离是多少。
七、其它聚类方法
1、改进的聚类算法
(1)
k
k
k-模 (
k
k
k-modes) 算法是针对
k
k
k-平均算法仅适合数值属性的限制,实现对离散数据快速聚类而提出的。由于
k
k
k-模算法采用简单0-1匹配方法来计算同一离散属性下两个属性值之间的距离,弱化了序数属性取值之间的差异性,即不能充分反映同一序数属性下两个属性值之间的真实距离,还有改进和完善的空间。
(2)
k
k
k-prototype (
k
k
k-原型) 算法结合了
k
k
k-平均算法与
k
k
k-模算法的优点,可以对具有离散和数值两类属性 (称为混合属性) 的数据集进行聚类。它对离散属性采用
k
k
k-模算法计算对象
X
X
X与
Y
Y
Y之间的距离
d
1
(
X
,
Y
)
d_1(X,Y)
d1(X,Y),对数值属性采用
k
k
k-平均算法中的方法计算对象之间的距离
d
2
(
X
,
Y
)
d_2(X,Y)
d2(X,Y),最后用加权方法,即
α
d
1
(
X
,
Y
)
+
(
1
−
α
)
d
2
(
X
,
Y
)
\alpha d_1(X,Y)+(1-\alpha)d_2(X,Y)
αd1(X,Y)+(1−α)d2(X,Y) 作为数据集中对象
X
X
X与
Y
Y
Y之间的距离
d
(
X
,
Y
)
d(X,Y)
d(X,Y),其中
α
∈
[
0
,
1
]
\alpha\in[0,1]
α∈[0,1] 是权重系数,通常可取
α
=
0.5
\alpha=0.5
α=0.5。
(3)BIRCH算法 (Balanced Iterative Reducing and Clustering Using Hierarchies) 是一个综合的层次聚类方法。它用聚类特征 (Clustering Features,CF) 和聚类特征树 (CF Tree,类似于B-树) 来概括描述聚类的簇
C
i
C_i
Ci,其中
CF
i
=
(
n
i
,
LS
i
,
SS
i
)
\text{CF}_i=(ni, \text{LS}_i,\text{SS}_i)
CFi=(ni,LSi,SSi) 是一个三元组,
n
i
n_i
ni是簇中对象的个数,
LS
i
\text{LS}_i
LSi是
n
i
n_i
ni个对象分量的线性和,
SS
i
\text{SS}_i
SSi是
n
i
n_i
ni个对象分量的平方和。
(4)CURE (Clustering Using Representatives) 算法是对
k
k
k-平均算法的另一种改进。很多聚类算法只擅长聚类球形的簇,而有些聚类算法对孤立点又比较敏感。CURE算法为了解决上述两方面的问题,改变了
k
k
k-平均算法用簇中心和
k
k
k-中心点算法用单个具体对象代表一个簇的传统方法,而是选用簇中多个代表对象来表示一个簇,使其可以适应非球形簇的聚类,并降低了噪声对聚类的影响。
(5)ROCK (RObust Clustering using linK) 算法,就是针对二元或分类属性数据集而提出的一个聚类算法。
(6)OPTICS (Ordering Points To Identify the Clustering Structure) 算法,是为降低DBSCAN算法对密度
(
ε
,
MinPts
)
(\varepsilon,\text{MinPts})
(ε,MinPts) 参数的敏感性而提出的。它并不显示的产生结果聚类,而是为聚类分析生成一个增广的簇排序 (比如,以可达距离为纵轴,样本点输出次序为横轴的坐标图)。这个排序代表了各样本点基于密度的聚类结构。我们可以从这个排序中得到基于任何密度参数
(
ε
,
MinPts
)
(\varepsilon,\text{MinPts})
(ε,MinPts) 的DBSCAN算法的聚类结果。
2、其它聚类新方法
利用一些新的理论或技术来设计聚类新方法。
(1)基于网格的聚类方法
基于网格的方法把对象空间量化为有限数目的单元格,形成一个网格结构,而每一维上分割点的位置信息存储在数组中,分割线贯穿整个空间,所有的聚类操作都在这个网格结构(即量化空间)上进行。这种方法的主要优点是它的处理速度很快,其处理速度独立于数据对象的数目,只与量化空间中每一维的单元格数目有关,但其效率的提高是以降低聚类结果的精确性为代价的。由于网格聚类算法存在量化尺度的问题,因此,通常先从小单元开始寻找聚类,再逐渐增大单元的体积,重复这个过程,直到发现满意的聚类为止。
(2)基于模型的聚类方法
基于模型的方法为每一个簇假定一个模型,寻找数据对给定模型的最佳拟合。基于模型的方法通过建立反映样本空间分布的密度函数定位聚类,试图优化给定的数据和某些数据模型之间的适应性。
(3)基于模糊集的聚类方法
在实践中大多数对象究竟属于哪个簇并没有严格的归属值,它们的归属值和形态存在着中介性或不确定性,适合进行软划分。由于模糊聚类分析具有描述样本归属中介性的优点,能客观地反映现实世界,成为当今聚类分析研究中的热点之一。
模糊聚类算法是基于模糊数学理论的一种非监督学习方法,是一种不确定聚类方法。模糊聚类一经提出,就得到了学术界极大关注,模糊聚类是一个很大的聚类“家族”,关于模糊聚类的研究也十分活跃。
(4)基于粗糙集的聚类方法
粗糙聚类是基于粗糙集理论的一种不确定聚类方法。从粗糙集与聚类算法的耦合来看,可以把粗糙聚类方法分为两大类:强耦合粗糙聚类和弱耦合粗糙聚类。
当然,聚类分析新的研究方向远不止这些,比如,数据流挖掘与聚类算法,不确定数据及其聚类算法、量子计算与量子遗传聚类算法等,都是近些年兴起的聚类研究前沿课题。
3、其它离群点挖掘方法
前面介绍的离群点挖掘方法,仅是离群点挖掘的两个代表,实际应用中还有很多比较成熟的离群点挖掘方法,可以从挖掘方法使用的技术类型,或利用先验知识的程度两个角度来进行分类。
(1)使用技术类型
主要有基于统计的方法、基于距离的方法、基于密度的方法、基于聚类的方法、基于偏差的方法、基于深度的方法、基于小波变换的方法、基于图的方法、基于模式的方法、基于神经网络的方法等。
(2)先验知识利用
依据正常或离群的类别信息可利用程度,有三种常见方法:
① 无监督的离群点检测方法,即在数据集中没有任何类别标号等先验知识;
② 有监督的离群点检测方法,即通过存在包含离群点和正常点的训练集中提取离群点的特征;
③ 半监督的离群点检测方法,训练数据包含被标记的正常数据,但是没有关于离群数据对象的信息。