导语:你是否遇到过模型训练时Loss Function"左右横跳",死活不收敛?或是发现某个特征"霸道"地主导了模型决策?本文用一个"身高体重"的生动案例,带你搞懂特征缩放的底层逻辑!
目录
什么是特征缩放
定义
特征缩放是将不同量纲或范围的特征数据,通过数学变换映射到统一量纲区间(通常为[0, 1]或[-1, 1]的过程)。
类比:把不同货币统一换算成人民币,让所有特征站在同一起跑线上
| 目标 | 说明 | 类比 |
| 消除量纲差异 | 让kg和cm等不同单位具有可比性 | 把人民币和美元换算成黄金 |
| 平衡特征权重 | 防止大范围特征(如薪资)压制小范围特征(如年龄) | 拳击比赛按照选手的体重分级 |
| 加速模型收敛 | 优化损失函数形状 | 把崎岖山路("之字形")改造成高速公路 |
常见方法对比
import numpy as np
# 原始数据
data = np.array([[170, 75000],
[160, 48000],
[185, 125000]])
# 标准化(Z-Score)
def z_score(x):
return (x - np.mean(x, axis=0)) / np.std(x, axis=0)
# 归一化(Min-Max)
def min_max(x):
return (x - np.min(x, axis=0)) / (np.max(x, axis=0) - np.min(x, axis=0))
print("标准化结果:\n", z_score(data))
print("归一化结果:\n", min_max(data))
实践
数据准备和可视化
原始数据分布图:
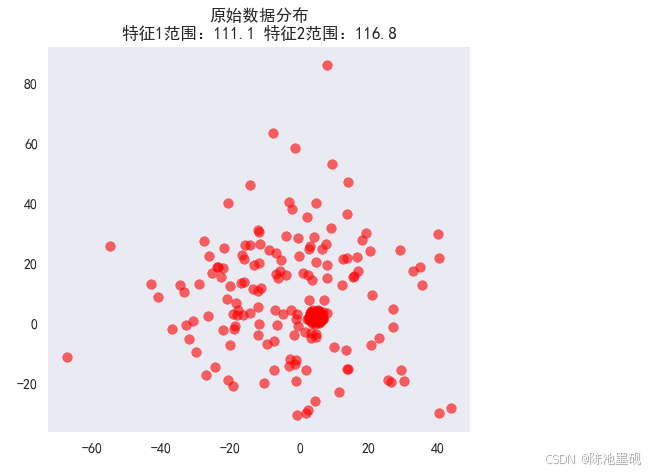
不同缩放方法效果对比:
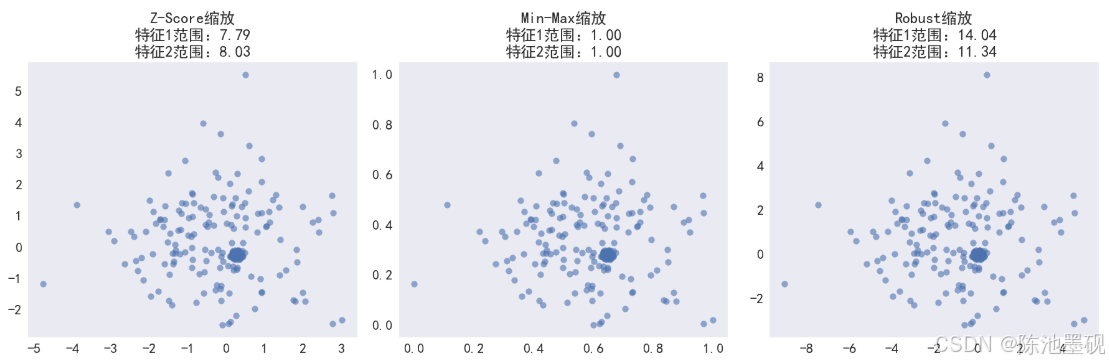
不同缩放方法对模型性能的影响(以SVM为例)
| 缩放方法 | 准确率(未缩放) | 准确率(缩放后) |
| Z-Score | 78% | 85% |
| Min-Max | 76% | 84% |
| Robust | 77% | 83% |
为什么需要使用特征缩放
首先来看看未进行特征缩放的数据分布和进行了特征缩放后的数据分布:
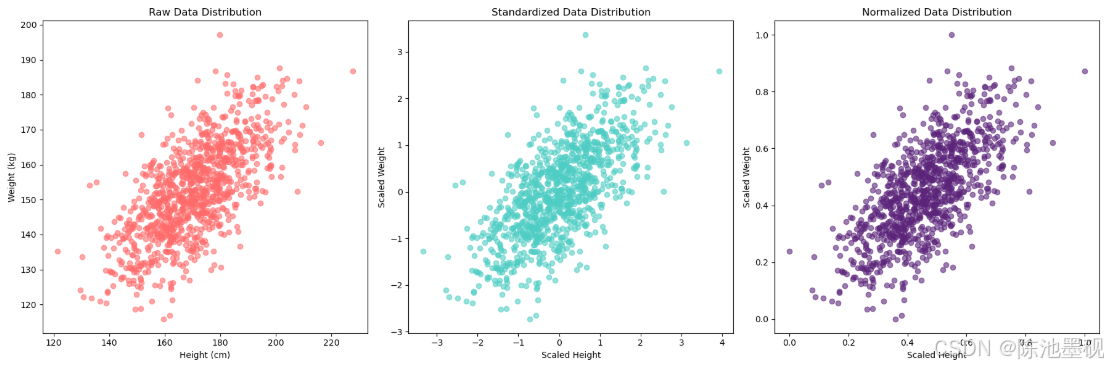
左边第一幅图展示的是原始数据分布(Raw Data Distribution):
X轴表示身高(Height),Y轴表示体重(Weight),每个数据点代表一个样本的身高和体重组合。可以看到,这些点呈现出一定的线性相关性,即随着身高的增加,体重也趋向于增加。
中间那幅图展示的是标准化后的数据分布(Standardized Data Distribution):
X轴表示标准化后的身高(Height),Y轴表示标准化后的体重(Weight),每个数据点代表标准化后的身高和体重组合。标准化是将数据转换成均值为0,标准差为1的标准正态分布形式。从图中可以看出,数据点的分布变得更加紧凑,并且中心点接近于(0,0).此外,由于标准化保持了数据的相对距离,因此数据点之间的关系仍然保持与原始数据相似的变化趋势。
最右边那幅图展示的是归一化后的数据分布(Normalized Data Distribution):
X轴表示归一化后的身高(Height),Y轴表示归一化后的体重(Weight),每个数据点代表归一化后的身高和体重组合。归一化是将数据缩放到[0, 1]范围内。从图中可以看出,所有数据点都被压缩到了一个固定的区间内,即X轴和Y轴的范围都是[0, 1]。尽管数据点的绝对位置发生了变化,但它们之间的相对位置和线性关系仍然得以保留。
通过对比以上三个子图,我们可以清楚的看到特征缩放对数据分布的影响。Standardized和Normalized都是常用的特征缩放方法,它们可以帮助我们消除特征之间尺度差异带来的影响,使得机器学习算法在训练过程中更加稳定和高效。具体选择哪种方法取决于实际应用场景和需求。
例如,在使用基于距离的算法(如K近邻、SVM等)时,归一化可能更合适;而在使用基于梯度下降的算法(如线性回归、逻辑回归等)时,标准化可能更为有效。
~我们再来看一个实例:
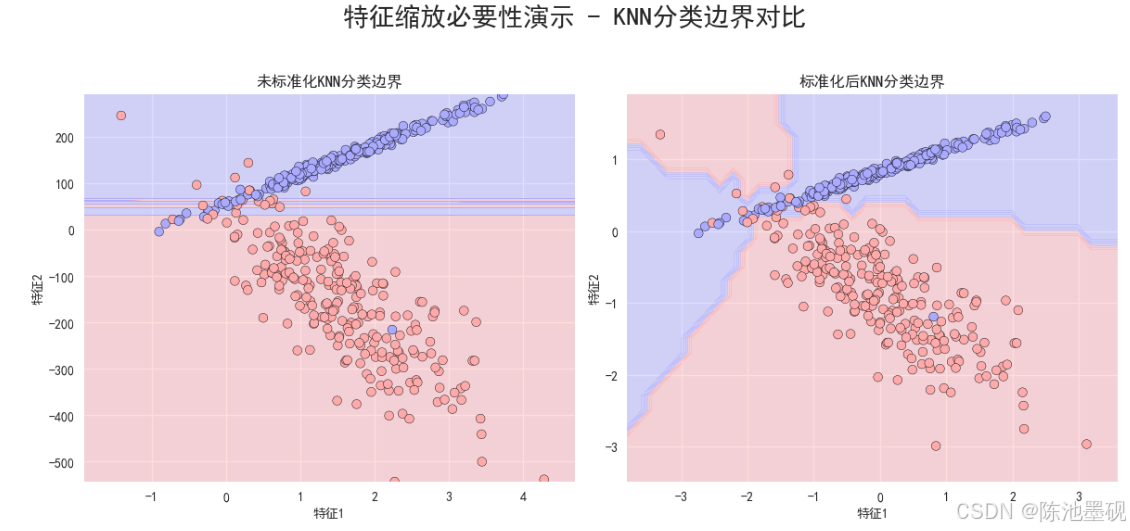
左图:
- 分类边界倾斜:由于特征2的尺度较大,KNN算法在计算最近邻时会更倾向于考虑特征2的变化,导致分类边界呈现出明显的倾斜趋势。
- 分类效果不佳:这种倾斜的分类边界可能无法准确地反映数据的真实分布情况,从而影响分类效果。例如,一些靠近分类边界的点可能会被错误分类。
右图:
- 分类边界更加合理:经过标准化处理后,特征1和特征2对距离计算的贡献变得相对均衡,分类边界变得更加平直,能够更好地反映数据的真实分布情况。
- 分类效果提升:标准化后的分类边界更加清晰,减少了因特征尺度不一致导致的误分类现象,从而提升了KNN算法的分类性能。
距离度量的均衡化证明:
在医疗诊断案例中,未标准化的实验指标(范围[0,1000])与体温(范围[36,42])计算欧氏距离时:
- 原始距离计算:
- 标准化后计算:
标准化使各特征贡献趋于均衡,分类准确率显著提升
总结:
四大核心原因:
| 原因 | 解释 |
| 去除量纲 | 特征缩放可以使不同的特征具有相同的尺度,从而具有可比性或者加权。 |
| 平衡影响力 | 若初始变量数据的范围之间存在较大差异,则范围较大的变量将主导范围较小的变量。 |
| 加速收敛 | 当特征的尺度相差很大时,损失函数的等高线图将变得非常扁平和延伸。这意味着在某些方向上,损失函数的变化会变得非常缓慢,而在其它方向上,它可能变化的非常快。 |
| 提升精度 | 使距离度量更合理 |
算法层面的深度解析
损失函数
在机器学习中,损失函数(Loss Function)是衡量模型预测值和实际值之间差异的关键指标。以线性回归为例,其损失函数通常采用均方误差(Mean Squared Error,MSE),定义如下:
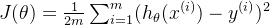
其中,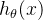
然而,当输入特征具有显著的量纲差异时,这会导致各参数偏导数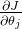
例如,在计算梯度下降时,如果某个特征的数值范围要远大于另一个特征,则该特征对应的权重更新将占据主导地位,导致其它特征的更新步长相对较小,甚至可能被忽略。
总之,记住:当特征的量纲差异较大时,更新步长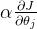
学习率
选择合适的学习率(Learning Rate 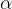
不妨想象一下,在一个多维度特征空间中,Feature1的梯度为0.01,而Feature 2的梯度为1.2。在这种情况下,最大学习率

可问题是,这样的学习率对于小梯度特征来说可能是不合适的。过大的学习率可能导致小梯度方向上的参数更新过于剧烈,从而跳过最优解,甚至导致模型发散无法收敛。相反,如果为了适应小梯度从而降低学习率,那么大梯度方向上的学习效率就会大大降低,每次更新都只能迈出很小的步伐。如图所示(注:该图来源于吴恩达机器学习课程)
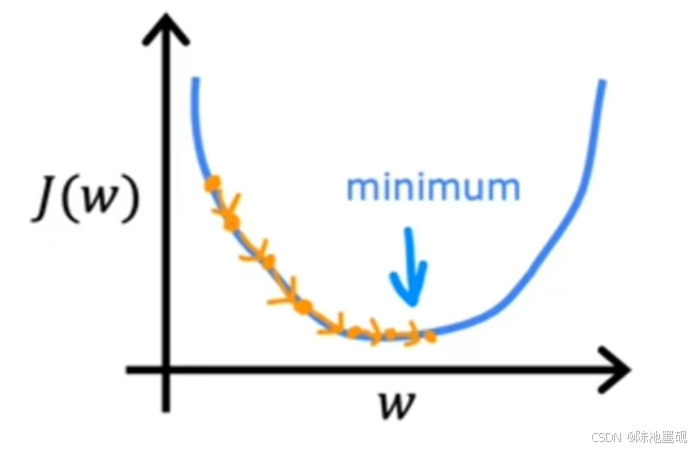
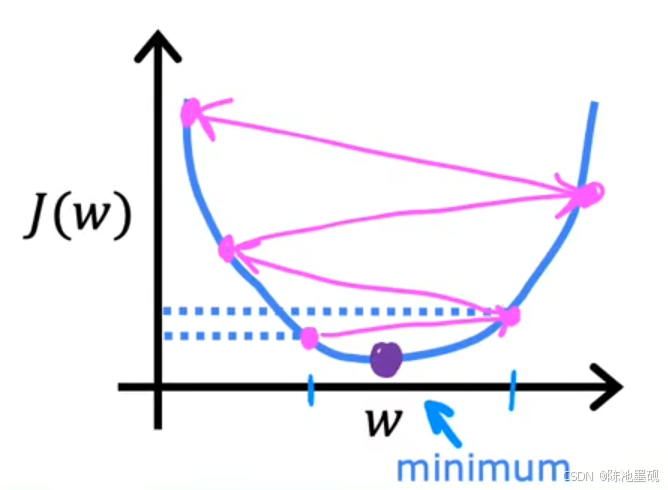
通过特征缩放(如标准化或归一化),可以使所有特征的梯度量级变得相当接近。这样,我们可以统一采用一个较大的学习率,比如α=0.1,既保证了小梯度特征的有效学习,也维持了大梯度特征的良好收敛速度。理论上,这样做可以显著提升参数更新的整体效率。
有关
五大特征缩放总结
| 方法 | 公式 | 适用场景 | 坑点预警 |
|---|---|---|---|
| Z-Score | 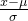 | 特征分布近似高斯,用于需要数据标准化的机器学习算法中,如SVM,Linear Regression等 | 对异常值敏感,如果数据集含有极端值,均值和标准差会被拉偏,导致标准化后的数据失真 |
| Max-Min | 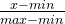 | 图像处理(像素归一化)、需要将数据映射到特征的范围(例如[0,1]区间) | 新数据可能超出边界,对于最大值或最小值变化的数据集不适应 |
| Robust | 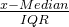 | 收入等长尾数据,适用于存在大量异常值的数据集 | 相较于Z-Score,虽然减少了异常值的影响,但可能造成一定的信息损失 |
| Power | 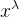 | 方差稳定化,用于修正数据分布形态,使其更贴近于正态分布 | 需要调参以找到合适的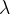 值,不同数据集的最佳参数可能不同,增加了复杂性 值,不同数据集的最佳参数可能不同,增加了复杂性 |
| Log | 订单量等计数数据,尤其是当数据呈偏态分布时,可以减少大数值的影响,使数据更加贴近正态分布 | 需要适当选择 来避免对零值进行对数运算时出现的问题,另外,对非常小的正值也需谨慎处理 来避免对零值进行对数运算时出现的问题,另外,对非常小的正值也需谨慎处理 |
常见误区
类别特征可以缩放吗?
处理方案:
- One-Hot编码后的特征:无需缩放
- 但Embedding后的连续向量:需要缩放!
经验/避坑指南:
- 对数值型类别(如用户等级)建议先缩放再编码
- 时序数据要防止未来信息泄露
- 注意异常值对缩放的影响
- 测试集超出缩放范围,该如何处理?
- Min-Max缩放后,测试机可能超出[0, 1],解决方案:
- 裁剪超出部分
- 使用训练集的'min'和'max'重新缩放测试集(而非重复计算)
- Min-Max缩放后,测试机可能超出[0, 1],解决方案:
工程化实践
在工程化实践中,我们通常会使用Pipeline来构建一个端到端的机器学习流水线。流水线可以简化为数据预处理和模型训练的流程,并确保训练集和测试集的处理方式一致。以下是一个完整的自动化流水线模板,包括特征缩放和模型训练,并对模型性能进行评估:
1、导入必要库
import numpy as np
import pandas as pd
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import SGDRegressor
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.metrics import mean_squared_error, r2_score
import matplotlib.pyplot as plt2、模拟更大的数据集
为了更好地展示特征缩放的效果和模型的性能,我们生成一个更大的数据集
np.random.seed(42)
height = np.random.normal(170, 10, 100)
weight = np.random.lognormal(mean=11, sigma=0.3, size=100) # 生成正数
target = 0.5 * height + 0.001 * weight + np.random.normal(0, 5, 100) # 目标值
# 创建DataFrame
data = pd.DataFrame({
'height': height,
'weight': weight,
'target': target
})- 使用np.random.normal生成100个样本的数据集,确保有足够的样本进行交叉验证
3、分离特征和目标变量
将数据集分为特征矩阵x和目标变量y:
X = data[['height', 'weight']]
y = data['target']4、分离训练集和测试集
为了评估模型的泛化能力,我们将数据集分成训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)- 使用train_test_split将数据分为训练集(80%)、测试集(20%)
- random_state=42确保结果的可重复性
5、构建预处理器
使用ColumnTransformer对数值型特征进行标准化
preprocessor = ColumnTransformer(
transformers=[
('num', StandardScaler(), ['height', 'weight'])
],
remainder='passthrough' # 其他列保持不变(假设存在)
)- ColumnTransformer用于对指定的特征进行预处理
- StandardScaler对height和weight进行标准化处理
6、构建完整ML流水线
将预处理器和回归模型组合成一个完整的流水线
pipeline = Pipeline(steps=[
('preprocessor', preprocessor), # 数据预处理
('regressor', SGDRegressor(max_iter=1000, tol=1e-3)) # 使用SGDRegressor作为回归模型
])- Pipeline包含了两个步骤:预处理和回归模型
- SGDRegressor是基于随机梯度下降的线性回归模型,适合处理大规模数据集
至于为什么选择SGDRegressor?它具有以下几个优点,使其非常适合用于演示特征缩放的重要性:
I、对特征尺度敏感
- SGDRegressor的优化过程依赖于梯度下降算法,而我们在前面也提到过了,梯度下降对特征尺度非常敏感。如果特征的尺度差异大,模型可能会收敛缓慢甚至无法收敛。
- 通过特征缩放,我们可以显著提升SGDRegressor的训练效率和性能。
II、支持大规模数据集
- SGDRegressor支持在线学习(即增量学习),适合处理大规模数据集或是流式数据
III、灵活性高
- 它允许用户调整超参数(如学习率,正则化参数等),便于进行模型调优
7、超参数网格搜索
使用GridSearchCV进行超参数调优,选择最佳参数组合:
param_grid = {
'regressor__alpha': [0.0001, 0.001, 0.01], # 正则化强度
'regressor__learning_rate': ['constant', 'optimal'], # 学习率策略
'regressor__eta0': [0.01, 0.1] # 初始学习率(仅适用于'constant'策略)
}
grid_search = GridSearchCV(pipeline, param_grid, cv=5, scoring='neg_mean_squared_error')8、训练模型
使用训练集训练模型并输出最佳参数
grid_search.fit(X_train, y_train)
# 输出最佳参数
print("最佳参数:", grid_search.best_params_)9、在训练集和测试集上评估模型性能
分别在训练集和测试集上评估模型性能,并计算MSE和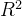
# 在训练集上评估模型性能
y_train_pred = grid_search.predict(X_train)
train_mse = mean_squared_error(y_train, y_train_pred)
train_r2 = r2_score(y_train, y_train_pred)
print(f"训练集均方误差 (MSE): {train_mse:.2f}")
print(f"训练集R²得分: {train_r2:.2f}")
# 在测试集上评估模型性能
y_test_pred = grid_search.predict(X_test)
test_mse = mean_squared_error(y_test, y_test_pred)
test_r2 = r2_score(y_test, y_test_pred)
print(f"测试集均方误差 (MSE): {test_mse:.2f}")
print(f"测试集R²得分: {test_r2:.2f}")10、可视化结果
使用散点图可视化训练集和测试集的预测值和实际值的对比:
plt.figure(figsize=(12, 6))
# 训练集结果
plt.subplot(1, 2, 1)
plt.scatter(y_train, y_train_pred, alpha=0.6)
plt.plot([y_train.min(), y_train.max()], [y_train.min(), y_train.max()], 'k--', lw=2)
plt.title("训练集预测 vs 实际", fontsize=18)
plt.xlabel("实际值", fontsize=16)
plt.ylabel("预测值", fontsize=16)
plt.xticks(fontsize=14)
plt.yticks(fontsize=14)
plt.grid(True)
# 测试集结果
plt.subplot(1, 2, 2)
plt.scatter(y_test, y_test_pred, alpha=0.6)
plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], 'k--', lw=2)
plt.title("测试集预测 vs 实际", fontsize=18)
plt.xlabel("实际值", fontsize=16)
plt.ylabel("预测值", fontsize=16)
plt.xticks(fontsize=14)
plt.yticks(fontsize=14)
plt.grid(True)
plt.tight_layout()
plt.show()注:有感兴趣的可以在Kaggle的Titanic数据集上,分别使用原始数据和缩放后的数据训练SVM模型,观察准确率差异。
附上链接:Kaggle
要点总结
- 特征缩放是数据预处理的标准动作
- 标准化适合大多数场景,归一化适合需要限定范围的情况
- 树模型不需要,但线性模型/神经网络必须做
- 测试集必须使用测试集的缩放参数
结语:在处理需要考量特征间距离或者依赖于梯度信息的算法时,特征缩放是不可或缺的一步,它能够显著影响到模型的性能和收敛速度。如果忽略了这一步骤,可能会导致模型训练效率低下,甚至得到次优的结果。
文章之中如有不对之处,恳请指正,感谢!