目录
- 前言
- 什么是分布式存储
- 分布式存储的优点
- 本章重点
- glusterfs相关术语
- glusterfs的逻辑卷类型
- 准备6台测试服务器
- storage服务器安装glusterfs软件并启动
- 分布式集群的结构
- 配置可信池 pool
- 创建复制卷--replicated volume
- client客户端挂载复制卷
- 卷的删除
- 创建条带卷--striped volume
- client客户端挂载条带卷
- 创建分布式卷-- replicated volume
- client客户端挂载分布式卷
- 分布式复制卷--distributed replicated volume(建议使用这种卷)
- client客户端挂载分布式复制卷
- 分散卷--dispersed volume
- client客户端挂载分散卷
- 分布式分散卷--distributed dispersed volume
前言
环境:centos7.9 glusterfs 9.4
什么是分布式存储
我们之前已经学过了NAS是远程网络共享目录,SAN是远程通过网络共享块设备,那么分布式存储可以看做拥有多台存储服务器连接起来的存储设备端,把这么多台存储服务器的存储组合起来做成一个整体,然后再通过网络进行远程共享,共享的方式可以是目录(文件存储)或块设备(块存储)或者对象存储,常见的分布式存储开源软件有GlusterFS,Ceph,HDFS ,MooseFS,FastDFS等。
分布式存储的优点
1、扩容方便,轻松达到PB级别或以上;
2、提升读写性能(LB)或数据高可用(HA);
3、避免单节点故障导致整个架构问题;
4、价格相对便宜,大量的廉价设备就可以组成分布式存储,比光纤SAN这种便宜;
本章重点
本章节我们主要讲解glusterfs,glusterfs全称为:Gluster File System ,这是一款自由软件,glusterfs属于文件存储,换句话说,glusterfs共享出来的是目录。glusterfs 是一个可扩展的分布式文件系统,它将来自多个服务器的磁盘存储资源聚合到一个全局命名空间中。glusterfs软件的下载以及更多安装文档我们可以访问官方文档:https://docs.gluster.org/en/latest/Quick-Start-Guide/Quickstart/,下面我们先来了解一些glusterfs基本的术语和概念。
glusterfs相关术语
trusted pool(可信池): 含义就是把多个服务器用命令组成一个pool,官方术语称为trusted pool,简称pool;
brick(存储块): 指可信主机池中由主机提供的用于物理存储的专用分区,如一个data分区;
volume(逻辑卷): 一个逻辑卷是一组Brick的集合,卷是数据存储的逻辑设备;
fuse: 用户空间文件系统,是一个客户端挂载远程文件存储的内核模块,允许用户自己创建文件系统,无须修改内核代码;
glusterd(后台管理进程): glusterfs的后台主服务进程,在存储群集中的每个节点上都要运行;
vfs: 内核空间对用户空间提供的访问磁盘的接口。
glusterfs的逻辑卷类型
分布式卷 replicated volumes:文件随机分布在卷中存储块中,提升读写性能但不提供数据冗余,最大化利用磁盘空间,在需要扩展存储和冗余不重要
或由其他硬件/软件层提供的地方使用分布式卷。注意:分布式卷中的磁盘/服务器故障可能会导致严重的数据丢失,因为数据内容随机分布在卷中的存储块
上。创建卷时不写卷模式默认就是分布式卷;
复制卷 replicated volumes:文件复制到多个brick中,写入性能下降,提升读取性,提供数据冗余,副本越多数据相对越安全,磁盘空间利用率低,
高可用,即使一个brick挂了,客户端还能访问,复制卷类似raid1,raid1就是把一个文件复制式的存储在多个磁盘,一个磁盘挂并不影响整个磁盘组;
条带卷 stripe volumes:文件以轮询调度算法分别在brick,提升大文件读写性能,brick的数量是条带数的等数,一个brick挂了,客户端就不能访
问,条带卷类似raid0,raid0就是轮询的把文件写入多个磁盘,一个磁盘挂,整个就挂;
分布式复制卷:提供数据高可靠,大大提升读取速度,brick数量是副本数的倍数;
分散卷dispersed volume:分散卷基于擦除码(校验码),它将文件的编码数据条带化,并在卷中的多个brick块中添加一些冗,可以使用分散卷来获得可配置的可靠性级别,同时最大限度地减少空间浪费;
分布式分散卷 distributed dispersed volume:集合了分布式卷和分散卷的特点。
更详细的卷类型介绍可以看官方文档,地址:https://docs.gluster.org/en/latest/Quick-Start-Guide/Architecture/
准备6台测试服务器
准备6台服务器,其中4台作为storage服务器,另外2台作为client服务端,IP配置如下:
192.168.118.126 client1
192.168.118.127 client2
192.168.118.128 storage1
192.168.118.129 storage2
192.168.118.130 storage3
192.168.118.131 storage4
为了安装软件方便,我们还需要格外附加条件,如下:
1、服务器安装的时候需要分一个data分区,因为glusterfs不建议共享根目录;
2、6台服务器都确保能连外网,以及6台服务器彼此能两两ping的通;
3、确保服务器的时间都是一致的,也就是说开启systemctl start ntpd 时间服务即可;
storage服务器安装glusterfs软件并启动
开始配置storage服务器,4台storage服务器都做如下的相同操作,下面在storage1服务器做演示:
[root@storage1 ~]# cd /etc/yum.repos.d/ #切换目录
[root@storage1 yum.repos.d]# vim glusterfs.repo #配置glusterfs网络源,内容如下:
[glusterfs]
name=glusterfs
baseurl=https://buildlogs.centos.org/centos/7/storage/x86_64/gluster-9/
enabled=1
gpgcheck=0
[root@storage1 yum.repos.d]# yum install glusterfs-server -y #yum安装glusterfs-server
[root@storage1 yum.repos.d]# systemctl start glusterd.service #启动glusterd服务
[root@storage1 yum.repos.d]# systemctl enable glusterd.service #设置开机自启
分布式集群的结构
分布式集群一般有两种结构:
有中心节点:中心节点一般指管理节点;
无中心节点:所有节点又管理又做事,glusterfs就属于这种;
本节我们主要讲无中心节点。
配置可信池 pool
我们在4个storage服务器都安装好了glusterfs-server并启动了,那么这4台storage服务器是如何组成一个集群的呢?
答案是:我们只需要在其中一台storage服务器上通过一条命令来连接另外3台storage服务器即可,这样就可以让这4台storage服务器组成一个集群了。
[root@storage1 /]# gluster peer probe 192.168.118.129 #既可以指定主机名,也可以指定IP地址
peer probe: success
[root@storage1 /]# gluster peer probe 192.168.118.130 把storage3也加入进来
peer probe: success
[root@storage1 /]# gluster peer probe 192.168.118.131 把storage4也加入进来
peer probe: success
[root@storage1 /]# gluster peer status #查看已连接的主机状态
Number of Peers: 3 #这里看到有3个,但本身主机也是一个
Hostname: 192.168.118.129
Uuid: fe928b95-5ea4-4351-9526-5d7aa4c79099
State: Peer in Cluster (Connected)
Hostname: 192.168.118.130
Uuid: 538342be-5bb9-45b7-bae5-681d66e9d68e
State: Peer in Cluster (Connected)
Hostname: 192.168.118.131
Uuid: 537342be-5er9-45b7-bae5-681d66e8jiug
State: Peer in Cluster (Connected)
[root@mysql /]# gluster peer detach 192.168.118.129 #断开指定的IP机器
创建复制卷–replicated volume
上一步,我们已经使用gluster peer probe命令把4台storage服务器组成一个集群,那么这个集群是如何共享存储呢?
答案是:每台storage服务器都捐点存储空间出来,就好像小时候捐钱一样;前面我们说过glusterfs是文件型存储系统,那么共享捐出来的就是目录。
复制卷replica:文件复制到多个brick中,写入性能下降,提升读取性,提供数据冗余,副本越多数据相对越安全,磁盘空间利用率低,高可用,即使一个brick挂了,客户端还能访问。
下面,将创建复制卷进行演示,在各个storage服务器上单独的分区里创建存储目录,如下所示:
[root@storage1 data]# mkdir /data/ #在每台storage服务器上创建共享目录,目录名可以不一样
[root@storage1 /]# gluster volume create gv0 replica 4 192.168.118.128:/data/ 192.168.118.129:/data/ 192.168.118.130:/data/ 192.168.118.131:/data/
volume create: gv0: success: please start the volume to access data
#创建复制卷,以上命令,gv0表示卷名,replica表示创建的是复制卷,4表示复制卷将会将同一个文件复制4份存在4个主机上,如果以上你的目录是在根目录,也可以加force强制创建卷
[root@storage1 /]# gluster volume info gv0 #查看指定卷的信息
Volume Name: gv0 #卷名
Type: Replicate #卷的类型为复制模式
Volume ID: a9de3a0f-b79e-4672-a8dd-67f48bc43c22 #卷的ID
Status: Created #卷的状态,现在是已创建状态
Snapshot Count: 0
Number of Bricks: 1 x 4 = 4 #该卷的Bricks数量,即该卷有多少个存储主机
Transport-type: tcp #传输类型为tcp传输
Bricks: #Bricks数量与相关信息
Brick1: 192.168.118.128:/data/ #第一个Brick,IP与共享目录
Brick2: 192.168.118.129:/data/ #第二个Brick,IP与共享目录
Brick3: 192.168.118.130:/data/ #第三个Brick,IP与共享目录
Brick4: 192.168.118.131:/data/ #第四个Brick,IP与共享目录
Options Reconfigured:
cluster.granular-entry-heal: on
storage.fips-mode-rchecksum: on
transport.address-family: inet
nfs.disable: on
performance.client-io-threads: off
#创建好卷之后还需要启动卷,这样客户端才能挂载
[root@storage1 /]# gluster volume start gv0 #启动gv0卷
volume start: gv0: success
[root@storage1 /]# gluster volume info gv0 | grep Status #查看卷的状态,已经启动了
Status: Started
[root@storage1 /]#
client客户端挂载复制卷
fuse:Filesystem in Userspace,用户空间文件系统,是一个客户端挂载远程文件存储的内核模块,允许用户自己创建文件系统,无须修改内核代码。现在我们就需要在client1安装它:
[root@client1 ~]# yum install glusterfs glusterfs-fuse -y #客户端安装glusterfs glusterfs-fuse
[root@client1 ~]# mkdir /data #创建本地目录
[root@client1 ~]# mount.glusterfs 192.168.118.128:gv0 /data #将远程存储挂载到本地/data目录
[root@client1 ~]# df -h #查看已挂载的存储空间
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/centos-root 6.2G 1.4G 4.9G 23% /
/dev/sda1 1014M 138M 877M 14% /boot
192.168.118.128:gv0 8.0G 0G 8G 70% /data #这就是我们挂载的存储,由于gv0是复制卷,4个storage共享的目录都是8g,而复制卷是把文件复制到每个storage上,所以客户端显示的就是32/4=8G
[root@client1 data]# dd if=/dev/zero of=/data/test bs=5M count=10 #使用dd命令创建一个50M的test文件进行测试
[root@client1 data]# ll -h #客户端查看已经创建一个50M的test文件
-rw-r--r--. 1 root root 50M Jan 1 22:09 test
[root@storage1 data]# ll -h #查看storage1,在共享的/data/目录已经有了一个50M的test文件
[root@storage2 data]# ll -h #查看storage2,在共享的/data/目录已经有了一个50M的test文件
[root@storage3 data]# ll -h #查看storage3,在共享的/data/目录已经有了一个50M的test文件
[root@storage4 data]# ll -h #查看storage4,在共享的/data/目录已经有了一个50M的test文件
以上,说明以下几点:
1、在client1客户端/data目录创建了一个50M的test文件,那么在4台storage服务器的共享目录/data就能看见这个文件,因为我们的卷是复制模式
即:replica 4表示在4台storage服务器上做复制模式,所以4台storage服务器的共享目录都有这个50M文件,这显然很浪费存储空间,其实这个
replica 4(主机也写了4个storage主机),这个数量4可以在创建卷时自定义,不一定要全部的storage服务器做复制模式,后面讲的分布式复制卷就
是这种情况;
2、多个client客户端可以挂载同一个卷,也就是说此时你在client2客户端上挂载gv0,也能看到client1写的文件,由于我们说过gluster
是文件存储,所以多个客户端可以挂载同一个卷,多个客户端彼此是文件共享的,即同读同写文件;
3、replica复制卷最大的优点是,具有高可用性,即使storage节点挂掉其中一个,并不影响client客户端读写文件,当挂掉的节点再次启动时,该节点
就会去同步其它节点的文件,实现了文件一致性,但缺点也是很明显,浪费存储控件间,同一个文件存了4份。
卷的删除
[root@client1 /]# umount /data/ #先umount卸载客户端
[root@storage1 /]# gluster volume stop gv0 #在storage1中停止卷
Stopping volume will make its data inaccessible. Do you want to continue? (y/n) y
volume stop: gv0: success
[root@storage1 /]# gluster volume delete gv0 #在storage1中删除卷
Deleting volume will erase all information about the volume. Do you want to continue? (y/n) y
volume delete: gv0: success
[root@storage1 /]# gluster volume list #现在已经没有任何卷了
No volumes present in cluster
[root@storage1 /]#
创建条带卷–striped volume
条带卷stripe:文件以轮询调度算法拆分大小的分布在brick,提升大文件读写性能,brick的数量是条带数的等数,一个brick挂掉,文件就损坏了,整个客户端就不能访问文件了。
备注:在glusterfs 6.1版本之后,不在支持stripe ,分布式条带卷不在多说,可以自行查阅 ,在官方的安装文档卷的介绍中已经把条带卷移除了,因为这个卷的可用性太差,只要一个brick挂掉,整个就挂掉,客户端就不能访问,显然不符合生产环境。所以,这里只是简单的对旧版本中条带卷做了介绍。
[root@storage1 /]# gluster volume create gv1 stripe 4 192.168.118.128:/data/gv1 192.168.118.129:/data/gv1 192.168.118.130:/data/gv1 192.168.118.131:/data/gv1 #以下报错是因为我的gluster版本是9版本,如果你的版本是glusterfs 6.1以下,那么你就可以创建条带卷
stripe option not supported
[root@storage1 /]# gluster volume start gv1 #启动条带卷
client客户端挂载条带卷
[root@client1 ~]# yum install glusterfs glusterfs-fuse -y #客户端安装glusterfs glusterfs-fuse
[root@client1 ~]# mkdir /data #创建本地目录
[root@client1 /]# mount.glusterfs 192.168.118.128:gv1 /data #客户端挂载
说明:客户端挂载条带卷之后看到的存储空间是4个storage共享目录相加的总存储空间,在client客户端中创建一个100M的test文件,那么test文件会被分散存储在每个storage服务器中,即每个storage服务器存储着一个25M 的test文件,当client客户端中创建一个30K的test文件,test文件会被分散存储在每个storage服务器中,但由于文件太小,所以只有其中一个storage服务器存储着一个30K的test文件,其他
storage服务器存储着一个0K的test文件,这种分散机制是有gluster的条带卷内部决定的。同时,只要有其中一个storage服务器挂掉,客户端就访问不了了,也许这正是官网淘汰掉条带卷的原因吧。
创建分布式卷-- replicated volume
分布式卷:文件随机分布在卷中存储,提升读写性能但不提供数据冗余,最大化利用磁盘空间,在需要扩展存储和冗余不重要或由其他硬件/软件层提供的地方使用分布式卷。注意:分布式卷中的磁盘/服务器故障可能会导致严重的数据丢失,因为目录内容随机分布在卷中的存储块上。
分布式卷既不像复制卷一样提供镜像副本,也不像条带卷一样轮询的将文件大小拆分创建在不同的brick存储块中,分布式卷是随机的将整个文件分布在brick存储块中,即file1可能存储在brick1中,file2和file3可能存储在brick2中。
[root@storage1 gv1]# gluster volume create gv1 192.168.118.128:/data/gv1 192.168.118.129:/data/gv1 192.168.118.131:/data/gv1 #创建分布式卷,不用写卷模式,默认就是分布式卷
volume create: gv1: success: please start the volume to access data
[root@storage1 gv1]# gluster volume info
Volume Name: gv1
Type: Distribute #分布式卷
Volume ID: 2d7a1f95-14e5-4362-823c-c961f6f3823a
Status: Created
Snapshot Count: 0
Number of Bricks: 3
Transport-type: tcp
Bricks:
Brick1: 192.168.118.128:/data/gv1
Brick2: 192.168.118.129:/data/gv1
Brick3: 192.168.118.131:/data/gv1
Options Reconfigured:
storage.fips-mode-rchecksum: on
transport.address-family: inet
nfs.disable: on
[root@storage1 gv1]# gluster volume start gv1 #启动分布式卷
client客户端挂载分布式卷
[root@client1 data]# mount.glusterfs 192.168.118.128:gv1 /data/ #客户端挂载分布式卷
[root@client1 data]# df -h #查看挂载的存储空间
Filesystem Size Used Avail Use% Mounted on
192.168.118.128:/gv1 24G 0G 24G 100% /data #总空间就是3个存储块的总空间之和
[root@client1 data]# touch file{1..4} #创建4个文件
[root@client1 data]# dd if=/dev/zero of=/data/test bs=5M count=10 #再创建一个test文件
[root@storage1 /]# ls -lh /data/gv1/ #查看storage1,没有文件
total 0
[root@storage2 /]# ls -lh /data/gv1/ #查看storage2,有2个文件
total 0
-rw-r--r-- 2 root root 0 Jan 2 01:14 file3
-rw-r--r-- 2 root root 0 Jan 2 01:14 file4
[root@storage3 /]# ls -lh /data/gv1/ #查看storage3,有2个文件,可见,分布式卷随机存储文件
total 50M
-rw-r--r-- 2 root root 0 Jan 2 01:14 file1
-rw-r--r-- 2 root root 0 Jan 2 01:14 file2
-rw-r--r-- 2 root root 50M Jan 2 01:13 test
[root@storage3 /]#
以上,我们讨论了复制卷、条带卷、分布式卷,复制卷的缺点是很浪费空间,条带卷就不说了,官网新版本已经删除了条带卷,分布式卷缺点是没有高可用,即一个存储块挂掉之后,客户端就不能访问该储存块中的文件了,所以,以上3种卷都不建议在生产环境中使用,下面我们来介绍另外两种卷。
分布式复制卷–distributed replicated volume(建议使用这种卷)
分布式复制卷集结了分布式卷和复制卷的特点,即随机分布文件,又做到文件有副本镜像,那么,这是如何做到的呢,其实,分布式复制卷在创建时会把n个brick以倍数的形式进行创建,如4个brick,创建分布式复制卷时指定replica 2,那么就是4个brick分成了两组replicaed volume 1和replicaed volume 2,客户端创建文件会被随机分配到其中的一个replicaed volume组中去,然后在该组内进行副本镜像复制,具体如官方的示意图所示:
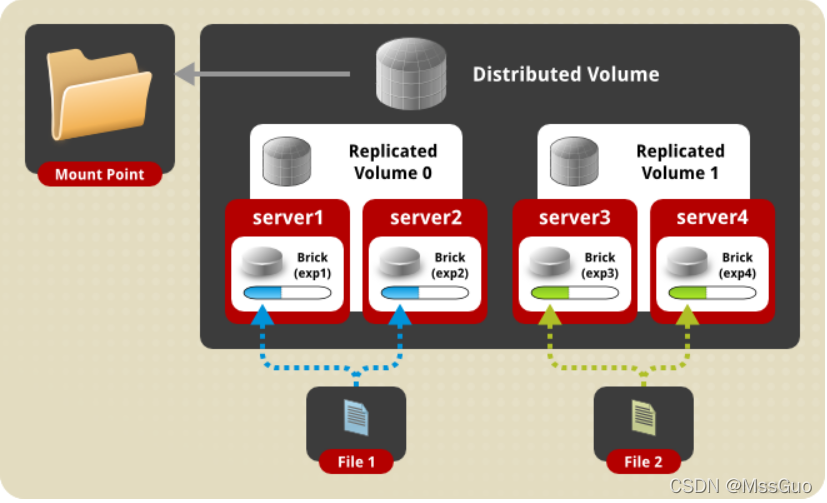
[root@storage1 ~]# gluster volume create gv0 replica 2 192.168.118.128:/data 192.168.118.129:/data 192.168.118.131:/data 192.168.118.133:/data
volume create: gv0: success: please start the volume to access data
#这里replica为2,但写了4个bricks,而分布式卷参数默认不用写就是分布式卷,这说明是把4个bricks分成了2组replicated volume,同理,replica为3时而bricks的数量也应当是3的倍数如9,这就表示分成3组replicated volume,每组有3个bricks;前面我们讲复制卷的时候,replica为4,也写了4个bricks,这时默认创建就是复制卷。因为默认Number of Bricks: 1 x 4 = 4,即1个replicated volume,有4个bricks。
[root@storage1 ~]# gluster volume info #查看gv2卷的信息
Volume Name: gv2
Type: Distributed-Replicate #已经是分布式复制卷了
Volume ID: 31066ee8-11ef-4d23-8d45-fb6b20065354
Status: Created
Snapshot Count: 0
Number of Bricks: 2 x 2 = 4 #这里就是2组replicated volume,每个组有2个bricks
Transport-type: tcp
Bricks:
Brick1: 192.168.118.128:/data
Brick2: 192.168.118.129:/data
Brick3: 192.168.118.130:/data
Brick4: 192.168.118.131:/data
Options Reconfigured:
cluster.granular-entry-heal: on
storage.fips-mode-rchecksum: on
transport.address-family: inet
nfs.disable: on
performance.client-io-threads: off
[root@storage1 ~]# gluster volume start gv2 #启动gv2卷,只有启动卷了客户端才能挂载
volume start: gv2: success
[root@storage1 ~]#
client客户端挂载分布式复制卷
[root@client1 /]# mount.glusterfs 192.168.118.128:gv2 /data #客户端挂载分布式复制卷
[root@client1 /]# df -h
Filesystem Size Used Avail Use% Mounted on
192.168.118.128:gv2 15G 7.0G 7.2G 50% /data #已挂载
[root@client1 /]# dd if=/dev/zero of=/data/test bs=5M count=10 #使用dd命令创建一个50M的test文件进行测试
[root@client1 data]# touch file{1..3} #再创建3个文件
[root@storage1 ~]# ll -h /data #查看storage1,有file3和test文件
total 50M
-rw-r--r--. 2 root root 0 Jan 2 17:04 file3
-rw-r--r--. 2 root root 50M Jan 2 17:03 test
[root@storage2 ~]# ll -h /data #查看storage2,有file3和test文件,说明storage1和storage2是一组,两两进行了文件复制
total 50M
-rw-r--r-- 2 root root 0 Jan 2 17:04 file3
-rw-r--r-- 2 root root 50M Jan 2 17:03 test
[root@storage3 ~]# ll -h /data #查看storage3,有file1和file2t文件
total 0
-rw-r--r-- 2 root root 0 Jan 2 17:04 file1
-rw-r--r-- 2 root root 0 Jan 2 17:04 file2
[root@storage4 ~]# ll -h /data #查看storage4,有file1和file2t文件,说明storage3和storage4是一组,两两进行了文件复制
total 0
-rw-r--r--. 2 root root 0 Jan 2 17:04 file1
-rw-r--r--. 2 root root 0 Jan 2 17:04 file2
#以上分布式复制卷即做了随机发布,也做到了复制副本,但是如果同为一组的bricks坏了仍会导致整个不可用。
分散卷–dispersed volume
分散卷:分散卷基于擦除码(校验码),它将文件的编码数据条带化,并在卷中的多个brick块中添加一些冗,可以使用分散卷来获得可配置的可靠性级别,同时最大限度地减少空间浪费,这种分散卷类似于raid5,拿一块或多块盘来做冗余校验。
#disperse 4 redundancy 1 表示4个brick做分散卷,拿1个brick要做冗余校验
[root@storage1 data]# gluster volume create gv3 disperse 4 redundancy 1 192.168.118.128:/data 192.168.118.129:/data 192.168.118.131:/data 192.168.118.133:/data force
volume create: gv3: success: please start the volume to access data
[root@storage1 data]# gluster volume info #查看分散卷gv3的信息
Volume Name: gv3
Type: Disperse #分散卷
Volume ID: 812c5547-a7cb-41ce-919a-a77c4d986e92
Status: Created
Snapshot Count: 0
Number of Bricks: 1 x (3 + 1) = 4 #表示3个brick存放数据,拿1个brick要做冗余校验
Transport-type: tcp
Bricks:
Brick1: 192.168.118.128:/data/gv3
Brick2: 192.168.118.129:/data/gv3
Brick3: 192.168.118.131:/data/gv3
Brick4: 192.168.118.133:/data/gv3
Options Reconfigured:
storage.fips-mode-rchecksum: on
transport.address-family: inet
nfs.disable: on
[root@storage1 data]# gluster volume start gv3 #启动分散卷gv3
volume start: gv3: success
[root@storage1 data]#
client客户端挂载分散卷
[root@client1 /]# mount.glusterfs 192.168.118.128:gv3 /data #客户端挂载gv3分散卷
[root@client1 /]# df -h
Filesystem Size Used Avail Use% Mounted on
192.168.118.128:/gv3 15G 7.7G 7.4G 52% /data
[root@client1 data]# dd if=/dev/zero of=/data/test bs=5M count=10 #创建一个50M的test文件
[root@client1 data]# touch file1 #创建一个普通文件
[root@client1 data]# cat /etc/passwd >>file1 #往普通文件写入一些内容
[root@client1 data]# ll -h
-rw-r--r--. 1 root root 897 Jan 2 18:29 file1
-rw-r--r--. 1 root root 50M Jan 2 18:28 test
[root@storage1 /]# ll -h /data/gv3 #storage1有两个文件
total 31M
-rw-r--r--. 2 root root 512 Jan 2 18:29 file1
-rw-r--r--. 2 root root 17M Jan 2 18:28 test
[root@storage2 /]# ll -h /data/gv3 #storage2也有两个文件
total 31M
-rw-r--r-- 2 root root 512 Jan 2 18:29 file1
-rw-r--r-- 2 root root 17M Jan 2 18:28 test
[root@storage3 /]# ll -h /data/gv3 #storage3也有两个文件
total 17M
-rw-r--r-- 2 root root 512 Jan 2 18:29 file1
-rw-r--r-- 2 root root 17M Jan 2 18:28 test #storage4也有两个文件,校验码其实是分散在各个storage中的
[root@storage4 /]# ll -h /data/gv3
total 31M
-rw-r--r--. 2 root root 512 Jan 2 18:29 file1
-rw-r--r--. 2 root root 17M Jan 2 18:28 test
分布式分散卷–distributed dispersed volume
[root@storage1 /]# gluster volume create gv5 disperse 4 redundancy 1 192.168.118.128:/data/gv4 192.168.118.128:/data/gv5 192.168.118.129:/data/gv4 192.168.118.129:/data/gv5 192.168.118.131:/data/gv4 192.168.118.131:/data/gv5 192.168.118.133:/data/gv4 192.168.118.133:/data/gv5 force
This configuration is not optimal on most workloads. Do you want to use it ? (y/n) y
volume create: gv5: success: please start the volume to access data
#创建一个分布式分散卷,由于分布式分散卷要求比较高,所以在每个storage上都创建了两个共享目录来模拟多个storage
# bricks数必须是disperse count的倍数
[root@storage1 /]# gluster volume info #查看卷的信息
Volume Name: gv5
Type: Distributed-Disperse #分布式分散卷
Volume ID: 18cf1b43-ab7b-46ca-a858-1b39f6476980
Status: Created
Snapshot Count: 0
Number of Bricks: 2 x (3 + 1) = 8 #有待解释这个具体含义
Transport-type: tcp
Bricks:
Brick1: 192.168.118.128:/data/gv4
Brick2: 192.168.118.128:/data/gv5
Brick3: 192.168.118.129:/data/gv4
Brick4: 192.168.118.129:/data/gv5
Brick5: 192.168.118.131:/data/gv4
Brick6: 192.168.118.131:/data/gv5
Brick7: 192.168.118.133:/data/gv4
Brick8: 192.168.118.133:/data/gv5
Options Reconfigured:
storage.fips-mode-rchecksum: on
transport.address-family: inet
nfs.disable: on
[root@storage1 /]# gluster volume start gv5 #启动分布式分散卷
客户端挂载分布式分散卷
[root@client1 /]# mount.glusterfs 192.168.118.128:gv5 /data #客户端挂载分布式分散卷
[root@client1 /]# df -h #查看挂载信息
Filesystem Size Used Avail Use% Mounted on
192.168.118.128:gv5 17G 6.0G 11G 36% /data
[root@client1 /]# dd if=/dev/zero of=/data/test bs=5M count=10 #创建一个50M的test文件
[root@client1 /]# cd /data/
[root@client1 data]# touch file{1..2} #创建两个普通文件file1、file2
[root@client1 data]# ll -h
total 51M
-rw-r--r--. 1 root root 0 Jan 2 19:02 file1
-rw-r--r--. 1 root root 0 Jan 2 19:02 file2
-rw-r--r--. 1 root root 50M Jan 2 19:01 test
[root@client1 data]#
[root@storage1 /]# ll -h /data/gv4/ && ll -h /data/gv5/ #查看storage1
total 29M
-rw-r--r--. 2 root root 17M Jan 2 19:01 test
total 17M
-rw-r--r--. 2 root root 17M Jan 2 19:01 test
[root@storage1 /]#
[root@storage2 /]# ll -h /data/gv4/ && ll -h /data/gv5 #查看storage2
total 29M
-rw-r--r-- 2 root root 17M Jan 2 19:01 test
total 29M
-rw-r--r-- 2 root root 17M Jan 2 19:01 test
[root@storage2 /]#
[root@storage3 /]# ll -h /data/gv4/ && ll -h /data/gv5 #查看storage3
total 0
-rw-r--r-- 2 root root 0 Jan 2 19:02 file1
-rw-r--r-- 2 root root 0 Jan 2 19:02 file2
total 0
-rw-r--r-- 2 root root 0 Jan 2 19:02 file1
-rw-r--r-- 2 root root 0 Jan 2 19:02 file2
[root@storage3 /]#
[root@storage4 /]# ll -h /data/gv4/ && ll -h /data/gv5 #查看storage5
total 8.0K
-rw-r--r--. 2 root root 0 Jan 2 19:02 file1
-rw-r--r--. 2 root root 0 Jan 2 19:02 file2
total 8.0K
-rw-r--r--. 2 root root 0 Jan 2 19:02 file1
-rw-r--r--. 2 root root 0 Jan 2 19:02 file2
[root@storage4 /]#
#分布式分散卷的文件存储情况解释优点复杂,待分析
扩容
只有分布式distributed或带有分布式的卷才能在线扩容。
#先创建一个分布式卷gv8
[root@storage1 data]# gluster volume create gv8 192.168.118.128:/data/gv8 192.168.118.129:/data/gv8 force
volume create: gv8: success: please start the volume to access data
[root@storage1 data]# gluster volume info #查看卷信息
Volume Name: gv8 #卷名
Type: Distribute #卷类型,分布式卷
Volume ID: fd01f49d-c542-44ec-a5d6-c7ca2b2f28f7
Status: Started
Snapshot Count: 0
Number of Bricks: 2 #只有两个存储块
Transport-type: tcp
Bricks:
Brick1: 192.168.118.128:/data/gv8
Brick2: 192.168.118.129:/data/gv8
Options Reconfigured:
storage.fips-mode-rchecksum: on
transport.address-family: inet
nfs.disable: on
[root@storage1 data]#
[root@storage1 data]#gluster volume start gv8 #启动分布式卷gv8
[root@client1 /]# mount.glusterfs 192.168.118.128:gv8 /data/gv8/ #客户端挂载
[root@client1 /]# df -h
Filesystem Size Used Avail Use% Mounted on
192.168.118.128:gv8 13G 6.0G 7.1G 46% /data/gv8 #容量大小为13G,不够了,要扩容
[root@client1 /]#
#现在假设gv8容量不够了,客户端需要存放很大的文件,那么现在需要扩容分布式卷,操作如下:
[root@storage8 /]# yum install glusterfs-server -y #需要新加一台服务器storage8,并安装glusterfs-server软件
[root@storage8 /]# systemctl status glusterd.service #启动服务
[root@storage8 /]# systemctl enable glusterd.service #设置开机自启
[root@storage8 /]# mkdir /data/gv8 -p #创建共享目录为/data/gv8
[root@storage1 /]# gluster peer probe 192.168.118.190 #在storage1服务器上把storage8拉进可信池(拉进群)
[root@storage1 data]# gluster volume add-brick gv8 192.168.118.131:/data/gv8 force #把storage8加入gv8卷中
volume add-brick: success
Volume Name: gv8
Type: Distribute
Volume ID: fd01f49d-c542-44ec-a5d6-c7ca2b2f28f7
Status: Started
Snapshot Count: 0
Number of Bricks: 3 #存储块变成3个了
Transport-type: tcp
Bricks:
Brick1: 192.168.118.128:/data/gv8
Brick2: 192.168.118.129:/data/gv8
Brick3: 192.168.118.131:/data/gv8
Options Reconfigured:
storage.fips-mode-rchecksum: on
transport.address-family: inet
nfs.disable: on
[root@storage1 data]#
[root@client1 /]# df -h #查看客户端,容量已经增大了,扩容成功
Filesystem Size Used Avail Use% Mounted on
192.168.118.128:gv8 49G 28G 21G 58% /data/gv8 #容量增大到49G了,扩容成功
[root@client1 /]#
这里不讲缩容,因为一般生产环境不缩容,缩容有风险,可能会造成数据丢失,其实缩容的原理就是可信池中减少一个brick,但并不是全部的卷都支持缩容。
总结
glusterfs是文件类型存储,可以实现数据共享;
1、storage服务器安装glusterfs-server、启动服务、创建共享目录、配置可信池(组群)、创建卷、启动卷;
[root@storage1 /]# yum install glusterfs-server -y #storage1安装glusterfs-server
[root@storage1 /]# systemctl start glusterd.service #启动服务
[root@storage1 /]# systemctl enable glusterd.service #设置开机自启动
[root@storage1 /]# mkdir /data #设置共享目录,建议把/data单独挂载一个分区,专门存储数据
#以上,安装glusterfs-server软件和创建共享目录需要再多个storage服务器中安装,安装之后就可以配置可信池了(即组群)
[root@storage1 /]# gluster peer probe 192.168.118.129 #在storage1服务器上把storage2拉进可信池(拉进群)
[root@storage1 /]# gluster peer probe 192.168.118.130 #在storage1服务器上把storage3拉进可信池(拉进群)
#可信池组好之后,可以开始创建卷,卷的类型有很多,这里简单创建分布式卷:
[root@storage1 /]# gluster volume create gv1 192.168.118.128:/data 192.168.118.129:/data 192.168.118.130:/data
volume create: gv1: success: please start the volume to access data
#创建分布式卷,不用写卷模式,默认就是分布式卷,卷名为gv1,有3个brick
[root@storage1 gv1]# gluster volume info
Volume Name: gv1 #卷名
Type: Distribute #分布式卷
Volume ID: 2d7a1f95-14e5-4362-823c-c961f6f3823a
Status: Created #卷的状态是已创建
Snapshot Count: 0
Number of Bricks: 3 #有3个存储块
Transport-type: tcp
Bricks:
Brick1: 192.168.118.128:/data
Brick2: 192.168.118.129:/data
Brick3: 192.168.118.130:/data
Options Reconfigured:
storage.fips-mode-rchecksum: on
transport.address-family: inet
nfs.disable: on
[root@storage1 gv1]# gluster volume start gv1 #启动分布式卷
2、客户端安装软件glusterfs glusterfs-fuse,创建挂载点、开始挂载远程的卷
[root@client1 ~]# yum install glusterfs glusterfs-fuse -y #客户端安装glusterfs glusterfs-fuse
[root@client1 ~]# mkdir /data
[root@client1 data]# mount.glusterfs 192.168.118.128:gv1 /data/ #客户端挂载分布式卷
[root@client1 data]# df -h #查看挂载的存储空间
Filesystem Size Used Avail Use% Mounted on
devtmpfs 475M 0 475M 0% /dev
tmpfs 487M 0 487M 0% /dev/shm
tmpfs 487M 7.7M 479M 2% /run
tmpfs 487M 0 487M 0% /sys/fs/cgroup
/dev/mapper/centos-root 6.2G 1.4G 4.9G 23% /
/dev/sda1 1014M 138M 877M 14% /boot
tmpfs 98M 0 98M 0% /run/user/0
192.168.118.128:/gv1 24G 0G 24G 100% /data #总空间就是3个存储块的总空间之和
[root@client1 data]# touch file{1..4} #创建4个文件
[root@client1 data]# dd if=/dev/zero of=/data/test bs=5M count=10 #再创建一个test文件
[root@storage1 /]# ls -lh /data/gv1/ #查看storage1,没有文件
total 0
[root@storage2 /]# ls -lh /data/gv1/ #查看storage2,有2个文件
-rw-r--r-- 2 root root 0 Jan 2 01:14 file3
-rw-r--r-- 2 root root 0 Jan 2 01:14 file4
[root@storage3 /]# ls -lh /data/gv1/ #查看storage3,有2个文件,可见,分布式卷随机存储文件
-rw-r--r-- 2 root root 0 Jan 2 01:14 file1
-rw-r--r-- 2 root root 0 Jan 2 01:14 file2
-rw-r--r-- 2 root root 50M Jan 2 01:13 test
glusterfs有很多不同的卷,如:分布式卷、复制卷、分散卷、分布式复制卷、分布式分散卷,更详细的卷类型介绍可以看官方文档,地址:https://docs.gluster.org/en/latest/Quick-Start-Guide/Architecture/