在当今数字化时代,游戏行业蓬勃发展,TapTap 作为一个热门的游戏平台,汇聚了大量丰富多样的游戏资源。今天,我将带大家详细了解一段 Python 代码,它能够从 TapTap 平台抓取热门游戏的相关信息,并将这些数据存储到数据库中。
结果展示(文末附完整代码):
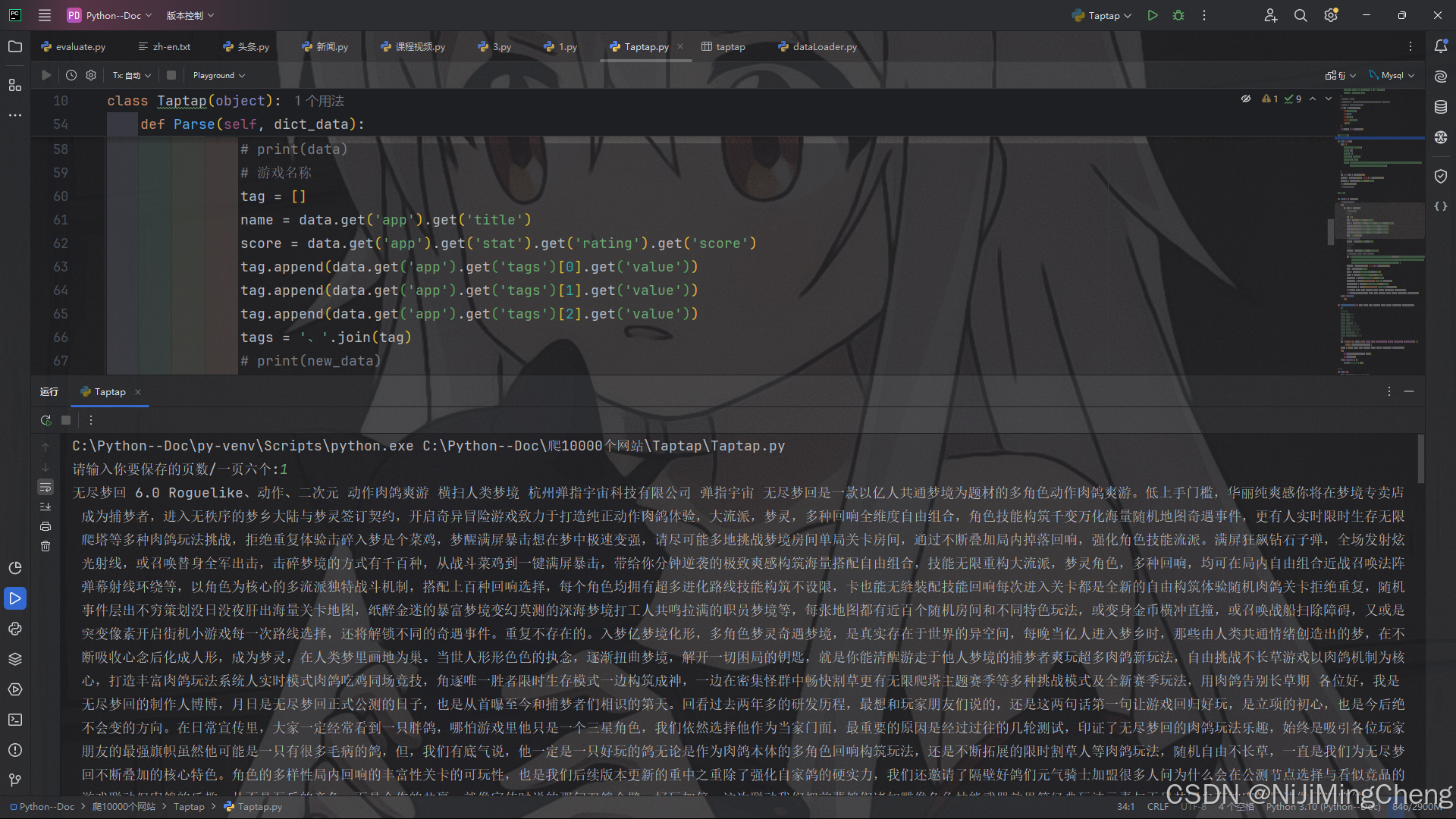
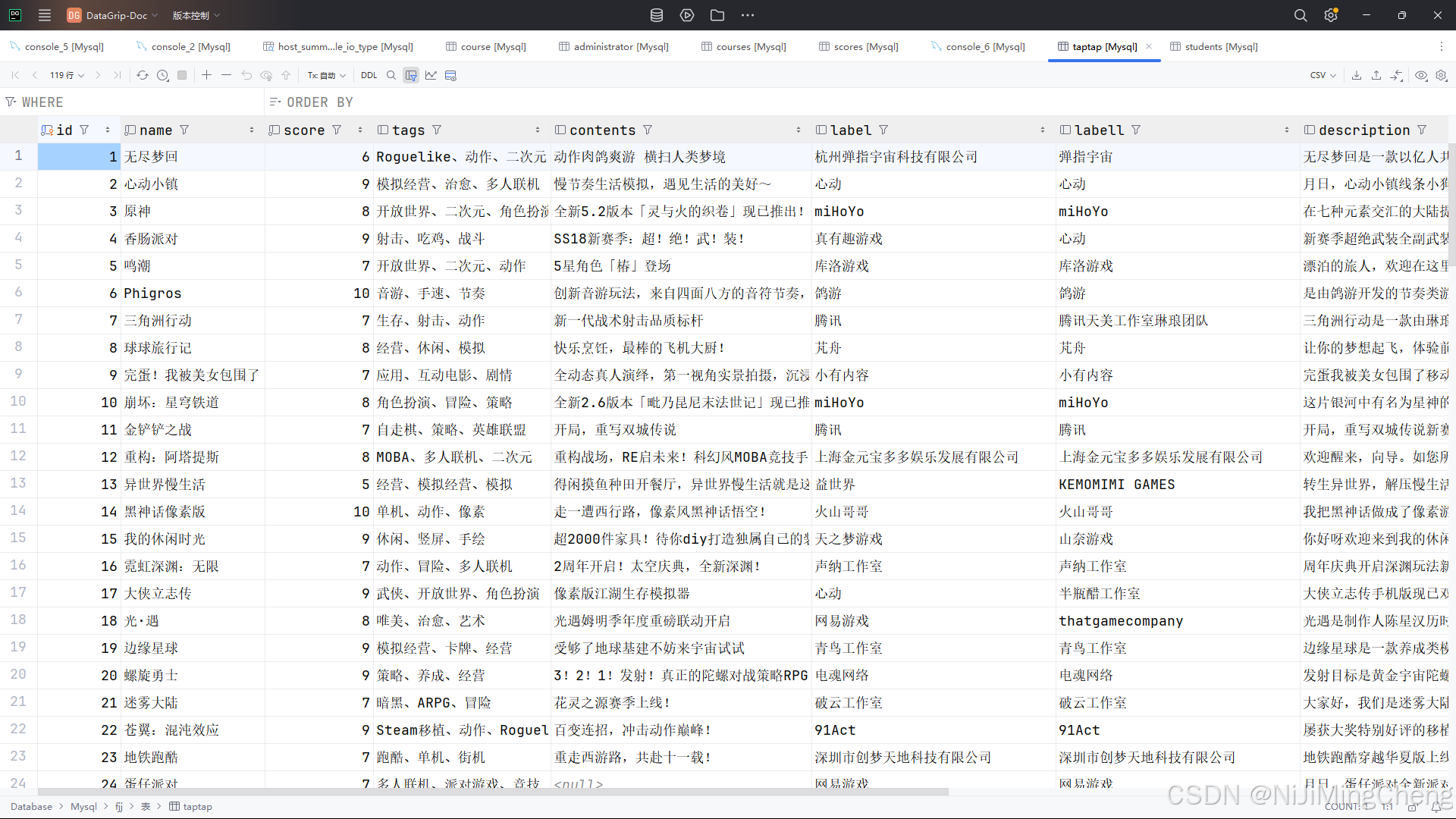
数据可视化:
目录
3. 数据插入数据库方法 (insert_data_to_db)
一、代码概述
这段代码定义了一个名为 Taptap 的类,它具备从 TapTap 平台获取热门游戏信息、解析这些信息以及将其插入到数据库的功能。整体代码结构清晰,通过几个主要的方法协同工作来完成整个任务流程。
1. 导入必要的库
代码开头部分导入了一些必要的 Python 库,这些库在后续的功能实现中起着关键作用:
import re
from urllib.parse import urlencode
import pymongo
import pymysql
import requests
re:用于正则表达式操作,在处理游戏描述和开发商备注等文本信息时,用来去除非中文字符、逗号和句号之外的其他字符。urlencode:来自urllib.parse模块,用于对请求参数进行编码,以便正确构建请求 URL。pymongo和pymysql:分别是用于连接 MongoDB 数据库和 MySQL 数据库的库,不过在当前代码中,虽然导入了pymongo,但实际使用的是pymysql来连接和操作数据库。requests:一个常用的 HTTP 库,用于发送 HTTP 请求并获取响应,在与 TapTap 平台的 API 进行交互时发挥重要作用。
2. 类的初始化方法 (__init__)
def __init__(self):
self.url = "https://www.taptap.cn/webapiv2/app-top/v2/hits?platform=android&type_name=hot&dataSource=Android" \
"&X-UA=V%3D1%26PN%3DWebApp%26LANG%3Dzh_CN%26VN_CODE%3D100%3D0.1.0&LOC=CN&PLT=PC&DS" \
"%3DAndroid&UID=4afcab35-865c-46df-9545-3e190b69d048&DT=PC&OS=Windows&OSV=15.0.0 "
self.headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/107.0.0.0 Safari/537.36 Edg/107.0.1418.42",
'referer': 'https: // www.taptap.cn / top / download',
'content - encoding': 'gzip'
}
# mongodb端口默认27017
# self.client = pymongo.MongoClient(host="localhost", port=27017)
# self.db = self.client['Tap']
self.db = pymysql.Connect(
host='127.0.0.1',
port=3306,
user='root',
password='921108',
db='fjj'
)
self.cursor = self.db.cursor()
在 __init__ 方法中,进行了以下初始化操作:
- 定义了
self.url,这是指向 TapTap 平台获取热门游戏列表的 API 端点的 URL,其中包含了一些固定的查询参数,用于指定平台、数据来源等信息。 - 设置了
self.headers,这是发送 HTTP 请求时的请求头信息,包括user-agent(模拟浏览器身份)、referer(表示请求的来源页面)和content - encoding(指定响应内容的编码方式)等,这些信息有助于使请求看起来更像是来自正常的浏览器访问,避免被服务器拒绝。 - 原本有连接 MongoDB 数据库的代码部分被注释掉了,实际连接的是 MySQL 数据库。通过
pymysql.Connect方法建立了与本地 MySQL 数据库的连接,指定了主机地址、端口、用户名、密码和数据库名等连接参数,并创建了一个游标对象self.cursor,用于后续执行 SQL 语句操作数据库。
二、主要内容解释
1. 获取数据方法 (Get)
def Get(self, num):
data = {
'dataSource': 'Android',
'from': num,
'limit': 10,
'platform': 'android',
'type_name': 'hot',
'X-UA': 'V=1&PN=WebApp&LANG=zh_CN&VN_CODE=100&VN=0.1.0&LOC=CN&PLT=PC&DS=Android&UID=4afcab35-865c-46df'
'-9545-3e190b69d048&DT=PC&OS=Windows&OSV=15.0.0',
}
url = self.url + urlencode(data)
response = requests.get(url, headers=self.headers).json()
dict_data = response.get('data').get('list')
self.Parse(dict_data)
# print(dict_data)
- 这个方法接受一个参数
num,用于指定从哪个位置开始获取游戏数据。它首先构建了一个包含查询参数的字典data,这些参数会进一步完善请求 URL,以获取特定范围的热门游戏列表数据。 - 通过
urlencode函数将参数字典编码后添加到self.url上,形成完整的请求 URL。然后使用requests.get方法发送 HTTP 请求,并将响应解析为 JSON 格式。 - 最后,从响应数据中提取出游戏列表信息
dict_data,并将其传递给Parse方法进行进一步的解析处理。
2. 数据解析方法 (Parse)
def Parse(self, dict_data):
try:
for data in dict_data:
tag = []
name = data.get('app').get('title')
score = data.get('app').get('stat').get('rating').get('score')
tag.append(data.get('app').get('tags')[0].get('value'))
tag.append(data.get('app').get('tags')[1].get('value'))
tag.append(data.get('app').get('tags')[2].get('value'))
tags = '、'.join(tag)
game_id = data.get('app').get('id')
contents = data.get('app').get('rec_text')
src = f'https://www.taptap.cn/webapiv2/app/v2/detail-by-id/{game_id}?X-UA=V%3D1&PN=WebApp&LANG=zh_CN' \
f'%26VN_CODE=100&VN=0.1.0&LOC=CN&PLT=PC&DS=Android&UID=4afcab35-865c-46df' \
f'-9545-3e190b69d048&DT=PC&OS=Windows&OSV=15.0.0str '
response = requests.get(src, headers=self.headers).json()
data = response.get('data')
label = data.get('developers')[0].get('name')
labell = data.get('developers')[-1].get('name')
description = data.get('description').get('text')
description = re.sub('[^\u4e00-\u9fa5,。]+', '', description)
developer_note = data.get('developer_note').get('text')
developer_note = re.sub('[^\u4e00-\u9fa5,。]+', '', developer_note)
print(name, score, tags, contents, label, labell, description, developer_note)
self.insert_data_to_db(name, score, tags, contents, label, labell, description, developer_note)
except Exception:
pass
- 在
Parse方法中,遍历传入的游戏列表数据dict_data。对于每个游戏,它提取了以下关键信息:- 游戏名称 (
name):从游戏数据的app部分获取title字段的值。 - 游戏评分 (
score):通过多层嵌套的字典获取方式,从app部分的stat中的rating里获取score字段的值。 - 游戏标签 (
tags):从app部分的tags列表中获取前三个标签的值,并使用、将它们连接成一个字符串。 - 游戏公告 (
contents):直接从app部分获取rec_text字段的值。 - 开发商名称(第一个和最后一个):通过再次发送请求到游戏详情页的 API,获取更详细的游戏数据,然后从
developers列表中分别获取第一个和最后一个开发商的名称,即label和labell。 - 游戏描述 (
description) 和开发商备注 (developer_note):同样从游戏详情页数据中获取相应文本内容,并使用正则表达式re.sub方法去除非中文字符、逗号和句号之外的其他字符,以清理文本数据。
- 游戏名称 (
- 最后,将提取到的所有信息传递给
insert_data_to_db方法,以便将这些数据插入到数据库中。
3. 数据插入数据库方法 (insert_data_to_db)
def insert_data_to_db(self, name, score, tags, contents, label, labell, description, developer_note):
sql = "INSERT into Taptap (name, score, tags, contents,label, labell, description, developer_node) " \
"values (%s,%s,%s,%s,%s,%s,%s,%s) "
params = [(name, score, tags, contents, label, labell, description, developer_note)]
try:
self.cursor.executemany(sql, params)
self.db.commit()
except Exception as e:
print(f"数据库插入操作出现错误: {e}")
- 这个方法接受一系列游戏相关的参数,包括游戏名称、评分、标签、公告、开发商名称、游戏描述和开发商备注等。
- 它首先构建了一个 SQL 插入语句
sql,用于将这些数据插入到名为Taptap的数据库表中。然后创建了一个包含所有参数值的元组列表params。 - 通过游标对象
self.cursor的executemany方法执行插入操作,并在操作成功后提交事务,确保数据真正被写入到数据库中。如果出现异常,会打印出错误信息。
4. 运行代码方法 (run)
def run(self):
page = int(input('请输入你要保存的页数/一页六个:'))
for number in range(0, page):
num = number * 10
self.Get(num)
run方法是整个程序的启动入口。它首先通过input函数获取用户输入的要保存的页数,然后在一个循环中,根据页数计算出每次获取数据的起始位置num(每页显示六个游戏,所以每次偏移量为10),并调用Get方法来获取相应页的游戏数据,从而实现了对多页热门游戏数据的连续获取和处理。
配置注意:
- 确保环境配置正确:
- 确保已经安装了代码中所使用的所有 Python 库,即
re、urllib.parse、pymongo(虽然未实际使用,但以防后续可能用到)、pymysql和requests。可以通过pip install命令来安装这些库,例如:pip install requests pymysql。 - 确认已经正确安装并启动了 MySQL 数据库,并且创建了名为
fjj的数据库,以及具有相应权限的用户(在代码中是root用户,密码为921108)。
- 确保已经安装了代码中所使用的所有 Python 库,即
- 运行代码:
- 将上述代码保存为一个
.py文件,比如taptap_spider.py。 - 在命令行中切换到保存代码文件的目录,然后执行以下命令运行代码:
python taptap_spider.py。 - 程序会提示你输入要保存的页数,输入一个整数后,代码就会开始从 TapTap 平台获取相应页数的热门游戏信息,并将其存储到 MySQL 数据库的
Taptap表中。
- 将上述代码保存为一个
四、总结
完整代码:
# -*- coding:utf-8 -*-
import re
from urllib.parse import urlencode
import pymongo
import pymysql
import requests
class Taptap(object):
def __init__(self):
self.url = "https://www.taptap.cn/webapiv2/app-top/v2/hits?platform=android&type_name=hot&dataSource=Android" \
"&X-UA=V%3D1%26PN%3DWebApp%26LANG%3Dzh_CN%26VN_CODE%3D100%26VN%3D0.1.0%26LOC%3DCN%26PLT%3DPC%26DS" \
"%3DAndroid%26UID%3D4afcab35-865c-46df-9545-3e190b69d048%26DT%3DPC%26OS%3DWindows%26OSV%3D15.0.0 "
self.headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/107.0.0.0 Safari/537.36 Edg/107.0.1418.42",
'referer': 'https: // www.taptap.cn / top / download',
'content - encoding': 'gzip'
}
# mongodb端口默认27017
# self.client = pymongo.MongoClient(host="localhost", port=27017)
# self.db = self.client['Tap']
self.db = pymysql.Connect(
host='127.0.0.1',
port=3306,
user='root',
password='921108',
db='fjj'
)
self.cursor = self.db.cursor()
"""发起请求并获取数据"""
def Get(self, num):
data = {
'dataSource': 'Android',
'from': num,
'limit': 10,
'platform': 'android',
'type_name': 'hot',
'X-UA': 'V=1&PN=WebApp&LANG=zh_CN&VN_CODE=100&VN=0.1.0&LOC=CN&PLT=PC&DS=Android&UID=4afcab35-865c-46df'
'-9545-3e190b69d048&DT=PC&OS=Windows&OSV=15.0.0',
}
url = self.url + urlencode(data)
response = requests.get(url, headers=self.headers).json()
dict_data = response.get('data').get('list')
self.Parse(dict_data)
# print(dict_data)
"""数据解析"""
def Parse(self, dict_data):
# print(dict_data)
try:
for data in dict_data:
# print(data)
# 游戏名称
tag = []
name = data.get('app').get('title')
score = data.get('app').get('stat').get('rating').get('score')
tag.append(data.get('app').get('tags')[0].get('value'))
tag.append(data.get('app').get('tags')[1].get('value'))
tag.append(data.get('app').get('tags')[2].get('value'))
tags = '、'.join(tag)
# print(new_data)
game_id = data.get('app').get('id')
# 游戏详情页链接
# 游戏公告
contents = data.get('app').get('rec_text')
# print(name, score, tags, contents)
src = f'https://www.taptap.cn/webapiv2/app/v2/detail-by-id/{game_id}?X-UA=V%3D1%26PN%3DWebApp%26LANG%3Dzh_CN' \
f'%26VN_CODE%3D100%26VN%3D0.1.0%26LOC%3DCN%26PLT%3DPC%26DS%3DAndroid%26UID%3D4afcab35-865c-46df' \
f'-9545-3e190b69d048%26DT%3DPC%26OS%3DWindows%26OSV%3D15.0.0str '
response = requests.get(src, headers=self.headers).json()
data = response.get('data')
label = data.get('developers')[0].get('name')
labell = data.get('developers')[-1].get('name')
description = data.get('description').get('text')
description = re.sub('[^\u4e00-\u9fa5,。]+', '', description)
developer_note = data.get('developer_note').get('text')
developer_note = re.sub('[^\u4e00-\u9fa5,。]+', '', developer_note)
print(name, score, tags, contents, label, labell, description, developer_note)
self.insert_data_to_db(name, score, tags, contents, label, labell, description, developer_note)
except Exception:
pass
def insert_data_to_db(self, name, score, tags, contents, label, labell, description, developer_note):
"""
将数据插入到数据库中
:param name: 游戏名称
:param score: 游戏评分
:param tags: 游戏标签
:param contents: 游戏公告
:param label: 开发商名称(第一个)
:param labell: 开发商名称(最后一个)
:param description: 游戏描述
:param developer_note: 开发商备注
"""
sql = "INSERT into Taptap (name, score, tags, contents,label, labell, description, developer_note) " \
"values (%s,%s,%s,%s,%s,%s,%s,%s) "
params = [(name, score, tags, contents, label, labell, description, developer_note)]
try:
self.cursor.executemany(sql, params)
self.db.commit()
except Exception as e:
print(f"数据库插入操作出现错误: {e}")
# 运行代码
def run(self):
page = int(input('请输入你要保存的页数/一页六个:'))
for number in range(0, page):
num = number * 10
self.Get(num)
if __name__ == '__main__':
spider = Taptap()
spider.run()
通过以上详细的介绍,我们了解了这段 Python 代码是如何实现从 TapTap 平台获取热门游戏信息并存储到数据库中的功能的。它涵盖了网络请求、数据解析、数据库操作等多个方面的知识和技巧,希望这篇教程能够帮助你更好地理解和运用类似的代码来满足自己的数据获取和存储需求。如果你在运行过程中遇到任何问题,欢迎随时在评论区留言提问哦!
请注意,在实际使用中,如果涉及到对网站数据的获取,需要确保遵守相关网站的使用条款和法律法规,避免未经授权的访问和数据滥用等问题,本文仅供交流学习,请勿滥用。