大家好啊!我是NiJiMingCheng
我的博客:NiJiMingCheng
上一节我们分享了正则表达式的内容,这一节我们来实战,这一节我们主要学习爬取上海软科中国大学排名并使用正则来解析文本内容,写的有点冗余,仅供学习交流,加油。

结果展示(文末附源码):

目录
一、引言
在日常的数据分析以及网页数据抓取等工作中,我们常常需要从网页中获取特定格式的数据,并进行一系列的处理和信息提取操作。今天我们就来深入分析一段 Python 代码,看看它是如何完成从指定网页获取数据、对数据进行清洗加工以及提取关键信息的过程的。
二、代码整体结构概述
这段 Python 代码定义了一个名为DataProcessor的类,主要用于处理来自特定网页的数据。下面我们逐步来看类中的各个方法以及它们的作用。
打开软科中国大学排名,观察这个页面结构复杂且一页只显示了 30 所大学。
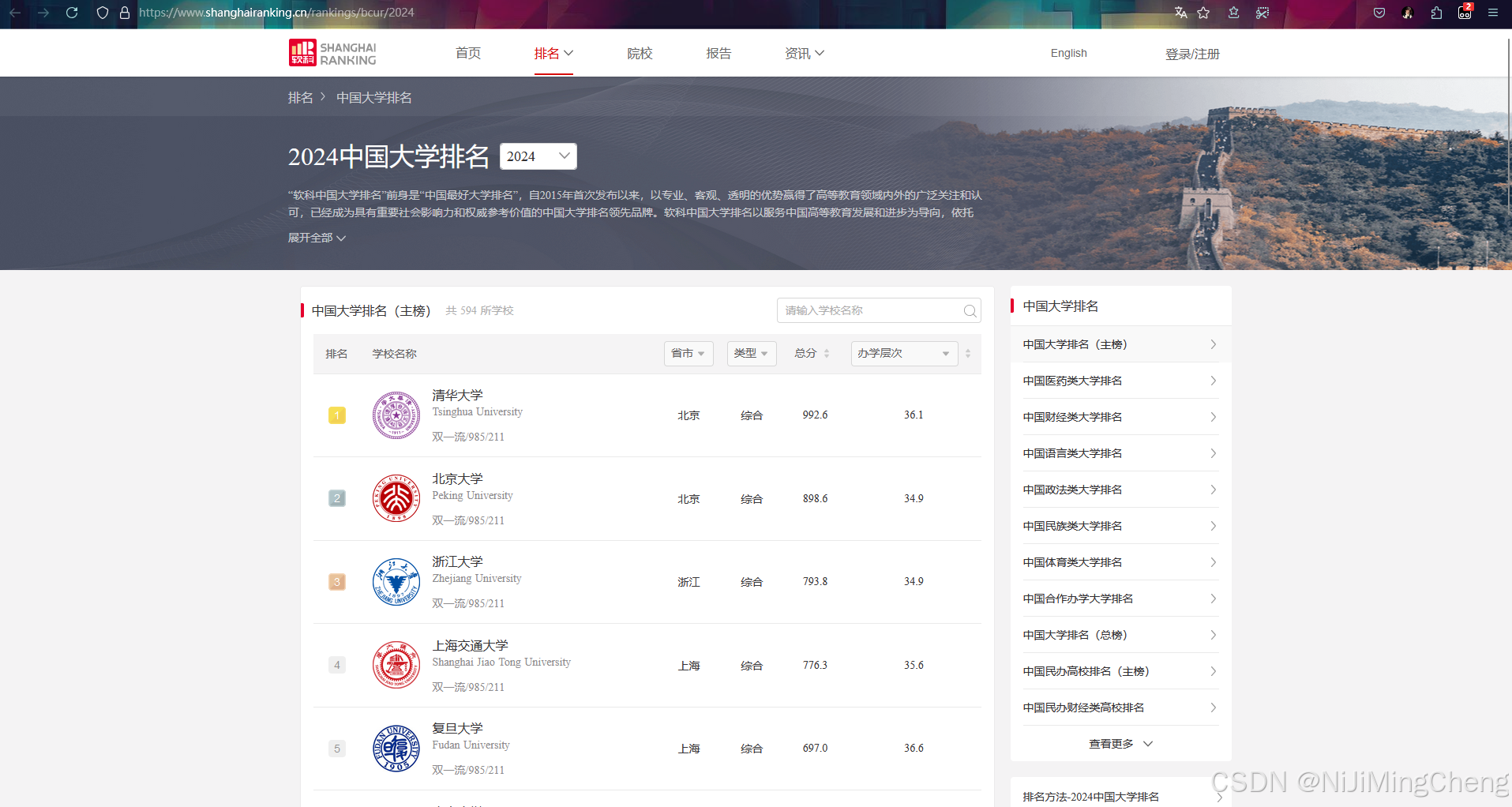
而且点击了翻页,发现 url 没有发生变化,说明该页面有可能是已经获取了所有数据,然后使用 JavaScript 动态生成。此时可能就很麻烦了,因为没有办法通过 get 传参的方式来切换网页进行爬取。
查看(XHR)内容发现并没有数据信息跟大学有关,当我们搜索关键字是发现一个很可疑的JS文件,点开后我们发现里面有信息。
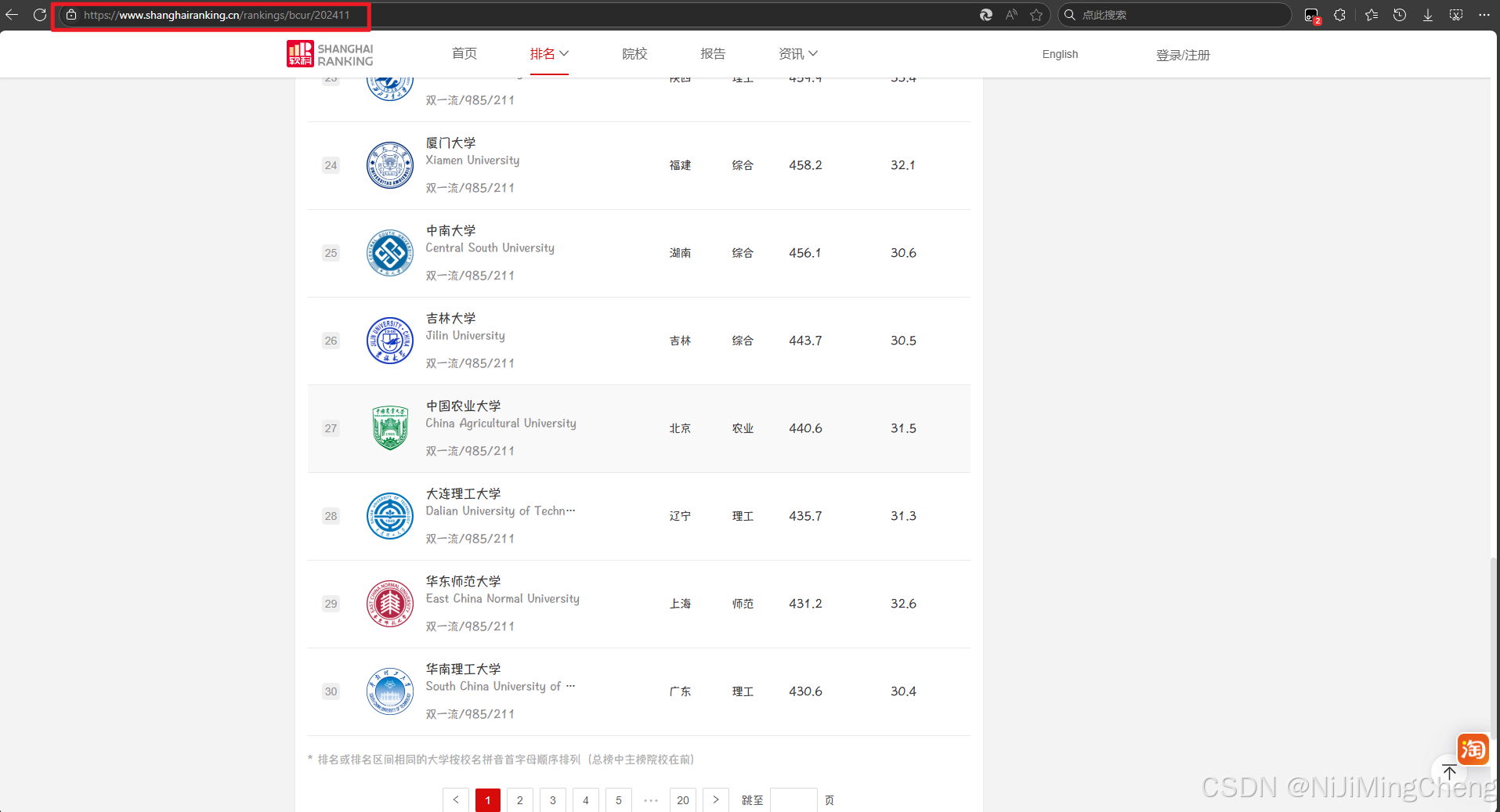


可以看到在 univData 中出现了清华大学和其他大学的参数,说明这个 JavaScript 文件保存了所有大学的信息。
访问“payload.js”文件资源,可以看到这些数据确实存在此处,所以这就是我们要爬虫的对象。
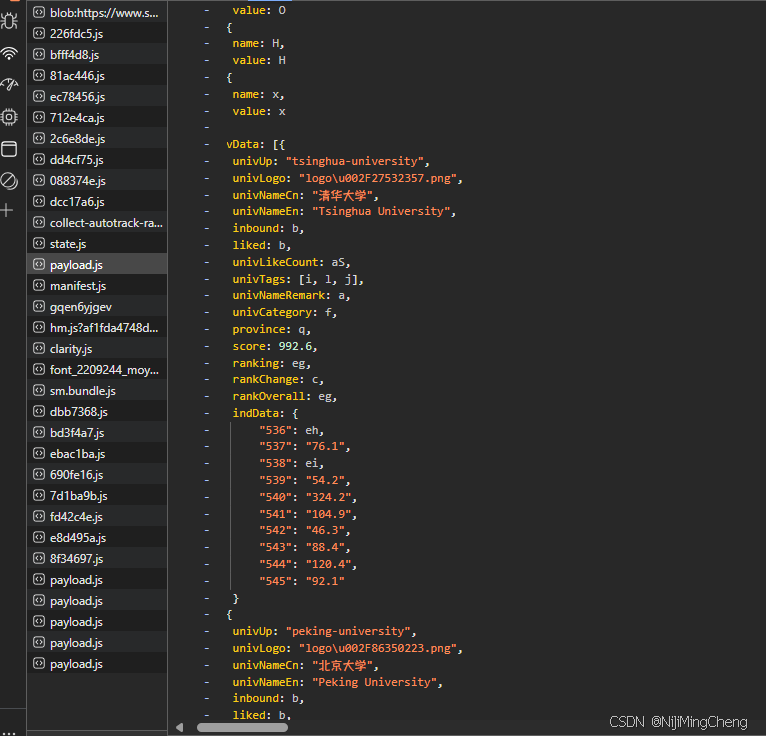
接下来我们将JS代码下载进行数据处理:
https://www.shanghairanking.cn/_nuxt/static/1735093903/rankings/bcur/202411/payload.js
三、代码部分解析
1、__init__方法解析
def __init__(self):
# 初始化请求头和 cookies
self.url = "https://www.shanghairanking.cn/_nuxt/static/1735093903/rankings/bcur/2020/payload.js"
self.text = None
self.con = download.get_inList(self.url)
self.item = {}
# 存储格式化模板,根据你的字段数量调整格式
# self.tplt = "{0:^5} {1:^10} {2:^5} {3:^10} {4:^10}\t{5:^10}\t{6:^10}\t{7:^10}\t{8:^10}\t{9:^10}\t{10:^10}\t{11:^10}\t{12:^10}\t{13:^10}\t{14:^10}\t{15:^10}"
__init__方法作为类的构造函数,在这里它首先定义了要获取数据的目标url,也就是上海排名网站相关的一个js文件地址,这个文件大概率包含了后续要处理的数据。- 初始化了
self.text为None,它后续会用于存储从网页获取到的文本内容。 - 通过
download.get_inList(self.url)获取了一些内容赋值给self.con(不过这里download模块的具体实现我们不清楚,推测是和获取数据列表相关的操作)。 - 初始化了一个空字典
self.item,从后面的代码来看,它主要是用于存储处理后的数据键值对。 - 还有一个被注释掉的
self.tplt,看格式应该是用于格式化输出数据的模板。
2、fetch_data方法解析
def fetch_data(self):
try:
# 发送请求获取数据
self.text = requests.get(self.url).text
except requests.RequestException as e:
print(f"获取数据时发生错误: {e}")- 这个方法的核心功能就是向之前在
__init__中定义的url发送HTTP GET请求,使用requests库来获取该网页对应的文本内容,并将其赋值给self.text变量,这样后续的操作就可以基于获取到的原始文本数据来进行了。 - 代码中注释掉的部分原本可能是用于从本地的
JSON文件indList.json中加载数据到self.con,而不是通过download.get_inList(self.url)获取,也许是提供了一种可选的数据获取方式。
3、remove_commas_in_quotes方法解析
def remove_commas_in_quotes(self, text):
def replace_commas(match):
# 替换逗号为顿号
return match.group(0).replace(',', '、')
# 编译正则表达式,匹配双引号内的内容
pattern = re.compile(r'"([^"]*)"')
# 使用 re.sub 替换匹配到的内容
result = re.sub(pattern, replace_commas, text)
return result
- 这是一个用于处理文本的辅助方法,它接受一个文本参数
text。 - 其目的是通过正则表达式
r'"([^"]*)"'来匹配文本中双引号内的内容,然后在匹配到的这些内容里,将逗号(,)替换成顿号(、),最后返回处理后的文本结果。例如如果文本中有"abc,def"这样在双引号内含逗号的内容,经过这个方法处理后就会变成"abc、def"。
4、process_text方法解析
def process_text(self):
# 正则获取键
pattern = re.compile(r'function\((.*?)\)\s*{\s*return')
# 获取值
p = re.search(r'"",false(.*?)"大学"', self.text)
matches = pattern.search(self.text)
value_ = (p.group(0).replace("'", '"'))
resp = self.remove_commas_in_quotes(value_)
value_list = resp.replace('"', '').split(',')
key_list = matches.group(1).split(',')
# 创建键值对字典
for i in range(0, len(value_list)):
self.item[key_list[i]] = value_list[i]
- 该方法主要用于从获取到的文本数据(
self.text)中提取键值对信息来构建字典self.item。 - 首先通过两个不同的正则表达式分别获取键(通过
function(.*?)\s*{\s*return这个模式匹配函数参数部分作为键)和值(通过"",false(.*?)"大学"模式获取相关值部分的文本)。 - 然后对获取到的值部分进行处理,比如调用
remove_commas_in_quotes方法处理逗号,去除双引号后再按照逗号分割成列表,同时键部分也分割成列表,最后通过循环将键值对应地存入self.item字典中。
5、replace_keys方法解析
def replace_keys(self, match):
key = match.group(0)
value = self.item.get(key)
if value is not None:
return str(value)
return key
- 这是一个辅助方法,用于在后续文本替换过程中发挥作用。它接收一个匹配对象
match,获取匹配到的键(也就是文本中的某个字符串,被当作键来处理),然后尝试从self.item字典中查找对应的键值,如果找到了就返回对应的值(转成字符串类型),如果没找到就返回原来的键本身。
6、replace_text_keys方法解析
def replace_text_keys(self):
# 定义正则表达式模式来匹配键(假设键符合标识符格式)
pattern = re.compile(r'(?<!\w)(?:\b([a-zA-Z0-9_]+)\b(?=[:,\]}])|(?<=[:{])[a-zA-Z]+\$(?=,|}|$))(?!\w)')
# 使用正则表达式替换文本中的键
replaced_text = pattern.sub(self.replace_keys, self.text)
return replaced_text
- 这个方法的目标是在原始文本数据(
self.text)中查找符合特定正则表达式模式定义的键,并通过调用replace_keys方法将其替换成对应的值(如果存在于self.item字典中),最后返回替换后的文本内容,达到更新文本中关键标识符对应实际值的效果。
7、process_ind_data方法解析
def process_ind_data(self, text):
def replace_commas(match):
pattern = re.compile(r'(-?\d+\.?\d*)')
def replace_keys(match):
key = match.group(0)
value = self.con.get(key)
if value is not None:
return str(value)
return key
# 使用正则表达式替换文本中的键
replaced_text = pattern.sub(replace_keys, match.group(0))
return replaced_text
# 修改匹配规则,匹配大括号里面的内容
pattern = re.compile(r'indData:\{(.*?)}')
result = re.sub(pattern, replace_commas, text)
return result
- 此方法用于处理文本中特定格式(
indData:{...}大括号内的内容)的数据。 - 内部定义了嵌套的函数来处理数字键(通过
(-?\d+\.?\d*)正则匹配数字),尝试从self.con中获取对应的值进行替换,最后整体通过re.sub对匹配到的大括号内内容按照这个规则进行替换,并返回处理后的结果文本。
8、extract_information方法解析
def extract_information(self, text):
item_str = re.findall(
r'{univUp:(.*?),univLogo:(.*?),univNameCn:(.*?),univNameEn:(.*?),inbound:(.*?),liked:(.*?),univLikeCount:(.*?),univTags:(.*?),univNameRemark:(.*?),univCategory:(.*?),province:(.*?),score:(.*?),ranking:(.*?),rankChange:(.*?),rankOverall:(.*?),indData:(.*?)},',
text)
for item in item_str:
information = {
'ranking': item[12],
'univNameCn': item[2],
'univNameEn': item[3],
'province': item[10],
'univTags': item[7],
'univCategory': item[9],
'score': item[11],
'indData': item[15],
'univUp': item[0],
'univLogo': item[1],
'inbound': item[4],
'liked': item[5],
'univLikeCount': item[6],
'univNameRemark': item[8],
'rankChange': item[13],
'rankOverall': item[14],
}
print(information)- 这个方法的主要作用是从处理后的文本数据中提取出关键的信息并整理成字典形式。
- 通过复杂的正则表达式
r'{univUp:(.*?),univLogo:(.*?),univNameCn:(.*?),univNameEn:(.*?),inbound:(.*?),liked:(.*?),univLikeCount:(.*?),univTags:(.*?),univNameRemark:(.*?),univCategory:(.*?),province:(.*?),score:(.*?),ranking:(.*?),rankChange:(.*?),rankOverall:(.*?),indData:(.*?)},'来查找符合特定格式的信息块,然后将每个信息块中的各部分内容提取出来,按照对应的字段名存入字典information中,并打印输出这个字典(原本还可以按照之前定义的tplt模板进行格式化输出,但目前那部分代码是注释掉的状态)。
四、主函数__main__部分解析
if __name__ == "__main__":
processor = DataProcessor()
processor.fetch_data()
processor.process_text()
replaced_text = processor.replace_text_keys()
processed_text = processor.process_ind_data(replaced_text)
processor.extract_information(processed_text)
- 在
__main__代码块中,首先实例化了DataProcessor类,创建了一个processor对象。 - 然后依次调用类中的各个方法,先是通过
fetch_data获取网页数据,接着用process_text处理文本提取键值对,再通过replace_text_keys和process_ind_data进一步对文本进行替换和处理,最后使用extract_information方法从最终处理好的文本中提取关键信息并输出,整体完成了从数据获取到信息提取展示的一整套流程。
五、总结
完整代码(DataProcess.py):
# -*- coding:utf-8 -*-
import re
import requests
import download
class DataProcessor:
def __init__(self):
# 初始化请求头和 cookies
self.url = "https://www.shanghairanking.cn/_nuxt/static/1735093903/rankings/bcur/2024/payload.js"
self.text = None
self.con = download.get_inList(self.url)
self.item = {}
# 存储格式化模板,根据你的字段数量调整格式
# self.tplt = "{0:^5} {1:^10} {2:^5} {3:^10} {4:^10}\t{5:^10}\t{6:^10}\t{7:^10}\t{8:^10}\t{9:^10}\t{10:^10}\t{11:^10}\t{12:^10}\t{13:^10}\t{14:^10}\t{15:^10}"
def fetch_data(self):
try:
# 发送请求获取数据
self.text = requests.get(self.url).text
except requests.RequestException as e:
print(f"获取数据时发生错误: {e}")
def remove_commas_in_quotes(self, text):
def replace_commas(match):
# 替换逗号为顿号
return match.group(0).replace(',', '、')
# 编译正则表达式,匹配双引号内的内容
pattern = re.compile(r'"([^"]*)"')
# 使用 re.sub 替换匹配到的内容
result = re.sub(pattern, replace_commas, text)
return result
def process_text(self):
# 正则获取键
pattern = re.compile(r'function\((.*?)\)\s*{\s*return')
# 获取值
p = re.search(r'"",false(.*?)"大学"', self.text)
matches = pattern.search(self.text)
value_ = (p.group(0).replace("'", '"'))
resp = self.remove_commas_in_quotes(value_)
value_list = resp.replace('"', '').split(',')
key_list = matches.group(1).split(',')
# 创建键值对字典
for i in range(0, len(value_list)):
self.item[key_list[i]] = value_list[i]
def replace_keys(self, match):
key = match.group(0)
value = self.item.get(key)
if value is not None:
return str(value)
return key
def replace_text_keys(self):
# 定义正则表达式模式来匹配键(假设键符合标识符格式)
pattern = re.compile(r'(?<!\w)(?:\b([a-zA-Z0-9_]+)\b(?=[:,\]}])|(?<=[:{])[a-zA-Z]+\$(?=,|}|$))(?!\w)')
# 使用正则表达式替换文本中的键
replaced_text = pattern.sub(self.replace_keys, self.text)
return replaced_text
def process_ind_data(self, text):
def replace_commas(match):
pattern = re.compile(r'(-?\d+\.?\d*)')
def replace_keys(match):
key = match.group(0)
value = self.con.get(key)
if value is not None:
return str(value)
return key
# 使用正则表达式替换文本中的键
replaced_text = pattern.sub(replace_keys, match.group(0))
return replaced_text
# 修改匹配规则,匹配大括号里面的内容
pattern = re.compile(r'indData:\{(.*?)}')
result = re.sub(pattern, replace_commas, text)
return result
def extract_information(self, text):
item_str = re.findall(
r'{univUp:(.*?),univLogo:(.*?),univNameCn:(.*?),univNameEn:(.*?),inbound:(.*?),liked:(.*?),univLikeCount:(.*?),univTags:(.*?),univNameRemark:(.*?),univCategory:(.*?),province:(.*?),score:(.*?),ranking:(.*?),rankChange:(.*?),rankOverall:(.*?),indData:(.*?)},',
text)
for item in item_str:
information = {
'ranking': item[12],
'univNameCn': item[2],
'univNameEn': item[3],
'province': item[10],
'univTags': item[7],
'univCategory': item[9],
'score': item[11],
'indData': item[15],
'univUp': item[0],
'univLogo': item[1],
'inbound': item[4],
'liked': item[5],
'univLikeCount': item[6],
'univNameRemark': item[8],
'rankChange': item[13],
'rankOverall': item[14],
}
print(information)
# # 按照 tplt 模板格式化输出信息
# print(self.tplt.format(
# information.get('ranking', ''),
# information.get('univNameCn', ''),
# information.get('univNameEn', ''),
# information.get('province', ''),
# information.get('univTags', ''),
# information.get('univCategory', ''),
# information.get('score', ''),
# information.get('indData', ''),
# information.get('univUp', ''),
# information.get('univLogo', ''),
# information.get('inbound', ''),
# information.get('liked', ''),
# information.get('univLikeCount', ''),
# information.get('univNameRemark', ''),
# information.get('rankChange', ''),
# information.get('rankOverall', '')
# ))
if __name__ == "__main__":
processor = DataProcessor()
processor.fetch_data()
processor.process_text()
replaced_text = processor.replace_text_keys()
processed_text = processor.process_ind_data(replaced_text)
processor.extract_information(processed_text)Download.py
# -*- coding:utf-8 -*-
import requests
import re
import json
def remove_commas_in_quotes(text):
def replace_commas(match):
return match.group(0).replace(',', '、')
pattern = re.compile(r'"([^"]*)"')
result = re.sub(pattern, replace_commas, text)
return result
def get_inList(url):
try:
# 发送请求获取网页的文本内容
text = requests.get(url).text
except requests.RequestException as e:
print(f"请求失败:{e}")
return None
# 定义一个正则表达式模式,用于匹配函数的参数部分
pattern = re.compile(r'function\((.*?)\)\s*{\s*return')
# 另一个正则表达式模式,用于查找特定的内容,这里看起来是查找包含 "大学" 关键字的部分
p = re.search(r'"",false(.*?)"大学"', text)
# 在文本中搜索第一个模式
matches = pattern.search(text)
if not p or not matches:
print("未找到预期内容")
return None
# 对搜索到的 p 组的内容进行处理,将单引号替换为双引号
value_ = (p.group(0).replace("'", '"'))
# 调用 remove_commas_in_quotes 函数处理 value_
resp = remove_commas_in_quotes(value_)
# 将处理后的字符串去掉双引号,并按逗号分割成列表
value_list = resp.replace('"', '').split(',')
# 将 matches 组的内容按逗号分割成列表
key_list = matches.group(1).split(',')
item = {}
# 将键值对存储到 item 字典中
for i in range(0, len(value_list)):
item[key_list[i]] = value_list[i]
# 定义一个新的正则表达式模式,用于匹配 indList 部分
patterns = r'indList:\s*(\[.*?\],\s*indId:)'
# 在文本中搜索这个模式
match_ = re.search(patterns, text, re.DOTALL)
if not match_:
print("未找到 indList 部分")
return None
def replace_keys(match):
# 获取匹配到的键
key = match.group(0)
# 从 item 字典中查找键对应的值
value = item.get(key)
if value is not None:
# 如果找到,将键替换为其对应的值
return str(value)
# 如果未找到,保持键不变
return key
# 获取匹配到的完整内容(包含 univData 列表及后面的 indList:)
matched_content = match_.group(0)
# 去掉匹配内容中的 ",indId:" 部分
univ_data_str = matched_content.replace(",indId:", "")
# 定义一个新的正则表达式模式,用于匹配标识符,这里看起来是用于替换键
pattern_ = re.compile(r'(?<!\w)(?:\b([a-zA-Z0-9_]+)\b(?=[:,\]}])|(?<=[:{])[a-zA-Z]+\$(?=,|}|$))(?!\w)')
# 使用正则表达式替换文本中的键
replaced_text = re.sub(pattern_, replace_keys, text)
# 查找匹配的模式,提取一些代码、中文名称、权重等信息
indlist = re.findall(r'{code:(.*?),nameCn:(.*?),weight:(.*?),(.*?):(.*?)}', replaced_text)
j = {}
for i in indlist:
# 将结果存储到字典 j 中,将键和值的双引号去掉
j[i[0].replace('"', '')] = i[1].replace('"', '')
# 返回存储结果的字典 j
return j
if __name__ == "__main__":
url = "https://www.shanghairanking.cn/_nuxt/static/1735093903/rankings/bcur/2020/payload.js"
result = get_inList(url)
if result:
print(result)希望这篇博客文章能帮助大家更好地理解这段代码的逻辑和功能,欢迎大家一起交流探讨相关的数据处理技巧和 Python 编程经验。
你可以根据实际情况对文章内容进行调整和修改,比如添加更多示例、更详细的代码运行效果展示等,让博客文章更丰富完善。 同时,如果代码中的download等外部依赖模块有更详细的信息,也可以进一步补充到文章中去更好地解释整体流程。
注意:
请注意,在实际使用中,如果涉及到对网站数据的获取,需要确保遵守相关网站的使用条款和法律法规,避免未经授权的访问和数据滥用等问题,本文仅供交流学习,请勿滥用。