文章目录
Hadoop的MapReduce详解
一、引言
MapReduce是一个由Google提出并实现的软件框架,用于大规模数据集(大于1TB)的并行计算。在Hadoop项目中,MapReduce被用来进行分布式数据处理。它将任务分为Map阶段和Reduce阶段,Map阶段负责处理输入数据并产生中间结果,Reduce阶段则对Map阶段的中间结果进行汇总以得到最终结果。
二、MapReduce的核心概念
1、Map阶段
Map阶段是MapReduce框架中的第一个阶段,它的主要任务是处理输入数据并生成中间结果。Map函数接收输入的键值对,并产生一组中间键值对,这些中间结果会被框架自动收集并传递给Reduce阶段。
1.1、Map函数的实现
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
在上述代码中,Mapper类继承自org.apache.hadoop.mapreduce.Mapper类,map方法接收输入的文本行,并将其分割成单词,每个单词作为键,对应的值固定为1。
2、Reduce阶段
Reduce阶段是MapReduce框架中的第二个阶段,它接收来自Map阶段的中间结果,并进行汇总处理,最终输出计算结果。
2.1、Reduce函数的实现
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
在上述代码中,Reducer类继承自org.apache.hadoop.mapreduce.Reducer类,reduce方法接收相同的键和该键对应的所有值的集合,计算这些值的总和,并将结果输出。
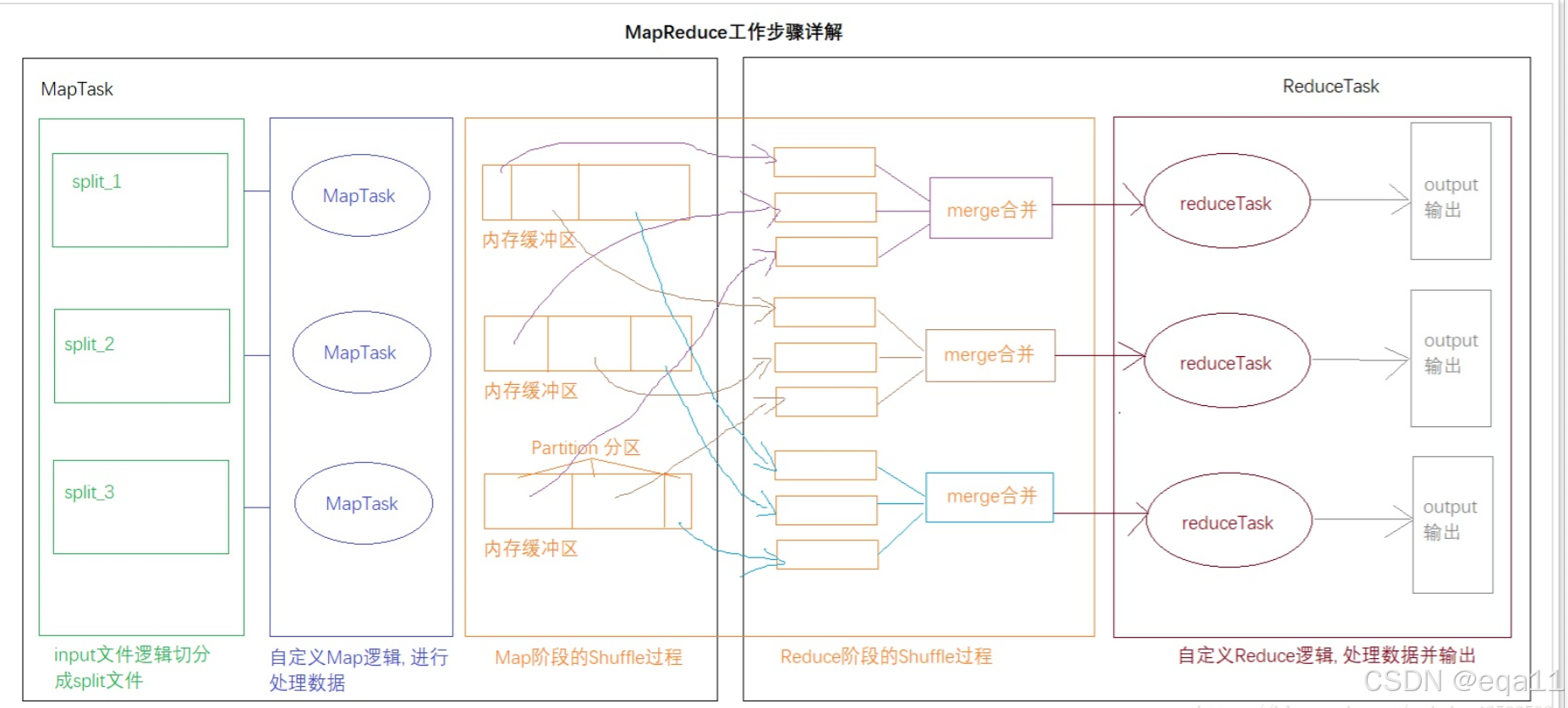
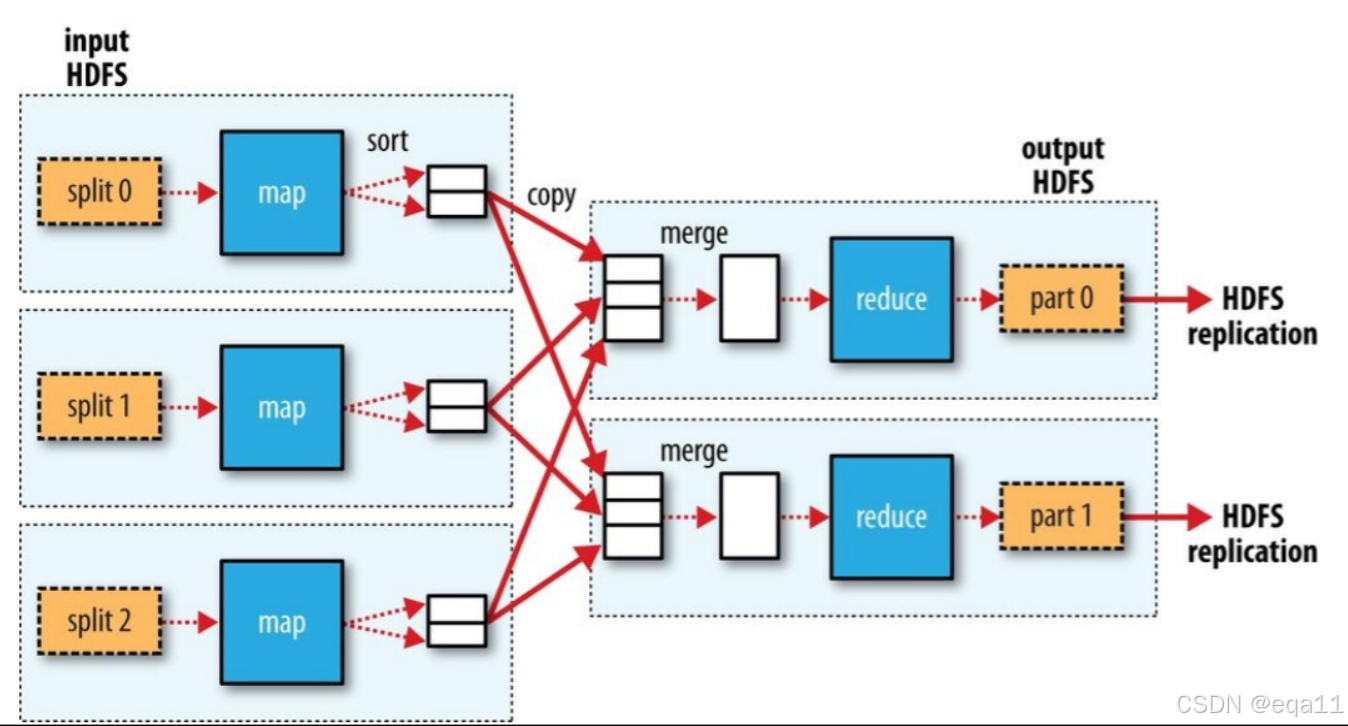
三、MapReduce的执行流程
MapReduce的执行流程大致可以分为以下几个步骤:
- 输入分片:Hadoop将输入数据切分成多个数据块,并为每个数据块分配一个Map任务。
- Map任务执行:每个Map任务对分配到的数据块进行处理,并产生中间结果。
- Shuffle和Sort:Map任务产生的中间结果被Shuffle(重新分配)和Sort(排序)。
- Reduce任务执行:Reduce任务对排序后的中间结果进行处理,并输出最终结果。
- 输出结果:Reduce任务的输出结果被写入到HDFS中。
四、MapReduce的使用实例
Word Count示例
Word Count是MapReduce中的经典应用之一,其主要任务是统计文本文件中每个单词出现的次数。以下是Word Count的实现步骤和代码示例:
1. Mapper类
Mapper类负责读取输入的文本行,并将其分割成单词,然后输出键值对,其中键是单词,值是1。
public class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
2. Reducer类
Reducer类接收相同的键和该键对应的所有值的集合,计算这些值的总和,并将结果输出。
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
3. 执行Word Count
执行Word Count的命令如下:
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.4.jar wordcount input.txt output
这里input.txt是输入文件,output是输出目录。执行后,输出目录中会包含处理结果,通常包括_SUCCESS和part-r-00000两个文件,其中part-r-00000包含了最终的单词计数结果。
五、总结
MapReduce是一种强大的分布式数据处理框架,它通过将复杂的数据处理任务分解为简单的Map和Reduce操作,使得对大规模数据集的处理变得简单和高效。理解MapReduce的工作原理和核心概念对于大数据处理领域的开发者来说至关重要。
版权声明:本博客内容为原创,转载请保留原文链接及作者信息。
参考文章: