本篇的主题围绕着内存管理进行展开。首先编写了内存容量获取的程序,接下来详细讲解了内存管理的具体内容,以及两种实现内存管理的方式。
1. 内存容量获取
前面已经实现了访问内存的扩展,能够使用的内存大大增加了。但是不同的应用程序在运行时,对内存的使用会有不同的要求,这就需要操作系统实现一个内存管理的功能,以确保各个应用程序都能够正常运行。
管理内存的第一步,当然是先要了解内存有多少,地址范围是哪里。内存相关的信息可以从BIOS获取,但不同的版本BIOS调用方式可能不同,因此这里作者决定自行开发程序去检查内存。
检查内存之前还需要先讲解一下CPU高速缓存(cache)的功能。
由于CPU的寄存器容量太小,而频繁从内存读写又会严重影响CPU的处理速度,考虑到这些,英特尔的CPU开发者们在CPU中增加了一些存储空间,被称为高速缓冲存储器(cache memory)。这一部分存储的读写速度能够跟得上CPU的处理速度,但是由于芯片造价太高,这部分的存储相比内存来说仍然很小,比如128KB。而这部分高速缓存是这样使用的:每次访问内存,都将所访问的内存地址和内容存入高速缓存。这样下次再读取内存时,先从高速缓存中查找,找到了之后就立即返回;同理,写入内存时,如果直接写入内存,在等待内存写入期间,CPU处于空闲状态。所以先写入高速缓存,缓存控制电路再配合内存的速度慢慢发送内存写入命令。
另外程序中遇到循环的地方也不少。比如for循环中,会多次改变循环变量i的值,即多次更改同一个内存地址的值。如果每一次更改都直接访问内存,很明显会拖慢CPU的处理速度。因此中间的过程都尽量在缓存中进行处理,到最后循环完成之后再将循环变量的值更新到内存中。
实际内存检查的过程,是需要向内存中写入一个任意值,再读取出来检查读取值是否与写入值相等。但如果开启了缓存功能,实际值会从缓存中读出,而不是实际访问内存,这样的检查结果都是“正常”,就无法达到实际检查内存的效果。
所以在具体执行内存检查前,需要将缓存功能关闭。内存检查相关代码如下:
#define EFLAGS_AC_BIT 0x00040000
#define CR0_CACHE_DISABLE 0x60000000
unsigned int memtest(unsigned int start, unsigned int end)
{
char flg486 = 0;
unsigned int eflg, cr0, i;
/* 确认CPU是386还是486以上的 */
eflg = io_load_eflags();
eflg |= EFLAGS_AC_BIT; /* AC-bit = 1 */
io_store_eflags(eflg);
eflg = io_load_eflags();
if ((eflg & EFLAGS_AC_BIT) != 0) { /* 如果CPU是386,设定AC=1后AC值还是会回到0 */
flg486 = 1;
}
eflg &= ~EFLAGS_AC_BIT; /* AC-bit = 0 */
io_store_eflags(eflg);
if (flg486 != 0) {
cr0 = load_cr0();
cr0 |= CR0_CACHE_DISABLE; /* 禁止缓存 */
store_cr0(cr0);
}
i = memtest_sub(start, end);
if (flg486 != 0) {
cr0 = load_cr0();
cr0 &= ~CR0_CACHE_DISABLE; /* 允许缓存 */
store_cr0(cr0);
}
return i;
}
unsigned int memtest_sub(unsigned int start, unsigned int end)
{
unsigned int i, *p, old, pat0 = 0xaa55aa55, pat1 = 0x55aa55aa;
for (i = start; i <= end; i += 0x1000) {
p = (unsigned int *) (i + 0xffc);
old = *p; /* 记录修改前的值 */
*p = pat0; /* 试写 */
*p ^= 0xffffffff; /* 反转 */
if (*p != pat1) { /* 检查反转结果 */
not_memory:
*p = old;
break;
}
*p ^= 0xffffffff; /* 再次反转 */
if (*p != pat0) { /* 检查值是否恢复 */
goto not_memory;
}
*p = old; /* 恢复为修改前的值 */
}
return i;
}
首先通过EFLAGS确认CPU是386还是486。如果是486以上的CPU,EFLAGS寄存器的第18位是AC标志位,而对于386的CPU,这一位始终是0。先将这一位写入1,再读出EFLAGS查看这一位是否仍然是1。用完之后再将AC这一位重新设置为0。
确认CPU为486以上,接下来就需要禁用缓存(高速缓存是从486开始引入的)。
禁用缓存需要操作cr0寄存器,用到的load_cr0与store_cr0函数也需要用汇编语言进行编写:
_load_cr0: ; int load_cr0(void);
MOV EAX,CR0
RET
_store_cr0: ; void store_cr0(int cr0);
MOV EAX,[ESP+4]
MOV CR0,EAX
RET
memtest_sub函数则是实际进行内存检查的处理。这里的操作是首先记录需要被检查的内存地址的内容,然后向该内存地址进行写入读取测试。之所以要进行反转,是因为有些机型不这样做会直接读出写入的数据。
每次增加4个字节,把所有内存地址都读写一遍,运行速度会很慢。其实BIOS之前已经检查过内存了,应该没什么问题,这里主要是获取容量。为了加快执行速度,修改为每次增加0x1000,并且p指针修改为p = i + 0xffc,即每4K检查最后的4个字节,这样就可以了。
接下来在主程序中调用,对0x00400000~0xbfffffff范围的内存进行检查。
i = memtest(0x00400000, 0xbfffffff) / (1024 * 1024);
sprintf(s, "memory %dMB", i);
putfonts8_asc(binfo->vram, binfo->scrnx, 0, 32, COL8_FFFFFF, s);
根据上文的内存分布图,0x00400000之前的内存已经被使用了,应用程序不会运行到这里,因此不需要检查。因为是在QEMU虚拟机上进行运行,根据虚拟机的设置内存应该是32MB。运行:
实际结果和预期不符。为什么呢?
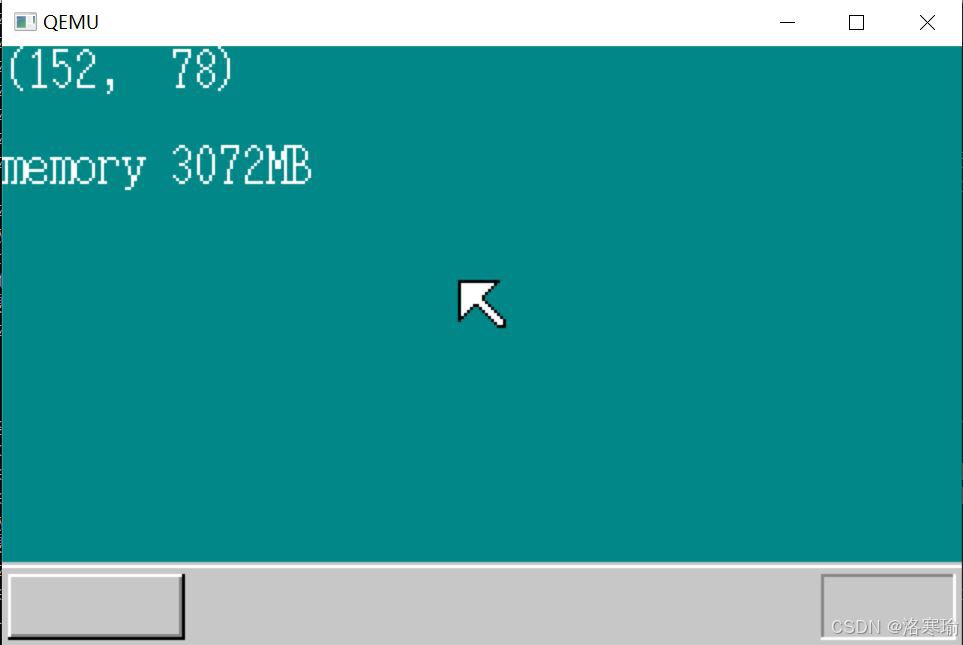
原因出在编译器上。
上面执行内存检查的memtest_sub程序,编译器在编译的过程中进行了优化,而这种优化导致没有实现我们预期的结果。
与我们的预期不同,编译器可能是按照以下思路进行优化的。
首先,写入pat0再反转,与pat1进行比较,编译器认为这一定是相等的,于是if(*p != pat1)得不到执行,编译过程中干脆删掉了。同理,下面再反转,与pat0进行比较,也被认为是一定相等的,于是下面的if语句也被删除掉了。程序于是变成了下面的样子:
unsigned int memtest_sub(unsigned int start, unsigned int end)
{
unsigned int i, *p, old, pat0 = 0xaa55aa55, pat1 = 0x55aa55aa;
for (i = start; i <= end; i += 0x1000) {
p = (unsigned int *) (i + 0xffc);
old = *p;
*p = pat0;
*p ^= 0xffffffff;
*p ^= 0xffffffff;
*p = old;
}
return i;
}
这样看来,两次反转之后又回到原来的值,没什么意义,也删掉。
unsigned int memtest_sub(unsigned int start, unsigned int end)
{
unsigned int i, *p, old, pat0 = 0xaa55aa55, pat1 = 0x55aa55aa;
for (i = start; i <= end; i += 0x1000) {
p = (unsigned int *) (i + 0xffc);
old = *p;
*p = pat0;
*p = old;
}
return i;
}
既然 *p最终被赋值为old,那中间的*p = pat0也没有意义了,删掉。
unsigned int memtest_sub(unsigned int start, unsigned int end)
{
unsigned int i, *p, old, pat0 = 0xaa55aa55, pat1 = 0x55aa55aa;
for (i = start; i <= end; i += 0x1000) {
p = (unsigned int *) (i + 0xffc);
old = *p;
*p = old;
}
return i;
}
old = *p,紧接着又是*p = old?这有什么意义?删掉删掉。
unsigned int memtest_sub(unsigned int start, unsigned int end)
{
unsigned int i, *p, old, pat0 = 0xaa55aa55, pat1 = 0x55aa55aa;
for (i = start; i <= end; i += 0x1000) {
p = (unsigned int *) (i + 0xffc);
}
return i;
}
虽然计算了p,但是完全没用到p的值,也删掉吧。于是最后编译出来的程序实现的是这样的效果:
unsigned int memtest_sub(unsigned int start, unsigned int end)
{
unsigned int i, *p, old, pat0 = 0xaa55aa55, pat1 = 0x55aa55aa;
for (i = start; i <= end; i += 0x1000) {}
return i;
}
已经面目全非了,而且最终返回的就是end的值,并没有达到我们预期的目的。
当然编译器的优化还是有其用武之地的,还不能将优化关闭掉。只是这里我们需要严格按照设计一步一步进行执行,因此这里还是用汇编语言进行编写:
_memtest_sub: ; unsigned int memtest_sub(unsigned int start, unsigned int end)
PUSH EDI ;
PUSH ESI
PUSH EBX
MOV ESI,0xaa55aa55 ; pat0 = 0xaa55aa55;
MOV EDI,0x55aa55aa ; pat1 = 0x55aa55aa;
MOV EAX,[ESP+12+4] ; i = start;
mts_loop:
MOV EBX,EAX
ADD EBX,0xffc ; p = i + 0xffc;
MOV EDX,[EBX] ; old = *p;
MOV [EBX],ESI ; *p = pat0;
XOR DWORD [EBX],0xffffffff ; *p ^= 0xffffffff;
CMP EDI,[EBX] ; if (*p != pat1) goto fin;
JNE mts_fin
XOR DWORD [EBX],0xffffffff ; *p ^= 0xffffffff;
CMP ESI,[EBX] ; if (*p != pat0) goto fin;
JNE mts_fin
MOV [EBX],EDX ; *p = old;
ADD EAX,0x1000 ; i += 0x1000;
CMP EAX,[ESP+12+8] ; if (i <= end) goto mts_loop;
JBE mts_loop
POP EBX
POP ESI
POP EDI
RET
mts_fin:
MOV [EBX],EDX ; *p = old;
POP EBX
POP ESI
POP EDI
RET
再运行之后,获取到的内存容量就正常了:
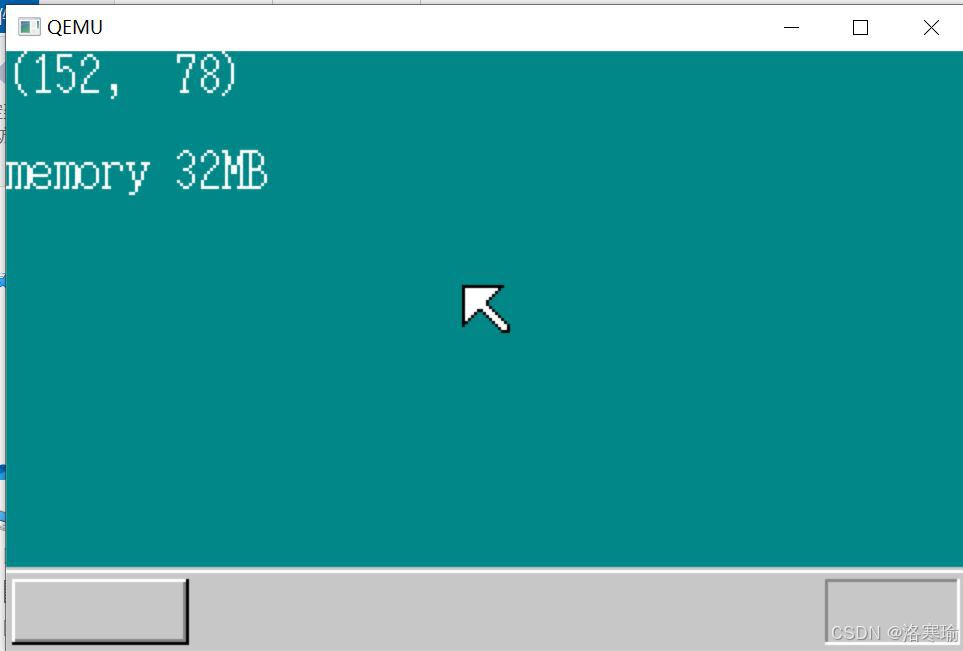
获取内存容量之后可以着手进行内存管理部分的开发了。简单来说,操作系统需要管理不同应用程序的内存使用需求,一方面是内存分配,一方面是内存释放。
首先假设共有128MB的内存,以4KB为单位进行管理,如何操作呢?下面从简单的情况开始逐一说明。
(1)128MB内存包含32768个4KB,这样我们创建32768字节的区域,用写入0或1来标记空闲或使用。
char a[32768];
for(i = 0; i < 1024; i++)
{
a[i] = 1; /* 将4MB的内存标记为使用 */
}
for(i = 1024; i < 32768; i++)
{
a[i] = 0;
}
比如需要100KB的空间,只要从a中找出连续25个标记为0的位置:
j = 0;
onemoretime:
for(i = 0;i < 25;i++)
{
if(a[j + 1] != 0)
{
j++;
if(j < 32768 -25)
{
goto onemoretime;
}
// no more memeory available
}
}
找到了足够的地址,就将a中的地方标记为1表示正在使用。因为是以4KB(0x1000)字节为单位进行管理的,只需将j放大0x1000倍就可以计算出地址了。
同理,要释放这部分内存,用起始地址除以0x1000可以计算出j,再将对应的数组成员标记为0即可。
这样的管理方式比较方便,但占用的空间还是大了一点。其实只用来存储0或1,用比特位代替字节存储就可以,这样占用空间可用进一步缩小。
(2)还有一种列表管理的方法,是把类似于“从xxx号地址开始的yyy字节的空间是空着的”保存在列表里。
struct FREEINFO{ /* 用于保存可用状况*/
unsigned int addr, size;
};
struct MEMMAN{ /* 内存管理*/
int frees;
struct FREEINFO free[1000];
};
struct MEMMAN memman;
memman.frees = 1; /* 可用状况list中只有1条*/
memman.free[0].addr = 0x00400000; /* 从0x00400000号地址开始,有124MB可用*/
memman.free[0].size = 0x07c00000;
简单理解,就是一个列表中保存了一条一条的空闲内存信息,包括起始地址和内存大小。
用这种方法管理内存的优点在于占用的内存少,分配速度快。不管一条信息保存的内存有多大,占用的空间都是固定的8字节。这里设置1000的数组也会有富余,因为可用空间不会这么的分散,实际占用的空间可能会更小。而将一段内存分配出去只需要将起始地址后移,将可用长度减少,执行两次运算就可以了。
当然这样的管理方法也有缺陷。采用这样的分配方法,时间长了可用的内存段会变得很零碎。如果此时需要分配较大的内存时,虽然有很多零散的小块内存,却无法分配给应用程序使用。
作者这里采用的就是第二种方法,并在此基础上采取了一些改进措施。对于零碎而无法分配使用的内存,暂时舍弃,在后续有机会时再对零碎的内存整合起来。程序如下:
#define MEMMAN_FREES 4090 /* 大约32KB */
#define MEMMAN_ADDR 0x003c0000
struct FREEINFO { /* 可用信息 */
unsigned int addr, size;
};
struct MEMMAN { /* 内存管理 */
int frees, maxfrees, lostsize, losts;
struct FREEINFO free[MEMMAN_FREES];
};
void memman_init(struct MEMMAN *man)
{
man->frees = 0; /* 可用信息数目 */
man->maxfrees = 0; /* 用于观察可用状况,frees的最大值 */
man->lostsize = 0; /* 释放失败的内存的大小总和 */
man->losts = 0; /* 释放失败次数 */
return;
}
unsigned int memman_total(struct MEMMAN *man)
/* 报告空余内存大小的合计 */
{
unsigned int i, t = 0;
for (i = 0; i < man->frees; i++) {
t += man->free[i].size;
}
return t;
}
unsigned int memman_alloc(struct MEMMAN *man, unsigned int size)
/* 分配 */
{
unsigned int i, a;
for (i = 0; i < man->frees; i++) {
if (man->free[i].size >= size) {
/*找到了足够大的内存 */
a = man->free[i].addr;
man->free[i].addr += size;
man->free[i].size -= size;
if (man->free[i].size == 0) {
/* free[i].size变成0,减掉一条可用信息 */
man->frees--;
for (; i < man->frees; i++) {
man->free[i] = man->free[i + 1]; /* 代入结构体 */
}
}
return a;
}
}
return 0; /* 没有可用内存 */
}
分配内存的程序不难理解。下面释放内存函数略复杂一些:
int memman_free(struct MEMMAN *man, unsigned int addr, unsigned int size)
/* 内存释放程序 */
{
int i, j;
/* 为了便于归纳内存,将free[]按照addr的顺序排列 */
/* 先决定应该放在哪里 */
for (i = 0; i < man->frees; i++) {
if (man->free[i].addr > addr) {
break;
}
}
/* free[i - 1].addr < addr < free[i].addr */
if (i > 0) {
/* 前面有可用内存 */
if (man->free[i - 1].addr + man->free[i - 1].size == addr) {
/* 可以与前面的可用内存归纳到一起 */
man->free[i - 1].size += size;
if (i < man->frees) {
/* 后面也有可用内存 */
if (addr + size == man->free[i].addr) {
/* 可用与后面的可用内存归纳到一起 */
man->free[i - 1].size += man->free[i].size;
/* man->free[i]删除 */
/* free[i]变成0后归纳到前面去 */
man->frees--;
for (; i < man->frees; i++) {
man->free[i] = man->free[i + 1]; /* 通过移位给结构体重新赋值 */
}
}
}
return 0; /* 成功完成 */
}
}
/* 不能与前面的可用空间归纳到一起 */
if (i < man->frees) {
/* 后面还有可用空间 */
if (addr + size == man->free[i].addr) {
/* 可以与后面的可用空间归纳到一起 */
man->free[i].addr = addr;
man->free[i].size += size;
return 0; /* 成功完成 */
}
}
/* 既不能与前面的可用空间归纳到一起,也不能与后面的归纳到一起 */
if (man->frees < MEMMAN_FREES) {
/* free[i]之后的,向后移动,腾出可用空间 */
for (j = man->frees; j > i; j--) {
man->free[j] = man->free[j - 1];
}
man->frees++;
if (man->maxfrees < man->frees) {
man->maxfrees = man->frees; /* 更新最大值 */
}
man->free[i].addr = addr;
man->free[i].size = size;
return 0; /* 成功完成 */
}
/* 不能往后移动 */
man->losts++;
man->lostsize += size;
return -1; /* 失败 */
}
其实释放内存的本质还是在列表中给一段内存找位置,能合并则合并,实在不能合并就在列表中新增一项。代码看起来有些复杂,多读几遍还是能明白意思的。
下一篇会处理之前鼠标遗留的一点小问题,优化鼠标显示。敬请期待。