Abstract
背景:
图像到图像的转换被认为是医学图像分析领域的一个新的前沿领域。
工作:
提出了一种新的医学图像到图像的转换框架MedGAN:
将对抗性框架与非对抗性损失的新组合相结合;
生成器——CasNet,该结构通过编码器-解码器对的逐步细化来增强翻译后的医学输出的清晰度;
判别器——作为一个可训练的特征提取惩罚之间的差异转换医学图像和期望的模式;
利用风格传递损失将目标图像的纹理和精细结构匹配到转换后的图像;
应用于三个不同的任务:PETCT翻译、MR运动伪影校正和PET图像去噪。
结果:
MedGAN优于其他现有的转换方法。
1. Introduction
由于可能引入不切实际的信息,将输入图像模态转换为输出模态的任务具有挑战性。这显然会使合成图像不可靠,无法用于诊断目的。
1.1 Classical approaches
1.2 Generative models
1.3 Medical image translation
1.4 Contributions
MedGAN的主要目的不是诊断,而是进一步增强需要全局一致图像属性的技术后处理任务。
- MedGAN通过结合对抗性框架和一种新的非对抗性损失组合,捕捉所需目标模态的高频和低频成分。
- CasNet新生成器架构,将多个完全卷积的编码器-解码器网络通过跳跃连接链接成一个生成器网络。
- MedGAN在三项具有挑战性的医学成像任务中的应用:从PET图像生成合成CT图像、PET图像去噪以及MR运动伪影。
- MedGAN与其他对抗性翻译框架的定量和定性比较。
- 从医学角度研究翻译后的医学图像的主观性能和保真度。
2. Materials and Methods
MedGAN架构:
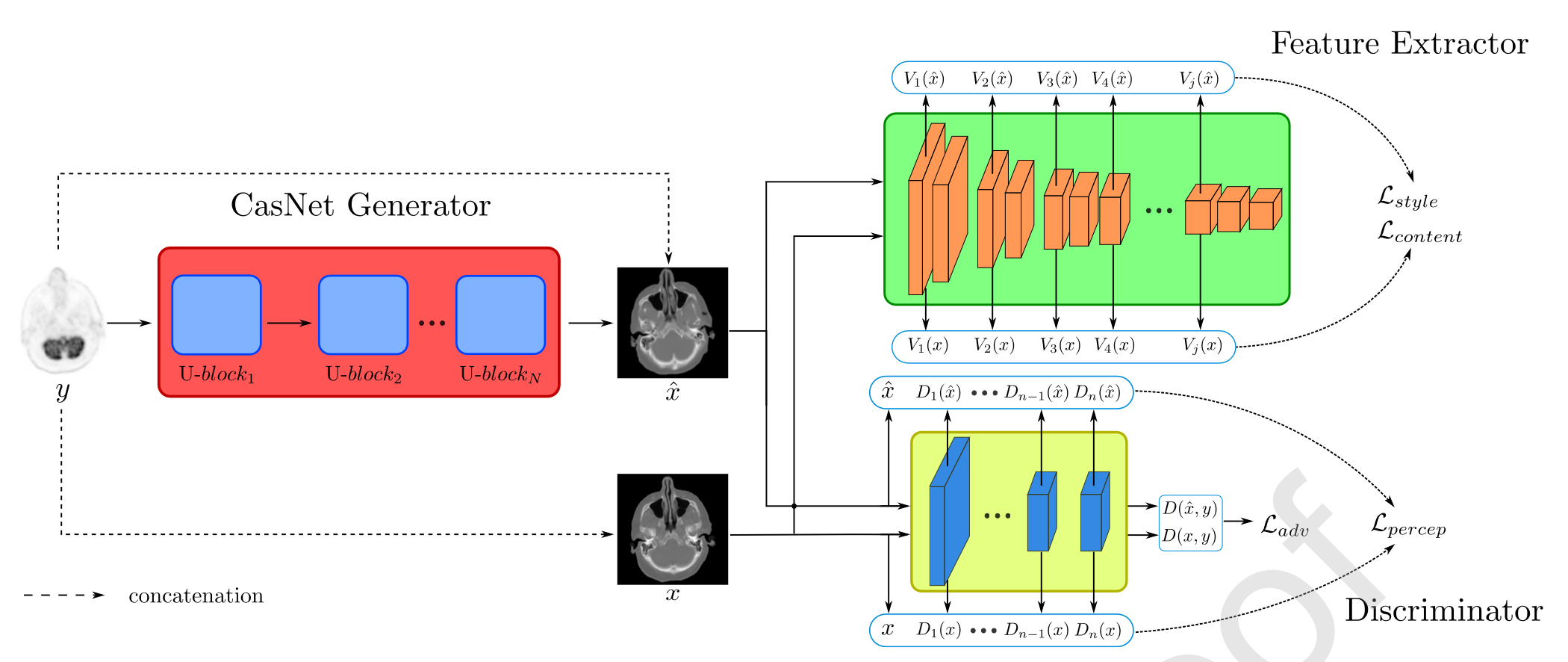
2.1 Preliminaries
2.1.1 Generative adversarial networks
GANs 由两个主要部分组成:生成器和判别器。
生成器 G 接受来自先验噪声分布
p
noise
p_{\text{noise}}
pnoise(例如正态分布)的输入样本 z,并将其映射到数据空间
x
^
=
G
(
z
)
\hat{x} = G(z)
x^=G(z),从而诱导出模型分布
p
model
p_{\text{model}}
pmodel 。
判别器 D 是一个二元分类器,其目标是将真实数据样本
x
∼
p
data
x \sim p_{\text{data}}
x∼pdata 分类为真实(D(x)=1),而将生成的样本
x
^
∼
p
model
\hat{x} \sim p_{\text{model}}
x^∼pmodel 分类为虚假(
D
(
x
^
)
=
0
D(\hat{x}) = 0
D(x^)=0)。
这两个网络相互竞争:生成器试图生成与真实样本无法区分的样本,即使
p
model
≈
p
data
p_{\text{model}} \approx p_{\text{data}}
pmodel≈pdata,从而欺骗判别器;与此同时,判别器的目标是通过学习更有意义的特征来避免被欺骗,更好地区分真实和生成的样本。
表现为:
min
G
max
D
L
GAN
\min_G \max_D L_{\text{GAN}}
GminDmaxLGAN
对抗损失:
L
GAN
=
E
x
∼
p
data
[
log
D
(
x
)
]
+
E
z
∼
p
noise
[
log
(
1
−
D
(
G
(
z
)
)
)
]
L_{\text{GAN}} = \mathbb{E}_{x \sim p_{\text{data}}} [\log D(x)] + \mathbb{E}_{z \sim p_{\text{noise}}} [\log (1 - D(G(z)))]
LGAN=Ex∼pdata[logD(x)]+Ez∼pnoise[log(1−D(G(z)))]
2.1.2 Image-to-image translation
将对抗网络从图像生成应用于转换任务的基本原理是将生成器网络替换为条件生成对抗网络 (cGAN)。
生成器的目标是通过映射函数 G ( y , z ) = x ^ ∼ p model G(y, z) = \hat{x} \sim p_{\text{model}} G(y,z)=x^∼pmodel 将源域图像 y ∼ p source y \sim p_{\text{source}} y∼psource 映射到其对应的真实目标图像 x ∼ p target x \sim p_{\text{target}} x∼ptarget。这通常可以被视为两个共享相同底层结构但表面外观不同的域之间的回归任务。
cGAN 不是使用手动构建的损失函数来测量转换图像和目标图像之间的相似性,而是利用一个二元分类器——判别器来代替。
对抗损失:
L
cGAN
=
E
x
,
y
[
log
D
(
x
,
y
)
]
+
E
z
,
y
[
log
(
1
−
D
(
G
(
y
,
z
)
,
y
)
)
]
L_{\text{cGAN}} = \mathbb{E}_{x,y}[\log D(x, y)] + \mathbb{E}_{z,y}[\log (1 - D(G(y, z), y))]
LcGAN=Ex,y[logD(x,y)]+Ez,y[log(1−D(G(y,z),y))]
判别器的目标是将源图像 y 和其对应的真实目标图像 x 的拼接视为真实(D(x, y) = 1),而将 y 和生成的图像
x
^
\hat{x}
x^ 视为虚假(
D
(
x
^
,
y
)
=
0
D(\hat{x}, y) = 0
D(x^,y)=0)。
仅依赖对抗损失函数的图像到图像翻译框架无法生成一致的结果。生成的图像可能不会与目标图像共享相似的全局结构。
为了解决这一问题,通常会加入像素重构损失,例如 L1 损失 。这可以通过计算目标图像与生成图像之间的平均绝对误差 (MAE) 来实现:
L
L
1
=
E
x
,
y
,
z
[
∥
x
−
G
(
y
,
z
)
∥
1
]
L_{L1} = \mathbb{E}_{x,y,z} [\|x - G(y, z)\|_1]
LL1=Ex,y,z[∥x−G(y,z)∥1]
最终训练目标:
min
G
max
D
(
L
cGAN
+
λ
L
L
1
)
\min_G \max_D (L_{\text{cGAN}} + \lambda L_{L1})
GminDmax(LcGAN+λLL1)
2.2 Perceptual loss
利用这种损失函数的转换框架往往会在保持全局结构的同时,导致图像失真和细节丢失。
为了捕捉图像中高频成分之间的差异,额外引入了感知损失。
这种损失是基于使用判别器网络作为可训练的特征提取器,提取中间特征表示。目标图像 x 和翻译图像
x
^
\hat{x}
x^ 的特征图之间的平均绝对误差 (MAE) 被计算为:
P
i
(
G
(
y
,
z
)
,
x
)
=
1
h
i
w
i
d
i
∥
D
i
(
G
(
y
,
z
)
,
y
)
−
D
i
(
x
,
y
)
∥
1
P_i (G(y, z), x) = \frac{1}{h_i w_i d_i} \|D_i (G(y, z), y) - D_i (x, y)\|_1
Pi(G(y,z),x)=hiwidi1∥Di(G(y,z),y)−Di(x,y)∥1
其中
D
i
D_i
Di 表示从判别器网络的第 i 个隐藏层提取的特征表示,
h
i
h_i
hi 、
w
i
w_i
wi 和
d
i
d_i
di 分别表示特征空间的高度、宽度和深度。
感知损失:
L
perceptual
=
∑
i
=
0
L
λ
p
i
P
i
(
G
(
y
,
z
)
,
x
)
L_{\text{perceptual}} = \sum_{i=0}^{L} \lambda_{pi} P_i (G(y, z), x)
Lperceptual=i=0∑LλpiPi(G(y,z),x)
其中 L 是判别器的隐藏层数量,
λ
p
i
>
0
\lambda_{pi} > 0
λpi>0 是一个调节超参数,表示第 i 层的影响。
稳定判别器的对抗训练,采用了谱归一化正则化,通过对判别器中每一层 i 的权重矩阵
θ
D
,
i
\theta_{D,i}
θD,i 进行归一化来实现:
θ
D
,
i
=
θ
D
,
i
δ
(
θ
D
,
i
)
\theta_{D,i} = \frac{\theta_{D,i}}{\delta(\theta_{D,i})}
θD,i=δ(θD,i)θD,i
其中
δ
(
θ
D
,
i
)
\delta(\theta_{D,i})
δ(θD,i) 表示矩阵
θ
D
,
i
\theta_{D,i}
θD,i 的谱范数。因此,判别器函数 D(x, y) 的 Lipschitz 常数将被限制为 1。
在实际操作中,为了计算谱范数,使用了功率迭代法的近似
δ
^
(
W
i
)
\hat{\delta}(W_i)
δ^(Wi),而不是应用奇异值分解,以降低所需的计算复杂度。
2.3 Style transfer losses
用于损失计算的特征来自为图像分类任务预训练的特征提取器。
预训练网络的优势它能够从更大的感受野中提取丰富的特征,从而在增强转换图像的全局结构的同时,也增强精细的细节。
风格迁移损失可以分为两个主要组成部分:风格损失和内容损失。
2.3.1 Style loss
风格损失惩罚转换图像与其对应目标图像之间风格表示的差异。
特征的相关性通过每个卷积块的Gram矩阵
G
r
j
(
x
)
Gr_j(x)
Grj(x) 表示,该矩阵的形状为
d
j
×
d
j
d_j \times d_j
dj×dj,其元素通过特征图在高度和宽度维度上的内积计算得出:
G
r
j
(
x
)
m
,
n
=
1
h
j
w
j
d
j
∑
h
=
1
h
j
∑
w
=
1
w
j
V
j
(
x
)
h
,
w
,
m
V
j
(
x
)
h
,
w
,
n
Gr_j(x)_{m,n} = \frac{1}{h_j w_j d_j} \sum_{h=1}^{h_j} \sum_{w=1}^{w_j} V_j(x)_{h,w,m} V_j(x)_{h,w,n}
Grj(x)m,n=hjwjdj1h=1∑hjw=1∑wjVj(x)h,w,mVj(x)h,w,n
V
j
,
i
(
x
)
V_{j,i}(x)
Vj,i(x) 表示从输入图像 x 中通过特征提取网络的第 j 个卷积块和第 i 层提取的特征图。仅使用每个卷积块的第一层,并将在符号中省略。这些特征图的大小为
h
j
×
w
j
×
d
j
h_j \times w_j \times d_j
hj×wj×dj,其中
h
j
h_j
hj 、
w
j
w_j
wj 、
d
j
d_j
dj 分别表示高度、宽度和空间深度。
风格损失计算为转换输出
x
^
\hat{x}
x^ 和真实输入 x 之间的特征相关性差异的Frobenius范数平方:
L
style
=
∑
j
=
1
B
λ
s
j
1
4
d
j
2
∥
G
r
j
(
G
(
y
,
z
)
)
−
G
r
j
(
x
)
∥
F
2
L_{\text{style}} = \sum_{j=1}^{B} \lambda_{sj} \frac{1}{4 d_j^2} \| Gr_j(G(y, z)) - Gr_j(x) \|_F^2
Lstyle=j=1∑Bλsj4dj21∥Grj(G(y,z))−Grj(x)∥F2
λ
s
j
>
0
\lambda_{sj} > 0
λsj>0 是一个调整的超参数,表示第 j 个卷积块的贡献权重,B 是卷积块的总数。
2.3.2 Content loss
内容损失惩罚从特征提取网络中提取的特征表示之间的差异,不捕捉风格或纹理的差异。
起到了类似像素重构损失的辅助作用,通过增强低频分量并确保转换图像的全局一致性。
内容损失:
L
content
=
∑
j
=
1
B
λ
c
j
1
h
j
w
j
d
j
∥
V
j
(
G
(
y
,
z
)
)
−
V
j
(
x
)
∥
F
2
L_{\text{content}} = \sum_{j=1}^{B} \lambda_{cj} \frac{1}{h_j w_j d_j} \| V_j(G(y, z)) - V_j(x) \|_F^2
Lcontent=j=1∑Bλcjhjwjdj1∥Vj(G(y,z))−Vj(x)∥F2
其中,
λ
c
j
>
0
\lambda_{cj} > 0
λcj>0 是一个超参数,表示第 j 个卷积块第一层的影响力。
2.4 MedGAN architecture
CasNet架构:

2.4.1 U-blocks
U-块是一个全卷积编码器-解码器网络。
编码路径将输入域中的图像(分辨率为256×256)映射到一个高级表示,该表示由8个卷积层堆叠而成,每个卷积层后面都跟着批量归一化和Leaky-ReLU激活函数。
卷积滤波器的数量分别为64、128、256、512、512、512、512和512,卷积核大小为4×4,步长为2。
解码路径与编码架构相对应,但使用分数步长反卷积,每层之后将分辨率放大两倍。
上采样路径的每层分别包含512、1024、1024、1024、1024、512、256和128个滤波器,这些层使用ReLU激活函数,但最后一层反卷积层使用Tanh激活函数。
U-块包含跳跃连接。
2.4.2 CasNet
CasNet通过端到端地连接多个U-块来增强MedGAN的生成能力。
通过这种网络深度的损失梯度反向传播可能导致梯度消失问题,但是,由于单个U-块内部使用了跳跃连接,这个问题得到了缓解。
2.4.3 Discriminator architecture
判别器采用了改进后的PatchGAN架构。
PatchGAN的设计不是为了将目标图像和输出图像分类为真实或虚假,而是具有减小的感受野,以便在分类之前将输入图像通过卷积分成更小的图像块,并对结果进行平均。
为了避免使用较小块大小时出现的典型平铺伪影,70x70块是常用的块大小。然而,实验发现,将较小的块与先前引入的非对抗性损失(如感知损失和风格迁移损失)结合使用,可以促进更清晰的结果,同时消除传统的平铺伪影。
通过结合两个卷积层(分别具有64和128个空间滤波器),随后是批量归一化和Leaky-ReLU激活函数,来实现16x16块的大小。
最后,为了输出所需的置信度概率图,使用了一个输出维度为1的卷积层和一个sigmoid激活函数。
2.5 MedGAN framework and training
MedGAN累计损失函数:
L
MedGAN
=
L
cGAN
+
λ
1
L
perceptual
+
λ
2
L
style
+
λ
3
L
content
L_{\text{MedGAN}} = L_{\text{cGAN}} + \lambda_1 L_{\text{perceptual}} + \lambda_2 L_{\text{style}} + \lambda_3 L_{\text{content}}
LMedGAN=LcGAN+λ1Lperceptual+λ2Lstyle+λ3Lcontent
λ
1
\lambda_1
λ1、
λ
2
\lambda_2
λ2 和
λ
3
\lambda_3
λ3 是平衡不同损失组件的超参数。
最终选择了
λ
1
=
20
\lambda_1 = 20
λ1=20 和
λ
2
=
λ
3
=
0.0001
\lambda_2 = \lambda_3 = 0.0001
λ2=λ3=0.0001 。
设置
λ
p
i
\lambda_{pi}
λpi 来使判别器的两层对损失的影响相等。
设置
λ
c
j
\lambda_{cj}
λcj 使除最深的卷积块外的所有卷积块对内容损失有影响。
对于风格损失,设置
λ
s
j
\lambda_{sj}
λsj 被设定为仅包括预训练的VGG-19网络的第一个和最后一个卷积块的影响。
特征提取器使用一个深度的VGG-19网络,它是在ImageNet分类任务上预训练的。
使用ADAM优化器 ,动量值为0.5,学习率为0.0002。
使用实例归一化,批量大小为1。
每训练CasNet生成器三次时训练一次Patch判别器。
生成器的CasNet架构由N=6个U-block组成。
训练过程:

3. Experimental evaluation
3.1 Datasets
3.2 Experimental setup
3.2.1 Analysis of loss functions
3.2.2 Comparison with state-of-the-art techniques
3.2.3 Perceptual study and validation
3.3 Evaluation metrics
- 结构相似性指数(SSIM)
- 峰值信噪比(PSNR)
- 均方误差(MSE)
- 视觉信息保真度(VIF)
- 通用质量指数(UQI)
- 学习感知图像块相似性(LPIPS)
4. Results
4.1 Analysis of loss functions
4.2 Comparison with state-of-the-art techniques
4.3 Perceptual study and validation
5. Discussion
讨论MedGAN框架各个部分的性能,以及现有的不足。
6. Conclusion
MedGAN 将条件对抗框架与一种新型的非对抗性损失组合以及CasNET生成器架构相结合,以增强结果的全局一致性和高频细节。
未来的工作将致力于扩展MedGAN以支持3D多通道体积的处理,还将研究MedGAN在技术后处理任务中的性能。