
尽管量化已成为大模型性能优化的常规技术手段,但由于很难评估模型量化的实际效果,依然有人质疑量化模型的准确度与生成质量。
对此,基于Llama 3.1系列模型,AI模型优化与加速推理服务商Neural Magic进行了超五十万次的实测,以对比模型量化与原始模型的效果。以下是他们评估后中的要点:
1.设计了一套覆盖广泛推理场景的评估体系,确保从结构化任务到实际应用的全面分析,包括学术基准测试、真实场景基准测试、文本相似度评估。
2.学术基准测试结果:在OpenLLM Leaderboard v1测试中,所有量化方案——无论模型大小——都恢复了未量化基准平均得分的99%以上的分数;在OpenLLM Leaderboard v2测试中,量化模型的平均得分接近99%的基准平均得分,所有模型的恢复率至少达到96%。
3.真实世界基准测试结果:在Arena-Hard测试中,所有模型尺寸和量化方案的95%置信区间存在重叠,说明量化对准确率的影响极小;量化模型在HumanEval和HumanEval+上均表现出色,8-bit模型实现了99.9%的准确率恢复,4-bit模型则达到了98.9%。
4.文本相似度评估结果:较大的量化模型(70B和405B)与全精度模型保持了较高的文本相似度,ROUGE-1和ROUGE-L得分显示其在词汇选择和结构方面保留程度良好。BERTScore和STS进一步证实,即使量化引入了细微的词元变化,但整体含义仍保持一致。
5.与全精度模型相比,量化模型保持了令人印象深刻的准确性和高质量。量化在成本、能源和性能方面提供了巨大的优势,同时又不会牺牲模型的完整性。
(本文由OneFlow编译发布,转载请联系授权。原文:https://neuralmagic.com/blog/we-ran-over-half-a-million-evaluations-on-quantized-llms-heres-what-we-found/)
来源 | Neural Magic
翻译|张雪聃、刘乾裕、林心宇
OneFlow编译
题图由SiliconCloud平台生成
将模型量化为较低精度格式(如8-bit或4-bit)可以显著降低计算成本并加速推理过程。然而,有个关键问题一直存在:这些量化模型是否能保持与未压缩模型相同的精确度和质量。
最近,机器学习社区对此产生了较大担忧:量化的大语言模型是否真能在精确度和生成质量上与原始模型媲美?
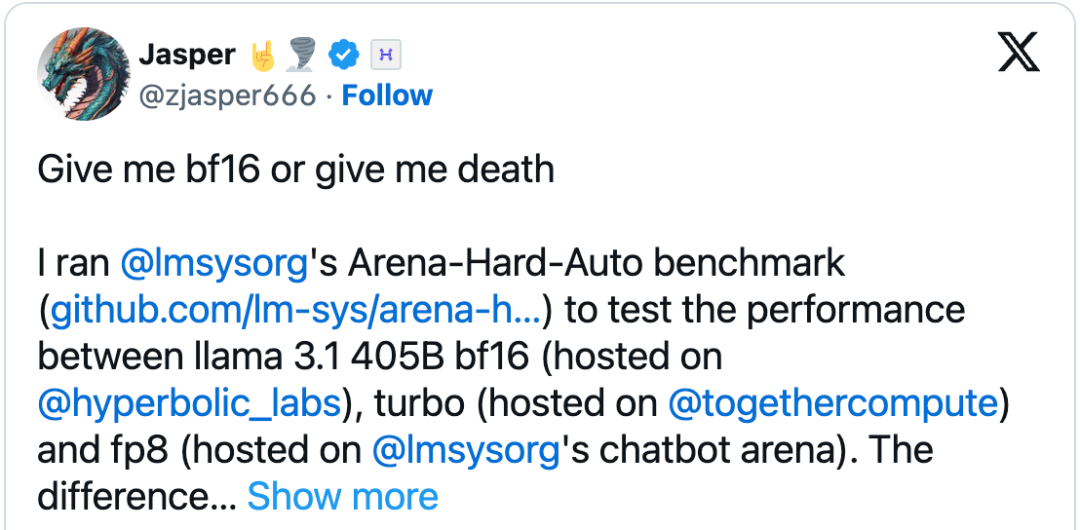
在本文中,我们将正面回应这些担忧,并解答一个核心问题:量化LLM究竟会牺牲多少精确度?
为此,我们在多个基准测试上进行了超过五十万次评估,涵盖学术数据集、真实场景任务以及人工检查,严格测试了我们最新的量化模型。
我们的研究结果揭示了社区担忧的几个可能来源,例如过于敏感的评估、对聊天模板格式敏感的模型以及广泛使用的量化算法中超参数调优的不足。通过解决这些问题,我们推出了高精确度的量化模型,这些模型与原始精度模型几乎没有明显差异。
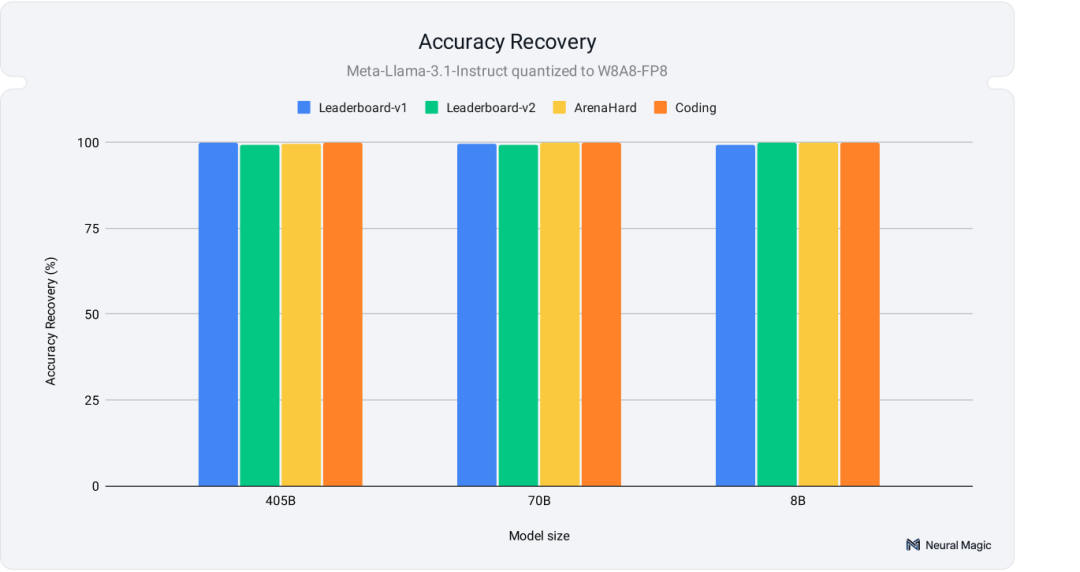
如图1所示,我们在多个学术及实际任务中实现了全面的精确度恢复,包括社区曾发现问题的ArenaHard基准测试(https://github.com/lmarena/arena-hard-auto)。 接下来,让我们进一步探讨具体方法!
1
方法与思路
我们的评估聚焦于Llama 3.1系列模型的深入测试。这些模型在研究和实际应用中得到了广泛关注,以其简洁高效的架构成为评估量化方案的理想候选。
我们分别对8B、70B和405B三种模型尺寸进行了三种不同的量化方案测试,并与16-bit基准模型进行对比。这些方案根据不同的硬件和部署需求进行选择,所有性能数据均通过了vLLM (0.6.2)验证:
-
W8A8-INT:将权重和激活值量化为8-bit整数值,适用于Nvidia Ampere (A100 GPU)及较旧硬件的服务器或高吞吐量场景。此方案可实现2倍模型压缩,并在多请求服务器场景中平均提升约1.8倍性能加速。
-
W8A8-FP:采用8-bit浮点格式而不是整数值表示权重和激活值,简化了压缩过程,仅支持Nvidia Hopper (H100)和Ada Lovelace等最新硬件。此方案也提供2倍模型压缩,并在多请求服务器场景中实现1.8倍性能提升。
-
W4A16-INT:将权重量化为4-bit整数,激活值保持16-bit精度。适用于对时延敏感的边缘场景或单一请求任务,其中模型大小和单请求响应时间是关键因素。这意味着模型推理主要受限于加载权重的内存访问,而不是计算密集型操作。该方案可实现3.5倍模型压缩,并在单个流数据场景中提供2.4倍速度提升。
每个量化模型的构建都在OpenLLM Leaderboard (https://huggingface.co/spaces/open-llm-leaderboard-old/open_llm_leaderboard) 基准上进行了超参数和算法选择的优化,并在多个基准测试中验证其广泛适应性。最佳选择因模型和方案而异,通常采用了SmoothQuant 、GPTQ以及标准就近取整(round-to-nearest)量化算法的组合。具体方法详见我们在HuggingFace上的模型卡 (https://huggingface.co/collections/neuralmagic/llama-31-quantization-66a3f907f48d07feabb8f300)。
我们设计了一套覆盖广泛推理场景的评估体系,确保从结构化任务到实际应用的全面分析:
-
学术基准测试(Academic Benchmarks):如OpenLLM Leaderboard v1和v2(https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard) ,侧重于回答问题与推理等结构化任务,提供一致且易于验证的精确度评分。然而,它们往往无法反映语义、变化和上下文这些重要的实际场景。
-
真实场景基准测试(Real-World Benchmarks):这些基准测试模拟人类使用场景,如指令执行、对话和代码生成,涵盖了更广泛的任务,并更好地反映模型在实际环境中的表现。包括ArenaHard和HumanEval等测试,能更全面地展示模型在动态环境中的能力。
-
文本相似度评估(Text Similarity):我们通过ROUGE、BERTScore和语义文本相似度(STS)等指标,评估量化模型与未量化模型输出的匹配度。这些指标衡量生成文本在语义和结构上的一致性,确保其意义和质量得以保留。
通过这种广泛的评估框架,我们确保涵盖从研究驱动任务到开放式应用场景的各种部署需求,全面展现量化LLM的性能与能力。
2
学术基准表现
学术基准是评估语言模型准确性和推理能力的绝佳起点。这些基准提供了结构化的任务,在依据明确标准对模型表现进行比较时起着至关重要的作用。我们的评估重点是OpenLLM Leaderboard v1和v2,旨在确保在较旧版本以及更新且更具挑战性的基准测试中皆能获取一致的结果。此外,在这两个版本上进行测试有助于防止对v1进行过拟合,因为我们在v1上优化了量化超参数。
我们通过使用Meta为Llama-3.1模型提供的提示(https://huggingface.co/datasets/meta-llama/Llama-3.1-8B-Instruct-evals)对OpenLLM Leaderboard v1进行了评估。我们基于平均得分进行比较和恢复百分比计算,并在我们的HuggingFace模型集(https://huggingface.co/datasets/meta-llama/Llama-3.1-8B-Instruct-evals)中提供了每个任务的详细结果。
Leaderboard v1基准涵盖了多种主题,包括:
-
小学数学:GSM8k
-
世界知识与推理:MMLU, ARC-Challenge
-
语言理解:Winogrande, HellaSwag
-
真实性:TruthfulQA
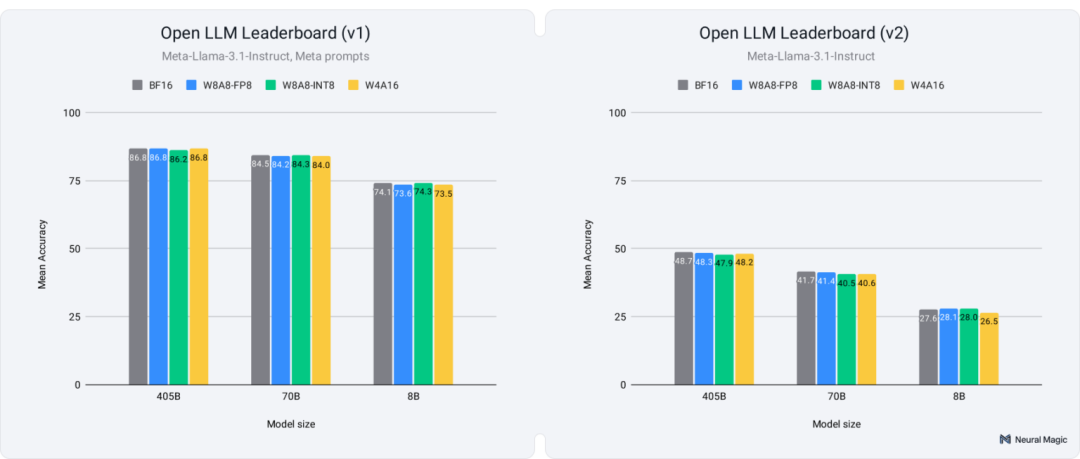
如图2(左)所示,所有量化方案——无论模型大小——都恢复了未量化基准平均得分的99%以上。
随着社区的不断发展,基准测试也随之进化。由于v1的得分开始趋于平稳,OpenLLM Leaderboard v2应运而生,旨在进一步推动模型的发展,提供更具挑战性的任务,测试模型更深入的推理和知识能力。与v1类似,我们基于v2基准测试的平均得分计算恢复百分比(完整结果请见我们的HuggingFace模型集:https://huggingface.co/collections/neuralmagic/llama-31-quantization-66a3f907f48d07feabb8f300)。v2的基准测试涵盖了更复杂的主题,如:
-
专家知识与推理:MMLU-Pro、GPQA、Big Bench Hard
-
多步推理:MuSR
-
高级数学问题:MATH Level 5
-
指令跟随:IFEval
如图2(右)所示,量化模型的平均得分接近99%的基准平均得分,所有模型的恢复率至少达到96%。然而,这些任务的难度增加,尤其对较小模型而言,导致在GPQA和MuSR等基准测试中出现更大的差异,即使是全精度基准,得分也接近随机猜测的阈值。这使得量化版本的得分波动更大,准确率恢复信号也变得不够明确。
3
真实世界基准表现
虽然学术基准提供了结构化的评估,但真实世界中开放式的基准测试更能代表模型在动态环境中的表现,例如人机对话互动或代码生成任务。这些基准测试通过多样化的提示、较长的生成结果和多个潜在的解决方案,重点考察模型生成内容的正确性和语义质量。我们的评估针对三个关键的真实世界基准:Arena-Hard、HumanEval和HumanEval+,它们分别衡量模型在对话、指令跟随以及代码生成方面的表现。
LMSYS Chatbot Arena已成为评估LLM的主要基准,主要评估模型与人类偏好的一致性。Arena-Hard Auto是该基准的自动化扩展版,由LLM对500个复杂问题的回应进行评估,涵盖多种主题。该基准与人类评价表现出高度相关性,达到了89%的领先水平,几乎与人类偏好排名一致。
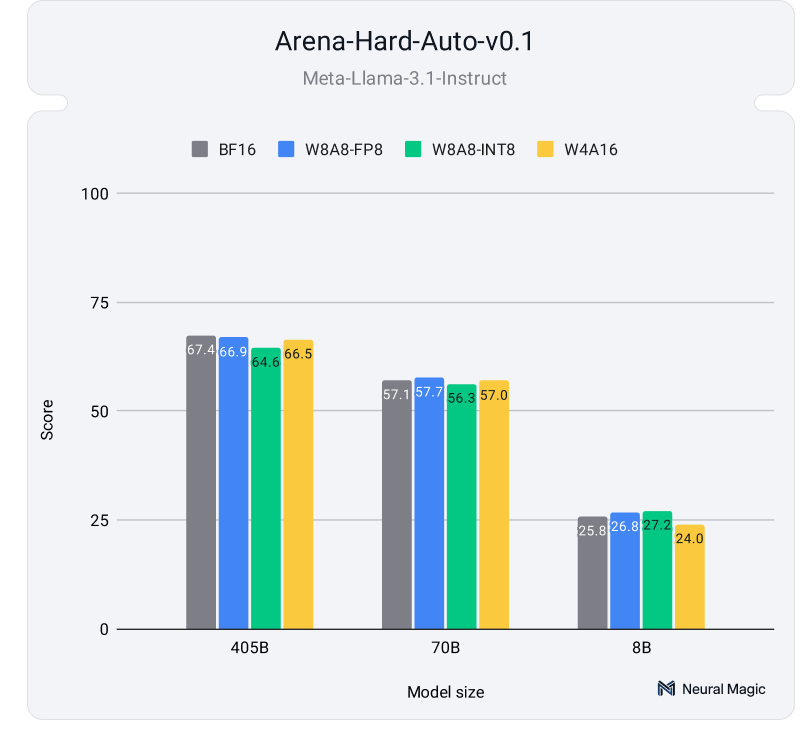
图4显示了量化模型与其全精度对比模型在Arena-Hard-Auto基准测试中的表现,平均每个模型进行了两轮评估。结果表明,量化模型的回复质量与未量化模型相比,依然极具竞争力。根据我们在HuggingFace Hub上的详细结果(https://huggingface.co/datasets/neuralmagic/quantized-llama-3.1-arena-hard-evals) ,所有模型尺寸和量化方案的95%置信区间存在重叠,说明量化对准确率的影响极小。
除了基于聊天的交互外,LLM还被广泛用作编码助手。为了评估量化模型在代码生成方面的表现,我们在HumanEval及其更具挑战性的变体HumanEval+上进行了测试。这些基准测试衡量了模型根据编程问题生成正确且功能性代码的能力,针对HumanEval+的测试引入了更复杂、多步骤的任务,需要更深入的推理和问题解决能力。下述图5显示了使用EvalPlus库获得的pass@1分数(https://github.com/evalplus/evalplus)。
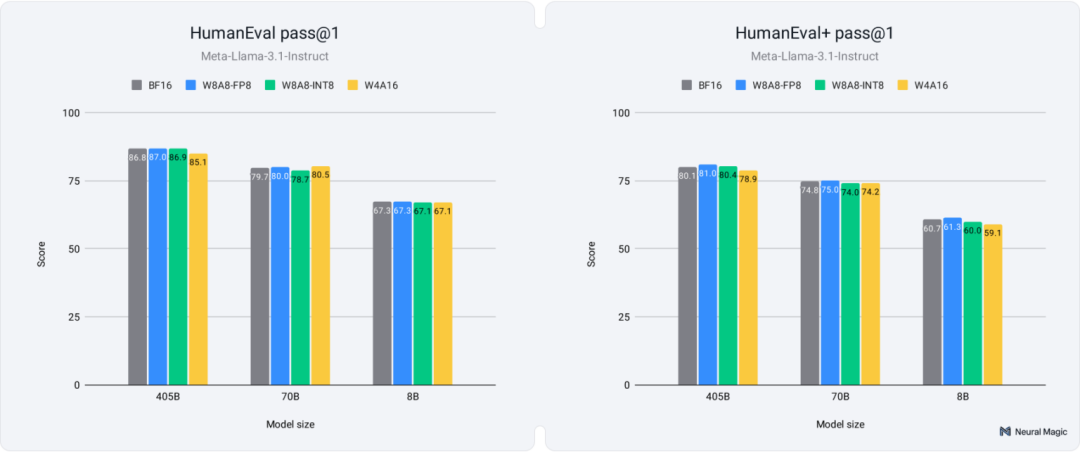
如图5所示,量化模型在HumanEval和HumanEval+上均表现出色,8-bit模型实现了99.9%的准确率恢复,4-bit模型则达到了98.9%。
这些结果表明,量化模型不仅在较简单的编码任务中保持高性能,而且在较复杂的场景中也表现优异,证明了它们在实际编码应用中的可靠性,并且准确率损失最小。
4
文本相似度与人工检查
在对量化模型进行了各种学术和实际基准测试的评估后,我们进行了最终测试:量化模型生成的文本与未量化模型的文本相似度是多少?
我们使用了四个关键指标来回答这个问题:
-
ROUGE-1用于衡量量化模型和未量化模型输出之间的词级重叠程度。
-
ROUGE-L通过关注最长公共子序列来捕获结构相似性。
-
BERTScore在词元层面评估上下文相似性。
-
STS在句子层面评估整体语义相似性。
指标基于ArenaHard提示生成的响应计算得出,使我们能够分析量化模型在保持输出的意义和结构方面与全精度模型相比的表现如何。结果汇总如下图6所示。
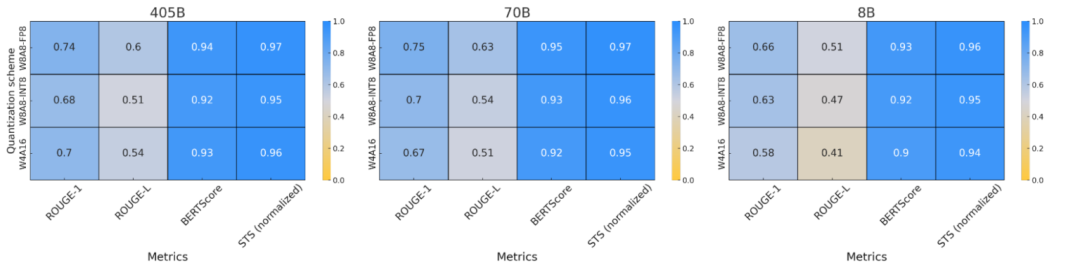
结果表明,较大的量化模型(70B和405B)与全精度模型保持了较高的文本相似度,ROUGE-1和 ROUGE-L得分显示其在词汇选择和结构方面保留程度良好。BERTScore和STS进一步证实,即使量化引入了细微的词元变化,但整体含义仍保持一致。虽然8B模型在词汇选择方面表现出更大的变异性,但它们仍然保留了核心语义,如BERTScore和STS结果所示。这表明量化模型在所有模型大小和量化方案中都能保持高质量的输出。
到目前为止,我们已经使用了各种基准和比较指标来评估量化模型的性能,并将其提炼为原始数据。现在,是时候亲自看看结果了。我们的交互式演示应用(基于出色的HuggingFace Spaces构建)可让你选择不同的模型和量化方案,以将生成的响应与全精度响应并排比较。该工具提供了一种直观的方式,以评估量化对模型输出以及生成文本质量的影响(https://huggingface.co/collections/neuralmagic/llama-31-quantization-66a3f907f48d07feabb8f300)。
5
量化为何会继续存在
总之,我们的全面评估表明,与全精度模型相比,量化模型保持了令人印象深刻的准确性和高质量,使其成为在实际部署中优化LLM的重要工具。
-
性能一致:8-bit和4-bit量化LLM在各种基准测试中表现出非常有竞争力的准确度恢复,包括Arena-Hard、OpenLLM Leaderboards v1和v2以及HumanEval和HumanEval+等编码基准测试。
-
最小权衡:较大模型(70B、405B)表现出可忽略不计的性能下降。相比之下,较小的模型(8B)可能会出现轻微的变化,但仍保留其输出的核心语义和结构一致性。
-
高效和可扩展:量化实现了显著地节省计算成本,并有更快的推理速度,同时保持了响应的语义质量和可靠性。
这些发现证实,量化在成本、能源和性能方面提供了巨大的优势,同时又不会牺牲模型的完整性。随着LLM规模和复杂性的增长,量化将在帮助组织高效部署最先进模型方面发挥关键作用。
其他人都在看
让超级产品开发者实现“Token自由”
邀请好友体验SiliconCloud,狂送2000万Token/人
邀请越多,Token奖励越多
siliconflow.cn/zh-cn/siliconcloud