前言
B+Tree 被数据库普遍使用,作为索引实现的基础。网上的资料也非常多,所以这里也不再详细介绍。但是基于 B+Tree 的并发优化,资料却非常少,所以这篇来讲讲 B+Tree 的一种并发优化,那就是BLink-Tree。为了讲述得更加清楚,我会通过图的形式,来详细阐述每一步骤。
BLink-Tree 结构
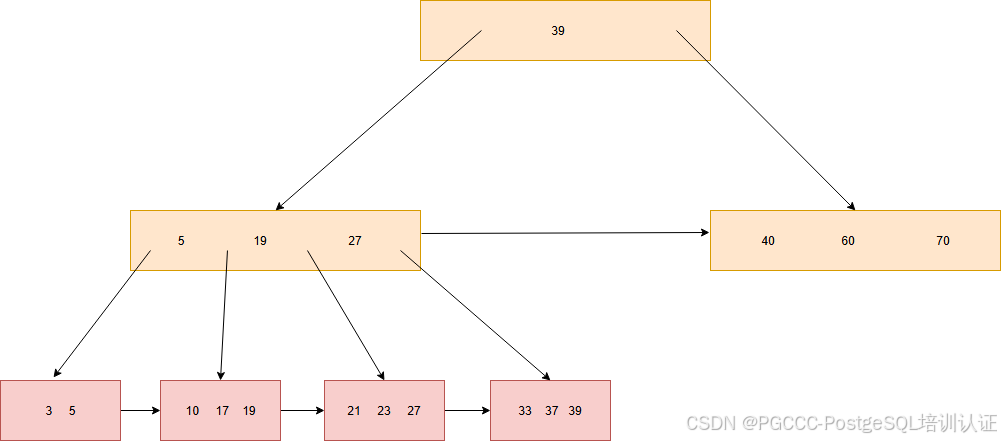
BLink-Tree,它与传统的 B+Tree 区别,就是非叶子节点,也会有个指向同层级的旁边节点的指针。这个指针在优化并发上面,起到了核心作用。下图展示了一个BLink-Tree,我们接下来的操作都是以这棵树为例。这里我将右边的叶子节点都省略掉了,因为下面的节点都没有涉及到它。
数据插入
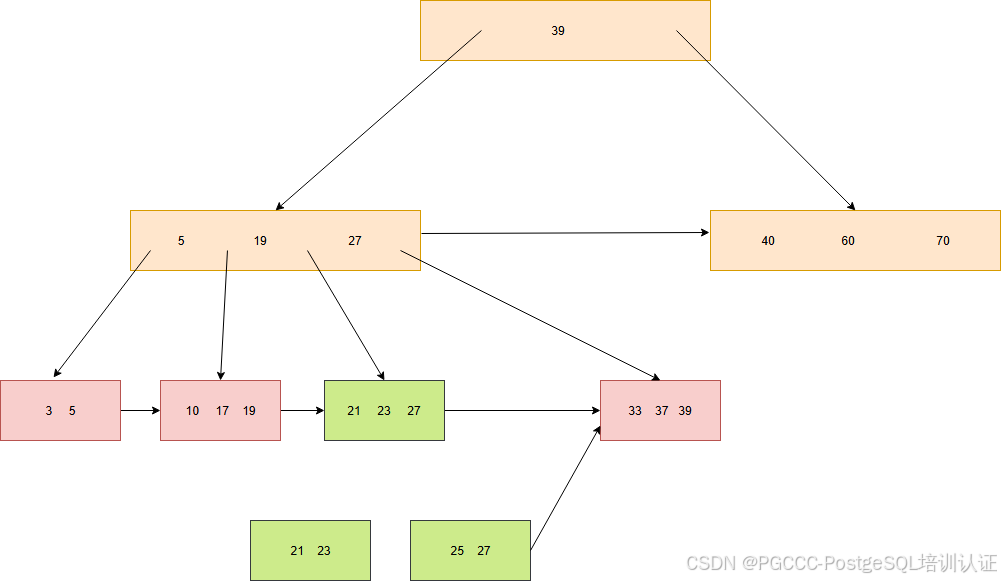
这里先讲解 BLink-Tree 的插入操作,这里设计了一个相对复杂的场景,会触发多个父节点分裂。假设现在插入数据 25,首先我们找到对应的叶子节点(左边第三个),然后对该节点加锁。此时检查到该节点的数据已经满了,需要触发分裂操作,步骤如下图所示。
首先计算出分裂后的节点,也就是(21, 23)和 (25,27)两个节点。这里仅仅讲(25,27)这个节点的右指针指向了节点(33,27,39)。
然后将(21,23,27)节点的内容原地修改,改成(21, 23),同时将右指针指向节点(25,27),然后会释放之前的锁(我们在向节点添加元素前,会先加锁)。
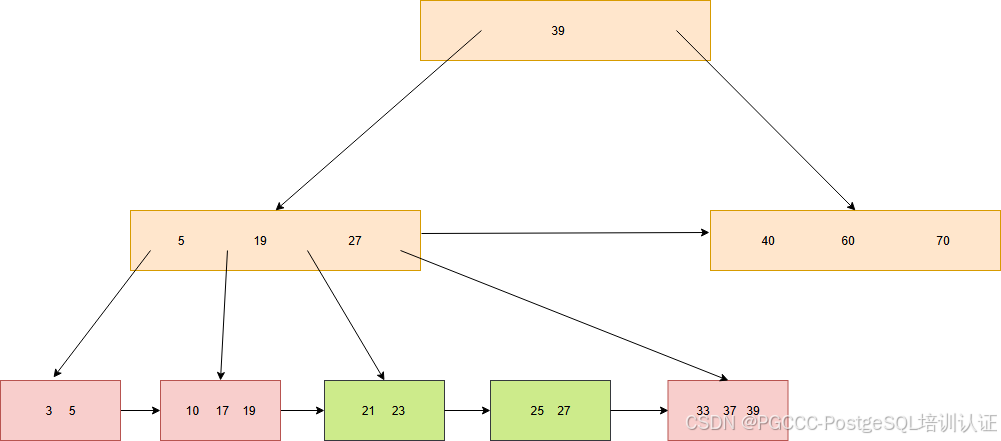
接下来我们需要向父节点添加 23 这个元素,这样才能构成标准的B+Tree。首先我们需要获取父节点(5,19,27)的锁,然后添加元素时,发现节点已经满了,必须触发分裂操作。
分裂操作同上面的相同。首先计算出分裂后的节点,将(23,27)节点的右指针指向节点(40,60,70)。
然后原地将节点(5,19,27)修改为(5,19),同时右指针指向节点(23,27)。此时就可以释放之前的锁。
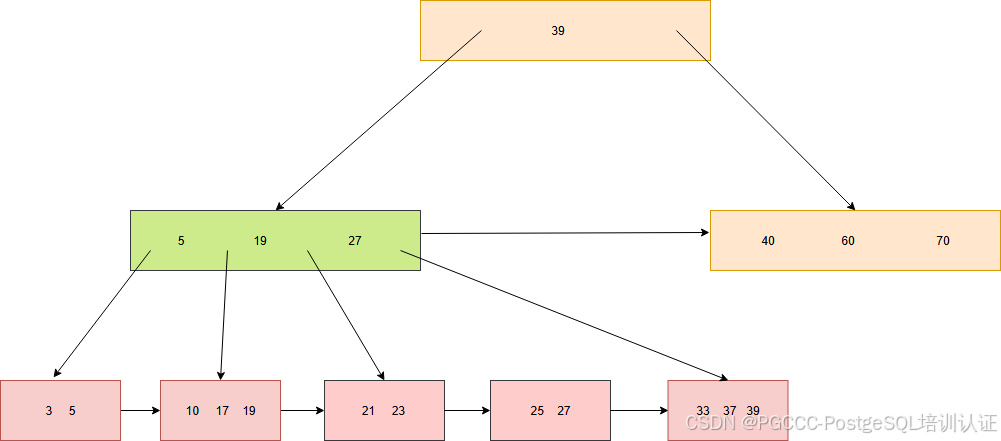
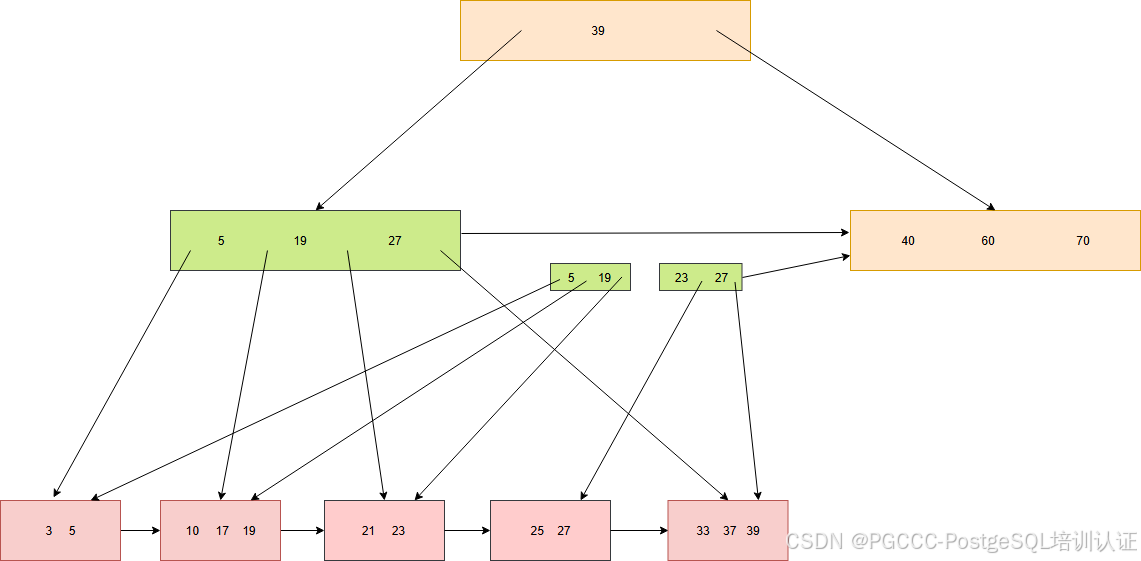
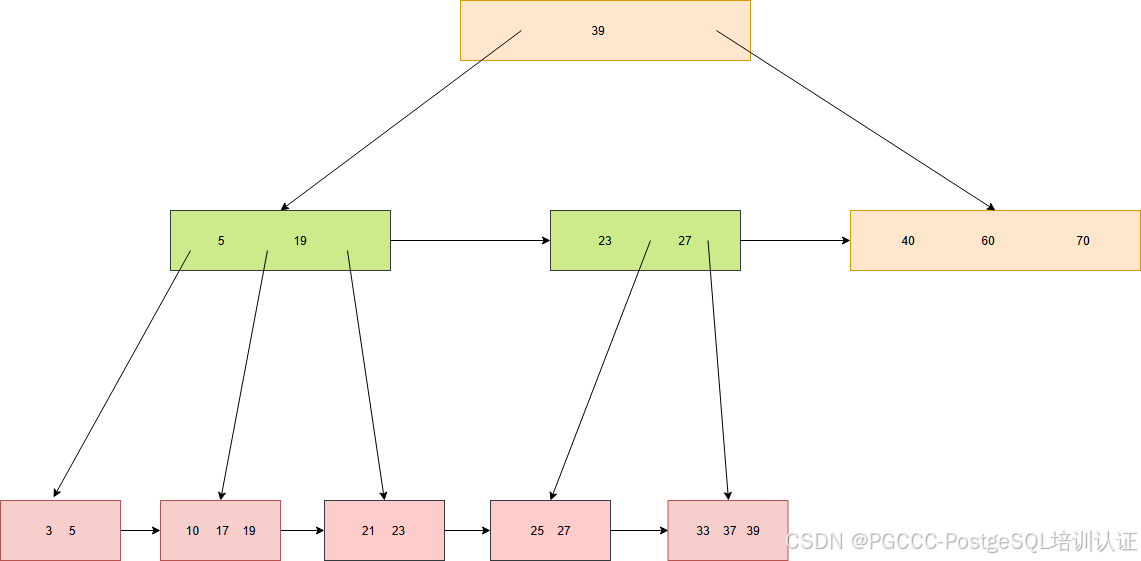
同样完成分裂节点后,还需要继续向父节点添加元素。这里先加锁节点(39),发现并不需要分裂,所以就直接添加。
回顾数据插入的过程,发现加锁的顺序都是从下向上的,所以不会造成死锁。
数据查找
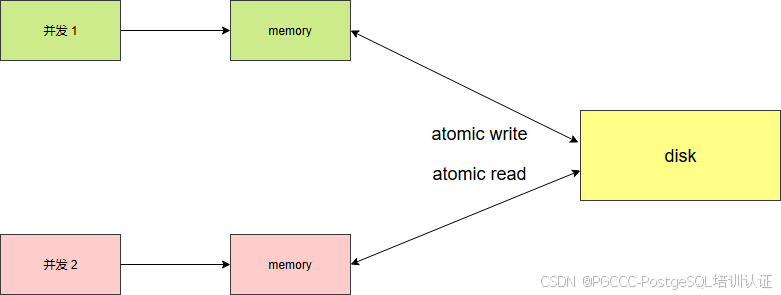
这里需要提下 BLink-Tree 论文适用的场景,它认为数据都是存储在磁盘里的,并且磁盘可以提供原子性的读写。也就是说对于单个节点的读写都是一瞬间完成的,是原子性的。对节点的加锁只是防止节点的并发写,并不会阻塞节点的都操作。
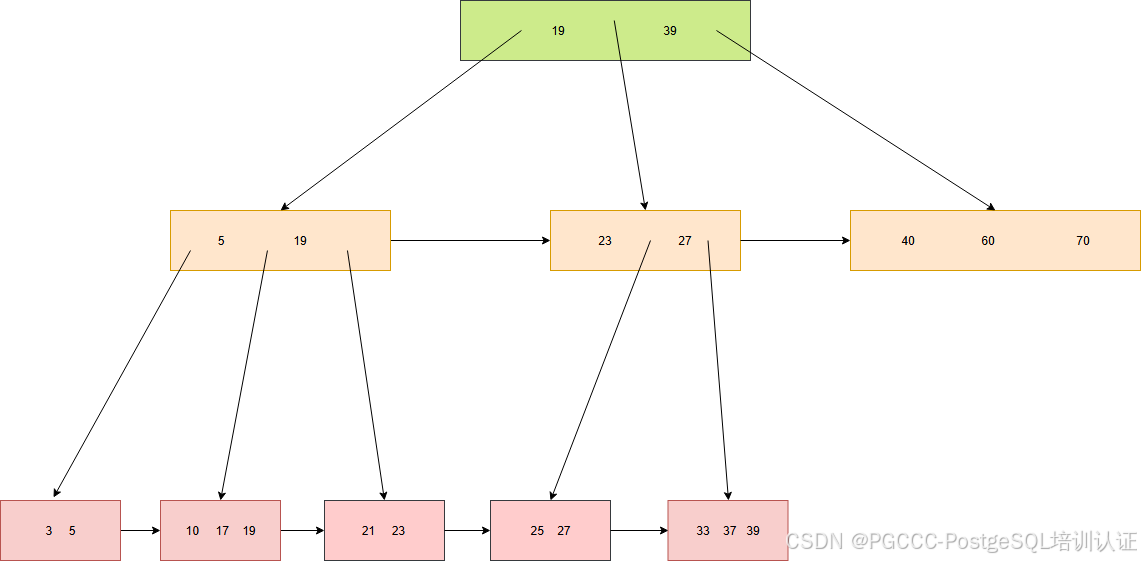
我们以第五步的图为例,这时我们寻找 值为 27 的数据,查找路径如下所示:
当发找到(5,19)节点时,发现要查找的数据 27 比它们都大时,还会试图去找右边的节点。结果发现 27 处于右边节点,所以它才会向下继续寻找子节点。
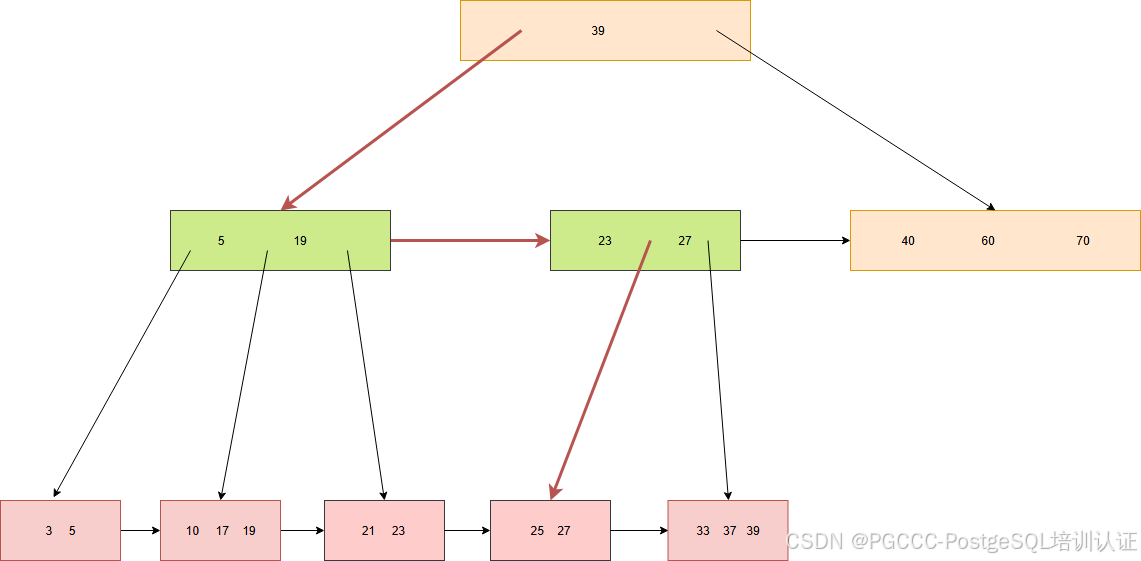
我们同样可以分裂操作时的每一步来看,发现每次数据查找都是没有问题的。因为有了右指针,所以巧妙的避开了读写冲突,还能正确的找到结果。
适用场景
在上面已经讲解了 BLink-Tree 的适用场景,如下图所示:
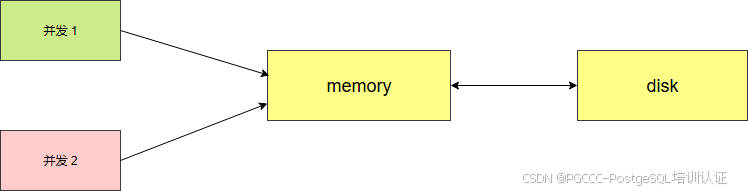
但是在 postgresql 数据库中却不适用。因为数据的读写都时先在共享内存中,并且外部存储也不一定提供原子性的读写。
所以 postgresql 在数据查找时,加上了读锁。而在数据插入时,需要加上写锁,虽然并发性降低了,但是保证了数据的准确性。
作者:zhmin
链接:https://zhmin.github.io/posts/blink-tree/
#PG证书#PG考试#PostgreSQL培训#PostgreSQL考试#PostgreSQL认证