论文传送门:Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
前置文章:ViT模型——pytorch实现
Swin Transformer的特点:
相较于ViT:
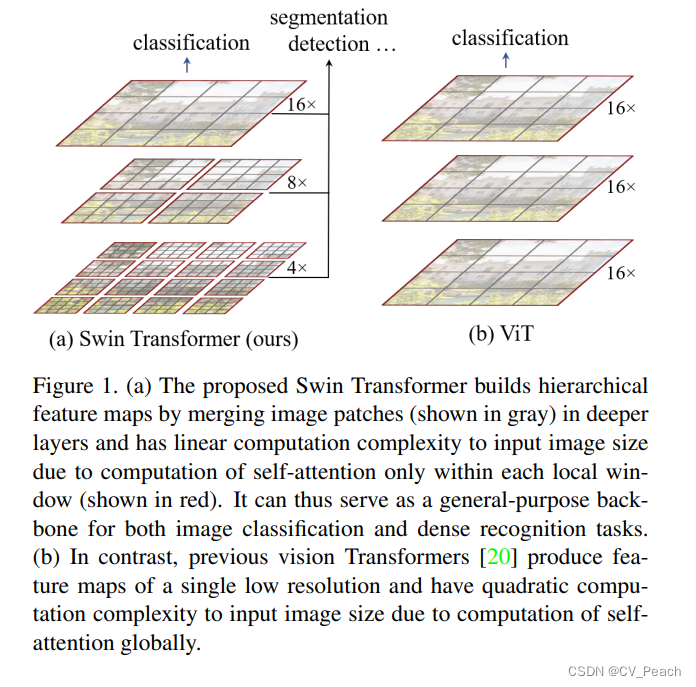
①采用逐渐递增的下采样倍数,获得具有层次的特征图(hierarchical feature maps),便于进行检测和分割任务;
②引入W-MSA(Windows Multi-Head Self-Attention)和SW-MSA(Shifted Windows Multi-Head Self-Attention),减少了计算量。
W-MSA和SW-MSA:
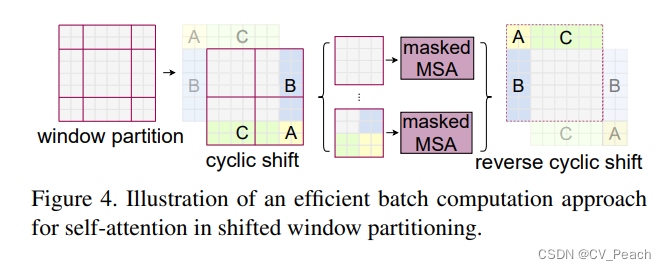
W-MSA是将特征图划分成一个个Window,然后在每个Window中进行Patch的划分和Attention的计算,这样可以减少计算量,但同时也使得不同Window之间无法进行信息交互;
因此,作者又提出SW-MSA,即偏移的W-MSA,具体做法为将原本划分Windows的网格向右、向下平移window_size//2长度,然后通过平移拼接将小块的Window拼接成整块Window,从而保证与W-MSA的Windows数量相同,同时生成mask,将原本不相邻的区域的tokens(patches)设为-100,在Attention计算时,与attention( Q K T QK^T QKT)相加,使得不相邻的区域的attention经过softmax后趋近于0,避免不相邻区域的干扰,经过Attention后再将拼接的Windows拆分,反向平移还原回原特征图。
Relative Position Bias:
在Attention计算中,引入一个偏置项B,B从一个可训练的矩阵(relative positon bias matrix)中取,索引为每个token(patch)的相对位置索引(经过一些变换)。

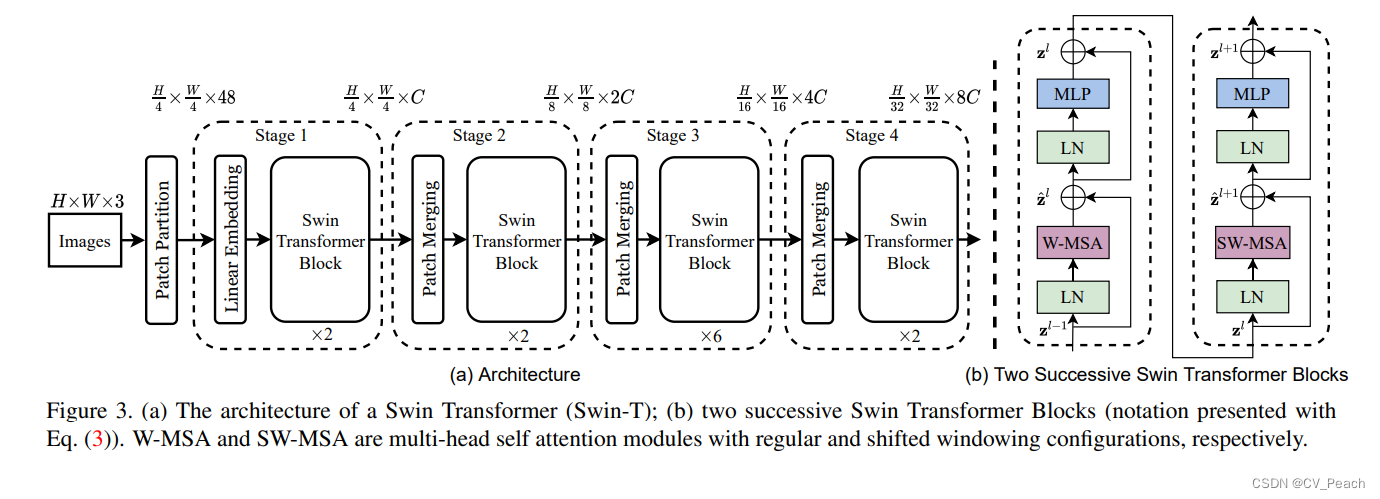
Swin Transformer的结构:
①Patch Partition:将输入图片用4x4的窗口划分,并在Channel通道堆叠,代码中使用Conv2d实现;
②Linear Embedding:将H和W维度展平;
(代码中将Patch Partition和Linear Embedding通过一个Patch Embedding实现)
③Swin Transformer Block:成对出现,整个结构与ViT中的Transformer Block相同,只是把MSA替换成了W-MSA和SW-MSA,第奇数个Block使用W-MSA,第偶数个Block使用SW-MSA(二者交替使用);
④Patch Merging:下采样方法,类似focus,每次Patch Merging先使高H、宽W减半,通道C翻4倍,然后通过一个Linear将C减半,即最后C为原来的2倍;
Stage:Linear Embedding/Patch Merging + L * Swin Transformer Block
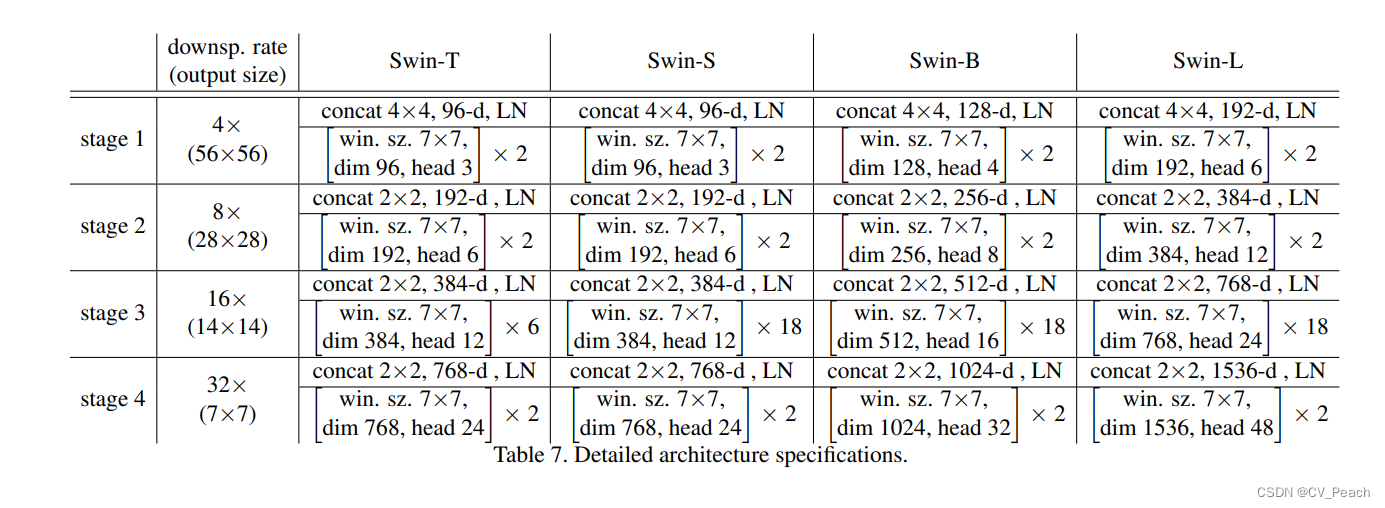
不同规模的Swin Transformer模型:
import torch
import torch.nn as nn
import torch.nn.functional as F
from einops import rearrange
def drop_path_f(x, drop_prob: float = 0., training: bool = False):
"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
This is the same as the DropConnect impl I created for EfficientNet, etc networks, however,
the original name is misleading as 'Drop Connect' is a different form of dropout in a separate paper...
See discussion: https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ... I've opted for
changing the layer and argument names to 'drop path' rather than mix DropConnect as a layer name and use
'survival rate' as the argument.
"""
if drop_prob == 0. or not training:
return x
keep_prob = 1 - drop_prob
shape = (x.shape[0],) + (1,) * (x.ndim - 1) # work with diff dim tensors, not just 2D ConvNets
random_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device)
random_tensor.floor_() # binarize
output = x.div(keep_prob) * random_tensor
return output
class DropPath(nn.Module):
"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
"""
def __init__(self, drop_prob=None):
super(DropPath, self).__init__()
self.drop_prob = drop_prob
def forward(self, x):
return drop_path_f(x, self.drop_prob, self.training)
class PatchEmbedding(nn.Module): # Patch Partition + Linear Embedding
def __init__(self, patch_size=4, in_channels=3, emb_dim=96):
super(PatchEmbedding, self).__init__()
self.conv = nn.Conv2d(in_channels, emb_dim, patch_size, patch_size) # 4x4卷积实现Patch Partition
def forward(self, x):
# (B,C,H,W)
x = self.conv(x)
_, _, H, W = x.shape
x = rearrange(x, "B C H W -> B (H W) C") # Linear Embedding
return x, H, W
class MLP(nn.Module): # MLP
def __init__(self, in_dim, hidden_dim=None, drop_ratio=0.):
super(MLP, self).__init__()
if hidden_dim is None:
hidden_dim = in_dim * 4 # linear的hidden_dims默认为in_dims的4倍
self.fc1 = nn.Linear(in_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, in_dim)
self.gelu = nn.GELU()
self.dropout = nn.Dropout(drop_ratio)
def forward(self, x):
# Linear + GELU + Dropout + Linear + Dropout
x = self.fc1(x)
x = self.gelu(x)
x = self.dropout(x)
x = self.fc2(x)
x = self.dropout(x)
return x
class WindowMultiHeadSelfAttention(nn.Module): # W-MSA / SW-MSA
def __init__(self, dim, window_size, num_heads,
attn_drop_ratio=0., proj_drop_ratio=0.):
super(WindowMultiHeadSelfAttention, s