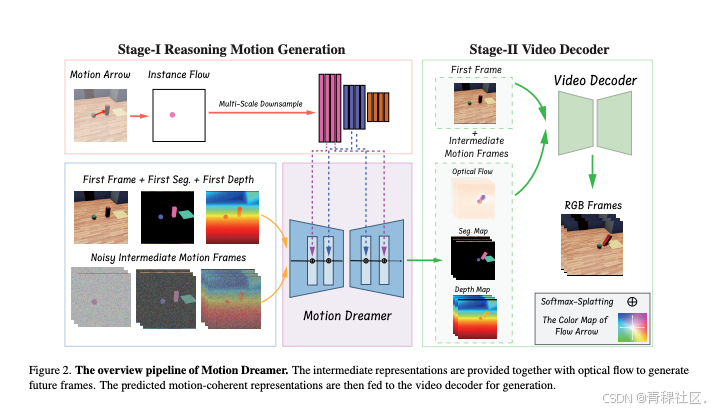
为何现有视频生成模型难以理解物理世界,无法生成运动合理的视频结果?基于认知心理学研究,我们重新审视现有视频生成模型,认为生成运动合理的视频其实是和生成高视觉质量视频同样困难的任务,而现有一阶段建模方式更关注视觉质量,缺少对运动的关注。

为此,香港科技大学(广州)的研究者提出了两阶段模型 Motion Dreamer,通过生成中间运动表示,将运动和视觉质量进行解耦,从而生成运动合理且高视觉质量的视频。
Abs:https://arxiv.org/pdf/2412.00547
1月14日19:00,青稞Talk 第37期,香港科技大学(广州)博士生许添硕,将直播分享《Motion Dreamer:面向自动驾驶与物理世界对齐的视频生成模型》。
许添硕,香港科技大学(广州)博士生,导师为陈颖聪教授,研究兴趣是自动驾驶、视频生成。