LLM Based 综述
之前的一些研究更加注重算法设计和训练策略,而忽视了模型固有的通用能力的发展,如知识记忆、长期规划、有效泛化和高效互动等。事实证明,增强模型固有能力是推动智能代理进一步发展的关键因素。
如果将 NLP 到 AGI 的发展路线分为五级:语料库、互联网、感知、具身和社会属性,那么目前的大型语言模型已经来到了第二级,具有互联网规模的文本输入和输出。
在这个基础上,如果赋予 LLM-based Agents 感知空间和行动空间,它们将达到第三、第四级。进一步地,多个代理通过互动、合作解决更复杂的任务,或者反映出现实世界的社会行为,则有潜力来到第五级 —— 代理社会
Agent核心组件
Agent的框架主要由三个部分组成:
控制端(Brain)、感知端(Perception)和行动端(Action)
- 控制端:通常由 LLMs 构成,是智能代理的核心。
- 它可以存储记忆和知识
- 它承担着信息处理、决策等不可或缺的功能。
- 它可以呈现推理和计划的过程,并很好地应对未知任务,反映出智能代理的泛化性和迁移性。
- 感知端:将智能代理的感知空间从纯文本拓展到包括文本、视觉和听觉等多模态领域,使代理能够更有效地从周围环境中获取与利用信息。
- 行动端:除了常规的文本输出,还赋予代理具身能力、使用工具的能力,使其能够更好地适应环境变化,通过反馈与环境交互,甚至能够塑造环境。Minecraft中是输出可执行的代码。
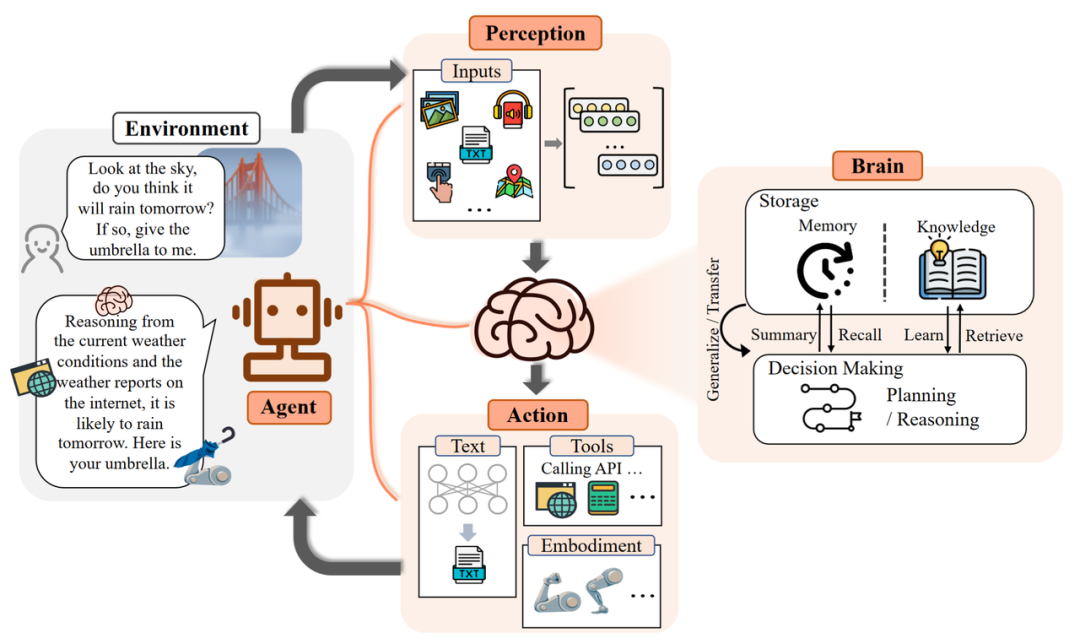
作者们用一个例子来说明来了 LLM-based Agent 的工作流程:
- 当人类询问是否会下雨时,感知端(Perception)将指令转换为 LLMs 可以理解的表示。
- 然后控制端(Brain)开始根据当前天气和互联网上的天气预报进行推理和行动规划。
- 最后,行动端(Action)做出响应并将雨伞递给人类。
- 通过重复上述过程,智能代理可以不断获得反馈并与环境交互。
控制端:Brain
自然语言交互:
语言是沟通的媒介,其中包含着丰富的信息。得益于 LLMs 强大的自然语言生成和理解能力,智能代理能够通过自然语言与外界进行多轮交互,进而实现目标。
- 多轮对话:动态的多轮对话包括多个体、多话题、缺少连续性的特点。通常分为以下三步:
- 理解历史对话
- 决定采取何种行动
- 生成自然语言的回复
- 高质量文本生成:大量评估实验表明,LLMs 能够生成流畅、多样、新颖、可控的文本。尽管在个别语言上表现欠佳,但整体上具备良好的多语言能力。
- 意图和隐含语义的理解:除了直观表现出的内容,语言背后可能还传递了说话者的意图、偏好等信息。言外之意有助于代理更高效地沟通与合作,大模型已经展现出了这方面的潜力。
奖励建模的主要方法之一是根据反馈推断奖励,主要以比较的形式呈现(可能还会补充原因),以及无约束的自然语言。(判断是否正确,正确反馈Success,错误反馈Failed)- 另一种方法是通过行动空间作为桥梁,从描述中恢复奖励(之前的action错了,返回执行错误的信息进行反馈)。Jeon等人指出,人类行为可以映射到一个隐含的选项集合中的选择,这有助于将所有信息解释为一个统一的形式。通过利用对环境的理解,智能体可以采取高度个性化和准确的行动,以满足特定要求。
知识:
基于大批量语料训练的 LLMs,拥有了存储海量知识(Knowledge)的能力。
- 多语言知识
- 常识知识: 常识知识通常不会在上下文中提及,但是缺少它将会导致做出错误的决策
- 专业技能知识:垂直领域微调
虽然 LLMs 其本身仍然存在知识过期、幻觉等问题,现有的一些研究通过知识编辑或调用外部知识库等方法,可以在一定程度上得到缓解。
记忆:
在本文框架中,记忆模块(Memory)储存了代理过往的观察、思考和行动序列。通过特定的记忆机制,代理可以有效地反思并应用先前的策略,使其借鉴过去的经验来适应陌生的环境。
两个主要的挑战:
1) 历史对话记录的长度。直接把历史对话记录拼接到子对话的前面会让超过模型的max squence length
2)获取最相关的记忆信息。模型存储轮非常多的abservation和action,如何在上下文中获取最相关的topic信息。
通常用于提升记忆能力的方法有三种:
-
扩展 Backbone 架构的长度限制:针对 Transformers 固有的序列长度限制问题进行改进。(改进模型)
- 随着序列长度的增加,由于自注意机制中的成对标记计算,计算需求呈指数增长。缓解这些长度限制的策略包括
文本截断、分段输入和强调文本的关键部分。其他一些方法修改注意机制以减少复杂性,从而适应更长的序列。
- 随着序列长度的增加,由于自注意机制中的成对标记计算,计算需求呈指数增长。缓解这些长度限制的策略包括
-
总结记忆(Summarizing):对记忆进行摘要总结,增强代理从记忆中提取关键细节的能力。(改进Prompt)
- 简洁地整合记忆
- 强调反思过程来创建简化的记忆表示
- 分层方法将对话整理成每日快照和总体摘要
- 特定的策略将环境反馈转化为文本概括,增强了代理人对未来交流的上下文把握能力
-
压缩记忆(Compressing):通过使用向量或适当的数据结构对记忆进行压缩,可以提高记忆检索效率。(改进向量数据库)
- 使用嵌入向量来表示记忆部分、计划或对话历史记录
- 将句子转化为三元组配置
- 将记忆视为一个独特的数据对象,促进了多样化的交互
- ChatDB 和 DB-GPT 将 LLMrollers 与 SQL 数据库集成,通过 SQL 命令实现数据操作
-
记忆的检索方法也很重要,只有检索到合适的内容,代理才能够访问到最近、最相关和准确的信息,可以通过这三个角度给一个分数来评估。(LLM自己生存技能描述的Text作为index以此来做检索增强)
- 一些研究引入了交互式记忆对象的概念,它们是对话历史记录的表示形式,可以通过摘要移动、编辑、删除或合并。用户可以查看和操作这些对象,影响代理程序对对话的感知
- 其他研究允许基于用户提供的特定命令进行删除等记忆操作。这样的方法确保记忆内容与用户的期望密切相关
推理和规划
推理:
一些人认为语言模型在预训练或微调过程中就具备了推理能力,而另一些人则认为它在达到一定规模后才会出现。具体而言,代表性的思维链(CoT)方法(通过在输出答案之前引导大型语言模型生成推理依据,可以激发其推理能力)
一些策略来提高大型语言模型的性能,例如自一致性、自我优化、自我改进和选择推理。
- 逐步推理的有效性可以归因于训练数据的局部统计结构,局部结构化变量之间的依赖关系比对所有变量进行训练具有更高的数据效率
规划:
-
计划的制定:1) 一次性生成整个计划 2)分成若干个子任务,一次执行一个子任务 3)将任务进行层级划分类似树状(路径规划的思想,选一条最优的路径执行)
-
给大模型添加垂直领域的知识会表现更好 -
计划反思: 反馈机制。在制定计划后,可以进行反思并评估其优劣。这种反思一般来自三个方面:1)借助LLM的内部反馈机制;2)与人类互动获得反馈;3)从环境中获得反馈。
-
对未知任务的泛化:随着模型规模与训练数据的增大,LLMs 在解决未知任务上涌现出了惊人的能力。通过指令微调的大模型在 zero-shot 测试中表现良好,在许多任务上都取得了不亚于专家模型的成绩。
-
情景学习(In-context Learning):大模型不仅能够从上下文的少量示例中进行类比学习,这种能力还可以扩展到文本以外的多模态场景,为代理在现实世界中的应用提供了更多可能性。
-
持续学习(Continual Learning):持续学习的主要挑战是灾难性遗忘,即当模型学习新任务时容易丢失过往任务中的知识。专有领域的智能代理应当尽量避免丢失通用领域的知识。
- 三种类型的方法:1)参考之前模型的常用术语 2)逼近先前的数据分布 3)以及设计具有任务自适应参数的体系结构。
感知端 Preception
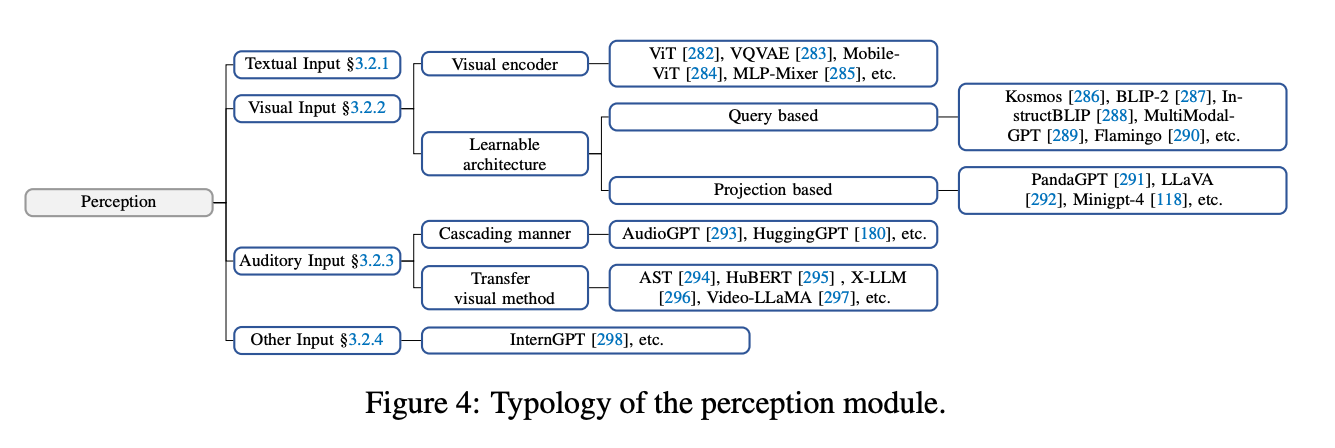
文本输入:
作为 LLMs 最基础的能力,这里不再赘述。
视觉输入:
LLMs 本身并不具备视觉的感知能力,只能理解离散的文本内容。而视觉输入通常包含有关世界的大量信息,包括对象的属性,空间关系,场景布局等等。常见的方法有:
- 将视觉输入转为对应的文本描述(Image Captioning):可以被 LLMs 直接理解,并且可解释性高。
- 对视觉信息进行编码表示:以视觉基础模型(ViT) + LLMs 的范式来构成感知模块,通过对齐操作来让模型理解不同模态的内容,可以端到端的方式进行训练。但问题是计算资源耗费太大
- 视觉编码需要和LLM对齐。LLM无法理解visual encoder的输入,需要转换成embedding后的编码。例如使用BLIP-2就使用了Q-Former(Q-Former is a transformer that employs learnable query vectors, giving it the capability to extract language-informative visual representations)
- 同时,一些研究人员采用了一种计算效率高的方法,通过使用单个投影层来实现视觉文本对齐,从而减少了训练额外参数的需求。此外,投影层可以与可学习接口有效地集成,以适应其输出的维度,使其与LLM兼容。
听觉输入:
听觉也是人类感知中的重要组成部分。由于 LLMs 有着优秀的工具调用能力,一个直观的想法就是:代理可以将 LLMs 作为控制枢纽,通过级联的方式调用现有的工具集或者专家模型,感知音频信息。
此外,音频也可以通过频谱图(Spectrogram)的方式进行直观表示。频谱图可以作为平面图像来展示 2D 信息,因此,一些视觉的处理方法可以迁移到语音领域,例如AST (Audio Spectrogram Transformer)。
- 冻结encoder层来减少训练时间和开销
- 加入一些可学习的参数接口层来对齐语音和数据的编码对齐
其他输入:
现实世界中的信息远不止文本、视觉和听觉。作者们希望在未来,智能代理能配备更丰富的感知模块,例如触觉、嗅觉等器官,用于获取目标物体更加丰富的属性。同时,代理也能对周围环境的温度、湿度和明暗程度有清楚的感受,采取更 Environment-aware 的行动。
此外,还可以为代理引入对更广阔的整体环境的感知:
- 采用激光雷达( 3D point cloud maps)
- GPS(location coordinates)
- 惯性测量单元( measure and record the three-dimensional motion of object)等成熟的感知模块。
Action
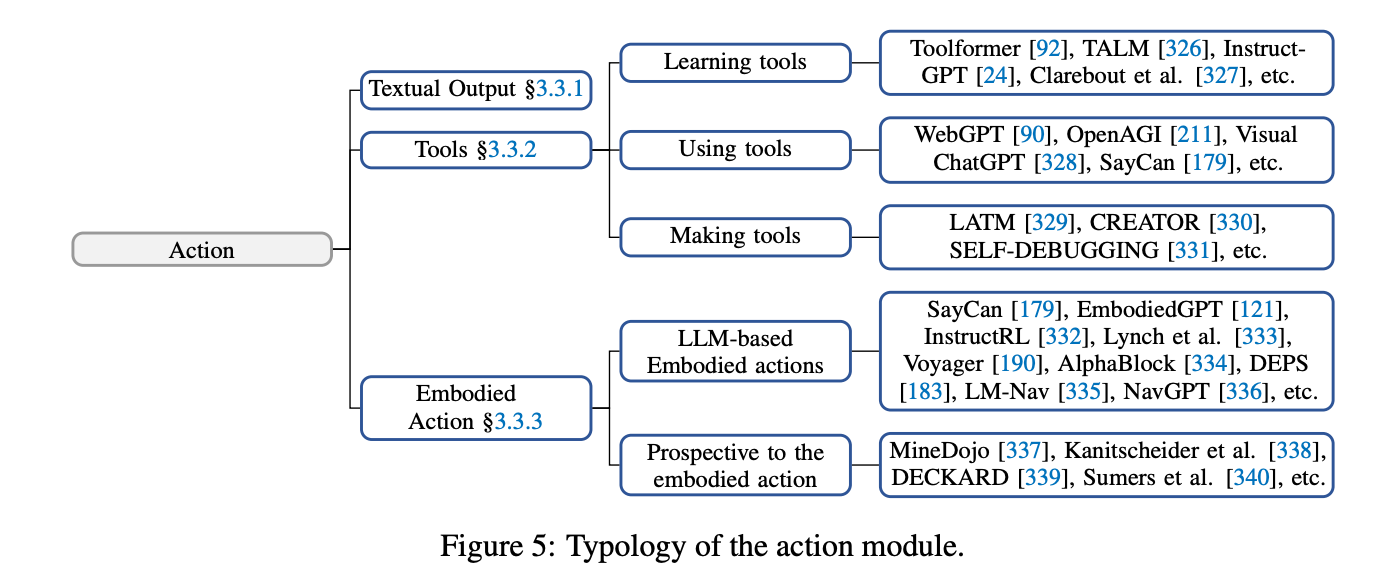
Using Tools
- 专业化工具使得LLM能够增强其专业知识,适应领域知识,并以可插拔的形式更适合特定领域的需求。
尽管 LLMs 拥有出色的知识储备和专业能力,但在面对具体问题时,也可能会出现鲁棒性问题、幻觉等一系列挑战。
-
知识遗忘和幻觉死循环。尽管基于LLM的代理程序具有强大的知识库和专业知识,但它们没有能力记住每一条训练数据。由于上下文提示的影响,它们可能无法引导到正确的知识,甚至可能生成虚假的知识。
- 由于缺乏特定领域和场景的语料库、训练数据和调优,代理程序在专门化特定领域时的专业知识也是有限的。
- 基于LLM的代理程序的决策过程缺乏透明度和可信度,在医疗保健和金融等高风险领域中,它们的可信度较低。
-
容易受到对抗性攻击,对于轻微的输入修改的鲁棒性不足。
-
工具是专门为各自的使用场景设计的,利用这些工具的代理程序更能处理轻微的输入修改,并且对抗性攻击的韧性更强。
理解工具:
所谓Tools的使用方式:
- zero shot prompt去描述工具的用途的参数
- few shot prompt去描述工具的具体使用场景和方法
学习使用工具的方法:
- 从案例中学习。
- 从反馈中学习。从环境和人类反馈中学习
- 学习工具与工具之间的关系,简单和复杂工具的关系
- 此外,也可以通过元学习、课程学习等方式来让代理程序在使用各种工具方面具备泛化能力。更进一步,智能代理还可以进一步学习如何「自给自足」地制造工具,从而提高其自主性和独立性。
具体工具如何使用?
- 代理程序可以在推理和规划阶段利用各种外部资源。基于搜索的工具可以通过外部数据库、知识图谱和网页的帮助改进代理程序访问的知识范围和质量,而特定领域的工具可以增强代理程序在相应领域的专业知识
- 基于LLM的代理程序可以使用科学工具来执行化学中的有机合成等任务,或者与Python解释器进行交互,提升在复杂数学计算任务上的性能。
- 于多代理系统,通信工具(例如电子邮件)可以作为代理程序在严格安全约束下相互交互的手段,促进它们的协作,并展示自治性和灵活性
- 尽管之前提到的工具增强了代理程序的能力,但与环境的交互媒介仍然是基于文本的。然而,工具的设计是为了扩展语言模型的功能,它们的输出不仅限于文本。非文本输出的工具可以使代理程序行动的模态多样化,从而扩大基于LLM的代理程序的应用场景。
例如,一个代理程序可以借助视觉模型进行图像处理和生成 [328]。在航空航天工程领域,研究人员正在探索使用代理程序建模物理和解决复杂的微分方程 [356];在机器人领域,代理程序需要规划物理操作并控制机器人执行 [179];等等。能够通过工具以及以多模态方式与环境或世界动态交互的代理程序可以称为数字化体现的 [94]。代理程序的体现性已经成为体现学习研究的核心关注点。下面我们将深入讨论代理程序的体现行动。
Embodyment
具身行动:具身(Embodyment)是指代理与环境交互过程中,理解、改造环境并更新自身状态的能力。具身行动(Embodied Action)被视为虚拟智能与物理现实的互通桥梁。
传统的强化学习由于建模动态且常常含糊不清的真实环境或者过于依赖精确的奖励信号表示,强化学习算法在数据效率、泛化能力和复杂问题推理方面存在限制。
利用在LLM预训练期间获得的丰富内部知识可以有效缓解这些问题:
-
成本低。强化学习需要不断的收集数据来更新策略,而利用LLM的内在知识,像PaLM-E这样的代理程序可以联合训练机器人数据和通用视觉语言数据,从而在体现任务中实现显著的迁移能力,同时也展示了几何输入表示可以提高训练数据效率的优点
-
泛化能力强。大多数强化学习算法都是为特定任务训练和评估相关技能而设计的,LLM展示出了显著的跨任务泛化能力。
- zero shot prompt泛化
- 环境交互泛化
- Voyager 引入了技能库组件,以持续收集新的自验证技能,从而实现代理程序的终身学习能力。
-
行动规划。具有新兴推理能力的LLM[26]可以以零样本或少样本的方式无缝应用于复杂任务。此外,来自环境的外部反馈可以进一步提升基于LLM的代理程序的规划性能。
- 基于当前的环境反馈。动态生成、维护和调整高层行动计划,以在部分可观察环境中最大程度地减少对先前知识的依赖,从而使计划得到实际应用。
- 反馈还可以来自模型或人类,通常可以称为评论家(Critic)。根据当前状态和任务提示评估任务完成情况。
Observation:
- 观察主要发生在具有各种输入的环境中,最终这些输入会汇聚成为一个多模态信号。可以帮助智能代理在环境中定位自身位置、感知对象物品和获取其他环境信息;
- ViT作为文本和视觉信息的对齐模块,并标记特殊令牌以表示多模态数据的位置
- Soundspaces 提出了通过混响音频输入来指导物理空间几何元素的识别,从而以更全面的视角增强代理程序的观察能力
- 人类的实时语言指令,而人类的反馈则帮助代理程序获取可能无法轻易获得或解析的详细信息。
Manipulation
- 操纵则是完成一些具体的抓取、推动等操作任务;典型情况下,代理程序在厨房执行一系列任务,包括从抽屉中取出物品并递给用户,以及清理桌面。除了精确的观察,这还涉及通过利用LLM将一系列子目标组合在一起。因此,保持代理程序的状态与子目标的同步非常重要。
- DEPS 利用基于LLM的交互式规划方法来保持这种一致性,并在整个多步骤、长途推理过程中通过代理程序的反馈进行错误修正。
- 与现有的开环范式不同,AlphaBlock构建了一个包含35个复杂高级任务的数据集,以及相应的多步规划和观察对,并对多模态模型进行微调,以增强其对高级认知指令的理解能力
Navigation
-
Navigation 要求智能代理根据任务目标变换自身位置并根据环境信息更新自身状态,以及基于当前探索的长期操纵。在导航之前,具身代理程序建立起关于外部环境的先验内部地图非常重要,这些地图通常采用拓扑地图、语义地图或占据地图的形式
- LM-Nav 利用VNM 创建了一个内部拓扑地图。它进一步利用LLM和VLM来分解输入命令并分析环境,找到最优路径。
- 一些研究[380;381]强调了空间表示对于实现对空间目标的精确定位的重要性,而不是传统的基于点或对象的导航操作,通过利用预训练的VLM模型将图像的视觉特征与物理世界的3D重建相结合
- 导航通常是一个长期任务,代理程序的未来状态受其过去行动的影响。需要一个内存缓冲区和摘要机制作为历史信息的参考
- 一些工作提出音频输入也非常重要,但将音频信息与视觉环境关联起来存在挑战。一个基本的框架包括一个动态路径规划器,它使用视觉和听觉观察以及空间记忆来规划一系列导航动作
未来:
基于LLM的具身行动被视为虚拟智能与物理世界之间的桥梁,使代理程序能够像人类一样感知和修改环境。然而,仍然存在一些限制,例如物理世界机器人操作员的高成本和具身数据集的稀缺性,这促使人们对在Minecraft等模拟环境中研究代理程序的具身行动产生越来越大的兴趣。通过利用Mineflayer [387] API,这些研究可以成本效益地检查各种具身代理程序的操作,包括探索、规划、自我改进,甚至终身学习[190]。尽管取得了显著进展,但由于模拟平台和物理世界之间存在显著差异,实现最佳的具身行动仍然是一个挑战。为了在真实世界场景中有效部署具身代理程序,对于与真实世界条件密切相符的具身任务范例和评估标准的需求越来越大[358]。另一方面,为代理程序学习语言基础也是一个障碍。例如,“像猫一样跳下来”这样的表达主要传达一种轻盈和宁静的感觉,但这种语言的隐喻需要足够的世界知识[30]。[340]尝试将文本提炼与回顾式经验重放(HER)相结合,构建一个数据集作为训练过程的监督信号。然而,在各个领域中,具身行动在人类生活中发挥着越来越重要的作用,因此仍然需要进一步研究具身数据集的基础。
Vogayer
参考文章列表;
- https://zhuanlan.zhihu.com/p/632995675
- https://zhuanlan.zhihu.com/p/633145960
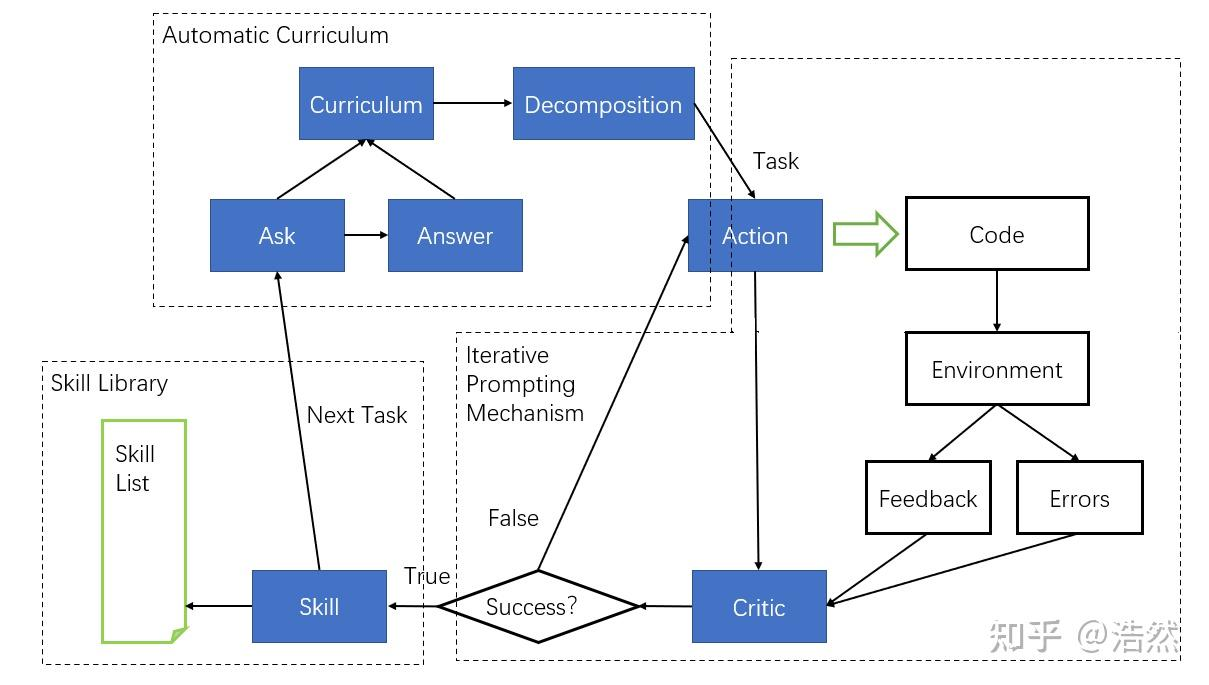
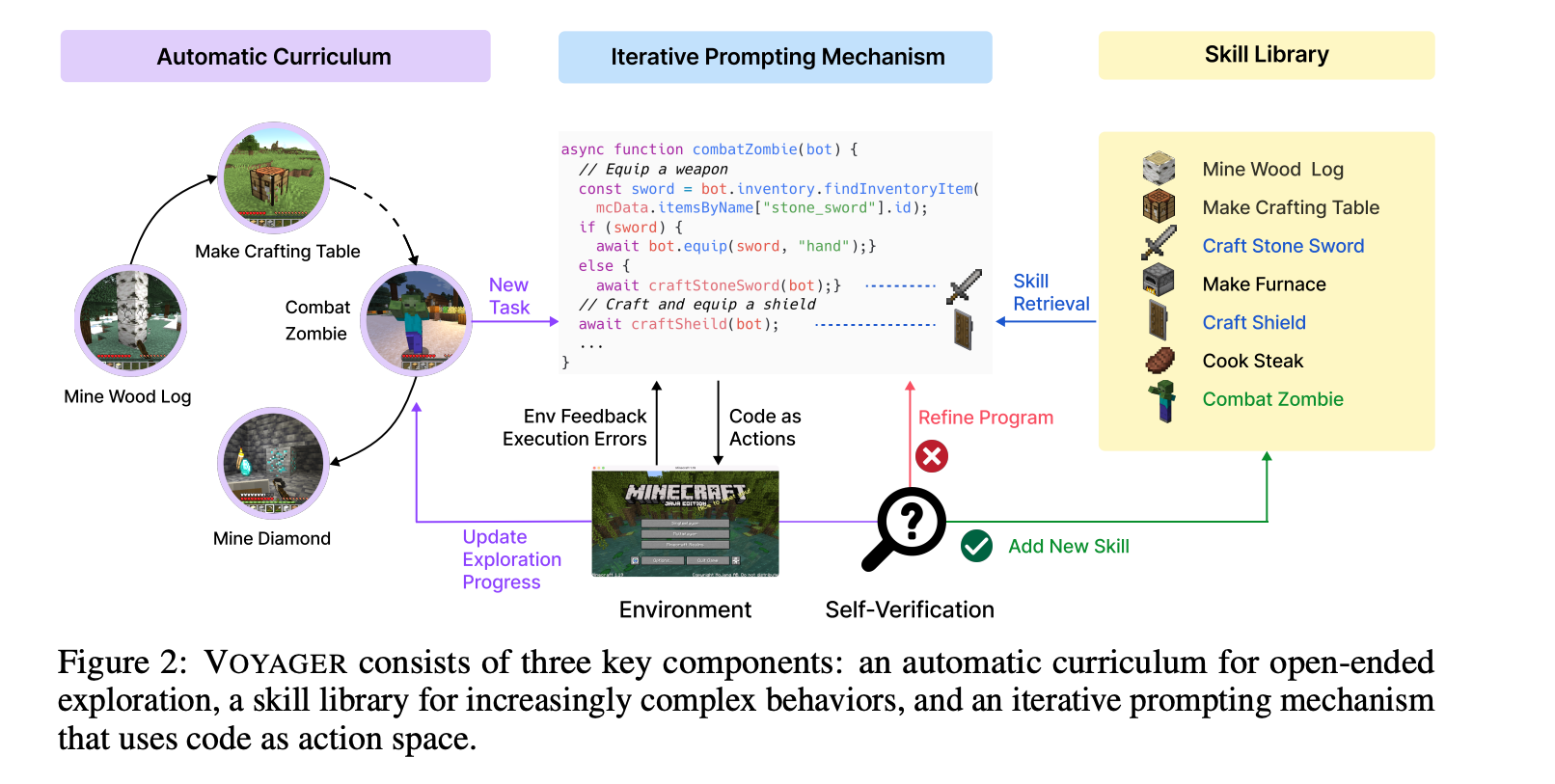
VOYAGER 包括 3 个部分:
1)一种最大化探索的自动课程
2)一个不断增长的可执行代码的技能库,用于存储和检索复杂行为
3)一种新的迭代式 prompting 机制,能够结合环境反馈、执行误差和自我验证以改善程序。
- 总结一下,探索、规划、自我改进,甚至终身学习
- 上图存在一个错误,那就是如果超过5轮还没有学习到正确的action(没有Success),就会跳出来进行下一轮的学习
浩然大佬的见解:
Ask-Answer-Summary-Decomposition。这种ask-answer的架构非常符合GPT模型的交互习惯,给予充分的引导以及时间,能够更好地发挥模型的潜能。这样的架构比起直接问“What’s your next task”的效果的提升是毋庸置疑的。
Self-Coding。使用action给定模板输出代码+迭代prompt机制+critic评价的机制,实现了成功率较高的GPT4的代码自动编写。这简直听起来是不可思议的事情——GPT4能自己写新的代码了,并且堪用程度还不错,更并且如果生成有错误的代码还能够自己检查自己提升,而不是报错中断。这是否意味着硅基生命的细胞分化与分裂呢?
Skill list可以重用技能。这一点大多数prompt engineering的工作都有提到,类似于其他工作中的”记忆机制“,毕竟想要模仿人类智慧首先要保留有记忆,才有进化的可能。但是这篇工作采用的skill机制,是直接整理成复用性更高的代码级别的skill,效果比记忆更好。
我的理解是Agent通过(GPT4)来进行学习,反馈,执行,也就是用LLM决策代替RL。Voyager 通过GPT-4提出的自动课程来解决日益困难的任务。通过从较简单的程序中综合复杂的技能,代理程序不仅可以迅速提升其能力,还可以有效地对抗灾难性遗忘。
基于大型语言模型(LLM)的智能体利用预训练蕴藏的世界知识(world knowledge)来生成一致的行动规划或可执行的策略,在最近取得了进展。他们被应用于像游戏和机器人这样的实体任务,以及 NLP 那样不需要实体的任务中。然而,这些智能体无法进行终身学习(lifelong learning)无法在不同的时间阶段逐步获取、更新、积累以及迁移知识。
- 将场景放到Minecraft,不是传统的博弈游戏,没有结局即没有最优解(无法通过概率求解最优的情况),是一个开放的问题即没有最优答案
- 所以对比一下就是,一个是结果导向(关注最终的结果),一个是过程导向(关注学习的过程)
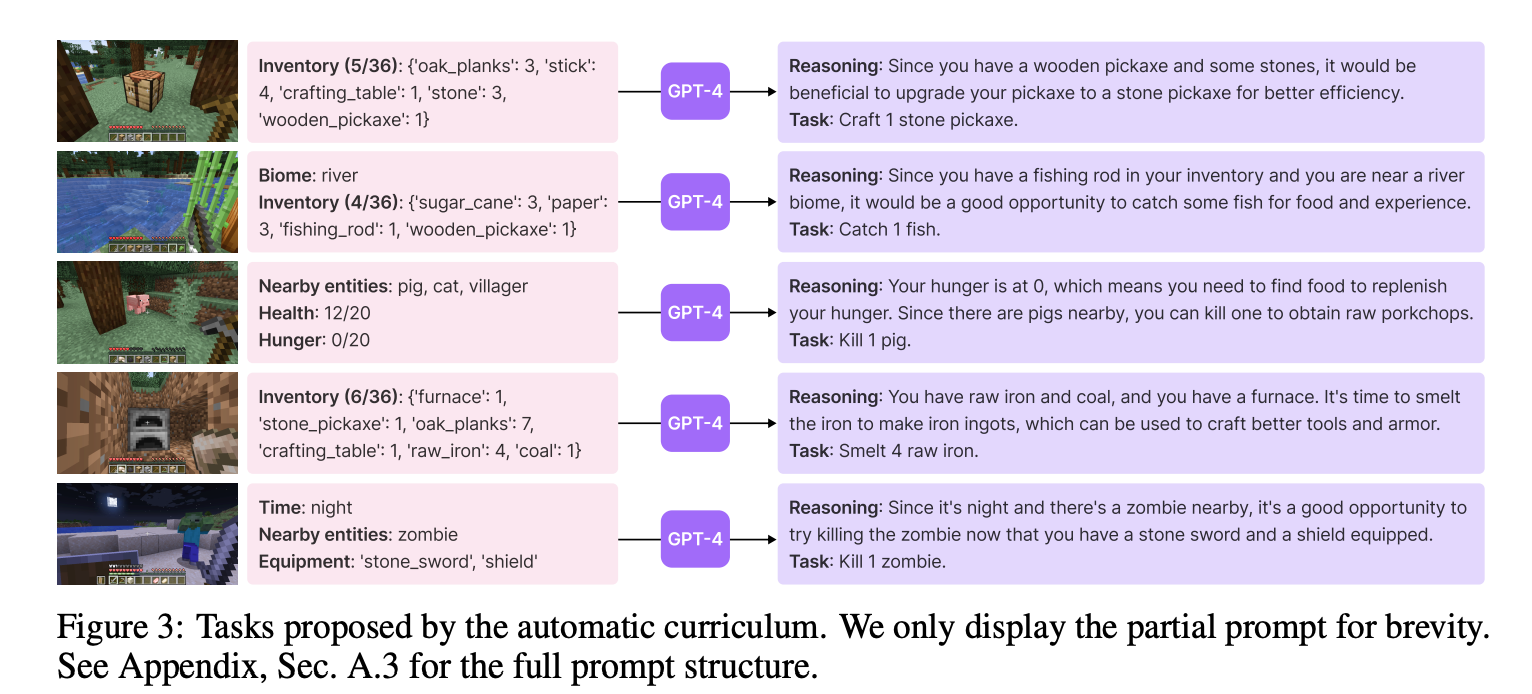
VOYAGER 试图解决由自动课程提出的越来越难的任务,这需要考虑探索进度和智能体的状态。课程的设计由 GPT-4 基于「尽可能探索更多的事物」这一个根本目标来完成。
Skill Labiary: 把学习到的有用的技能存储下来,解决知识灾难性遗忘问题
VOYAGER 通过储存有助于成功完成任务的动作程序,逐步建立起一个技能库。每个程序会通过其文字描述的 embedding 建立索引,在未来遇到类似情况的时候,就可以快速检索出来。
复杂的技能可以通过组合简单程序来生成,这样随着时间推移可以快速建构起 VOYAGER 的能力并且减少其它持续学习方法中的灾难性遗忘问题。
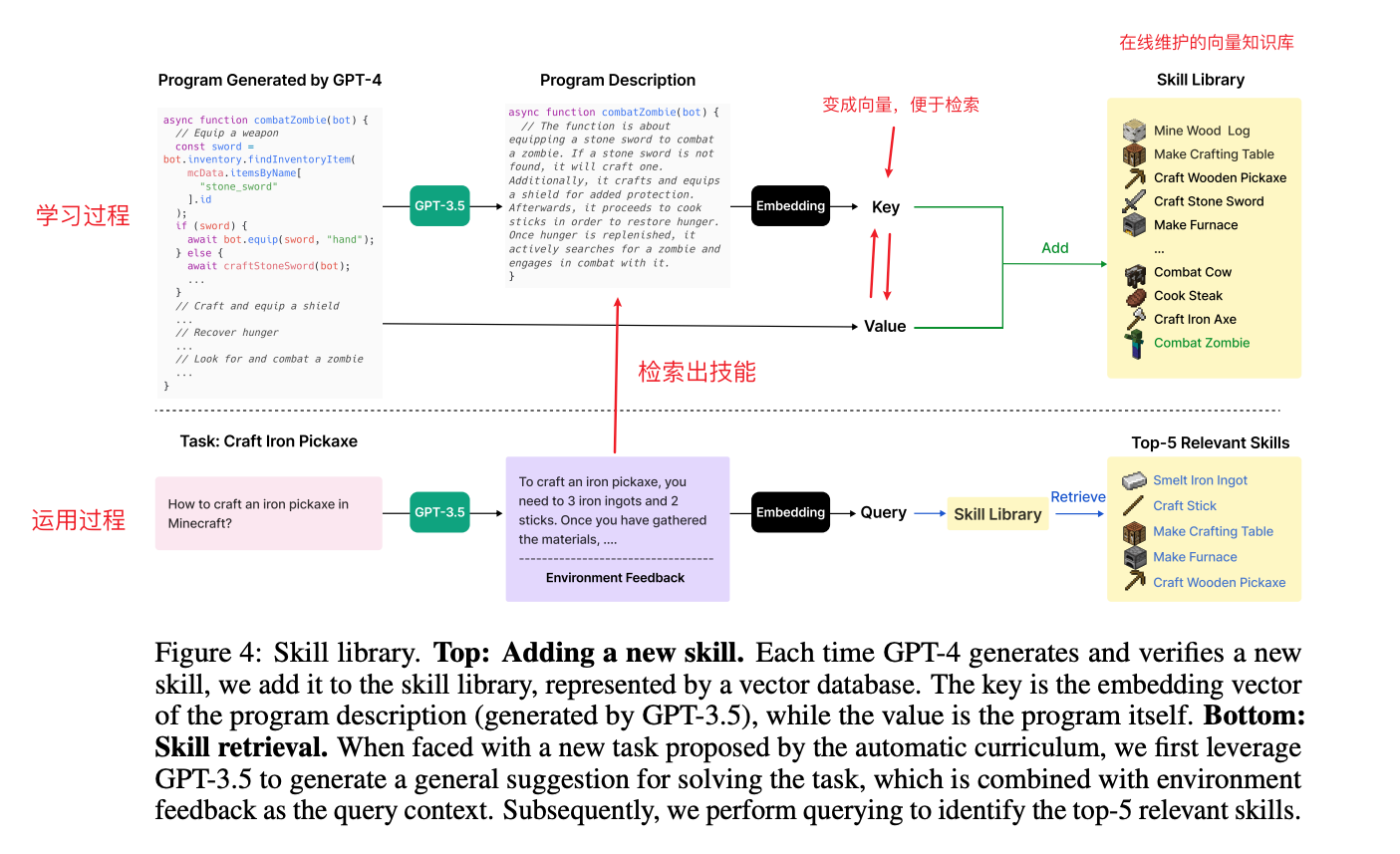
Itertor Prompt Learning: 学正确有效的知识
LLMs 很难一次就生成正确的动作代码。为了解决这个问题,我们提出了一种迭代式的 prompting 机制:
- (1)执行生成的程序,从 Minecraft 的模拟中获取 observations(比如清单列表和附近的生物)以及从代码解释器(如果有的话)中追踪错误;
其实就是让GPT4给出推理过程,方便下一轮纠错或者优化 - (2)将反馈合入 GPT-4 的 prompt 中来开始下一轮的代码精炼;
- (3)重复这个过程直到一个自我验证(self- verification)模块确认任务已经完成,此时我们将程序提交到技能库(比如 craftStoneShovel 和 combatZombieWithSword)并让自动课程给出下一个任务。
自问自答
Q:输入数据从哪来呢?
A:对比LLM任务,会发现没有输入的微调数据集。所以这个微调数据集就是通过自动课程来产生,相当于自监督打label,生成正确的技能就是label,只不过这个过程是在线的。我觉得任务输入是这么构造的,根据当前的Agent和Environment信息(input text),问GPT4下一步怎么办,GPT给出回复,然后去验证,对的就存下来,即 input text -> label(skill)。
- 微调过程自动课程学习的过程,微调中学到的领域知识就是技能库中学习到的技能
Q:如何从游戏中学呢?
A:通过与游戏进行交互后端能获取响应,所谓响应Minecraft世界的信息,包括Agent、Environment的信息。在游戏中Agent应该是一个Object,我们获取Object的属性就行
Q:学习的过程是什么?
A:我们获取到当前世界的全部信息后,打包交给GPT4问它根据当前的状态,下一步应该如何做。相当于GPT4作为一个大脑,决策者来制定下一步的任务策略以及动作。
- 核心是强化学习
**Q:学习的结果是什么?**A:(1)GPT4总结任务。(2)GPT4根据自己提出的任务写出代码,即技能。不仅提供方法,还提供途径
显然,这个Prompt如何写,以及如何得到正确的答案才是关键
Prompt如何写?-》 如何生成正确的任务描述?
1)鼓励多样化行为和施加限制。(扩大解空间的同时,加约束条件,减少错误)
比如:我的最终目标是探索尽可能多的东西。由于我还没有掌握必要的资源或者学习到足够的技能,因此下一个任务不应该太难以至于我无法完成。
(2)智能体当前的状态,包括物品清单、装备、附近的砖石和实体、生态环境、时间、血量和饥饿值,以及地点。(当前信息)
(3)之前完成的和失败的任务,反应智能体当前的探索进度和能力边界。(历史信息)
(4)其它上下文:我们还利用 GPT-3.5 根据智能体的当前状态和探索进度进行自我提问,并使用 wiki 知识库自己回答问题,为 GPT-4 提供额外的上下文。 出于预算考虑,我们选择使用 GPT-3.5 而不是 GPT-4 来执行标准 NLP 任务 (Prefix 提供额外的知识,更容易学习到最优解)
由任务描述如何得到正确的动作? -》 如何生成正确的代码?技能,即可执行代码
(1)代码生成指南。 比如,你的函数会被复用以创建更复杂的函数。因此,你应该尽可能使它通用且可复用。 (Prefix token)
(2)控制原始 API 和从技能库中检索相关的技能,对于 in-context learning 的运作至关重要。(当前记忆库信息)
(3)上一轮生成的代码、环境反馈、执行的错误信息可以让 GPT-4 自我优化。(历史信息)
(4)智能体当前的状态,包括物品清单、装备、附近的砖石和实体、生态环境、时间、血量和饥饿值,以及地点。(当前Agent信息)
(5)在生成代码前利用思维链 prompting 进行推理。(提高推理的正确率的手段)
反馈机制(CoT):
- 环境反馈
- 来自程序解释器的运行错误
- 自我验证以检查任务是否成功(GPT4)

- Environment feedback 直接来源于游戏中的Agent执行情况

对比

- 站在前面3位巨人的肩膀上,核心的创新是:自动课程(主动学习)和技能库的建立
消融实验
-
自动课程对智能体的持续进步至关重要。如果随机选择一个课程,那么发现的物品数量会下降 93%。这是因为如果不按照(合理的)顺序,那么某些任务可能对智能体来说太过于困难了。另一方面,手工设计的课程要求大量关于 Minecraft 的专业知识,而且也无法考虑智能体的实际处境。这种方法在我们的实验中反而不如自动课程。
-
没有技能库的 VOYAGER 在后期往往遇到瓶颈。这反映出技能库在 VOYAGER 中的重要性。它有助于创造更多复杂的动作并,且通过鼓励在旧技能的基础上建立新技能直接推动智能体的能力边界。
-
自我验证是在所有反馈类型中最为重要的。移除这个模块会在发现物品数量方面导致巨大的性能衰减(-73%)。自我验证是一种重要机制,它负责决定什么时候开始新任务或者重新尝试之前失败的任务。
-
GPT-4 在生成代码上显著优于 GPT-3.5 并且让智能体多取得 5.7 倍的不同物品,这是因为 GPT-4 在编码能力上有巨大的跃升。
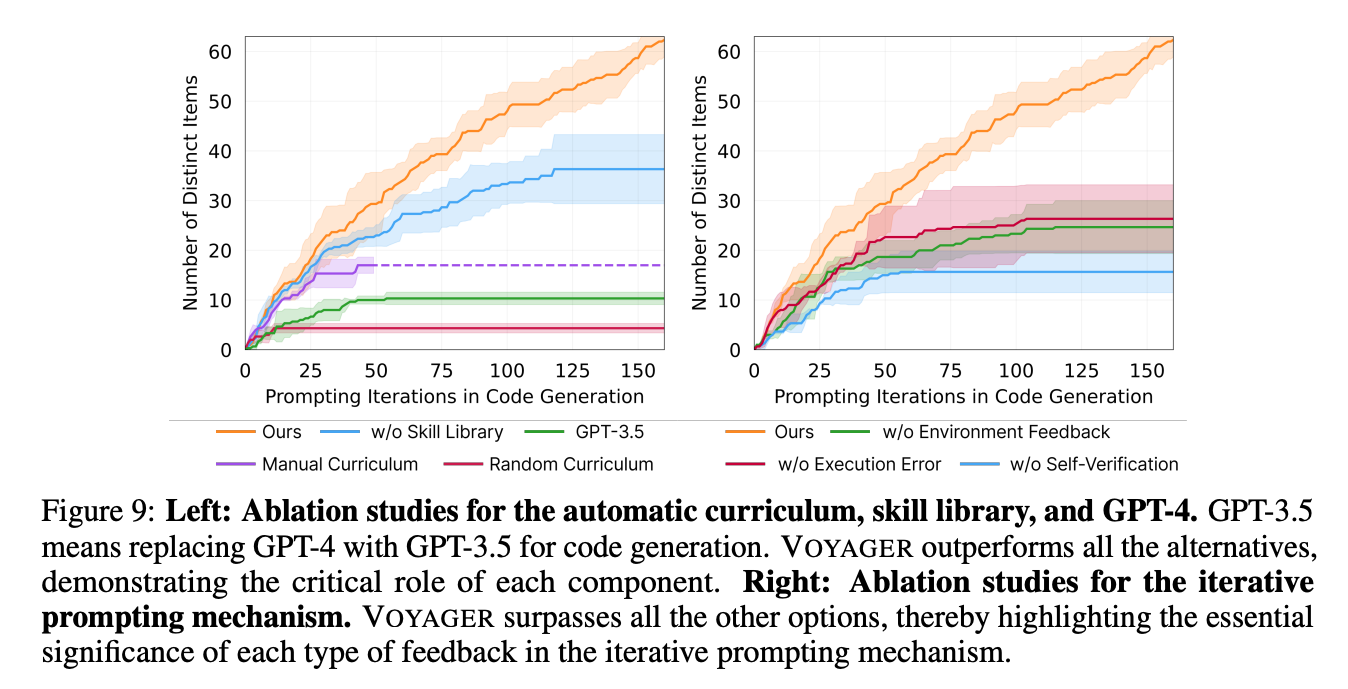
- 对比AutoGPT,最显著的提升在skill Libiary上(解决了知识灾难性遗忘问题)
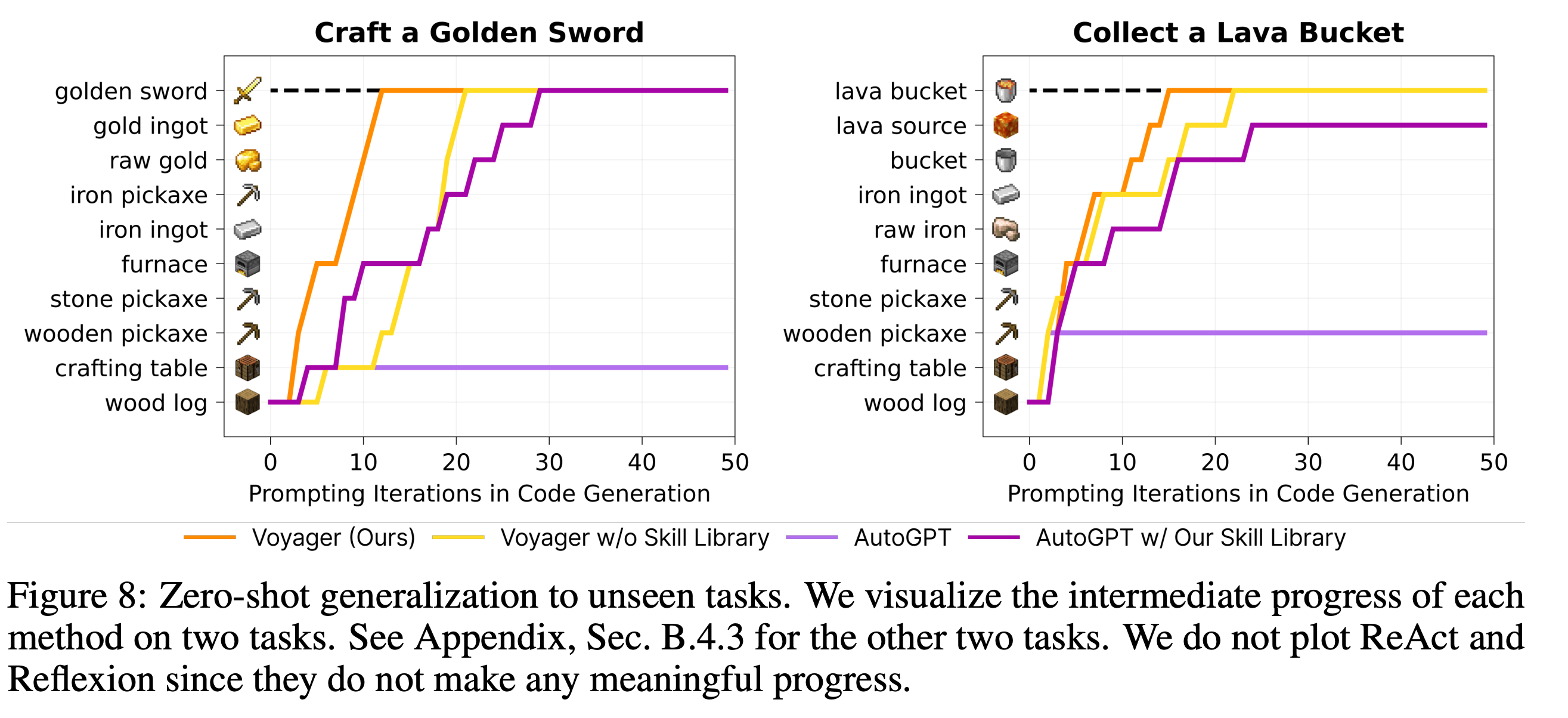
Multimodal Feedback from Humans
VOYAGER 目前不支持视觉感知,因为截止本文写作时只有纯文本的 GPT-4 可用。
然而,VOYAGER 有望通过多模态感知模型增强以完成更令人印象深刻的任务。我们证明了在给定人类反馈的清况下,VOYAGER 能够在 Minecraft 中搭建复杂的 3D 结构,比如下界传送门(Nether Portal)和小屋(Fig. 10)。
有两种结合人类反馈的方法:
(1)人类作为一个 critic(相当于 VOYAGER 的自我验证模块):人类为 VOYAGER 提供视觉的 critique,让它调整上一轮生成的代码。这种反馈对于纠正 VOYAGER 无法直接感知的 3D 结构中的某些细节错误至关重要。
(2)人类作为课程(相当于 VOYAGER 的自动课程模块):人类将一个复杂的建造任务拆解为更小的步骤,引导 VOYAGER 逐步完成它们。这个方法改善了 VOYAGER 处理更复杂的 3D 结构的能力。
Limitations and Future Work
- 灾难性遗忘问题(skill libary缓解)
- 幻觉问题
- 也就是说,LLM的问题并未解决
Vogayer细节
voyager算法

Prompt
- System: A high-level instruction that guides the model behavior throughout the conversation.
It sets the overall tone and objective for the interaction. - User: A detailed instruction that guides the assistant for the next immediate response.
- Assistant: A response message generated the model.
To save token usage, instead of engaging in multi-round conversations, we concatenate a system prompt and a user prompt to obtain each assistant’s response.
Additional Context
We leverage GPT-3.5 to self-ask questions to provide additional context.
- Each question is paired with a concept that is used for retrieving the most relevant document from the wiki knowledge base.
- We feed the document content to GPT-3.5 for self-answering questions. In practice, using a wiki knowledge base is optional since GPT-3.5 already possesses a good understanding of Minecraft game mechanics.
- However, the external knowledge base becomes advantageous if GPT-3.5 is not pre-trained in that specific domain.
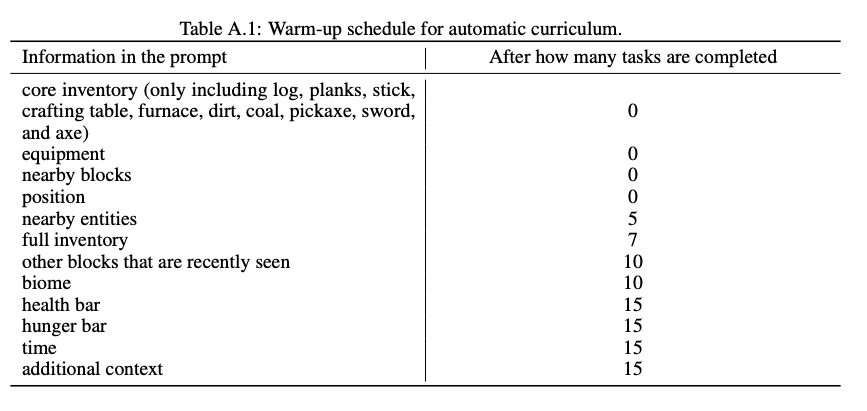
Warm-up Schedule
- 根据agent当前任务的完成情况,逐步的增加额外知识。也就是历史信息知识
Self-Verification

Voyager入门指南
Voyager使用OpenAI的GPT-4作为语言模型。使用Voyager需要拥有OpenAI的API密钥。你可以从这里获取API密钥。
安装完成后,你可以通过以下方式运行Voyager:
from voyager import Voyager
# 你也可以使用mc_port替代azure_login,但是azure_login是强烈推荐的
azure_login = {
"client_id": "YOUR_CLIENT_ID",
"redirect_url": "https://127.0.0.1/auth-response",
"secret_value": "[OPTIONAL] YOUR_SECRET_VALUE",
"version": "fabric-loader-0.14.18-1.19", # Voyager经过测试的版本
}
openai_api_key = "YOUR_API_KEY"
voyager = Voyager(
azure_login=azure_login,
openai_api_key=openai_api_key,
)
# 开始终身学习
voyager.learn()
- 如果你是第一次使用
Azure Login,它会要求你按照命令行指示生成一个配置文件。 - 对于
Azure Login,你还需要自行选择世界并将世界打开到局域网。在运行voyager.learn()后,游戏很快会弹出,你需要:- 选择“单人游戏”并按下“创建新世界”。
- 将游戏模式设置为“创造模式”并将难度设置为“和平”。
- 世界创建完成后,按下
Esc键,然后按下“打开到局域网”。 - 选择“允许作弊: 开启”并按下“启动局域网世界”。你将很快看到机器人加入世界。
从学习过程的检查点恢复
如果你停止了学习过程,并希望以后从一个检查点恢复,你可以按以下方式实例化Voyager:
from voyager import Voyager
voyager = Voyager(
azure_login=azure_login,
openai_api_key=openai_api_key,
ckpt_dir="YOUR_CKPT_DIR",
resume=True,
)
使用已学习的技能库为特定任务运行Voyager
如果你想要使用已学习的技能库为特定任务运行Voyager,你应该首先将技能库目录传递给Voyager:
from voyager import Voyager
# 首先使用skill_library_dir实例化Voyager。
voyager = Voyager(
azure_login=azure_login,
openai_api_key=openai_api_key,
skill_library_dir="./skill_library/trial1", # 加载一个已学习的技能库。
ckpt_dir="YOUR_CKPT_DIR", # 可以自由使用一个新的目录。不要使用与技能库相同的目录,因为新的事件仍将记录到ckpt_dir中。
resume=False, # 不要从技能库中恢复,因为这不是学习过程。
)
然后,你可以运行任务分解。注意:偶尔任务分解可能不合乎逻辑。如果你注意到打印的子目标存在问题,你可以重新运行分解。
# 运行任务分解
task = "YOUR TASK" # 例如:"Craft a diamond pickaxe"
sub_goals = voyager.decompose_task(task=task)
最后,你可以使用已学习的技能库运行子目标:
voyager.inference(sub_goals=sub_goals)
对于所有有效的技能库,请参阅已学习的技能库。
主程序参数注释
"""
Voyager的主要类。
Action agent是论文中的迭代提示机制。
Curriculum agent是论文中的自动课程设置。
Critic agent是论文中的自我验证机制。
Skill manager是论文中的技能库。
:param mc_port: Minecraft游戏中的端口号。
:param azure_login: Minecraft登录配置。
:param server_port: Mineflayer端口号。
:param openai_api_key: OpenAI API密钥。
:param env_wait_ticks: 每个步骤结束时等待的刻数,如果发现缺少一些聊天记录,可以增加此值。
:param env_request_timeout: 每个步骤等待的秒数,如果代码执行超过此时间,Python端将终止连接并需要恢复。
:param reset_placed_if_failed: 如果失败是否重置放置的方块,在构建任务中很有用。
:param action_agent_model_name: action agent模型名称。
:param action_agent_temperature: action agent温度。
:param action_agent_task_max_retries: 如果失败,重试的最大次数。
:param curriculum_agent_model_name: curriculum agent模型名称。
:param curriculum_agent_temperature: curriculum agent温度。
:param curriculum_agent_qa_model_name: curriculum agent QA模型名称。
:param curriculum_agent_qa_temperature: curriculum agent QA温度。
:param curriculum_agent_warm_up: 如果完成的任务大于字典中的值,则在课程设置人类消息中显示信息,可用的键有:
{
"context": int,
"biome": int,
"time": int,
"other_blocks": int,
"nearby_entities": int,
"health": int,
"hunger": int,
"position": int,
"equipment": int,
"chests": int,
"optional_inventory_items": int,
}
:param curriculum_agent_core_inventory_items: 在可选的inventory_items之前,在热身阶段中仅显示这些物品。
:param curriculum_agent_mode: "auto"表示自动课程设置,"manual"表示人工课程设置。
:param critic_agent_model_name: critic agent模型名称。
:param critic_agent_temperature: critic agent温度。
:param critic_agent_mode: "auto"表示自动critic,"manual"表示人工critic。
:param skill_manager_model_name: skill manager模型名称。
:param skill_manager_temperature: skill manager温度。
:param skill_manager_retrieval_top_k: 每个任务检索的技能数量。
:param openai_api_request_timeout: 等待OpenAI API的秒数。
:param ckpt_dir: 检查点目录。
:param skill_library_dir: 技能库目录。
:param resume: 是否从检查点恢复。
"""
RL
- 训练范式显然基于InstructGPT的3阶段经典范式:
- Vogayer工作的重点,显然是RL from Environment FeedBack
Actor - Critic
先补充一下背景,蒙特卡洛策略梯度(REINFORCE)

但是,REINFORCE存在如下三个问题:
① 由于agent在一个episode中会采取很多动作,我们很难说哪个动作对最后结果是有用的,换句话说,这种算法存在高方差(variance);

② 收敛速度慢;
③ 只在这种episodic环境下能用。
为了解决上述问题,于是提出了Actor-Critic算法。
参考文章:https://zhuanlan.zhihu.com/p/110998399
Actor-Critic,其实是用了两个网络:
两个网络有一个共同点,输入状态S:
- 一个输出策略,负责选择动作,我们把这个网络成为Actor;
- 一个负责计算每个动作的分数,我们把这个网络成为Critic。
大家可以形象地想象为,Actor是舞台上的舞者,Critic是台下的评委。
Actor在台上跳舞,一开始舞姿并不好看,Critic根据Actor的舞姿打分。Actor通过Critic给出的分数,去学习:如果Critic给的分数高,那么Actor会调整这个动作的输出概率;相反,如果Critic给的分数低,那么就减少这个动作输出的概率。
算法:
- 定义两个network:Actor 和 Critic
- j进行N次更新。
- 从状态s开始,执行动作a,得到奖励r,进入状态s’
- 记录的数据。
- 把输入到Critic,根据公式: TD-error = gamma * V(s’) + r - V(s)。求 TD-error,并缩小TD-error
- 把输入到Actor,计算策略分布 。
TD error:
-
为了避免正数陷阱,我们希望Actor的更新权重有正有负。因此,我们把Q值减去他们的均值V。有:Q(s,a)-V(s)
-
为了避免需要预估V值和Q值,我们希望把Q和V统一;由于Q(s,a) = gamma * V(s’) + r - V(s)。所以我们得到TD-error公式: TD-error = gamma * V(s’) + r - V(s)
-
TD-error就是Actor更新策略时候,带权重更新中的权重值;
-
现在Critic不再需要预估Q,而是预估V。而根据马可洛夫链所学,我们知道TD-error就是Critic网络需要的loss,也就是说,Critic函数需要最小化TD-error。
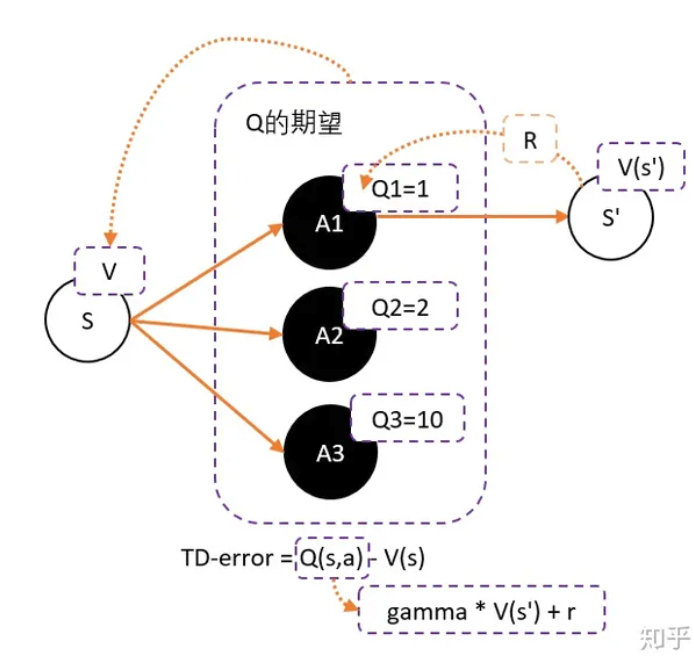
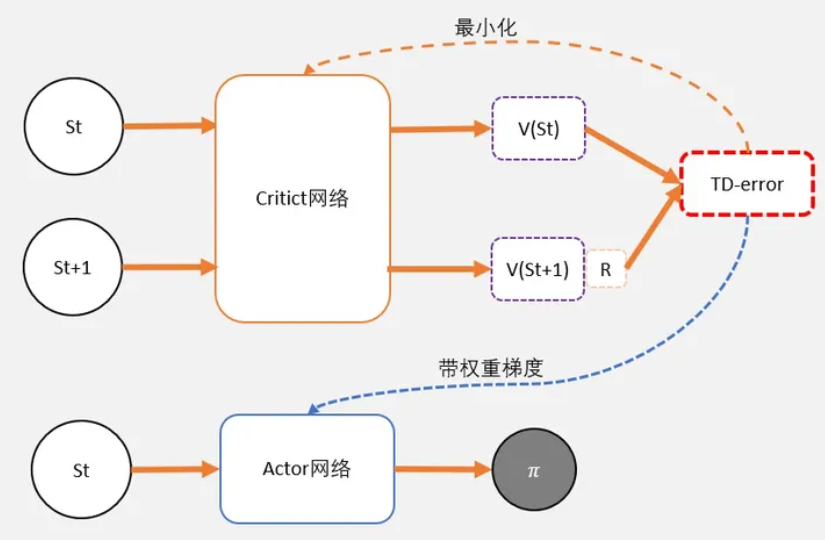
- Critic的任务就是让TD-error尽量小。然后TD-error给Actor做更新。
重点:
- 但在强化学习中,往往没有足够的时间让我们去和环境互动。这就会出现由于运气不好,使得一个很好的动作没有被采样到的情况发生。
- 在PG,智能体需要从头一直跑到尾,直到最终状态才开始进行学习。 在AC,智能体采用是每步更新的方式。
待阅读
- PPO的训练细节:https://iclr-blog-track.github.io/2022/03/25/ppo-implementation-details/
- COT
AutoGPT
参考文章:https://www.zhihu.com/question/595359852
- 我们可以把Auto-GPT看作是依赖GPT来使用一种非常简单的编程语言来解决任务,(GPT4的分治能力)。
-
GPT4的成本太过于贵。CoT加上Prompt面临如此长的token,开销巨大。
-
无法区分开发与生产。每次给一个任务都有重新来,无法由上文进行微调。想象一下,在玩《我的世界》(Minecraft),每次都要从头开始建造一切。显然,这会让游戏变得非常无趣。
- voyager如何解决这个问题?把历史任务信息全部放到prompt中。每次执行任务时,每次读取历史的任务信息。
-
任务不成功会陷入死循环中。解决问题和完成任务的能力,完全依赖于GPT4的推理能力,尽管GPT4解决问题的能力很好,但远非完美。
-
问题分解、背景理解、识别合适的task、处理重叠子问题不充分。
AutoGPT Demo
这个例子的目标是:整理篇AutoGPT的内容,初始行动计划是:
- 搜索AutoGPT;
- 找到项目地址看AutoGPT是做啥的?
- 在autogpt.txt这个文件中解释它;
- 结束任务
Name: AutoGPT-Demo
Role: an ai designed to teach me about auto gpt
Goals: ['search auto gpt','find the github and figure out what the project is','explain what auto gpt is in a file named autogpt.txt','terminate']
在第一轮分析后,把任务优化成了:
AUTOGPT-DEMO THOUGHTS : I think the first step should be to use the 'google' command to search for 'Auto GPT'
REASONING: This will help us gather more information about Auto GPT and we can proceed with identifying the relevant GitHub project .
PLAN:
- Use 'google' to search for 'Auto GPT'
- Browse relevant websites to find the GitHub project
- Write a document explaining what Auto GPI is
CRITICISM: I need to be sure to remain focused and efficient in my use of the 'google' command to minimize the number of step needed to identify the relevant GitHub project and answer the key questions
然后它就执行第一个任务,google搜索。
根据搜索的结果,AutoGPT重新调整了认知,增加了探索Github代码库这步:
AUTOGPT-DEMO THOUGHTS : The next step would be to browse the GitHub repository of Auto GPT. This will help us to gather more information about the project and understand it better.
REASONING: Browsing the GitHub repository is the best way to gather more detailed information about the project and understand its functionality
PLAN:
- Browse the Github repository of Auto GPT
- Explore the respository to understand the project better
- Write a document explaining what Auto GPT is
CRITICISM : I need to ensure that I focus on identifying the key functionalities of Auto GPT and understand the codebase effectively so that I can accurately describe the project in the document I write
随后就是一系列的探索AutoGPT的项目,然后写出介绍文件。
AutoGPT的核心代码逻辑
- 人类的逻辑:通过不断行动拿到反馈,同时更新想法,反复几轮后就可以完美的解决目标。
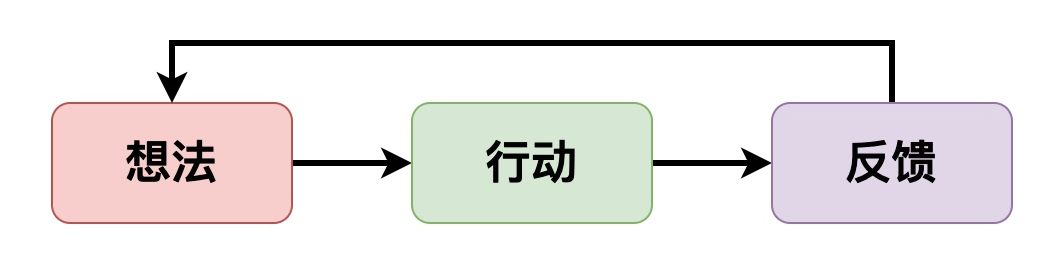
跟前面人类的行动模式是一样的,只不过想法和反馈被整合到Prompt里了。这里的Prompt分为下面几个部分(每轮迭代都会更新):
GOALS - 任务目标,可以列出多条,更有条理
CONSTRAINTS - 告诉LLM一些规则
COMMANDS - 可以调用的函数
RESOURCES - 补充规则
PERFORMANCE EVALUATION - 补充规则
RESPONSE FORMAT - 返回格式,返回格式里要求LLM给出“Thoughts”,这样在执行一系列任务时有更清晰的上下文信息。
- autogpt 配置zh文档:https://github.com/RiseInRose/Auto-GPT-zh
Agent的逻辑
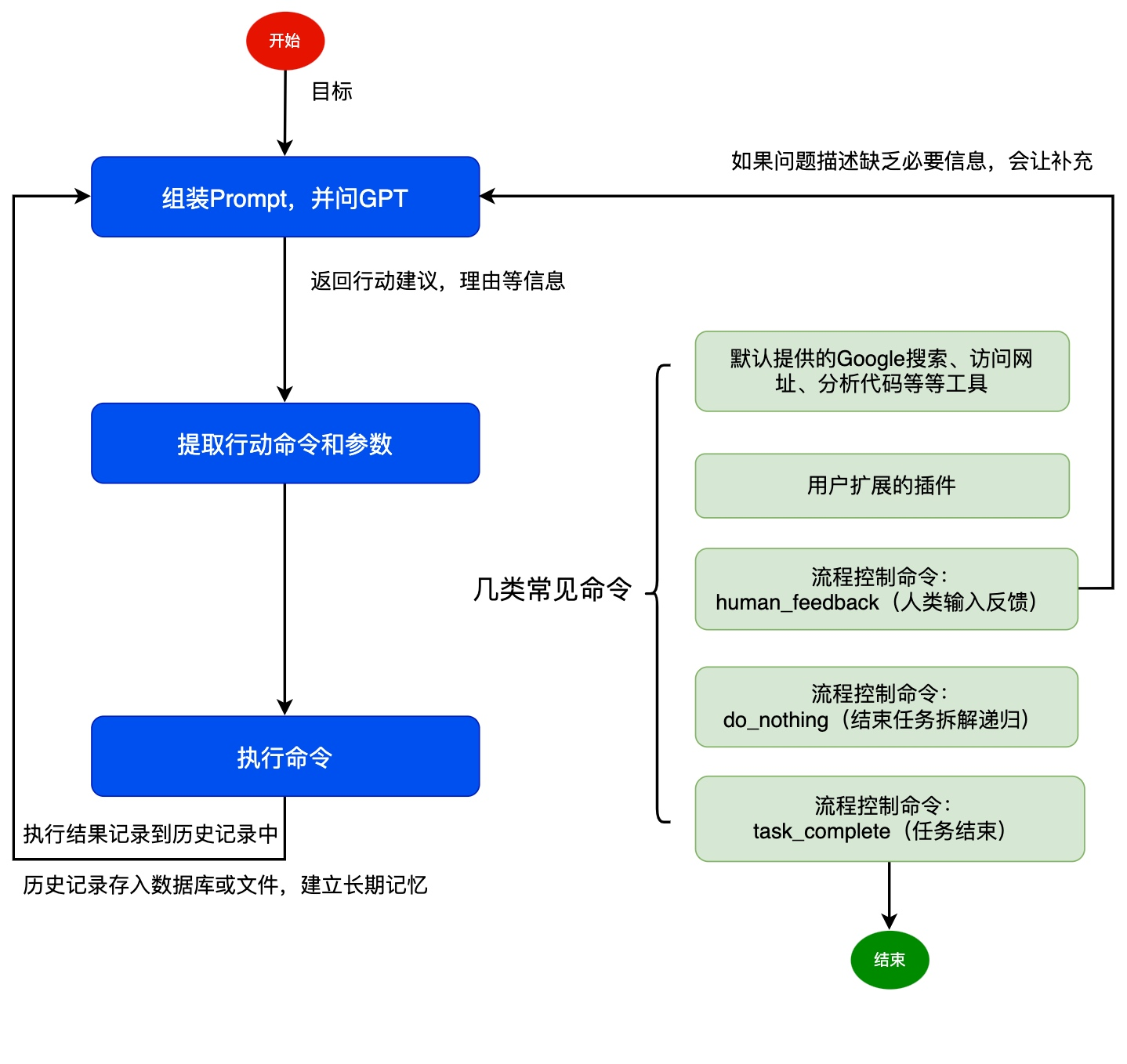
- prompting llm是AutoGPT的关键,所以整个过程中它到底是怎样构建prompt message非常重要。
- 总的来说,四个部分构成了它的prompt message,分别为
user、Prompt prefix、memory、Prompt Template. - 这四个部分中,只有prompt template是不变的。 AutoGPT的prompt template主要是要让llm生成带有thought和command键值的json,这样以来,command可以被容易地解析出来让用户执行。
- 其余三个组成部分(user,postfix,memory)在不同的阶段都有变化
具体来说可以分为两个阶段:- 生成第一个command的阶段(noted 阶段一)
- 第一个command执行完之后的阶段 (noted 阶段二)
阶段一
-
user input:ai name/role/goals memory为空
-
所以第一阶段的prompt message为 “ai name/role/goals + memory[空]+ template + postfix” prompting LLM, “同时” 生成了thought 和 command的json
阶段二
假设用户选择执行生成的command,输入y postfix变为了:GENERATE NEXT COMMAND JSON
这个postfix连同执行command产生的结果,以及上一步生成的json一起更新了memory memory = [json from previous step + result from previous command + postfix]
AutoGPT的prompt 建立过程中有几个疑惑点 :
1:“Determine which next command to use, and respond using the format specified above:” 以及 GENERATE NEXT COMMAND JSON 能不能起到 ‘let‘s think step by step’的神奇作用?
2: AutoGPT到底有没有CoT?
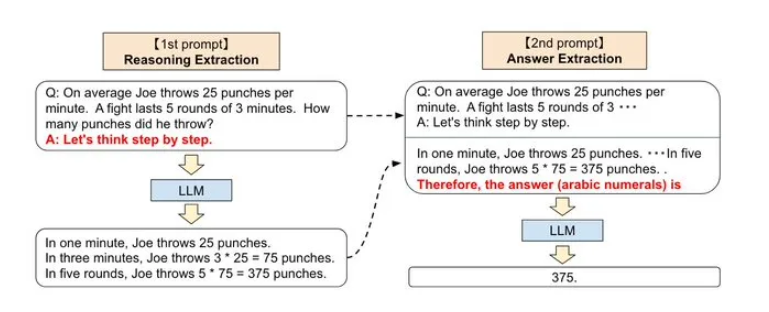
step by step的核心步骤是把step by step生成的CoT反贴生成新的prompt来生成action。也就是,llm的CoT需要prompt两次(上一轮分步骤拆解,下一轮再得到答案) 而AutoGPT只prompt了一次(直接生成Reason和action)
- CoT标准流程
- 相关领域paper集合:https://github.com/WooooDyy/LLM-Agent-Paper-List
XAgent
- 等待阅读…