0.if__name__ == "main"下定义的变量都是全局变量!
1. 调用python方法或者类方法即使没有参数都要加在函数名后面加()
2.工厂函数: 即一个函数直接返回一个类,这里也可以看出类可以直接赋值给变量。如果想验证是类还是对象的话,用type()可以直观得看到,返回的是type类型就说明是类。

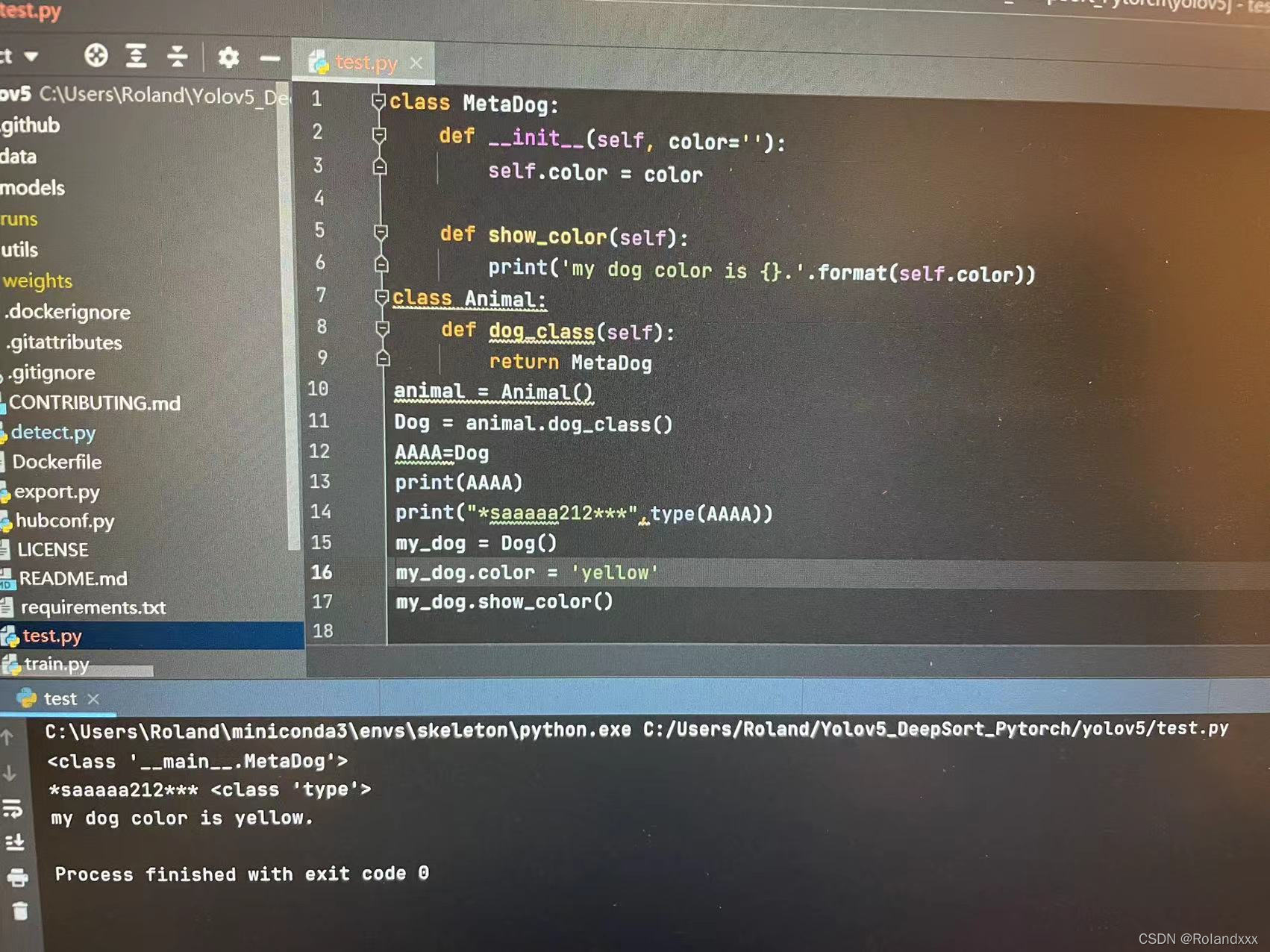
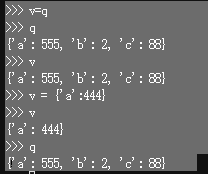
3.global和nonlocal:
在函数内声明某个变量为global变量时,该变量不能为函数的参数。global关键字用来在函数中是为了修改全局变量,注意不用global关键字,函数一样可以看到全局变量!!!只是全局变量如果和函数内部变量重名的话会被函数内部变量覆盖(加不加global关键字都会被覆盖,加只是为了在函数内部就可以改变全局变量)
nonlocal关键字是为了能修改嵌套作用域中的变量(即一个函数定义里面嵌套了另一个函数定义),当然这里不用nonlocal 嵌套的那个函数也能看到它外层函数内定义的变量!!!加nonlocal关键字只是为了能修改外层函数内定义的变量。
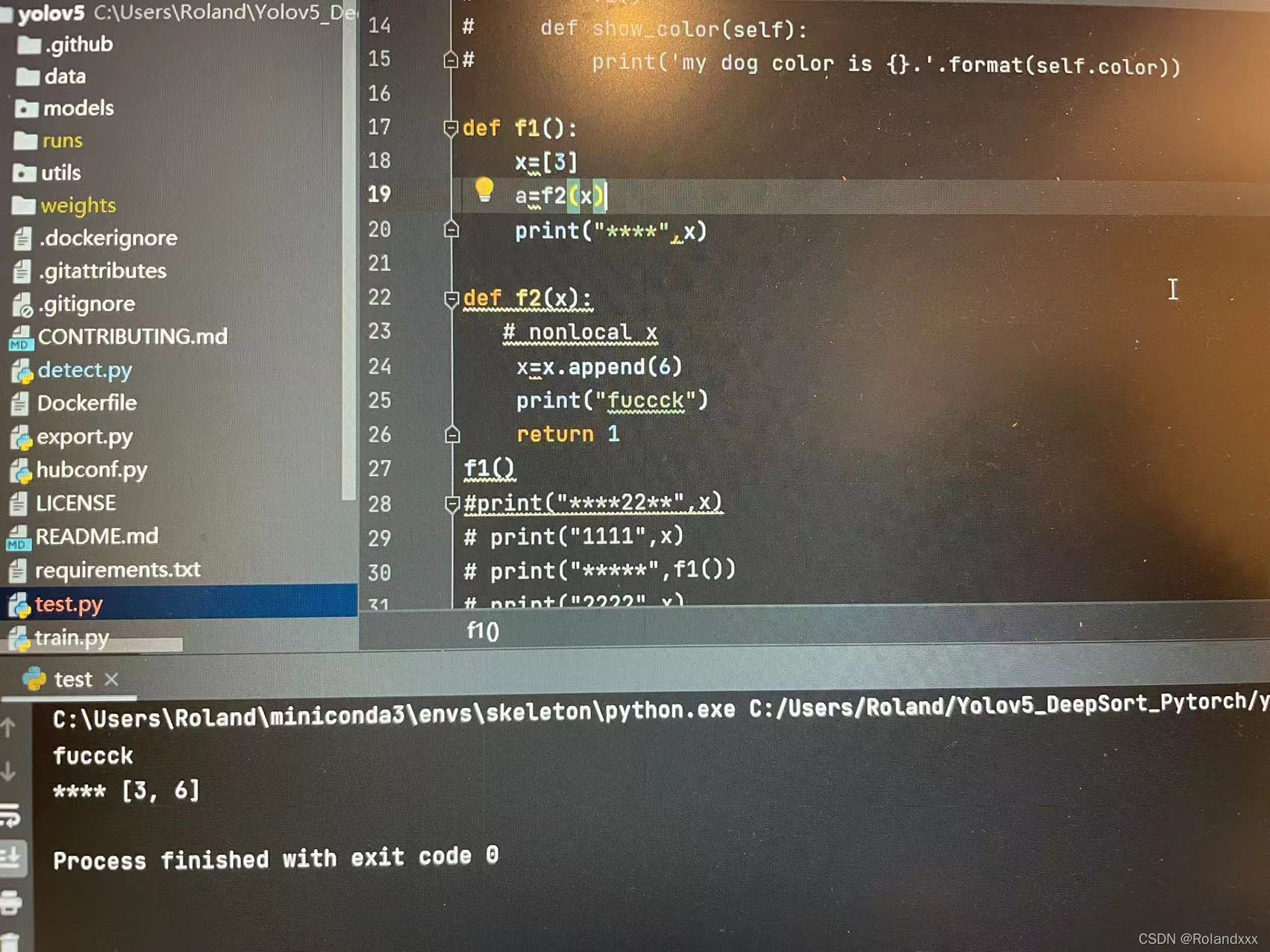
4. 若两个函数是单独分开定义的话(即各自在一个独立的层互不嵌套),那么其中任意一个函数如f1函数是无法看到另一个f2函数里的变量的,只有通过传参才能看到,但可以f1函数里可以调用f2函数,但就是看不到f2函数里面的东西,如下图例程所示:
(注:这里要特别说明python中实参随形参改变而改变的问题,我这里的小例程传参的是列表,用append方法的话列表这个实参会随着形参的改变而发生改变,因为append方法是直接对它本身进行操作了,具体参考此链接:实参随形参改变而改变的问题https://blog.csdn.net/qq_52852138/article/details/123286526?utm_medium=distribute.pc_aggpage_search_result.none-task-blog-2aggregatepagefirst_rank_ecpm_v1~rank_v31_ecpm-1-123286526.pc_agg_new_rank&utm_term=python%E3%80%81%E5%AE%9E%E5%8F%82%E6%94%B9%E5%8F%98&spm=1000.2123.3001.4430)
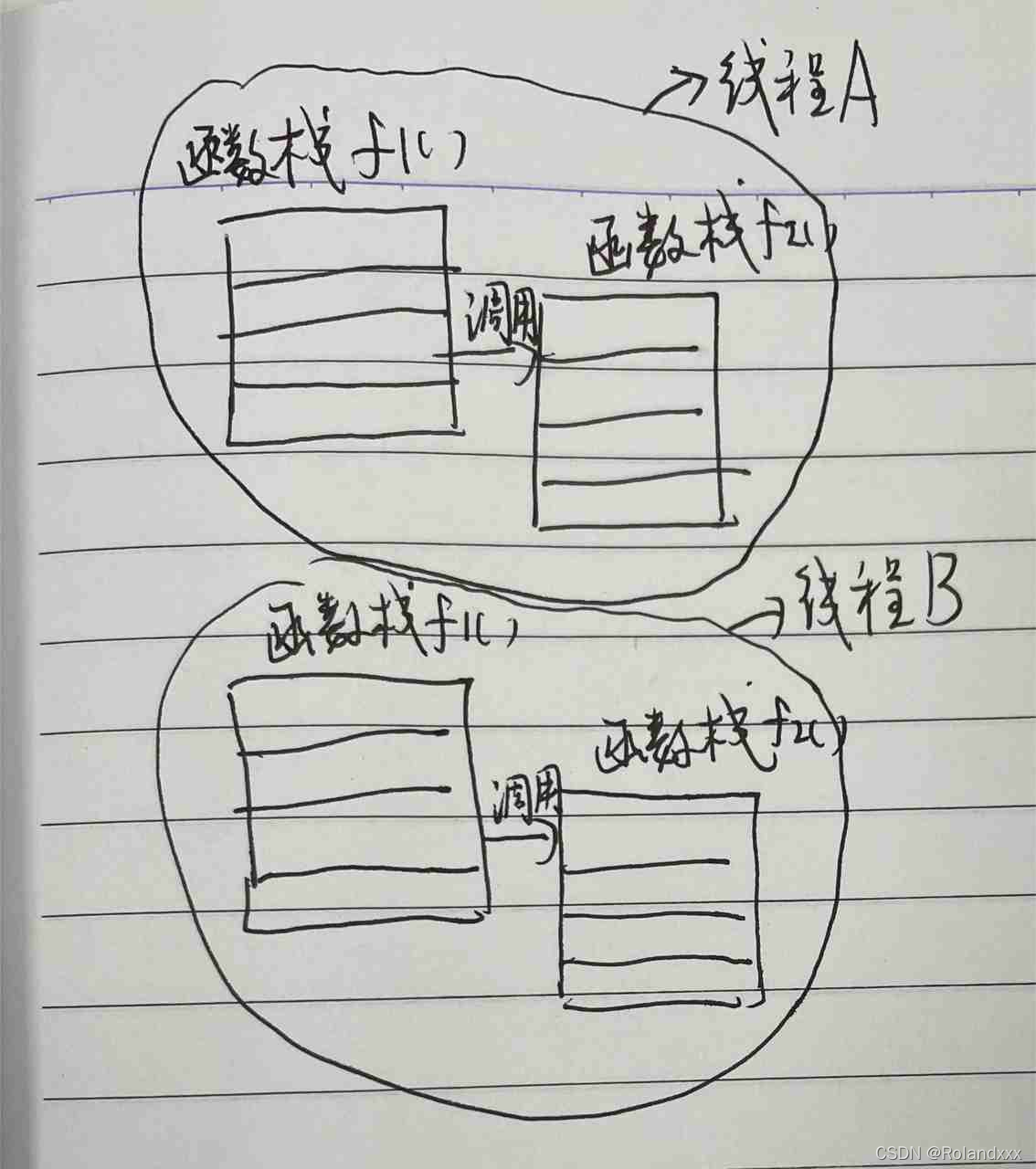
5.函数调用栈过程: 可以理解为压栈是执行某个函数,出栈是返回这个函数输出,遵循先入后出。见草图:



6.多线程: 多线程分为主线程和子线程,最开始跑起来的那个线程是主线程,其他的线程一视同仁,全是子线程!!!主线程和子线程会同时向下进行,主线程自己跑完了,另外的子线程在后台默默跑。每个线程间是相互独立的互相看不到各自线程里的局部变量,因为每个线程都拥有自己的函数堆栈,使得函数调用可以正常执行,不受其他线程的影响。这要和线程通信区分开,线程的等待与唤醒又称为线程之间的通信 ,等待与唤醒机制是实现两个或多个线程在执行任务过程相互配合相互协作的一种技术,通过锁或者共享内存来实现。 补充一下:定义的每个函数会有自己的一个栈空间,一个栈中有很多栈帧(一种数据结构)每个栈帧用来保存这一个函数调用所需的信息,比如参数,局部变量,返回地址等等。如下面草图所示,如果现在有一个主线程两个子线程,子线程的target是f1(),相当于会把f1()单独克隆出2份(注意:其他和f1()函数不相关的代码是不会被克隆的),这两个子线程只执行f1(),执行完f1()就死掉!!!和主线程互不影响,若f1()中y有调用到其他函数比如f2(),则f2()函数也会被克隆两份出来,这样就保证每个线程拥有了自己的函数堆栈,跑f1()时调用就可以正常执行!下图就是f1()里调用了f2()的例子:
更详细的线程共享和独立的资源可以参考这个链接:
https://blog.csdn.net/bxw1992/article/details/76764927
堆和栈讲解的参考链接:
https://baijiahao.baidu.com/s?id=1685244920257041395&wfr=spider&for=pc
7.多线程实例: 这个链接涵盖了多线程的基本应用,用进程模拟车间,用线程来模拟工人十分形象(备注:Thread中,join()方法的作用是等待该线程结束后,才能继续往下运行,一般用法就是主线程等所有子线程执行结束后才向下继续运行):
https://blog.csdn.net/sj2050/article/details/84250427?ops_request_misc=&request_id=&biz_id=102&utm_term=%E5%A4%9A%E7%BA%BF%E7%A8%8Bpython&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduweb~default-3-84250427.142v5pc_search_result_control_group,157v4control&spm=1018.2226.3001.4187
8. *和 **最全解析,收集参数和分配参数功能,拿 **举例,功能1是收集参数: ** args将传进来的参数变成字典形式,即args print出来就是字典形式。 功能2是分配参数:将字典形式的args前面加上 **传给另一个函数作为参数,就变成了分配参数,分配到参数上去 如 {a:1}分配到a=1。
https://blog.csdn.net/qq_46236063/article/details/120026929
9. 列表或元组前加 * 用在传参数时,表示将列表解开成几个独立的参数,传入函数。
10.委托: 通过一个类来调用另一个类里的方法来处理请求,一般通过__getattr__和getattr来实现(具体用法见注释):
class Test1(object):
def __init__(self, obj):
print ("In __init__")
self.data = obj
# def upper(self):
# print("8888888888888888888888")
def __str__(self):
print ("In __str__")
return str(self.data)
def __getattr__(self, attr):
print("***********",attr)
print ("In __getattr__")
return getattr(self.data, attr) #传进来的attr就是upper(),getattr表示self.data将调用upper()方法,因为self.data本身是字符串所以具备upper()这个方法。
if __name__ == '__main__':
myString = Test1('hello')
print myString # 会打印 In __str__ 和 hello
a=myString.upper() #首先调用时会去寻找实例(要考虑继承)有没有这个属性(实例的方法也算做属性),这里实例没有upper()这个属性,所以就会调用def __getattr__(self, attr)函数
print(a)# 调用了upper()方法,将小写字母字符串转为大写字母的字符串
# print myString.get_attr()
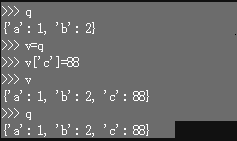
11. 当列表或字典被当成参数传入函数时,函数里面对其操作是会改变它的值的(这里操作指对list或dict的内容进行修改,类似于引用,但是如果直接用 = 直接对整个变量进行赋值来改变值的话就不会有引用的效果了)如图所示:
想要传入但不被改变可以参考以下两个方法(深拷贝)
http://www.runoob.com/python/att-dictionary-copy.html
https://blog.csdn.net/lanyang123456/article/details/73662452
12. name这称作类属性,是定义在所有方法的外部的,前面就不能加self,类属性的作用就是是所有对象共有的。 类属性和类方法一样不仅可以被类直接调用也可以被实例化对象直接访问。但类未实例化的话不能直接调用实例方法。(可以简单记忆为:加了self的属性就是类实例的属性,不加就是类的属性)
>>> class MyClass:
name = 'FishC'
def mufun(self):
print('hello Fishc!')
>>> MyClass.name#类对象对类的属性进行直接访问
'FishC'
>>> MyClass.mufun()#但是类没有实例化,访问其中的方法则成为不可能。
Traceback (most recent call last):
File "<pyshell#18>", line 1, in <module>
MyClass.mufun()
TypeError: mufun() missing 1 required positional argument: 'self'
>>> a = MyClass()
>>> a.mufun()
hello Fishc!
13. 类实例化方法可以修改类实例化的属性,但不能对类属性重新赋值,也就是定义实例化方法时是看不到类属性的(即使在类属性前加cls.也不行),类方法才可以看到和改变类属性(必须写成 cls.类属性 的形式才能看到)!!!还有一点就是这里的count属性称作类属性,是定义在类里所有方法的外部的,前面就不能加self。类属性不仅可以被类直接调用也可以被实例化对象访问。但在__init__(self)方法中的属性就必须要加self。
class Apple(object): # 定义Apple类
count = 0 # 定义类属性
def __init__(self):
self.a =7777
def add_one(self):
self.a = 1 # 对象方法
@classmethod
def add_two(cls):
cls.count = 2 # 类方法,可以被类或类的实例化对象调用。
#类实例化方法可以修改类实例的属性
apple = Apple()
print(apple.a) #输出777
apple.add_one()
print(apple.a)#输出 1
#通过实例和类改变类属性的区别,结果表示实例只影响自己实例中的属性,这样操作就相当于添加了一个实例属性
apple.count =333
print(apple.count) #输出 333
print(Apple.count) #输出 0
Apple.count = 888
print(apple.count) #输出 888
print(Apple.count) #输出 888
#通过类方法改变类属性
Apple.add_two() #类方法,用apple.add_two()也是一样的
print(Apple.count)#输出 2
14.python的实例可以动态增加实例属性和实例方法,当然类也可以直接动态增加类属性:
https://blog.csdn.net/xiaowang_test/article/details/119933261?ops_request_misc=&request_id=&biz_id=102&utm_term=python%E7%BB%99%E5%AE%9E%E4%BE%8B%E5%8A%A0%E5%B1%9E%E6%80%A7&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduweb~default-0-119933261.142v9control,157v4control&spm=1018.2226.3001.4187
15.装饰器在import的时候就会被执行,而不是调用被装饰的那个函数时才开始执行装饰器!经过@装饰器时,会把它装饰的那个函数作为参数传递给@右边那个函数(也就是装饰器)执行,然后装饰器的返回值也是一个函数。如例子所示,最后4行代码相当于执行了test=dect1(dect2(test)):
装饰器,注册器的应用
def dec1(func):
print("1111")
def one():
print("2222")
func()
print("3333")
return one
def dec2(func):
print("aaaa")
def two():
print("bbbb")
func()
print("cccc")
return two
@dec1
@dec2
def test():
print("test test")
结果:
16.带参数的装饰器,使用带有参数的装饰器,其实是在装饰器外面又包裹了一个函数,使用该函数接收参数,返回是装饰器,因为 @ 符号需要配合装饰器实例使用,反正最后装饰器也还是返回一个函数
python中带有参数的装饰器

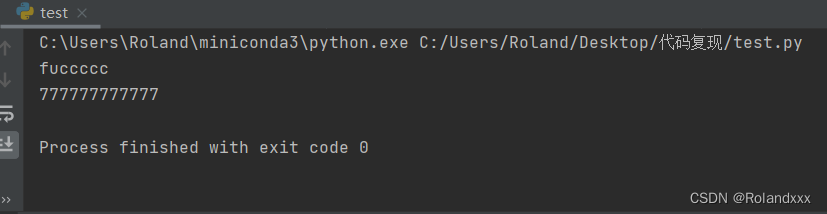
17. return的如果是个函数,在return那的函数后面加括号,就会在return那里调用函数,因为函数是个callable对象
def f1():
def f2():
print("777777777777")
print("fuccccc")
return f2()
f1()
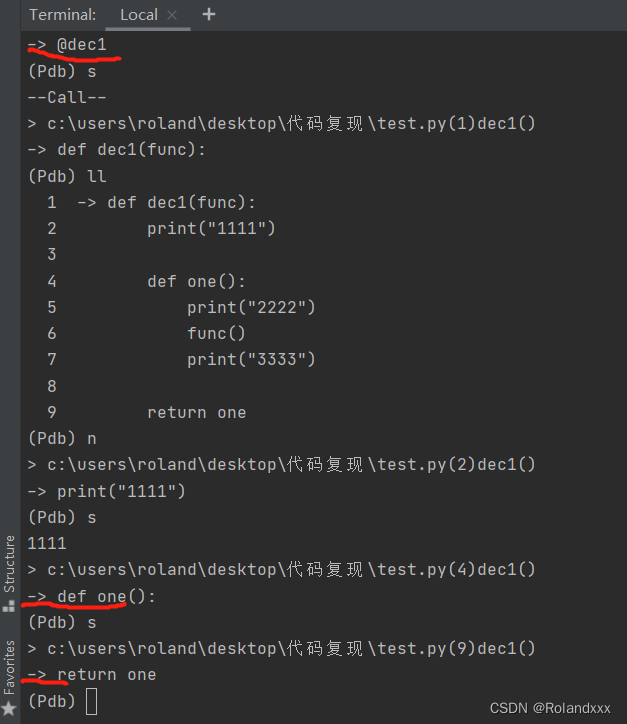
18.如果遇到f1函数里套f2函数的定义,运行f1函数debug时是不会进到f2函数的def里面的。如例子所示:
def dec1(func):
print("1111")
def one():
print("2222")
func()
print("3333")
return one
import pdb
pdb.set_trace()
@dec1
def test():
print("test test")
19. 注意直接torch.tensor 和 把元素取出来再torch.tensor的区别,知识点就是list3= list1+list2的知识点:[1,2]+[3,4]=[1,2,3,4],加的时候方括号不跟着加:
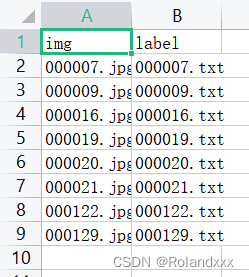
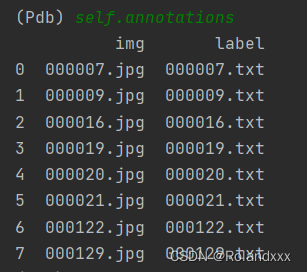
20.annotations=pd.read_csv(csv_file)结果(图1为csv_file,图2为annotations):
len(annotations)=8
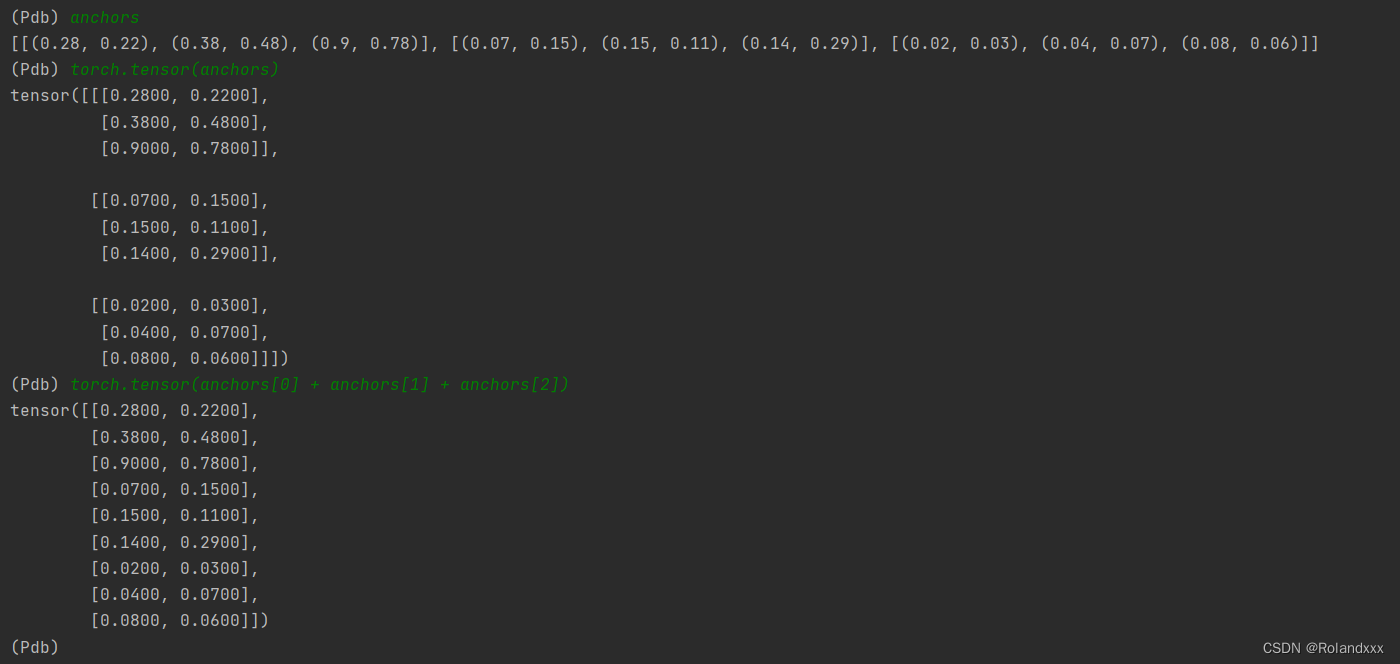
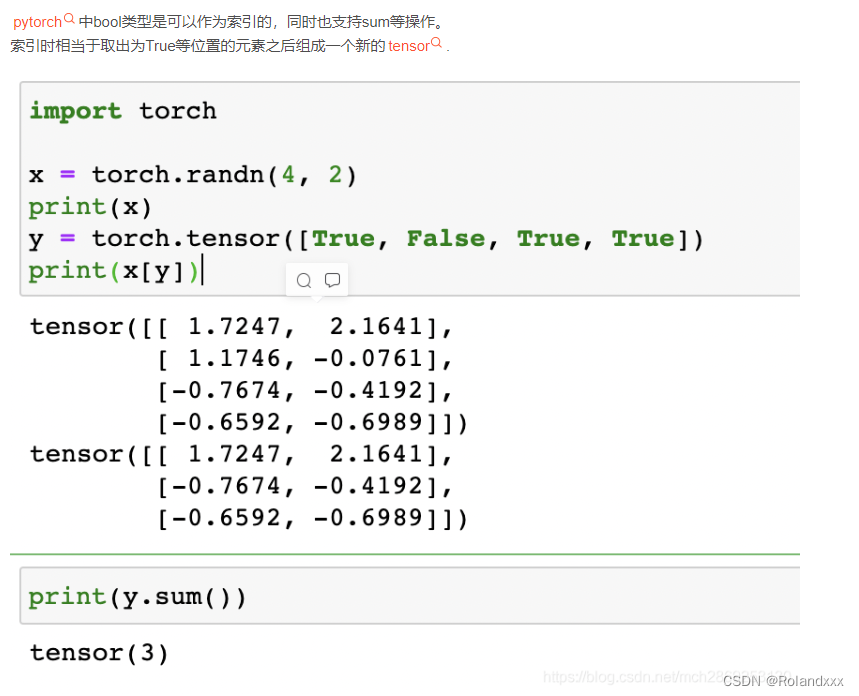
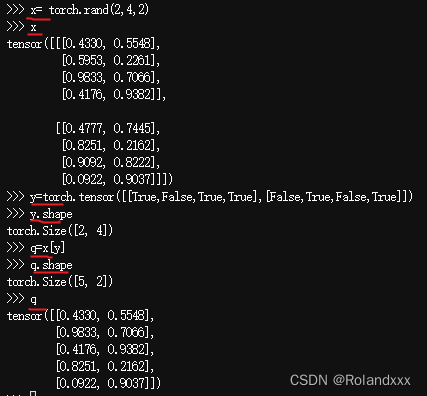
21.pytorch中bool类型的张量作为索引!!!
上面这张图相当于从shape为(2,4,2)的张量通过索引来取,在这里取出来的张量第二个维度不会消失,因为在这第二维度维度可以理解为[1:2]这样的取法,取完之后第二维度之前的维度会消失,第二维度保留。
#target.shape: torch.Size([2, 3, 13, 13, 6])
#noobj.shape:torch.Size([2, 3, 13, 13])
#predictions[..., 0:1].shape:torch.Size([2, 3, 13, 13, 1])
#predictions[..., 0:1][noobj].shape:torch.Size([1012, 1])
#self.bce=nn.BCEWithLogitsLoss()
noobj = target[...,0]==0
no_object_loss = self.bce(
(predictions[..., 0:1][noobj]), (target[..., 0:1][noobj]),
)
这里noobj = target[…,0]==0 这样去理解:取target的[…,0]出来,看取出来的东西里的每个元素和0是否相等,返回bool值。
22. torch.tensor的shape为(1,3),(3),(3,1)的区分:
tensor([13, 26, 52]) #shape:torch.Size([3])
tensor([[13],
[26],
[52]])#shape:torch.Size([3, 1])
torch.randn(1,3)
tensor([[ 0.3604, 0.6949, -0.3529]])#shape:torch.Size([1, 3])
23. 除了loss.backward()以外的loss才能用loss.item(),目的是为了避免显存爆炸,因为pytorch计算图会自动存取variable的信息。
24. torch.matmul()用法,向量乘向量,矩阵乘向量:
a = torch.randn(3)
b = torch.randn(3)
c = torch.matmul(a,b)
print('a:',a)
print('b:',b)
print('torch.matmul:',c)#a,b都是向量,这就相当于点乘
print('****************************************************')
#matrix * vector = 矩阵相乘,matrix第二维需要与vector维度相同
a = torch.randn(3,4)
b = torch.randn(4)
c = torch.matmul(a,b)#相当于(3,4)*(4,1),b的4看成行数,然后就是用矩阵乘法的法则。
print('a:',a)
print('b:',b)
print('torch.matmul:',c)
print('****************************************************')
a: tensor([ 2.6767, -0.8028, 4.1741])
b: tensor([-1.0552, 0.2841, 0.8013])
torch.matmul: tensor(0.2923)
****************************************************
a: tensor([[-1.2726, 0.6925, -0.3536, -0.2233],
[-0.5659, 1.5294, 0.1152, -0.9903],
[-0.2644, 0.5090, 0.7059, 0.2046]])
b: tensor([ 0.7085, -0.0952, 1.6654, -0.8139])
torch.matmul: tensor([-1.3747, 0.4513, 0.7733])
****************************************************
更多知识点参考这个链接:https://blog.csdn.net/whitesilence/article/details/119033117
25.np.ranndom.normal(均值,标准差,输入),这里指定了数据分布后得到的值是样本值,即x轴上的值。
26.import其他文件时,如果在其他文件内自身有发生函数的调用,那么在执行import时也会触发函数的调用。
27.python可以实现这样一个功能,通过调用一个函数创建对象,而且这个函数没有返回值,但创建的这个对象仍然可以在函数外部被看到。做法就是把global()作为参数传进去,修改全局变量。
七种Python创建对象的方式
python中globals_Python内置globals函数的详细介绍
28.python中无法在for循环中修改循环变量,这是因为你可以修改i的值,但每次循环之后for语句又会重新对i赋值,所以你问的问题不在于能否修改i,而是修改迭代器的行为,答案是不能。
29. 函数嵌套,外函数里面的变量和内函数里面的变量是有区别的,作用范围不一样。内函数也可以使用外函数的变量,但是如果想要在内部函数修改外部函数变量的值,就要使用关键字nonlocal。而且外部无法访问“嵌套函数”。具体见:python中的函数嵌套和嵌套调用
def func1():
b = 2
def func2():
nonlocal b
b = b - 1
func2()
print(b)