概叙
为什么是锁优化?
Java多线程为了实现线程同步,加入同步锁(synchronized和lock机制)机制,同步锁的诞生虽然保证了操作的原子性、线程的安全性,但是(相比不加锁的情况下)造成了程序性能下降。所以,"我们"(我们其实就是jvm)这里要做的一件事就是“锁优化”,即既要保证实现锁的功能(即保证多线程下操作安全)又要提高程序性能(即不要让程序因为安全而损失太大效率)。
锁优化是JVM内部自动干的事,程序员只是通过jvm提供的参数,来控制是否开启某项锁优化。例如可以通过-XX:+UseBiasedLocking来开启偏向锁。
下面来介绍HotSpot虚拟机(JVM)的锁优化措施,包括自旋与自适应自旋(Adaptive Spinning)、锁消除(Lock Elimination)、锁粗化(Lock Coarsening)、锁升级(Lock Escalation)、轻量级锁(Lightweight Locking)和偏向锁(Biased Locking)。这些技术都是为了在线程之间更高效地共享数据,以及解决竞争问题,从而提高程序的执行效率。
锁的固定化是指如果在一个循环中反复获取同一个锁,JIT可以将锁的获取放到循环的外面,只获取一次。
锁粗化是指如果一个对象被锁定,并且很长时间都只有一个线程访问,那么JVM会升级为重量级锁,减少线程竞争。
轻量级锁是指在没有实际竞争的情况下,线程在不涉及操作系统层面的线程阻塞和唤醒的情况下,尝试直接获取锁。
偏向锁是指如果一个线程获取了锁,那么下次该线程再获取这个锁就不需要进行同步操作。
不同jdk版本synchronize的优化过程
Java中的synchronized关键字用于实现线程同步,保证多个线程对共享资源的操作具有原子性和可见性。在不同的JDK版本中,对synchronized的优化过程可能有所不同。
以下是一般情况下的优化过程:
JDK 1.6及以前:
在旧版本的JDK中,synchronized关键字的底层实现是依赖于操作系统的底层互斥量(mutex)来实现的。每次进入synchronized块时,会使用操作系统提供的互斥量进行加锁和解锁。这种方式在竞争不激烈的情况下效率较高,但在高并发场景下可能存在性能问题。
JDK 1.6及以后:
从JDK 1.6开始,Java引入了偏向锁和轻量级锁来优化synchronized的性能。当一个线程进入synchronized块时,会尝试获取偏向锁,如果成功获取到偏向锁,则无需进行互斥量的加锁和解锁操作,直接执行同步操作。偏向锁的目的是优化无竞争情况下的同步操作。
如果偏向锁获取失败(例如有其他线程竞争资源),则会升级为轻量级锁。轻量级锁使用CAS(Compare and Swap)操作来实现加锁和解锁,避免了系统调用和线程阻塞的开销,提高了并发性能。当竞争激烈时,轻量级锁可能会升级为重量级锁。
JDK 1.9及以后:
在JDK 1.9中(jdk1.7开始引入逃逸分析、jdk1.8默认开启了同步锁消除(依赖逃逸分析)、直到jdk1.9才真正完成支持逃逸分析),Java引入了一种新的锁优化机制,即锁消除(Lock Elimination)和锁膨胀(Lock Coarsening)。锁消除是指在编译过程中,通过分析数据流和逃逸分析等技术,判断某些锁是不必要的,可以被消除掉,从而减少锁的竞争。锁膨胀是指在运行时,根据锁的使用情况,动态地将轻量级锁升级为重量级锁,以减少由于竞争导致的性能下降。
需要注意的是,以上是一般情况下synchronized的优化过程,具体优化策略可能会受到不同JDK版本和虚拟机实现的影响。优化过程的具体细节可能会有所不同。
锁升级的目的是为了在并发场景下尽量减少锁的开销,提高程序的性能。JVM会根据多线程的竞争情况自动进行锁升级,选择适当的锁级别。锁升级是JVM内部的实现细节,开发者一般无需显式操作。
synchronized有了锁升级后,还是悲观锁吗?
在Java中,synchronized 使用的是一种悲观锁(Pessimistic Locking)策略。悲观锁是一种保守的机制,在访问共享资源之前,假设会发生并发冲突,因此在进入临界区之前会先获取锁,确保只有一个线程能够执行临界区代码。
锁升级是指在低级别的锁(如偏向锁、轻量级锁)无法满足并发情况下的性能要求时,JVM会将锁升级为更高级别的锁(如重量级锁)。这种升级并不改变synchronized的悲观锁特性,而是优化了锁的实现方式。
无论是偏向锁、轻量级锁还是重量级锁,synchronized 都遵循悲观锁的策略,即假设会有并发冲突,并采取相应的控制措施。这种悲观的策略会带来一定的性能开销,特别是在高并发情况下。
相比之下,乐观锁(Optimistic Locking)是一种更为乐观的机制,它假设并发冲突的概率较低,不主动加锁,而是在更新时检查数据是否发生了变化。乐观锁通常使用版本号(Versioning)或时间戳(Timestamping)等机制来判断数据是否被修改。
需要注意的是,synchronized 是Java中最基本和常用的锁机制,而锁升级是底层JVM的实现细节,对于开发者来说是透明的。因此,在使用synchronized时,无需显式关注锁升级的细节,只需注意使用合适的同步范围和锁粒度,以及遵循悲观锁的特性。
锁
多线程编程中,有可能会出现多个线程同时访问同一个共享、可变资源的情况;这种资源可能是:对象、变量、文件等。
由于线程执行的过程是不可控的,所以需要采用同步机制来协同对对象可变状态的访问,那么我们怎么解决线程并发安全问题?
实际上,所有的并发模式在解决线程安全问题时,采用的方案都是 序列化访问临界资源。即在同一时刻,只能有一个线程访问临界资源,也称作同步互斥访问。
Java 中,提供了两种方式来实现同步互斥访问:synchronized 和 Lock
synchronized 关键字:对于不同线程之间看到的是有序的,但是对于synchronized代码块之内的代码有可能会发生指令重排。
1、同步器的本质就是加锁
加锁目的:序列化访问临界资源,即同一时刻只能有一个线程访问临界资源(同步互斥访问)
不过当多个线程执行一个方法时,该方法内部的局部变量并不是临界资源,因为这些局部变量是在每个线程的私有栈中,因此不具有共享性,不会导致线程安全问题。
2、锁类型
隐式锁:Synchronized加锁机制是Jvm内置锁,不需要手动加锁与解锁Jvm会自动加锁跟解锁。
显式锁:Lock;例如:ReentrantLock,实现juc里的Lock接口,实现是基于AQS实现,需要手动加锁跟解锁ReentrantLock lock(), unlock();
3、锁体系
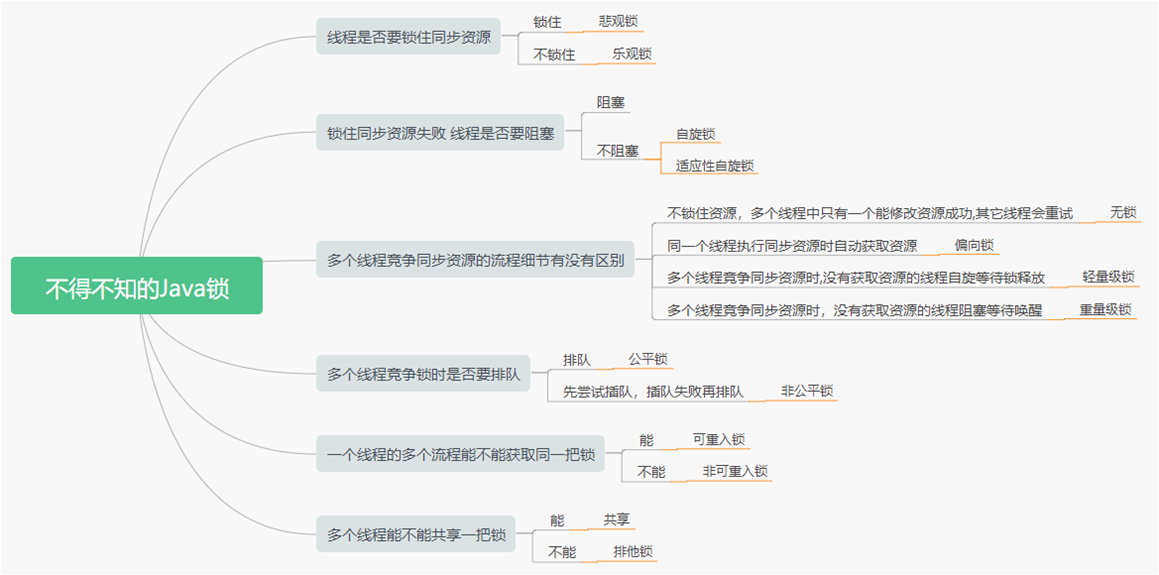
(1)synchronized的锁升级:无锁,偏向锁,轻量级锁,重量级锁;
(2)共享锁:读锁; 排他锁:写锁;
synchronized原理概叙
synchronized内置锁是一种对象锁(锁的是对象而非引用),作用粒度是对象,可以用来实现对临界资源的同步互斥访问,是可重入的。
1、加锁方式:
(1)同步静态方法:锁是类对象;
(2)同步普通方法:锁是实例对象;(在spring容器中,Bean必须是单例的,否则加的synchronized没有什么作用)
(3)同步代码块: 锁是括号里面的对象;
扩展:使用其他方式加锁:
(1)UnsafeInstance.reflectGetUnsafe().monitorEnter(obj); 和 UnsafeInstance.reflectGetUnsafe().monitorExit(obj);
(2)ReentrantLock;
2、synchronized底层原理
synchronized是基于JVM内置锁实现,通过内部对象Monitor(监视器锁)实现,基于进入与退出Monitor对象实现方法与代码块同步,监视器锁的实现依赖底层操作系统的Mutex lock(互斥锁)实现,它是一个重量级锁性能较低。
当然,JVM内置锁在1.5之后版本做了重大的优化,如锁粗化(Lock Coarsening)、锁消除(Lock Elimination)、轻量级锁(Lightweight Locking)、偏向锁(Biased Locking)、适应性自旋(Adaptive Spinning)等技术来减少锁操作的开销,内置锁的并发性能已经基本与Lock持平。
synchronized关键字被编译成字节码后会被翻译成 monitorenter 和 monitorexit 两条指令分别在同步块逻辑代码的起始位置与结束位置。

每一个对象被创建之后,都会在JVM内部维护一个与之对应的monitor监视器锁(ObjectMonitor对象)。当线程并发的去访问同步的代码块时,碰到了 monitorenter 指令的时候,这些线程要先去竞争这个对象的monitor对象。

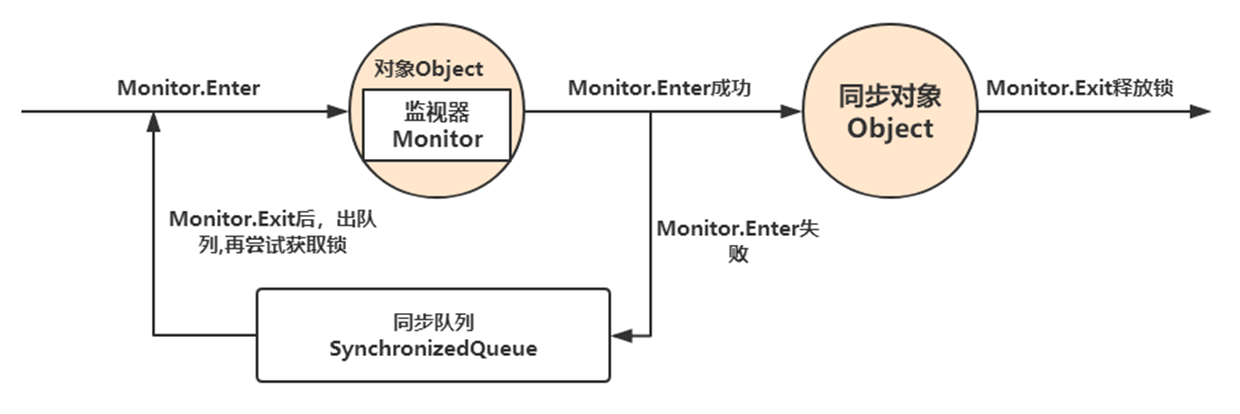
ObjectMonitor对象的部分代码:

synchronized加锁加在对象上,对象是如何记录锁状态的呢?
锁状态是被记录在每个对象的对象头(Mark Word)中,下面我们一起认识一下对象的内存布局。
对象的内存布局
HotSpot虚拟机中,对象在内存中存储的布局可以分为三块区域:对象头(Header)、实例数据(Instance Data)和对齐填充(Padding)。
- 对象头:比如 hash码,对象所属的年代,对象锁,锁状态标志,偏向锁(线程)ID,偏向时间,数组长度(数组对象)等;
- 实例数据:即创建对象时,对象中成员变量,方法等;
- 对齐填充:对象的大小必须是8字节的整数倍;
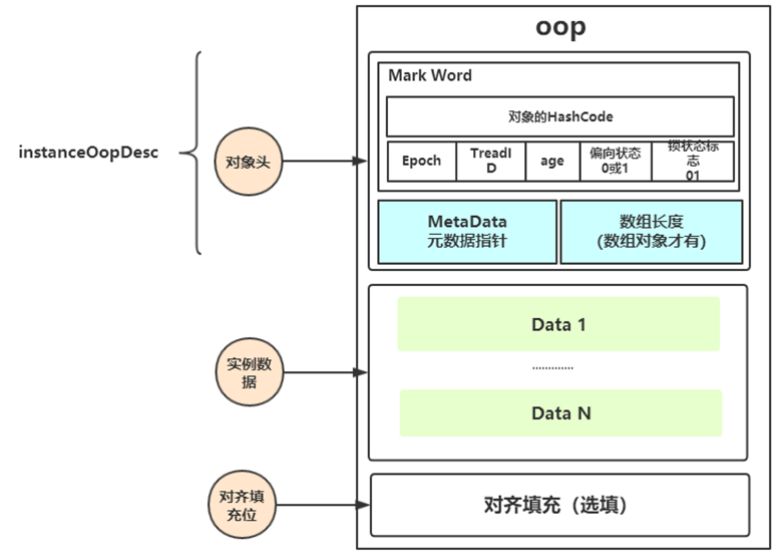
对象头
HotSpot虚拟机的对象头包括两部分信息,第一部分是“Mark Word”,用于存储对象自身的运行时数据, 如哈希码(HashCode)、GC分代年龄、锁状态标志、线程持有的锁、偏向线程ID、偏向时间戳等等。这些信息随着锁的膨胀升级而不同,以 32位JVM为例:
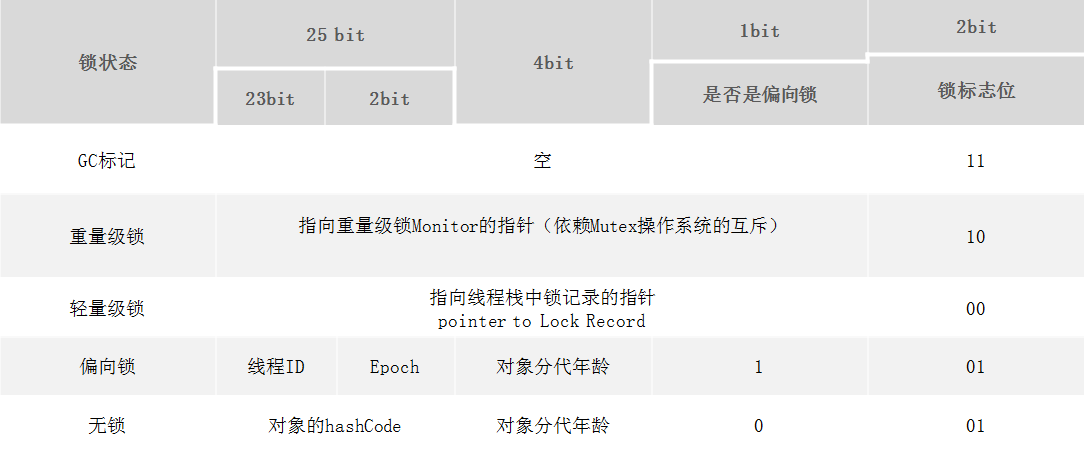

总结一下:Mark Word 可以存储多种内容,当锁标志位(00/01/10/11/01)处于不同类型时,该存储区域可以分别存储各种数据(对象hashcode和GC-age/锁记录pointer/重量级锁pointer/null/偏向锁的线程ID)
CAS:乐观锁的核心算法是CAS(Compareand Swap,比较并交换),它涉及到三个操作数:内存值、预期值、新值。当且仅当预期值和内存值相等时才将内存值修改为新值。
实例对象内存中存储在哪?
如果实例对象存储在堆区时:实例对象内存存在堆区,实例的引用存在栈上,实例的元数据class存在方法区或者元空间;
Object实例对象一定是存在堆区的吗?
不一定,如果实例对象没有线程逃逸行为。JIT会进行优化。
逃逸分析
参考:科普文:一文搞懂jvm实战(四)深入理解逃逸分析Escape Analysis-CSDN博客
使用逃逸分析,编译器可以对代码做如下优化:
(1)同步省略。如果一个对象被发现只能从一个线程被访问到,那么对于这个对象的操作可以不考虑同步。
(2)将堆分配转化为栈分配。如果一个对象在子程序中被分配,要使指向该对象的指针永远不会逃逸,对象可能是栈分配的候选,而不是堆分配。
(3)分离对象或标量替换。有的对象可能不需要作为一个连续的内存结构存在也可以被访问到,那么对象的部分(或全部)可以不存储在内存,而是存储在CPU寄存器中。
在Java代码运行时,通过JVM参数可指定是否开启逃逸分析, XX:+DoEscapeAnalysis : 表示开启逃逸分析 XX:DoEscapeAnalysis : 表示关闭逃逸分析 从jdk1.7开始已经默认开始逃逸分析,如需关闭,需要指定XX:DoEscapeAnalysis
锁优化
1.自旋锁Adaptive Spinning)
什么是自旋锁?
如果线程获取不到锁,第一时间不是去切换系统态进行等待,而是做一个循环操作,去等到锁的释放,循环到一定的次数终止循环,调入系统调用。为了让线程等待,而不是阻塞,让线程执行一个忙循环(自旋),这就是自旋锁。
为什么消耗CPU而不是等待?
自旋锁的优化主要是为了减少了线程切换带来的消耗。
自旋锁适应的场景
自旋锁适合那些线程占用锁时间短的场景。
什么是自适应自旋锁?
JDK1.6加入了自适应自旋锁。顾名思义,如果在同一个锁对象上,自旋等待刚刚成功获得过锁,并且持有锁的线程正在运行,那么虚拟机就会认为这次自旋也很有可能再次成功,并将自旋等待时间延长。如果对于某个锁,自旋很少成功,那么在之后获取该锁时可能会放弃不自旋直接挂起线程。
自旋锁:线程执行一个忙循环(自旋),这项技术就是自旋锁了(spinlock)。
互斥同步:阻塞的实现导致性能巨大的消耗,因为“挂起和恢复线程的操作都要转入到内核态”。(参考:《操作系统的线程模式》)
使用场景:共享资源的被锁定状态只会持续很短的时间,那么为此频繁挂起和恢复线程并不值得。
实现方法:让后面请求锁的线程“稍等一下”,不要放弃CPU的执行时间,看看持有锁的线程很快就会释放锁了。
JVM配置参数:使用-XX:PreBlockSpin参数来设置自旋锁等待的次数。(JDK1.6之后,默认开启了自旋锁,自旋次数的默认值是10次);超过自旋次数,就应当使用传统方式去挂起线程了。
自旋锁的好处:减少线程上下文切换的消耗(线程切换要从用户态切到内核态,很消耗资源)
自旋锁的不足:如果被锁资源的时间很长,那么自旋的线程只会白白浪费掉处理器资源,没有性能产出。
自适应锁的改进:优化方式:自旋的时间不固定,动态根据前一次在同一个锁的自旋时间&锁拥有者的状态共同决定。(JDK1.6 引入自适应锁)
案例1:(AQS的抽象类 AbstractQueuedSynchronizer,底层就是使用了自旋锁)
public class SpinLockTest {
AtomicReference<Thread> reference = new AtomicReference<>();
//加锁
public void mylock(){
Thread thread = Thread.currentThread();
System.out.println(thread.getName() + " try to get lock..");
//工具类提供了CAS操作
while (!reference.compareAndSet(null,thread)){
//do nothing CPU 空转(自旋)
System.out.println(thread.getName() + " cannot get the lock, so do nothing and waiting...");
}
}
//解锁
public void unlock(){
Thread thread = Thread.currentThread();
reference.compareAndSet(thread,null);
System.out.println(thread.getName()+ " to release lock.");
}
public static void main(String[] args) {
SpinLockTest spinLockTest = new SpinLockTest();
new Thread(()->{
spinLockTest.mylock();
try {
TimeUnit.SECONDS.sleep(5);
}catch (InterruptedException e){
e.printStackTrace();
}
//休眠10s之后,t1 才释放锁(未释放资源期间,其他的线程会一直空转)
spinLockTest.unlock();
},"t1").start();
try {
TimeUnit.SECONDS.sleep(1);
}catch (InterruptedException e){
e.printStackTrace();
}
new Thread(()->{
//t2 启动并且申请锁 & t2 释放锁资源
spinLockTest.mylock();
spinLockTest.unlock();
},"t2").start();
}
}
输出结果:
t1 try to get lock..
t2 try to get lock..
t2 cannot get the lock, so do nothing and waiting...(可以注释打印代码来禁止输出这段日志)
t1 to release lock.
t2 to release lock.2.锁消除(Lock Elimination)
什么是锁消除?
指虚拟机即时编译器在运行时,对一些代码上要求同步,但是被检测到不可能存在共享数据竞争时,把锁进行消除。
怎样判断哪些代码可以进行锁消除?
锁消除的主要判断依据来源于逃逸分析的数据支持,如果判断在一段代码中,堆上的所有数据都不会逃逸出去从而被其他线程访问到,那就可以把它们当做栈上数据对待,认为它们是线程私有的,同步加锁就无需进行。
锁消除:JVM 的即时编译器运行时,一些代码要求同步,但是检测到不可能存在共享数据的竞争的锁,那么会对这个锁进行消除处理。
判断依据:堆的数据不会逃逸(变量对象是否逃逸:虚拟机会使用数据流分析来确定),那么可以当做栈的数据,认为线程私有,同步加锁自然不需要进行了。
-XX:+EliminateLocks #开启同步锁消除(JVM默认状态)
-XX:-EliminateLocks #关闭同步锁消除参考:科普文:一文搞懂jvm实战(四)深入理解逃逸分析Escape Analysis-CSDN博客
案例2:JDK1.5之前的字符串连接优化
public class LockRemove {
public String concatString(String s1,String s2,String s3){
return s1 + s2 + s3;
}
}
JDK1.5之前,会转化为StringBuffer的append操作,而StringBuffer的拼接操作都是使用了重量级锁 synchronized;经过分析,此处的s1,s2,s3引用都不会“逃逸到”concatString 方法之外,那么就可以安全的消除掉这个锁。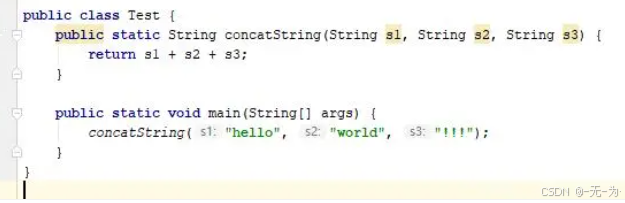
结合.java到.class字节码文件可以知道,在jdk8的情况下,return a+b+c;这句程序实际上底层被转换为StringBuilder的追加操作。
每个 StringBuffer.append() 方法中都有一个同步块,锁就是 sb 对象(StringBuilder新建的一个值为“”的空字符串对象)。虚拟机观察变量 sb,很快就会发现它的动态作用域被限制在 concatString() 方法内部。也就是说,sb 的所有引用永远不会 “逃逸” 道 concatString() 方法之外,其他线程无法访问到它,因此,虽然这里有锁,但是可以被安全地消除掉,在即时编译之后,这段代码就会忽略掉所有的同步而直接执行了(可以理解为StringBuilder虽然线程不安全,但是这里没有关系,因为整个执行过程都在main线程中,不会涉及任何线程同步,所以是安全的。这里底层使用StringBuilder就可以被认为是一种锁消除)。
之前文章逃逸分析种的示例:
通过示例: 明显可以看到“逃逸分析和锁消除” 对性能的提升
public void testLock(){
long t1 = System.currentTimeMillis();
for (int i = 0; i < 100_000_000; i++) {
locketMethod();
}
long t2 = System.currentTimeMillis();
System.out.println("耗时:"+(t2-t1));
}
public static void locketMethod(){
EscapeAnalysis escapeAnalysis = new EscapeAnalysis();
synchronized(escapeAnalysis) {
escapeAnalysis.obj2="abcdefg";
}
}
设置JVM参数,开启逃逸分析, 耗时:
java -Xmx64m -Xms64m -XX:+DoEscapeAnalysis
设置JVM参数,关闭逃逸分析, 耗时:
java -Xmx64m -Xms64m -XX:-DoEscapeAnalysis
设置JVM参数,关闭锁消除,再次运行
java -Xmx64m -Xms15m -XX:+DoEscapeAnalysis -XX:-EliminateLocks
设置JVM参数,开启锁消除,再次运行
java -Xmx64m -Xms15m -XX:+DoEscapeAnalysis -XX:+EliminateLocks
3.锁粗化(Lock Coarsening)
什么是锁粗化?
如果一系列的连续动作都对同一对象反复加锁和解锁,甚至加锁操作时出现在循环体中的,那即使没有线程竞争,频繁地进行互斥同步操作也会导致不必要的性能损耗,比如连续的append()方法。
锁粗化:代码块中对一个对象反复加锁&解锁,甚至在循环出现这种情况,那么可以适当地扩大锁的范围,实现“锁粗化”。
案例3:一个for循环里面对一个对象反复加锁&解锁
public class LockExpend {
private final static ReentrantLock lock = new ReentrantLock();
public static void main(String[] args) {
int[] ints = new int[10];
for (int i : ints){
lock.lock();
try {
// do something..
System.out.println(i);
} finally {
lock.unlock();
}
}
}
}
代码分析:
JVM探测到有这样一个零碎操作,对同一个对象加锁,会把这个加锁同步的范围扩展到整个操作序列的外部;这个案例里,会拓展到for循环之外。示例:同锁消除中的示例
public class Demo{
StringBuffer stb = new StringBuffer();
public void test1() {
stb.append("1");
stb.append("2");
stb.append("3");
stb.append("4");
}
}
StringBuffer 是线程安全的,它的 append() 方法上增加了 synchronized, test1() 方法中连续调用了4次 append() 方法,本应该是会有4次的加锁过程,但是JVM做了优化只需要做1次加锁,如下代码所示,这就是锁的粗化。
public void test1() {
synchronized(this) {
stb.append("1");
stb.append("2");
stb.append("3");
stb.append("4");
}
}轻量级锁和偏向锁
在说轻量级锁和偏向锁之前,我们要先了解一下HotSpot虚拟机中对象的对象头。
HotSpot虚拟机的对象头分为两部分信息:
- 第一部分用域存储对象自身的运行时数据(Mark Word),如哈希码、GC分代年龄等,他是实现轻量级锁和偏向锁的关键。
- 另一部分用于存储只想方法区对象类型的指针,如果是数组对象,还有一个额外部分存储数组长度。
所以,我们来看一下对象头的Mark Word中的存储内容有哪些?
| 存储内容 | 标志位 | 状态 | 用处 |
| 对象哈希码,对象分代年龄 | 01 | 未锁定 | 状态 |
| 指向锁记录的指针 | 00 | 轻量级锁定 | 状态 |
| 指向重量级锁的指针 | 10 | 膨胀 | 状态 |
| 空,不需要记录信息 | 11 | GC标记 | 状态 |
| 偏向线程ID,偏向时间戳、对象分代年龄 | 01 | 可偏向 | 状态 |
什么是CAS操作?
CAS是英文单词CompareAndSwap的缩写,中文意思是:比较并替换。简单来说,CAS整个比较并替换的操作是一个原子操作。
4.轻量级锁(Lightweight Locking)
什么是轻量级锁?
他的意思是在没有多线程竞争的前提下,减少传统的重量级锁使用操作系统互斥量产生的消耗
轻量级锁的执行过程?
加锁过程:
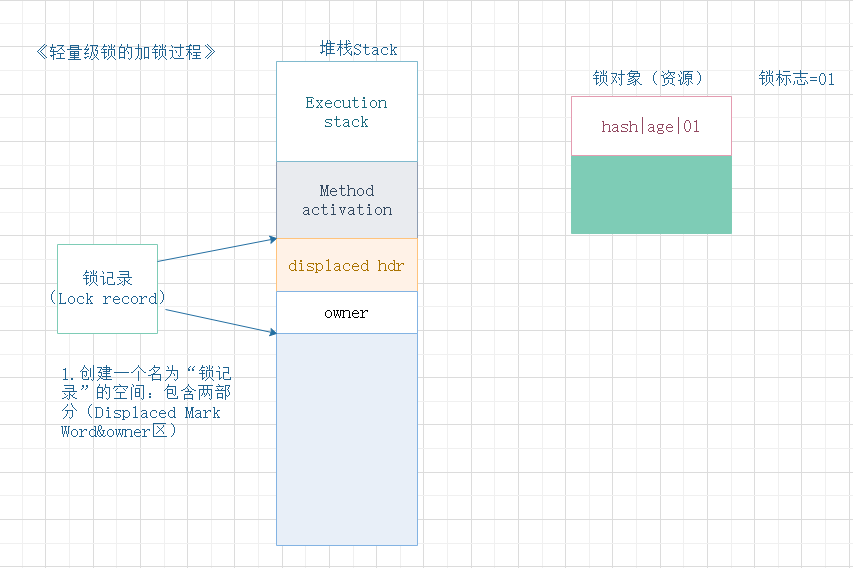
- 进入同步块的时候,如果此同步对象没有被锁定(锁标志位为“01”状态),虚拟机首先将在当前线程的帧栈中建立一个名为“锁空间”(Lock Record)的空间,用于存储锁对象目前Mark Word的拷贝(这份拷贝叫Displaced Mark Word)
- 虚拟机将使用CAS操作尝试将对象的Mark Word更新为指向Lock Record的指针
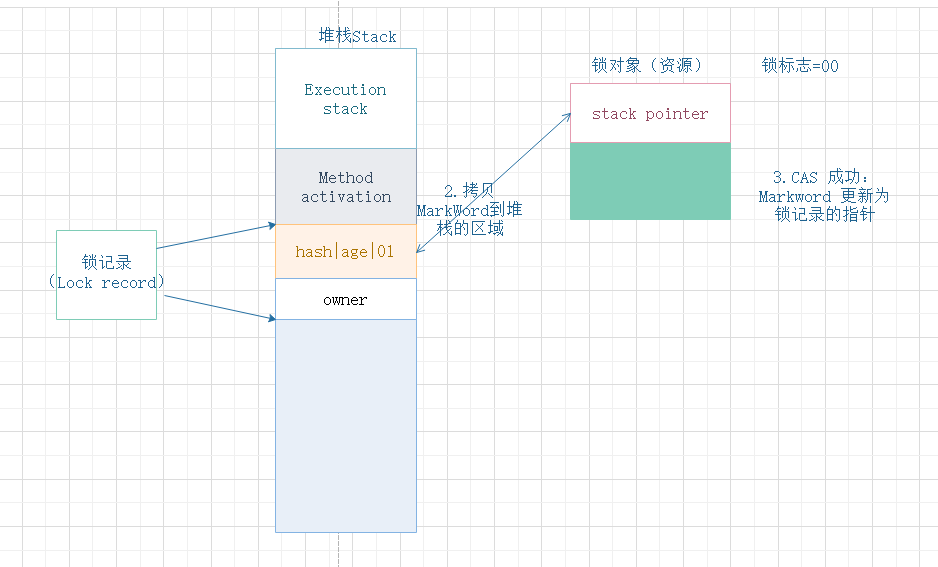
- 如果成功,这个线程就有了该对象的轻量级锁,Mark Word的锁标志位变为“00”
- 如果失败,虚拟机先检查对象的Mark Word是否指向当前线程的栈帧
- 如果指向当前线程帧栈就说明该线程获取到了该锁,可进入同步块继续执行
- 若没指向当前线程的帧栈,表示这个锁对象被其他线程占用,这时轻量级锁不再有效,要膨胀为重量级锁,锁的标志位变为“10”,Mark Word 中存储的就是指向重量级锁(互斥量)的指针,后面等待的线程也要进入阻塞状态
解锁过程:
- 如果对象的Mark Word仍然指向线程的锁记录,就用CAS操作把对象当前Mark Word和线程中复制的Displaced Mark Word替换回来
- 替换成功,同步完成
- 替换失败,有其他线程尝试获取该锁,释放锁的同时,唤醒被挂起的线程。
轻量级锁的使用场景
提升程序同步性能的依据是“对于绝大部分的锁,在整个同步周期内都是不存在竞争的”。
如果没有竞争,轻量级锁使用CAS操作避免了使用互斥量的开销。
但如果存在锁竞争,除了互斥量的开销外,还额外发生了CAS操作,因此在有竞争的情况下,轻量级锁会比传统的重量级锁更慢。
轻量级锁,不是传统重量级锁的替代品,而是用于在没有多线程竞争时,减少重量级锁使用操作系统互斥量带来的性能消耗,是用于性能优化的手段。
理解轻量级锁并不难,因为其本质是对象头部的“锁标志”以及堆栈的锁记录更新替换操作,继续看下去。
加锁过程
正常情况下,没有竞态条件发生,轻量级锁加锁过程有3个步骤。
步骤1,见下图:堆栈Stack整个新的“锁记录”区域;
步骤2跟步骤3,见下图:备份锁对象MarkWord后,CAS,改为堆栈Stack的地址,同时要修改MarkWord的锁标志;
至此,通过修改MarkWord,达到一个“轻量级锁”的效果,虚拟机认为锁对象被某个帧栈所在的线程拥有了。
解锁过程
正常情况下,加锁过程中如果没有碰到“第三者线程”进行竞争,那么线程很容易就获取到锁资源的所有权了。这样一来,解锁也变得简单了。
- 解锁过程,正常情况下,是一个CAS操作,把之前备份的MarkWord,归回原来的锁对象,这样一来,锁对象就丢失跟原拥有者线程的联系了,实现解锁,过程见下图。
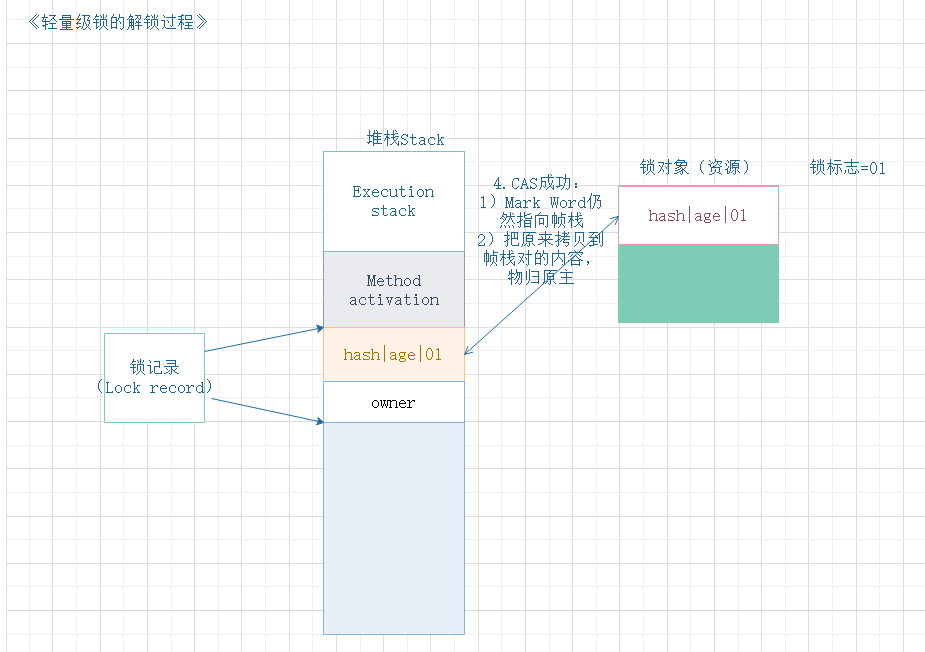
- 解锁过程,非正常情况下,就不太简单了,因为解锁时,发现锁资源还有一直等待的“备胎”线程,那么就要在释放锁的同时,唤醒这个被挂起的线程。
竞争锁资源
我们在上面了解到,正常情况下,没有竞态条件发生,轻量级锁加锁过程有3个步骤。
那如果不凑巧,有两条以上的线程竞争同一个锁呢?(OK,那么轻量级锁就不有效,“膨胀”为重量级锁)。
见下图,膨胀过程,修改MarkWord为互斥锁的指针,并且修改锁标志。
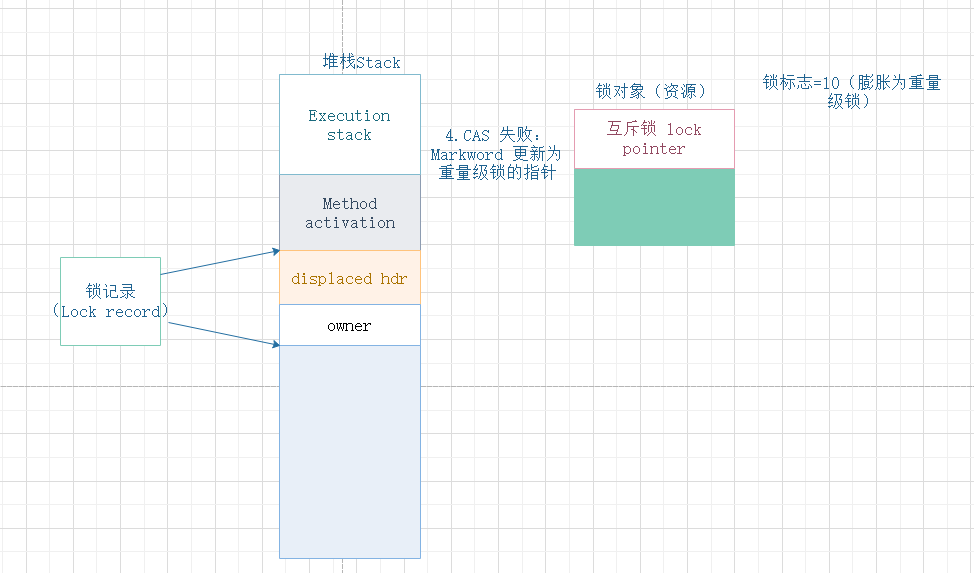
总结“轻量级锁”
轻量级锁的最大作用是:绝大部分锁,在同步周期内不存在多线程竞争访问(经验数据),因此通过CAS操作避免了互斥锁的巨大开销。
优点:偏向锁相对于重量级锁的优点是:因为线程在竞争资源时采用的是自旋,而不是阻塞,也就避免了线程的切换带来的时间消耗,提高了程序的响应速度。
不足:轻量级锁涉及到一个自旋的问题,而自旋操作是会消耗CPU资源的。为了避免无用的自旋,当锁资源存在线程竞争时,偏向锁就会升级为重量级锁来避免其他线程无用的自旋操作。
5.偏向锁(Biased Locking)
什么是偏向锁?
消除数据在无竞争情况下的同步原语,进一步提高程序的运行性能。简单来说就是**在无竞争的情况下把整个同步都消除掉,连CAS操作都不做。**就是说当一个线程率先获取到这个锁后,如果该锁没有被其他线程获取,那么持有偏向锁的线程将永远不需要同步。
工作过程
- 当锁对象第一次被线程获取的时候,虚拟机将会把对象头中的标志位设为"01",使用CAS操作把获取到的锁的线程ID记录到Mark Word中,如果CAS操作成功,持有偏向锁的线程以后每次进入这个锁相关的同步块时,都不再进行任何操作
- 当有另一个线程去尝试获取这个锁时,偏向模式宣告结束。根据锁对象目前是否处于被锁定的状态,撤销偏向后恢复到未锁定或轻量级锁定的状态,后续的同步操作就如上面介绍的轻量级锁那样执行
偏向锁的使用场景
可以提高带有同步但无竞争的程序性能
和轻量级锁一样,如果这个同步块可能很多时候都是多个线程同时访问的话,那么偏向锁甚至会增加时耗
偏向锁:无线程竞争下,把整个同步都消除,连CAS都不做了。
JVM配置参数:-XX:+UseBiasedLocking
原理:让第一次访问锁资源的线程将直接获取该资源的所有权(锁对象的MarkWord写入该线程的Thread-ID)。
加锁过程
加锁过程见下图,加锁完成后,该锁对象就进入了一个“可偏向状态”了。

解锁过程
偏向锁的解锁,跟轻量级锁不一样。
因为锁资源已经处于“已偏向状态”了,每次线程访问该资源时,都会检测 MarkWord 中存储的 thread ID 是否等于当前 thread ID 。
- 如果相等, 则证明本线程已经获取到偏向锁, 可以直接继续执行同步代码块;
- 如果不等, 则证明该对象目前偏向于其他线程, 需要撤销偏向锁;
何为撤销偏向锁?
偏向锁的撤销(Revoke) 操作并不是将对象恢复到无锁可偏向的状态, 而是在发现了线程竞争时,直接锁资源对象“升级到” 被加了轻量级锁,见下面的小点“锁升级过程”。
锁升级过程
锁升级的过程是:偏向锁 -> 轻量级锁 -> 重量级锁。

总结“偏向锁”
偏向锁最大作用:提高带同步但无竞争的程序性能。(对于共享资源极少被多线程同时访问到,因此把轻量级锁的CAS操作也省略了,从而达成了进一步的性能优化。)
偏向锁的特征是:“带效益权衡性质”的优化,如果程序大部分锁都会被多线程竞争访问,那么偏向模式就是多余的。
偏向锁案例
偏向锁不像自旋锁、读写锁或者synchronize修饰词这样的同步,它其实是JVM内置的一种锁机制,自JDK1.6后默认启用。换句话说,这种锁不是咱程序员能用代码来瞎操心的,JVM自己会去操心的。真想要瞎操心,就得改JVM的启动参数:
启用参数: -XX:+UseBiasedLocking 关闭延迟: -XX:BiasedLockingStartupDelay=0 禁用参数: -XX:-UseBiasedLocking
既然无需我们操心,那么了解一下也是好的。偏向锁偏向于第一个获得它的线程,如果在接下来的执行过程中,该锁没有被其他的线程获取,那么持有偏向锁的线程无需再进行同步。很明显,当锁的竞争情况很少出现时,偏向锁就能提高性能,因为它比轻量级锁(如自旋锁)少了一步:CAS。
偏向锁的加锁和解锁有点像可重入锁,它都得先知道取得锁的线程是谁,拿到锁的身份证(线程ID),下次相同的线程来了,啥都别说了,直接走快速通道pass。但如果锁的竞争比较激烈,那么偏向锁并无太大用处。我们来看看,在自旋锁和synchronize同步方法两种情况下,偏向锁的实际时延比较,这里用的是jdk1.8版本。
一、自旋锁:代码参见自旋锁浅析的testSpinLock方法
1、默认耗时:
count值:100000, 耗时:25毫秒.
2、开启偏向锁,启动默认五秒之后生效:-XX:+UseBiasedLocking

count值:100000, 耗时:32毫秒.
3、开启偏向锁,立即生效:-XX:+UseBiasedLocking -XX:BiasedLockingStartupDelay=0
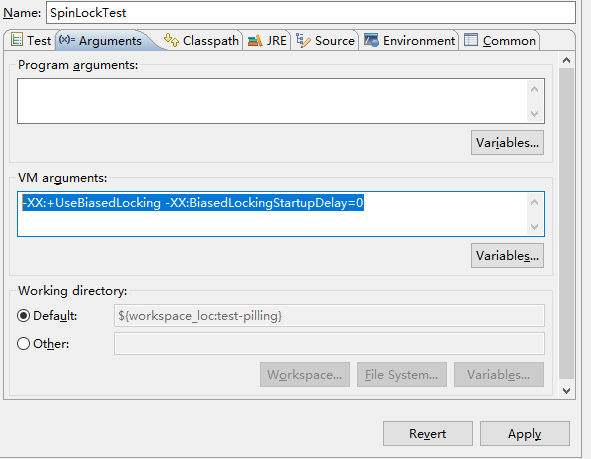
count值:100000, 耗时:102毫秒.
4、关闭偏向锁:-XX:-UseBiasedLocking
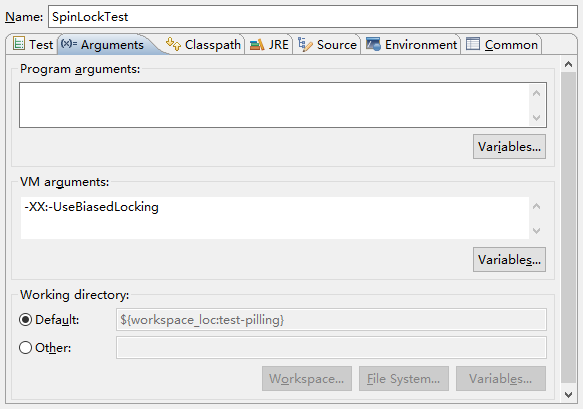
count值:100000, 耗时:30毫秒.
我们可以看到,默认时延是最少的,因为JVM会自动优化,而无时延开启偏向锁是最高的,不开启偏向锁和开启但需要5秒启动(这时线程早跑完了,跟不开启差不多)跟默认时延差不多。
二、synchronize同步方法:代码参见读写锁浅析的TestMyReadWriteLock方法,需要增加全局变量:
private long startTime = 0L;
在before方法开始处加入该变量的赋值:
startTime = System.currentTimeMillis();
再加上after方法:
@After
public void after()
{
System.out.printf("耗时:%d毫秒.\n", System.currentTimeMillis() - startTime);
}
1、默认耗时:
耗时:1076毫秒.
2、开启偏向锁
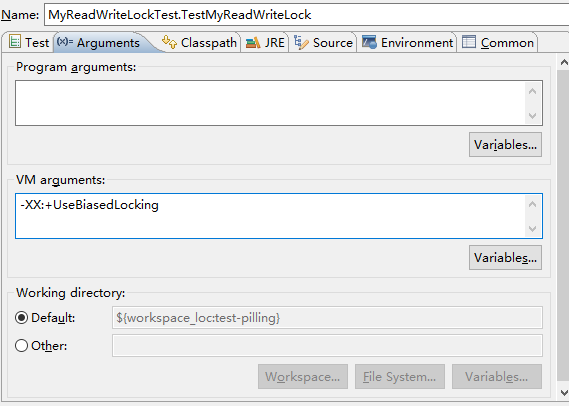
耗时:1090毫秒.
3、开启偏向锁,立即生效
耗时:1099毫秒.
4、关闭偏向锁

耗时:1078毫秒.
以上对比发现,这偏向锁开不开都差不多。
--案例:
private static List<Integer> numberList = new Vector<>();
public static void main(String[] args) {
long begin = System.currentTimeMillis();
int count = 0;
int startNum = 0;
while (count < 1000000) {
numberList.add(startNum);
startNum += 2;
count++;
}
long end = System.currentTimeMillis();
System.out.println("spend: " + (end - begin) + "ms");
}由于Vector声明为成员变量,导致逃逸分析认为这个变量可能会被其他线程访问,因此不会消除Vector内部的锁。
--开启偏向锁,并设置不延迟开启
-XX:+UseBiasedLocking -XX:BiasedLockingStartupDelay=0

--关闭偏向锁
-XX:-UseBiasedLocking

在本案例中使用偏向锁,可以提升45%的性能。
总结
[1] 偏向锁、轻量级锁、自旋锁都不是Java语言层面的锁优化方法。
[2] 内置于JVM中的获取锁的优化方法和获取锁的步骤:
i. 如果偏向锁可用,会先尝试获取偏向锁。
ii. 如果偏性锁失败,并且轻量级锁可用,那么就尝试使用轻量级锁。
iii. 以上都失败,会尝试自旋锁
iv. 如果再失败,最后尝试常规锁,使用OS互斥量在操作系统层实现锁。