转载:http://blog.csdn.net/u010751535/article/details/52856123#%E7%9F%A9%E9%98%B5%E4%B9%98%E6%B3%95
已精通线性代数的朋友,不需要看这篇文章。
写给那些不同专业又对人工智能感兴趣的同学们:
我和别人不太一样,未来就业的恐惧和压力驱动不了我,能驱动我前进的只有精神动力。而自高中开始我就没有了驱动我学习的理由。大学更是如此,别的同学会在临考试的前几天开始复习,而我是在临考试的前一天晚上才开始“复习”(准确说是学习,因为压根没听过课)。虽然这样不会挂科,但是考完试后学过的东西瞬间烟消云散。已经在大学玩了三年游戏的我面临着大四的实习。当我无意间跟爸妈提到室友要去日本留学时,他们要我也一起去。于是连50音都不会的我,没有任何目的的来了日本。毫不夸张的说,当时的我已经把初中的英语和数学都忘得一干二净。
但在日本,当我无意间读了《人工智能的未来》时就被神经网络和人工智能所吸引了。第一次让我意识到电脑和人脑的本质的不同。我开始对人工智能痴迷,开始想要知道更多。然而我发现,我完全读不懂机器学习的书籍,我甚至不知道向量是什么。我决定从英文原版开始寻找答案。于是我先是看完了《新东方•英语语法新思维初级教程、中级教程、高级教程》,这三本书让我对“语言”有了更深的理解。下一步是攻克Gilbert Strang的《Linear Algebra and Its Applications_4ed》。
然而过程是痛苦的。有些时候,我十天看不完3页。因为在学习过程中,我不得不对抗我已有的认知。但是读完后,它却改变了我的思维观。我同时也认识到,一个好的教学过程从来不是告诉你正确答案,而是帮助你用你脑中已有的概念去构建对一个全新概念的直观的认识。毕竟理解的过程不是一步到位,而是逐步加深的过程。当有了第一个直观认识后,我们可以在今后的学习中逐渐加深和纠正理解。但这第一个认识却是最难的部分。这也是我写这个文章的原因。
我听到很多次“机器学习中,不懂线性代数的是文盲”,我倒觉得每个人都懂线性代数,只是没有抽象归纳起来而已。
矩阵乘法
向量点乘
下面严肃点,我是来讲线性代数的。先让我们来看一段视频,但我希望你只看一遍!PPAP洗脑全球
如果你继续读到了这句话,那么恭喜你,你抵抗住了病毒的洗脑。同时你听到了3个向量点乘。
- 1、I have a pen, I have an apple—->apple pen
[applepen]=[11]⋅[penapple] (eq.1) - 2、I have a pen, I have a pineapple—->pineapple pen
[pineapplepen]=[11 ]⋅[penpineapple] (eq.2) - 3、apple pen, pineapple pen—->pen pineapple apple pen
[penpineappleapplepen]=[11]⋅[applepenpineapplepen] (eq.3)
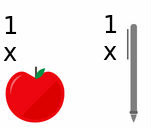
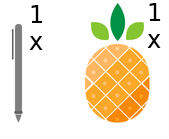
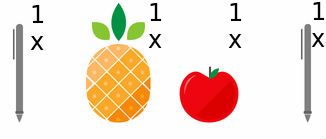
以(eq.1)举例。等式右边的第二个向量表示你有什么,右边的第一个向量表示你各拿几个,而等式的左边表示你获得了什么。从中你可以看出来:
向量点乘(dot product)是一种组合(combination)
矩阵乘向量
我们也可以把(eq.1)(eq.2)合二为一表示为(eq.4):
- I have a pen, I have an apple—->apple pen,
- I have a pen, I have a pineapple—->pineapple pen
[applepenpineapplepen]=[100111]⋅⎡⎣⎢applepineapplepen⎤⎦⎥ (eq.4)
这时,表示你各拿几个的向量变成了两行(两组),也就成了矩阵(向量是只有一行或一列的矩阵)。
表示你各拿几个的一个向量也叫一组权重(weights)。
在
[101]
中,第一个1对应着apple,第二个0对应着pineapple,第三个1对应着pen,我们不可以随意调换位置。所以,
向量是有顺序的一组数字,每个数字都是该向量的一个因素(element)
因素横着排列的向量叫做行向量(row vector),因素竖着排列的向量叫做列向量(column vector)
到这里我们需要更具体的描述一下第一个结论。向量点乘是一种组合,但
向量点乘向量可以是列向量中各个因素的一个组合
上式(eq.4)可分两步计算:
- 计算第一行权重 [101]⋅⎡⎣⎢applepineapplepen⎤⎦⎥ 得到的组合apple pen后,放到了第一行 [applepen]
- 计算第二行权重 [011]⋅⎡⎣⎢applepineapplepen⎤⎦⎥ 得到的组合pineapple pen后,放到了第二行 [pineapplepen]
行成的 [applepenpineapplepen] 依然有顺序,仍然是一个向量。比较向量点乘向量,我们可以看出
矩阵乘向量可以是列向量中各个因素的多个有顺序的组合
向量乘矩阵
然而形成组合的成分并不一定非要是向量中的各个元素,也可以是不同向量之间的组合。我们可以把(eq.1)(eq.2)(eq.3)改写成(eq.5)(eq.6):
- [applepenpineapplepen]=[11]⋅[penapplepenpineapple] (eq.5)
- [penpineappleapplepen]=[pineapplepenapplepen]⋅[11] (eq.6)
在(eq.5)等式右侧的矩阵是由两个行向量组成的。矩阵中,第一个行向量表示怪蜀黍两次组合中分别先拿什么,第二个行向量表示两次组合中分别后拿什么。等式右侧的权重(行向量)的第一个因素对应着矩阵中第一个行向量的个数,第二个因素表示右侧第二个行向量的个数。这样保持矩阵中每个行向量内部因素的比例,完成矩阵内向量与向量之间的组合。
向量乘矩阵可以是矩阵中各个行向量的多个有顺序的组合
而向量中的每个因素都可以当成是因素个数为一个的向量,也再次解释了为什么,向量可以看成是矩阵。
在(eq.6)中,你会发现,要形成组合的向量被拿到了乘法点(dot)的左边,而权重被拿到了右边。因为当行向量的因素作为组合成分时,乘法点右侧的矩阵(向量)装有着权重信息。效果是拿一个penpineapple和一个applepen形成组合。
从中你可以看出矩阵乘法并不满足乘法交换律,因为交换了两个矩阵的位置,就交换了权重与要形成组合的向量的位置。
矩阵乘法不满足乘法交换律:commutative law: AB =! BA
矩阵乘矩阵
如果怪蜀黍跳了两遍舞蹈。第二遍跳舞时,他在两次组合时,首次拿的东西都是都拿两个,那么我们就可以把等式右侧的行向量变成两个行向量,也就形成了一个矩阵。
[applepenapple+2∗penpineapplepenpineapple+2∗pen]=[1211]⋅[penapplepenpineapple]
那怪蜀黍在唱第二遍时,就要唱:
I have two pens. I have an apple. Apple-2pens!
I have two pens. I have a pineapple. Pineapple-2pens!
那该蜀黍就有卖pen的嫌疑,每次都拿两个。
至此你看到了我用的是pineapple +2*pen方式去形成组合。也就是只有乘法来控制数量,加法来组合不同向量。这样的组合方式才是线性代数讨论的组合,即线性组合。所以我们所有概括的结论中,所有组合前面都要加上线性二字。同时乘法所乘的数属于什么数要事先规定好(经常被规定为是实数
∈R
,也有虚数域)。不过这还没有结束,严谨性是数学的特点。我上文所说的“加法”“乘法”也只不过是一个名字而已。它们到底指的是什么运算,遵循什么样的规则。然后当你看线性代数教材的时候,你就会发现这8条规则。
- x+y=y+x .
- x+(y+z)=(x+y)+z .
- There is a unique “zero vector” such that x + 0 = x for all x.
- For each x there is a unique vector -x such that x + (-x) = 0
- 1x=x
- (c1c2)x=c1(c2x)
- (c1+c2)x=c1x+c2x
- (c1+c2)x=c1x+c2x
然而你不需要去记它们。你只需要知道,他们是用于描述和约束在线性代数中的加法,乘法的运算。特别要注意的是,这些运算都有一个原点(0),为了允许正负的出现。
线性组合:一组向量乘上各自对应的一个标量后再相加所形成的组合。(满足上述对乘法、加法的规则)
当我们再用(m by n),即m行n列的方式去描述一个矩阵的形状(shape)时,你就得到了矩阵的第一种描述:
矩阵的静态信息
坐标值与坐标系:
矩阵所包含的信息从来都是成对出现,拿向量 [applepen] 举例来说,这个向量并没有被赋予任何数值。但你已经确定了你要在apple的数量和pen的数量的两个因素(两个维度)下描述你的数据。换句话说,你已规定好你的坐标系。所以当你写出任何具有实际数值的向量,例如 [21] 时,他们的坐标系(二维向量空间)和坐标值就同时被确定了。它实际上是 [applepen] 和 [21] 的缩写。二者无法分割。即使是 [applepen] ,虽然我没有再pen,apple,pineapple前面写具体数字。但依然包含所有因素间的比例相同的隐含信息。而调换2和1的顺序同时也表示坐标轴之间的调换。
坐标值的两种看法:
单单考虑坐标值时,有两种角度去理解矩阵所包含的静态信息。
矩阵的静态坐标值信息:
(1)若干个维度相同的要形成组合的向量信息
(2)若干组维度相同的权重信息
他们本质都是向量,然而(2)中所指的向量(或叫权重)是用于控制每个向量的数量(scale),而(1)中的所指的向量是要通过乘法与加法的线性组合形成新向量的向量。
拿矩阵 [1211] 来说,你可以理解成该矩阵包含了两个行向量,也可以理解为包含了两组权重;同时,用列向量的方式也同样可以理解成向量和权重。
矩阵的动态信息
在一个矩阵内,你把矩阵内的向量理解为向量或权重都可以。但是当两个矩阵进行矩阵乘法时,一旦选择以权重信息理解其中一个矩阵,另一个矩阵的信息就会被瞬间确定为要形成组合的向量(量子力学的味道)。
[applepenapple+2∗penpineapplepenpineapple+2∗pen]=[1211]⋅[penapplepenpineapple]
举例来说,它的实际数学表达应该是:
[1+11+2∗11+11+2∗1]=[1211]⋅[1111]
,即便是都换成了数字,其物理意义任然存在,始终并未丢失。但也可以被理解为其他的物理意义。我会在
[1111]
与
[penapplepenpineapple]
二者之间进行切换,他们表示同一个矩阵。
当我把矩阵
[1211]
看成是两组行向量的权重时,后一个矩阵的两个行向量
[penpen]
和
[applepineapple]
就瞬间被赋予了要形成组合的向量的观察方式。
当我把矩阵
[1111]
看成是两组列向量的权重时,前一个矩阵的两个列向量
[12]
和
[11]
就瞬间被赋予了要形成组合的向量的观察方式。
矩阵的动态信息,两个矩阵相乘 A⋅B 时,
当把前者矩阵(A)中行向量理解成若干组权重,后者矩阵(B)中的行向量就是要形成组合的成分。
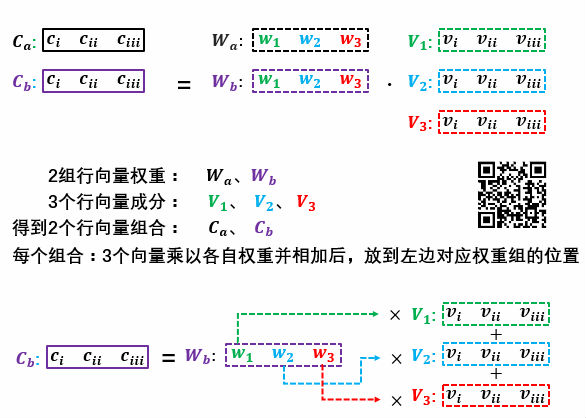
当把后者矩阵(B)中列向量理解成若干组权重,前者矩阵(A)中的列向量就是要形成组合的成分。
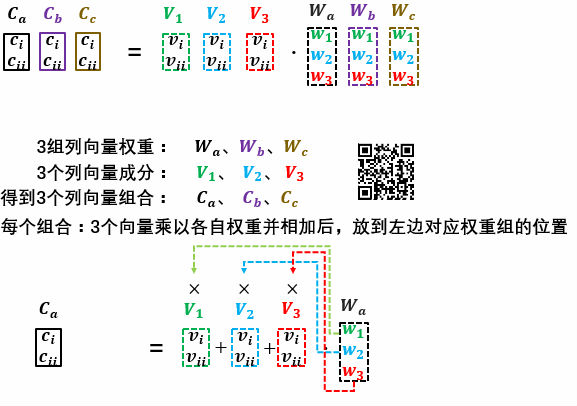
注意对应行向量与列向量。
转置一个矩阵可以理解为调换一个矩阵的权重与向量信息。
单位矩阵可以被理解为权重与向量信息相同。
请回想线性组合的描述(一组向量乘上各自对应的一个标量后再相加所形成的组合),这是因为向量的维度和权重的维度要一一对应。所以,
矩阵A(m by n)和矩阵B(p by q)能够做乘法的条件是 n = p
向量空间
很多线性代数教材所引入的第一个概念就是线性空间(linear space)。可见它的地位。虽然它有些抽象,但是却是自然而然推演出来的一个概念。
空间的本质是集合。而且是一个能够容纳所有你要描述内容的集合。
在具体讨论之前先要对上句话中“你要描述的内容”进行进一步说明。
从如何理解线性代数这四个字开始。首先我们已经知道了什么是线性(那8个条件约束的加法和乘法)。那什么是代数?意思是指你可以把任何概念都代入其中。
可以怪蜀黍手中的水果和笔换成盆和大菠萝PPAP河南话版。也可以换成任何宇宙上有的物体。然而不仅仅是物体,甚至可以是一个抽象的概念。我个人最喜欢的描述是:向量空间是描述状态(state)的线性空间。再加上之前的约束,于是我们就有了
向量空间是能够容纳所有线性组合的状态空间
那什么样的空间(所有状态的集合)能够容纳所有的线性组合?
如果说,我现在想要描述的你的两个状态(下图中的行向位置,和纵向位置),向量的维度就是二维。那么一个大圆盘够不够容纳所有的线性组合?答案是不够。
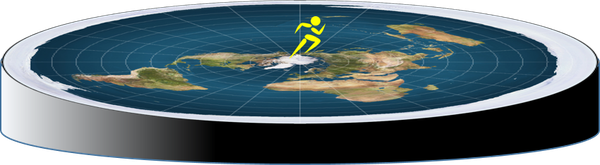
因为线性组合是一组向量乘上各自对应的一个标量后再相加所形成的组合,而这个标量是实数域的时候,由于实数域无线延伸,那么乘以标量后的状态也会无限延伸。所以向量空间一定是各个维度都像实数轴一样可以无线延伸。最终你得到的将不会是一维下的线段,二维下的圆盘。而一定是一维下的无限延伸的直线,二维下的无限延伸的平面。
向量空间的基本特点是各个维度都可以无限延伸。
我之所以用状态二字,是因为刚才的两个维度,我可以用于描述你的速度和体温。这时,这两个维度所展开的依然是一个平面,但却又不是描述位置的平面。
子空间
子空间(subspace)可以被想成是向量空间内的空间,同样要满足能够容纳线性组合的条件
那么最小的子空间是什么?只有一个状态的空间(集合)。而这个状态不是其他状态,就是0。只有这样才可以在乘以完一个标量后依然不会跑出空间外部。(因为跑出去了,我们就不得不扩大空间来容纳它)。其次空集可不可以是向量空间?不可以,空集是没有任何元素的集合,既然什么状态都没有,又怎么能够容纳线性组合。
最小的向量空间是只包含零向量的空间
假如上图的圆盘是一个无线延伸的平面,那么这个平面的子空间就是那个平面上所有直线吗?不是,8个运算规则中明确规定了,一定要有原点,这样才可以包含正负。所以这个平面的子空间是所有过原点的直线,并且包括中心的那个原点自己所组成的最小子空间,同时也包括这个平面自身(最大的子空间)
线性无关
s你会发现,在怪蜀黍的例子中,当要把可以把(eq.1)(eq.2)合二为一表示为(eq.4)时,是这个样子:
[applepenpineapplepen]=[100111]⋅⎡⎣⎢applepineapplepen⎤⎦⎥
(eq.4)
(eq.4)最右侧的向量并不是
⎡⎣⎢⎢⎢applepenpineapplepen⎤⎦⎥⎥⎥
4个维度。而是三个。因为pen 和pen是一个东西。我们想用的是若干个毫不相关的因素去描述状态。这里的毫不相关是在线性空间下的毫不相关,所以叫做线性无关。那么当我们要描述的状态是由向量来描述时怎么办?我们知道判断两个向量是否线性无关是,可以看他是否在空间下平行。但怎么判断几个向量之间(不一定是两个)是否线性无关?我们需要可靠的依据。这也是数学为什么要证明,它要让使用者知道某个性质在什么条件下适用,什么条件下又不适用。
线性无关(linearly independent): 当 ci 表示权重, vi 表示向量时,
c1v1+…+ckvk=0 只发生在when c1=…=ck=0 全都等于零时。
换句话说,这些向量不可以通过线性组合形成彼此。形成彼此的情况只能是他们都是零向量。
张成
明白了线性无关后,张成(spanning)就十分容易了,接下来要注意的是词的属性和关联词。
张成(spanning)是一个动词,而动词的主语是一组向量(a set of vectors)。描述的是一组向量通过线性组合所能形成子空间。是个动词,描述的内容并不是形成的这个空间,而是形成的这个行为。
⎡⎣⎢⎢⎢applepenpineapplepen⎤⎦⎥⎥⎥ ,就可以看成是4个向量,这4个向量,可以张成一个三维空间。(因为有两维线性相关,所以并不能张成4维)
基(基底)
基底也是建立在张成的基础上理解的。
一个向量空间的一个基底(A basis for a vector space V)是一串有顺序的向量(a sequence of vectors),满足:
A、向量之间彼此线性无关 (不可多余)
B、这些向量可以张成向量空间V (不可过少)
换句话说,刚刚好可以张成向量空间V的一串向量是该向量空间V的一个基底
基底是一个类似people的复数名词,是从属于某个空间的,而不是矩阵,也不是向量。
维度
一个向量空间可以有无数个基底。但每个基底所包含的向量的个数(the number of vectors in every basis)是一个空间的维度。注意,维度是空间的概念,而不是描述一个具体的向量。人们常说的n维向量实际是指n维向量空间内的向量,由于在讨论时并未给向量指定任何实际的数值,所以可以是任何值,可以张成整个空间。所以其真正描述的依旧是一个空间。并且,选择的维度是一个站在观察者角度,希望在某个向量空间下可以尽可能的描述一个物体的状态而选择的,并不一定是被描述者真实处在的空间。数学就是这么“拐外抹角”的去描述一个概念,不过确实非常有必要。但若是你觉得理解起来有困难。就简单记住:
互不相关的因素的个数是一个向量空间的维度。
秩
秩(rank)是矩阵的概念。指的是一个矩阵的所有列向量所能张成的空间的维度。
矩阵的所有列向量所张成的空间叫做列空间(column space)
矩阵的所有行向量所张成的空间叫做行空间(row space)
一个矩阵的列空间的维度是这个矩阵的秩,同时也等于该矩阵行空间的维度
秩是用于描述矩阵的包含的信息的
线性变换
线性变换(linear transformation)可以说是最最重要的概念了。你可以忘记我上面描述的所有内容,但不可以不深刻理解线性变换。下面是关于什么叫变换。由于概念很重要,我先不用逗比例子来解释。而用比较抽象的描述。
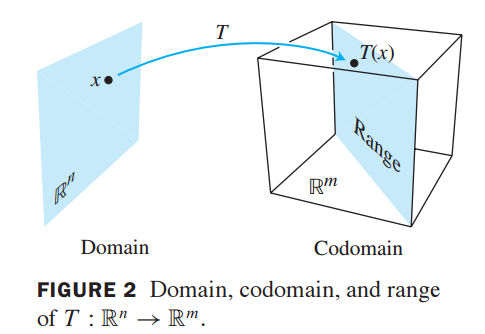
- 一个从n维实数域( Rn )到m维实数域( Rm )的变换(transformation or mapping or function) T 是将n维实数域( Rn )空间下任意一个向量 x 转换成为在m维实数域( Rm )空间下对应向量 T(x)
- 其中n维实数域( Rn )空间叫做变换 T 的domain,m维实数域( Rn )空间叫做该变换的codomain。
- 向量 T(x) 叫做向量 x 的image(变换 T 行为下的)
- 所有image组成的集合叫做变换 T 的range
而线性变换是是指线性规则所造成的变换, T() 是由一个矩阵 A 来实现的。此时你就会看到无处不在的式子:
y=Ax :列向量 x 左乘一个矩阵 A 后得到列向量 y
[applepenpineapplepen]=[100111]⋅⎡⎣⎢applepineapplepen⎤⎦⎥
(eq.4)举例来说,
x
是三维空间的向量(即
A
的domain是三维),而经过线性变换后,变成了二维空间的向量
y
(即
A
的codomain是二维)。
矩阵 A 可以被理解成一个函数(function),将三维空间下的每个向量投到二维空间下。
y=Ax 也可以理解为 x 经由一个动因 A ,使其状态发生了改变。
Ax 同时也是深层神经网络每层变换中的核心: y=a(Ax+b)
在机器学习中你会你会需要构架一个虚拟的世界,并选择合适的、用于描述某个事物状态的各种因素。
而线性代数正是有关如何构架“世界”的学问。
举一个小小的例子,比如你想通过温度,气候,湿度,当天时间,海拔,经度,纬度等信息来描述天气状况,从而进行预测是否会下雨。你如何合理的选择这些信息?你如何知道这些信息,海拔和气候如是否相关,是否重复?如果重复,那么你又是否可以减少某个信息?判断的准则又是什么?
数学讲的是我刚才所描述的内容的纯粹的结构关系。请你忘记我给你举得怪蜀黍例子,抓住“逻辑框架”。当你可以把这种关系应用在任何符合该结构关系的现实现象中时,你就算是精通了如何应用数学。
线性代数的内容十分庞大,行列式,特征矩阵,奇异值分解等你也会经常用到。然而我的描述就到此为止,我无法涵盖所有内容。写这篇文章只是希望能够用你脑中已有的概念帮助你构建一个对线性代数模糊的认识。当你今后用到线性代数时,再不断的加深和更正此刻的理解。