消息发送过程
使用Kafka发送消息时,一般有两种方式分别是:
- 同步发送
- 异步发送
同步发送时,可以在发送消息后,通过get方法等待消息结果,这种情况能够准确的拿到消息最终的发送结果,要么是成功、要么是失败。
而异步发送,是采用了callback的方式进行回调的,可以大大的的提升消息的吞吐量,也可以根据回调来判断消息是否发送成功。
不管是同步发送还是异步发送,最终都需要在Producer端把消息发送到Broker中,那么这个过程大致如下:
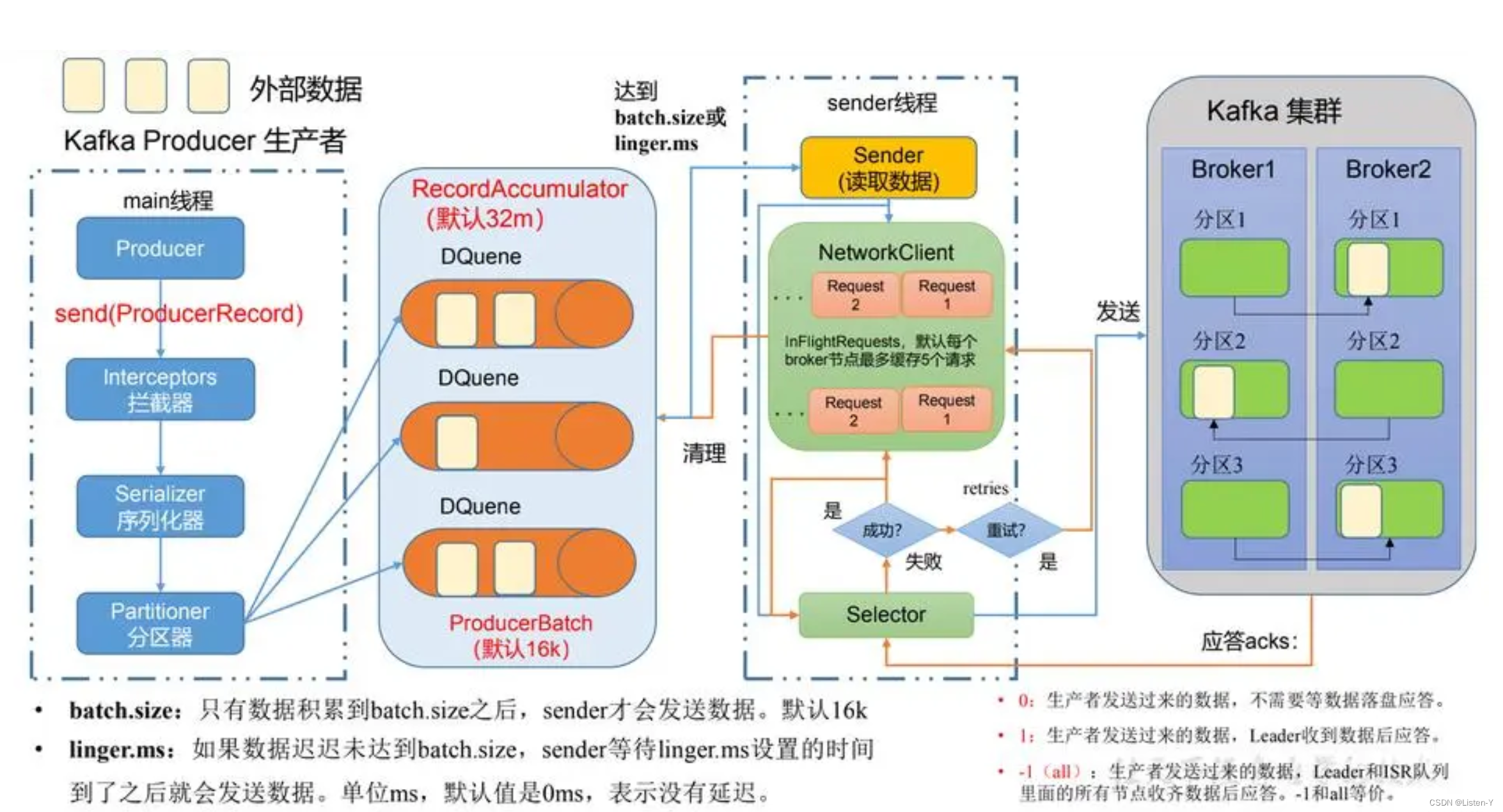
Kafka的Producer在发送消息时通常涉及两个线程,主线程(Main)和发送线程(Sender)和一个消息累加器(RecordAccumulator)
-
Main线程是Producer的入口,负责初始化Producer的配置、创建KafkaProducer实例并执行发送逻辑。它会按照用户定义的发送方式(同步或异步)发送消息,然后等待消息发送完成。一条消息的发送,在调用send方法后,会经过拦截器、序列化器及分区器。拦截器主要用于在消息发送之前和之后对消息进行定制化的处理,如对消息进行修改、记录日志、统计信息等。序列化器负责将消息的键和值对象转换为字节数组,以便在网络上传输。分区器决定了一条消息被发送到哪个Partition中。它根据消息的键(如果有)或者特定的分区策略,选择出一个目标Partition。
-
RecordAccumulator在Kafka Producer中起到了消息积累和批量发送的作用,当Producer发送消息时,不会立即将每条消息发送到Broker,而是将消息添加到RecordAccumulator维护的内部缓冲区中,RecordAccumulator会根据配置的条件(如batch.size、linger.ms)对待发送的消息进行批量处理。当满足指定条件时,RecordAccumulator将缓冲区中的消息组织成一个批次(batch),然后一次性发送给Broker。如果发送失败或发生错RecordAccumulator可以从将消息重新分配到新的批次中进行重试。这样可以确保消息不会丢失,同时提高消息的可靠性。
-
Send线程是负责实际的消息发送和处理的。发送线程会定期从待发送队列中取出消息,并将其发送到对应的Partition的 Leader Broker上。它主要负责网络通信操作,并处理发送请求的结果,包括确认的接收、错误处理等。
-
NetworkClient和Selector是两个重要的组件,分别负责网络通信和1/0多路复用。
发送线程会把消息发送到Kafka集群中对应的Partition的Parrtition Leader,Partition Leader接收到消息后,会对消息进行一系列的处理。它会将消息写入本地的日志文件(Log),存储为segment文件,因为是顺序写,segment文件也是顺序截断,为了保证数据的可靠性和高可用性,Kafka使用了消息复制机制。Leader Broker接收到消息后,会将消息复制到其他副本(Partition Follower)。副本是通过网络复制数据的,它们门会定期从LeaderBroker同步消息。
每一个Partition Follower在写入本地log之后,会向Leader发送一个TACK,但是我们的Producer其实也是需要依赖ACK才能知道消息有没有投递成功的,而这个ACK是何时发送的,Producer又要不要关心呢? 这就涉及到了kafka的ack机制,生产者会根据设置的request.required.acks参数不同,选择等待或或直接发送下一条消息:
- request.required.acks = 0
表示Producer不等待来自Leader的ACK确认,直接发送送下一条消息。在这种情况下,如果Leader分片所在服务器发生宕机,那么这些已经发送的数据会丢失。 - request.required.acks = 1
表示Producer等待来自Leader的ACK确认,当收到确认人后才发送下一条消息。在这种情况下,消息一定会被写入到 Leader服务器,但并不保证Follow节点已已经同步完成。所以如果在消息已经被写入Leader分片,但是还未同步到Follower节点,此时Leade分片所在服务器宕机了,那么这条消息也就丢失了,无法被消费到。 - request.required.acks = -1
Leader会把消息复制到集群中的所有ISR(In-Sync Replicas,同步副本),要等待所有ISR的ACK确认后,再向Producer发送ACK消息,然后Producer再继续发下下一条消息。
ISR机制
Kafka 中的 ISR(In-Sync Replicas)机制是一种用于确保数据可靠性和一致性的重要机制。ISR 是一组副本,它包括分区的领导者(Leader)和追随者(Follower)副本,这些副本与领导者保持数据同步。以下是关于 Kafka 的 ISR 机制的详细介绍:
- 意义:
ISR 机制动态维护了一个与 Leader 副本保持同步的副本集合,只有在 ISR 集合中的副本才有资格参与 Leader 的选举。通过 ISR 机制,可以确保在 Leader 副本出现故障时,能够快速从 ISR 集合中选举出新的 Leader,从而避免数据丢失和服务中断。
- 用途:
- 保证数据可靠性:ISR 机制通过副本冗余机制,提供了 Kafka 消息的高可靠性。
- 实现故障转移:ISR 机制可以做到故障转移,保障服务的可用性。当 Leader 副本出现故障时,Kafka 会从 ISR 集合中选举出新的 Leader,从而保证服务的连续性。
- 平衡复制方案:ISR 机制平衡了主从架构下,复制方案的选择(同步/异步/少数服从多数),让使用者根据参数自行选择。
- 实现方式:
- 数据同步:Leader Replica 接收到 Producer 发送的消息后,将其写入本地日志,并通过 Pull 模式等待 Follower Replica 主动拉取。Follower Replica 从 Leader Replica 拉取数据并写入本地日志后,将拉取偏移量(fetch offset)返回给 Leader。
- 同步状态监测:Leader Replica 持续监控每个 Follower Replica 的拉取偏移量,将其与自身的最新消息偏移量(log end offset)进行比较。若 Follower Replica 的拉取偏移量与 Leader 相差不超过一定阈值(由 replica.lag.time.max.ms 参数控制),则认为该 Follower 处于同步状态,将其纳入 ISR。
- ISR 调整:当 Follower Replica 因网络延迟、Broker 故障等原因导致拉取偏移量落后过多,超出阈值时,Leader Replica 会将其从 ISR 中移除。当 Follower Replica 恢复同步后,再次将其加入 ISR。
- 详细过程
当消息被写入Kafka的分区时,它首先会被写入Leader,然后LLeader将消息复制给ISR中的所有副本。只有当ISR中的所有副本都成功地接收到并确认了消息后,主副本才会认为消息已成功提交。这种机制确保了数据的可靠性和一致性。
在Kafka中,ISR(In-Sync Replicas)列表的维护是通过副本状态和配置参数来进行的。具体的ISR列表维护机制在不同的Kafka版本中有所变化。
- 在0.9.x之前的版本,Kafka有一个核心的参数:replica.lag.max.messages,表示如果Follower落后
Leader的消息数量超过了这个参数值,就认为Follower就会从ISR列表里移除。
但是,基于replica.lag.max.messages 这种实现,在瞬间高并发访问的情况下会有问题:比如Leader瞬间接收到几万条消息,然后所有Follower还没来得及同步过去,此时所有follower都会被踢出ISR列表。
- Kafka从0.9.x版本开始,引入了 replica.lag.max.ms参数,表示如果果某个Follower的LEO (latest end
offset)一直落后Leader超过了10秒,那么才会被从ISR列表里移除。
这样的话,即使出现瞬间流量,导致Follower落后很多数据,但是只要在限定的时间内尽快追上来就行了。
总之,通过 ISR 机制,Kafka 可以保证在 Leader 副本出现故障时,能够快速从 ISR 集合中选举出新的 Leader,从而避免数据丢失和服务中断。同时,ISR 机制也可以提高 Kafka 系统的可靠性和可用性。