当你在深夜享受高速下载一部高清电影,或是在关键时刻进行视频会议却毫无卡顿,你或许会为流畅的网络体验暗自庆幸。但你可曾意识到,这背后是网络 IO 底层原理在默默发力。它关乎我们每一次网络交互的顺畅与否,是保障高效数据通信的关键。现在,就让我们一同深入剖析网络 IO 底层原理,去理解那些让我们网络生活如此便捷的核心机制 。
一、网络Io概述
网络IO(输入/输出)是指计算机或设备与网络之间的通信,涉及数据、命令和响应的传输过程,允许信息交换以及通过网络访问资源和服务。简单来说,网络IO就是设备与网络之间的数据传输,比如你从网上下载文件或者上传图片,都是网络IO的例子。网络IO的过程可以分为输入和输出两个方向:
-
输入:指从网络接收数据或命令到设备的过程。例如,当你在浏览器中浏览网页时,网页的数据就是从网络输入到你的计算机中。
-
输出:指将数据或响应从设备传回网络的过程。比如,你发送一封电子邮件,邮件的数据就是从你的计算机输出到网络中。
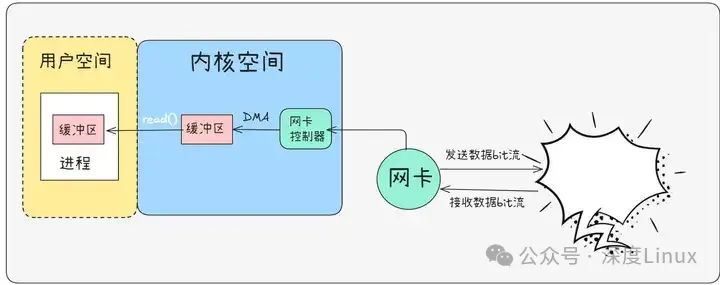
二、网络IO底层原理大揭秘
2.1硬件基础:网卡与中断
网络通信的起点是网卡,这个小小的硬件设备宛如计算机的 “网络触角”。当网线传来数据信号,网卡中的 PHY 芯片率先行动,它如同一位精准的翻译官,将电信号转换为比特流,紧接着 MAC 芯片登场,把比特流封装成数据帧,至此,网络数据完成了初步的 “变身”。但这些数据还需进入计算机的内存才能被进一步处理,这就要依靠 DMA(Direct Memory Access,直接存储器存取)技术了。
DMA 像是一条专属的数据高速公路,它允许网卡直接与内存交换数据,无需 CPU 过多干预,大大提高了数据传输效率。数据存入内存后,网卡会立即向 CPU 发送中断信号,就像拉响警报,告知 CPU:“有新数据抵达啦!”。CPU 收到中断后,会暂停当前手头的工作,迅速切换到中断处理程序。这个程序可是身负重任,一方面,它要将网卡接收缓冲区中的数据搬运到对应 socket 的接收缓冲区,确保数据有序存放;另一方面,它要查看等待该数据的进程,将阻塞中的进程唤醒,让其得以继续推进任务。如此一来,数据接收的前期准备工作便大功告成,后续进程就能顺利对数据进行处理。
2.2进程调度与阻塞
在操作系统的多任务处理体系里,进程调度起着关键的指挥作用。进程们如同忙碌的工人,各自有着不同的状态,运行、就绪、阻塞等。当一个进程执行到诸如 Recv 这样的网络接收函数,且此时所需数据尚未到达时,它就会进入阻塞状态,好似工人停下手中工作,进入休息等待区。这一阻塞状态设计得十分巧妙,它不会占用宝贵的 CPU 资源,因为此时进程处于被动等待,无需 CPU 持续关注。从进程调度层面看,处于阻塞态的进程会被移出运行队列,操作系统将 CPU 时间片分配给其他就绪进程,让系统整体保持高效运转。
以 Recv 函数为例,当进程调用它时,若接收缓冲区空空如也,进程便迅速切换至阻塞态,原地等待数据填充。期间,CPU 分身乏术,转而去处理其他就绪进程的任务。直到网卡接收数据并通过中断通知 CPU,CPU 执行中断处理程序,将数据存入接收缓冲区后,才会想起阻塞在此的进程,将其唤醒,重新放入运行队列。被唤醒的进程犹如睡饱的工人,立刻恢复活力,检查接收缓冲区,发现数据已就位,便开开心心地继续后续的数据处理流程。
①同步阻塞 IO(BIO)
同步阻塞 IO(Blocking IO,简称 BIO),作为最基础、最直观的 IO 模型,宛如一位坚守岗位、一步一个脚印的 “老实人”。在它的工作流程里,一旦用户进程发起一个 IO 操作,就如同向远方发出了一封等待回信的信件,之后便只能干巴巴地原地等待,直到内核完成数据的读取或写入,并将结果返回给用户进程,整个过程中,用户进程就像被 “冻结” 了一般,处于阻塞状态,无法抽身去处理其他事务。
以常见的网络编程场景为例,当服务器使用 BIO 模型来处理客户端连接时,服务端会开启一个线程,通过调用accept函数,如虔诚的守望者一般,静静地等待客户端的连接请求。一旦有新连接接入,服务端就会为这个连接单独开辟一个新线程,专门负责处理该连接上的数据读写。在这个新线程里,当调用read函数读取客户端发送的数据时,如果客户端还未发送数据,或者数据尚在网络传输途中,线程就会毫不犹豫地陷入阻塞,直至数据完整抵达内核缓冲区,并成功复制到用户进程缓冲区,才会 “苏醒” 过来继续后续的业务逻辑处理。
这种模型的弊端在高并发场景下暴露无遗。想象一下,在一个繁忙的网络服务器中,每来一个客户端连接就创建一个新线程,大量线程处于阻塞等待状态,不仅白白消耗系统宝贵的线程资源,还极易引发线程上下文切换的开销 “风暴”,使得系统性能如陷入泥沼的马车,愈发迟缓。不过,BIO 模型也并非一无是处,在并发量较小、对实时性要求极高,且每个连接都需要长时间独占资源进行复杂业务处理的场景下,它简单直接的特性反而能让代码逻辑清晰易懂,易于维护,就像在宁静的小村庄里,传统的手工作坊因其专注细致,依然能绽放独特的魅力。
②同步非阻塞 NIO
为了挣脱 BIO 模型中线程阻塞的 “枷锁”,同步非阻塞 IO(Non-Blocking IO,简称 NIO)应运而生。NIO 就像是一位充满活力、不愿被束缚的 “探险家”,当用户进程发起 IO 操作后,不再傻傻等待,而是立即返回,即便此时内核还未准备好数据,也绝不拖泥带水。不过,这也意味着进程需要时不时地主动去询问内核:“数据准备好了没?” 这种反复询问的方式,就如同探险家在未知的旅途中,不断地停下脚步,查看地图、寻找方向,生怕错过任何关键线索。
在 NIO 模型下,进程调用read函数时,如果内核缓冲区没有数据,函数不会阻塞线程,而是迅速返回一个特定的错误码(如在 Linux 系统下常返回EWOULDBLOCK),告知进程此刻无数据可读。进程收到这个信号后,就可以先去处理其他事务,待过一段时间后,再发起read调用,重新探询数据是否就绪。这种轮询机制虽然避免了线程长时间阻塞,但却也带来了新的问题:频繁的轮询如同不停旋转的陀螺,白白消耗大量 CPU 资源,让系统在忙碌中却难有高效产出。
从底层实现来看,NIO 借助操作系统提供的特定接口,巧妙地改变了内核与进程之间的交互模式。以 Java 语言为例,其java.nio包中的Channel(通道)和Buffer(缓冲区)便是 NIO 的核心组件。Channel就像是连接内核与用户进程的 “高速通道”,数据可以通过它在两者之间快速穿梭;而Buffer则是数据的临时 “停靠站”,无论是从内核读取数据,还是向内核写入数据,都需要先将数据暂存在Buffer中。
进程通过不断地切换Channel的读写状态,以及监控Buffer中的数据情况,实现与内核的高效协作,就如同探险家凭借精准的导航工具和灵活的应变策略,在复杂多变的环境中探索前行。虽然 NIO 在一定程度上优化了 IO 性能,但由于轮询带来的 CPU 开销问题,它仍然无法完美应对高并发场景下海量连接的挑战,于是,更为强大的多路复用 IO 模型登上了历史舞台。
③多路复用 IO
多路复用 IO 模型仿若一位足智多谋的 “指挥官”,能够统筹兼顾多个 IO 任务,让系统资源得到充分且高效的利用。它的核心思想是,通过一个专门的系统调用(如select、poll、epoll等函数),将多个文件描述符(File Descriptor,简称 fd,可简单理解为代表不同 IO 资源的 “标识符”,像网络套接字、文件等都有各自对应的 fd)集中交给内核进行监视。一旦其中某个或多个 fd 所对应的 IO 事件就绪(如可读、可写、出现异常等),内核便会及时通知用户进程,此时进程再针对就绪的 fd 进行相应的 IO 操作,避免了对未就绪 fd 的无效轮询,大大节省了 CPU 资源。
select函数,作为多路复用 IO 的 “先锋官”,历史悠久且兼容性极佳,几乎能在所有主流操作系统上找到它的身影。进程调用select时,需要将想要监视的 fd 集合(分别对应可读、可写、异常三种情况)传递给内核,随后进程便会陷入阻塞,如同指挥官下达作战指令后,静候前线的消息。内核则会按照既定规则,周期性地遍历这些 fd,逐一检查它们的状态。当发现有 fd 就绪,或者等待超时,select函数便会返回,进程此时苏醒,再通过遍历 fd 集合,使用特定的宏函数(如FD_ISSET)来精准定位哪些 fd 已经就绪,进而开展后续的数据处理。
然而,select也存在诸多 “短板”:一方面,它所能监视的 fd 数量存在硬上限,在 32 位系统中通常默认最多只能监视 1024 个 fd,这就如同指挥官的 “侦察视野” 受限,在大规模并发场景下显得力不从心;另一方面,每次调用select都需要将 fd 集合从用户空间拷贝到内核空间,并且在内核中遍历 fd 时采用的是线性扫描方式,效率低下,如同搬运大量物资时的来回奔波,以及在杂乱仓库中逐一翻找物品,耗时费力。
poll函数在功能上与select类似,好似一位接过 “指挥棒”、稍作改良的继任者。它摒弃了select中 fd 集合数量受限的弊端,采用链表结构来存储 fd,理论上可以监视的 fd 数量不再有明确的上限,只要系统资源允许。不过,poll在本质上依然没有摆脱select的 “低效魔咒”,每次调用时同样需要在用户空间与内核空间之间来回拷贝大量的 fd 信息,而且返回后也需要遍历所有 fd 来确定就绪情况,在高并发场景下,随着 fd 数量的激增,系统性能依然会如陷入泥沼的车辆,逐渐下滑。
直到epoll的出现,才真正为多路复用 IO 带来了革命性的突破,堪称一位 “卓越的战略大师”。epoll专为 Linux 系统量身打造(自 Linux 2.6 内核开始引入),它使用基于事件驱动的方式,彻底颠覆了select和poll的低效轮询模式。通过epoll_create函数创建一个epoll实例,就像是搭建起一座高效的 “指挥中心”;再利用epoll_ctl函数向这个实例中添加、修改或删除需要监视的 fd 及其关注的事件类型,相当于为各个 “侦察兵” 明确任务与职责;最后,进程调用epoll_wait函数,如同指挥官坐镇指挥中心,等待重要情报送达。
此时进程会阻塞,但与select不同的是,epoll采用了先进的回调机制,内核一旦监测到 fd 就绪,便会立即触发回调函数,将就绪的 fd 及其事件信息放入一个就绪链表中,epoll_wait函数直接从这个链表中获取就绪信息并返回给进程,无需像select和poll那样遍历所有 fd。这种机制使得epoll在处理海量并发连接时,性能表现极为出色,尤其是在活跃连接数占总连接数比例较低的场景下(如大量处于空闲等待状态的网络连接),能够精准且快速地响应就绪事件,让系统资源得到最大化利用,宛如一位能在千军万马中精准调度、从容指挥的名将。
④异步 IO
异步 IO 模型宛如一位神秘而高效的 “幕后英雄”,与前面几种模型相比,它将 “非阻塞” 的特性发挥到了极致。当用户进程发起一个 IO 操作后,就如同向一位万能助手下达了任务指令,随后便彻底放飞自我,无需再关注这个操作的执行进度,直接转身去处理其他事务。待内核完成数据的读取、写入以及从内核空间到用户空间的复制等一系列繁琐工作后,会以回调函数或者信号等方式,主动通知用户进程:“您交代的任务已经圆满完成啦!” 此时进程才悠然自得地回来处理数据,真正实现了 IO 操作与进程业务逻辑的完全分离。
以 Linux 系统下的aio_read和aio_write函数为例,进程调用这些函数发起异步 IO 请求时,函数会迅速返回,进程随即投身于其他任务的怀抱。内核则在后台默默承担起所有繁重的工作,包括与硬件设备的交互、数据的搬运与整理等。一旦数据准备妥当,内核便会依据进程预先设定的通知方式(如触发特定的信号,或者调用注册的回调函数),及时告知进程。
这种模型极大地解放了进程的 “生产力”,让其能在等待 IO 的漫长时间里,充分利用 CPU 资源创造更多价值,特别适用于那些对性能要求极高、IO 操作频繁且业务逻辑复杂的大型应用场景,如高性能数据库、大规模分布式存储系统等。只不过,异步 IO 模型对操作系统的底层支持要求颇高,就像一位需要顶级装备才能施展浑身解数的武林高手,在一些老旧或不支持的系统上难以发挥其全部威力,而且其编程实现的难度也相对较大,需要开发者具备深厚的系统知识与精湛的编程技巧,方能驾驭自如。
2.3缓冲区:数据的中转站
深入到 socket 的底层,会发现读写缓冲区是提升网络通信性能的得力助手。发送数据时,应用程序将数据写入 socket 的发送缓冲区,这里就像是货物的临时仓库,数据在此稍作停留。内核会按照网络协议,以合适的时机和节奏,将缓冲区中的数据分批发送出去,避免频繁打扰网卡进行小规模的数据传输,有效减轻网卡负担。接收数据时,网卡接收的数据先被暂存在接收缓冲区,等待应用程序有空时来提取。
这一机制极大地解耦了数据接收与处理的过程,即使应用程序因其他事务繁忙,未能及时处理数据,也不会导致数据丢失,它们安静地待在缓冲区中,随时等待被取用。例如在网络视频播放场景下,视频数据源源不断涌入接收缓冲区,播放器进程则按照播放节奏,从缓冲区中有序取出数据进行解码播放,既保证了播放的流畅性,又让网络数据收发与视频处理各司其职,互不干扰,全方位提升用户观看体验。
三、socket套接字:网络通信的基石
3.1Socket 是什么
Socket,常被译为 “套接字”,它宛如网络上进程通信的端点,是应用程序与网络协议栈交互的关键接口。追溯其起源,Socket 诞生于 Unix 的 “一切皆文件” 理念之下,从某种意义上来说,它是一种特殊的 “文件”,诸多 socket 函数便是对其进行类似文件操作,如打开、读写、关闭等。当程序调用 socket 函数时,就如同打开一个特殊文件,会返回一个整型的 Socket 描述符,后续的连接建立、数据传输等操作都围绕这个描述符展开,它就像一把钥匙,开启了网络通信的大门,让不同主机上的进程得以跨越网络的鸿沟,实现数据的交互与共享。
在 UNIX/Linux 系统中,为了统一对各种硬件的操作,简化接口,不同的硬件设备也都被看成一个文件。对这些文件的操作,等同于对磁盘上普通文件的操作。
你也许听很多高手说过,UNIX/Linux 中的一切都是文件!那个家伙说得没错。
为了表示和区分已经打开的文件,UNIX/Linux 会给每个文件分配一个 ID,这个 ID 就是一个整数,被称为文件描述符(File Descriptor)。例如:
-
通常用 0 来表示标准输入文件(stdin),它对应的硬件设备就是键盘;
-
通常用 1 来表示标准输出文件(stdout),它对应的硬件设备就是显示器。
UNIX/Linux 程序在执行任何形式的 I/O 操作时,都是在读取或者写入一个文件描述符。一个文件描述符只是一个和打开的文件相关联的整数,它的背后可能是一个硬盘上的普通文件、FIFO、管道、终端、键盘、显示器,甚至是一个网络连接。请注意,网络连接也是一个文件,它也有文件描述符!
我们可以通过 socket() 函数来创建一个网络连接,或者说打开一个网络文件,socket() 的返回值就是文件描述符。有了文件描述符,我们就可以使用普通的文件操作函数来传输数据了,例如:
-
用 read() 读取从远程计算机传来的数据;
-
用 write() 向远程计算机写入数据。
-
只要用 socket() 创建了连接,剩下的就是文件操作了,网络编程原来就是如此简单!
普通的I/O操作过程:打开文件>>>>>读/写文件>>>>>关闭文件,同一台主机上的两个进程可以通过管道、信号、共享内存等进行通信,那么两个不在同一台主机上的进程怎么进行通信呢?
TCP/IP协议被集成到操作系统的内核中,这就引入了新型的“I/O”操作,当两个不在一台主机上的进程要进行通信时,这时就需要socket套接字。
3.2工作原理详述
以常见的 TCP 协议下的 Socket 通信为例,服务器与客户端的交互流程有条不紊。服务器端率先行动,初始化 Socket 后,通过 bind 函数将 Socket 与特定的 IP 地址和端口号绑定,这一步就像是在网络世界中选定了一个专属的 “门牌号”,让客户端能够精准定位。接着,调用 listen 函数,让 Socket 进入监听状态,静静等候客户端的连接请求,犹如一位耐心的门卫。此时,如果有客户端发起连接,客户端首先创建自己的 Socket,指定要连接的服务器 IP 地址与端口号,随后调用 connect 函数发出连接请求,这一请求信号如同叩响服务器大门的门铃。
服务器监听到请求后,调用 accept 函数接受连接,此函数会阻塞线程,直到有客户端连接到来,一旦连接建立,服务器会创建一个新的 Socket 专门用于与该客户端通信,而原先监听的 Socket 依旧坚守岗位,继续监听新的连接请求。双方建立连接后,便可以通过 send 和 recv 等函数进行数据的发送与接收,实现信息的互通。
在这个过程中,Socket 的阻塞与非阻塞模式差异显著。阻塞模式下,当执行如 recv 等读写操作时,如果没有数据可读或无法立即写入数据,线程就会陷入等待,如同车辆在红灯前停下,直至条件满足才继续前行,这种模式代码编写相对简洁,适用于连接数较少且对实时性要求不高的场景,例如小型的文件传输工具,一次只处理一个文件传输任务,无需频繁切换线程。
而非阻塞模式则截然不同,读写操作若遇数据未就绪或写入受阻,函数会立即返回错误码,线程不会被阻塞,如同敏捷的飞鸟,遇到阻碍即刻转向,继续执行后续代码,不过这需要开发者通过轮询或事件通知机制来主动判断数据状态,代码复杂度增加,但在高并发场景下优势尽显,像大型的在线游戏服务器,需要同时处理海量玩家的数据交互,非阻塞模式能高效利用系统资源,避免线程长时间闲置等待。
3.3Socket 类型全解析
Socket 家族成员众多,各具特色,其中流套接字(SOCK_STREAM)、数据报套接字(SOCK_DGRAM)、原始套接字(SOCK_RAW)是最为常见的三种类型。
①流式套接字(SOCK_STREAM)-----面向连接的套接字
流格式套接字(Stream Sockets)也叫“面向连接的套接字”,在代码中使用 SOCK_STREAM 表示。它提供了一种可靠的、面向连接的双向数据传输服务,实现了数据无差错、无重复的发送,保证数据传输的可靠性和按序收发。如果数据损坏或丢失,可以重新发送。流格式套接字有自己的纠错机制。流式套接字内设流量控制,被传输的数据看作是无记录边界的字节流。在TCP/IP协议簇中,使用TCP协议来实现字节流的传输,当用户想要发送大批量的数据或者对数据传输有较高的要求时,可以使用流式套接字。
流失套接字特点:
-
传输过程中数据不会丢失
-
按序传输数据
-
传输的数据不存在数据边界
可以将 SOCK_STREAM 比喻成一条传送带,只要传送带本身没有问题(不会断网),就能保证数据不丢失;同时,较晚传送的数据不会先到达,较早传送的数据不会晚到达,这就保证了数据是按照顺序传递的。
为什么流格式套接字可以达到高质量的数据传输呢?这是因为它使用了 TCP 协议(The Transmission Control Protocol,传输控制协议),TCP 协议会控制你的数据按照顺序到达并且没有错误。
TCP 用来确保数据的正确性,IP(Internet Protocol,网络协议)用来控制数据如何从源头到达目的地,也就是常说的“路由”。
那么,“数据的发送和接收不同步”该如何理解呢?
假设传送带传送的是水果,接收者需要凑齐 100 个后才能装袋,但是传送带可能把这 100 个水果分批传送,比如第一批传送 20 个,第二批传送 50 个,第三批传送 30 个。接收者不需要和传送带保持同步,只要根据自己的节奏来装袋即可,不用管传送带传送了几批,也不用每到一批就装袋一次,可以等到凑够了 100 个水果再装袋。
流格式套接字的内部有一个缓冲区(也就是字符数组),通过 socket 传输的数据将保存到这个缓冲区。接收端在收到数据后并不一定立即读取,只要数据不超过缓冲区的容量,接收端有可能在缓冲区被填满以后一次性全部读取,也可能分成好几次读取。也就是说,在面向连接的套接字中,read函数和write函数的调用次数并无太大意义。所以说面向连接的套接字不存在数据边界。
也就是说,不管数据分几次传送过来,接收端只需要根据自己的要求读取,不用非得在数据到达时立即读取。传送端有自己的节奏,接收端也有自己的节奏,它们是不一致的。
那么接收数据的缓冲区被接收的数据填满会怎样,之后传递的数据是否会丢失呢?
首先调用read函数从缓冲区读取部分数据,因此,缓冲区并不总是满的。但如果read函数读取速度比接收数据的速度慢,则缓冲区有可能被填满。此时套接字无法再接收数据,但即使这样也不会丢失数据,因为这时传输端套接字将停止传输。也就是说,面向连接的套接字会根据接收端的状态进行数据传输,如果传输出错还会提供重传服务。因此,面向连接的套接字除特殊情况外不会发生数据丢失。
流格式套接字有什么实际的应用场景吗?浏览器所使用的 http 协议就基于面向连接的套接字,因为必须要确保数据准确无误,否则加载的 HTML 将无法解析。
②数据报套接字(SOCK_DGRAM)-----面向消息的套接字
数据报格式套接字(Datagram Sockets)也叫“无连接的套接字”,在代码中使用 SOCK_DGRAM 表示。它提供了一种无连接、不可靠的双向数据传输服务。数据通过相互独立的报文进行传输,是无序的,并且保留了记录边界,不提供可靠性保证。数据在传输过程中可能会丢失或重复,并且不能保证在接收端按发送顺序接收数据。计算机只管传输数据,不作数据校验,如果数据在传输中损坏,或者没有到达另一台计算机,是没有办法补救的。
也就是说,数据错了就错了,无法重传。在TCP/IP协议簇中,使用UDP协议来实现数据报套接字。在出现差错的可能性较小或允许部分传输出错的应用场合,可以使用数据报套接字进行数据传输,这样通信的效率较高。
因为数据报套接字所做的校验工作少,所以在传输效率方面比流格式套接字要高;可以将 SOCK_DGRAM 比喻成高速移动的摩托车快递,它有以下特征:
-
强调快速传输而非传输顺序
-
传输的数据可能丢失也可能损毁
-
限制每次传输的数据大小
-
数据的发送和接收是同步的(有的教程也称“存在数据边界”)
面向消息的套接字比面向连接的套接字具有更快的传输速度,但无法避免数据丢失或损毁。另外,每次传输的数据大小具有一定限制,并存在数据边界。存在数据边界意味着接收数据的次数应和传输次数相同。总之,数据报套接字是一种不可靠的、不按顺序传递的、以追求传输速度为目的的套接字。
数据报套接字也使用 IP 协议作路由,但是它不使用 TCP 协议,而是使用 UDP 协议(User Datagram Protocol,用户数据报协议)。
QQ 视频聊天和语音聊天就使用 SOCK_DGRAM 来传输数据,因为首先要保证通信的效率,尽量减小延迟,而数据的正确性是次要的,即使丢失很小的一部分数据,视频和音频也可以正常解析,最多出现噪点或杂音,不会对通信质量有实质的影响。
③原始套接字(SOCK_RAM)
该套接字允许对较低层协议(如IP或ICMP)进行直接访问,它功能强大使用较为不便,常用于网络协议分析,检验新的网络协议实现,也可用于测试新配置或安装的网络设备。
流套接字基于可靠的 TCP 协议打造,它为数据传输搭建了一条稳固的 “高速公路”,确保数据能够按序、无差错、无重复地从一端流向另一端。就像我们浏览网页,使用 HTTP 协议,其底层便是依赖流套接字,网页的 HTML、CSS、JavaScript 等文件必须完整且准确无误地传输到浏览器端,才能呈现出精美的页面,任何数据丢失或乱序都会导致页面解析出错,影响用户浏览体验。
数据报套接字则依托 UDP 协议,主打高效传输。它在数据传输时犹如投递信件,计算机只管将数据打包成一个个 “信件”(数据报)发送出去,不做过多的数据校验,即便部分 “信件” 在途中丢失或损坏,也不会补发。这种特性使得它在对实时性要求极高的场景大放异彩,比如 QQ 视频聊天、在线游戏中的实时位置同步等,少量的数据丢失并不会对整体的通信质量造成毁灭性打击,偶尔出现的画面噪点、声音卡顿,相较于流畅的实时互动,用户尚可接受,而高效的传输则保障了低延迟,让交流更加顺畅自然。
原始套接字宛如一位深入底层的 “探险家”,它给予开发者直接访问内核没有处理的 IP 数据包的权限,能够触及网络协议的底层细节。像网络安全监控软件、网络流量分析工具等,就需要借助原始套接字的力量,捕获原始的网络数据包,从中挖掘潜在的安全威胁、分析网络流量走向,为网络稳定运行保驾护航,这种底层操作能力虽强大,但对开发者要求较高,使用不当容易引发网络问题,如同在精密的机器内部操作,需要十足的谨慎。
四、epoll:高性能的io多路复用神器
4.1IO 多路复用概述
在网络编程的世界里,IO 多路复用是一项至关重要的技术。简单来说,它就像是一位神通广大的 “调度员”,允许单个进程 / 线程同时监听多个输入输出源,这些输入输出源通常以文件描述符(File Descriptor,FD)来表示,涵盖了网络套接字、文件、管道等各种类型。当其中任意一个或多个源有事件就绪,比如数据可读、可写,或是出现错误等情况,“调度员” 便能迅速察觉,并通知应用程序及时进行相应的读写操作。
这与传统的逐个监听方式截然不同,传统模式下,若要监听多个源,每个源都需对应一个独立的线程或进程,如此一来,系统资源极易被大量消耗,尤其是在面对海量连接时,线程上下文切换开销巨大,效率急剧下降。而 IO 多路复用技术则巧妙地解决了这一难题,它让多个 IO 操作共享同一个进程或线程,极大提高了资源利用率,使得系统能够轻松应对高并发场景,成为网络编程领域的核心技术之一。在 Linux 系统中,epoll 便是这一技术的典型代表,它以内核实现为依托,为高性能网络编程提供了强有力的支持。
为什么要使用epoll?
同样,我们在linux系统下,影响效率的依然是I/O操作,linux提供给我们select/poll/epoll等多路复用I/O方式(kqueue暂时没研究过),为什么我们对epoll情有独钟呢?原因如下:
⑴文件描述符数量的对比
epoll并没有fd(文件描述符)的上限,它只跟系统内存有关,我的2G的ubuntu下查看是20480个,轻松支持20W个fd。可使用如下命令查看:
cat /proc/sys/fs/file-max再来看select/poll,有一个限定的fd的数量,linux/posix_types.h头文件中
#define __FD_SETSIZE 1024⑵效率对比
当然了,你可以修改上述值,然后重新编译内核,然后再次写代码,这也是没问题的,不过我先说说select/poll的机制,估计你马上会作废上面修改枚举值的想法。
select/poll会因为监听fd的数量而导致效率低下,因为它是轮询所有fd,有数据就处理,没数据就跳过,所以fd的数量会降低效率;而epoll只处理就绪的fd,它有一个就绪设备的队列,每次只轮询该队列的数据,然后进行处理。
⑶内存处理方式对比
不管是哪种I/O机制,都无法避免fd在操作过程中拷贝的问题,而epoll使用了mmap(是指文件/对象的内存映射,被映射到多个内存页上),所以同一块内存就可以避免这个问题。
btw:TCP/IP协议栈使用内存池管理sk_buff结构,你还可以通过修改内存池pool的大小,毕竟linux支持各种微调内核。
4.2epoll 的核心 API 与数据结构
epoll 的强大功能主要通过三个核心 API 来实现,它们紧密协作,背后还有精妙的数据结构支撑。
首先是 epoll_create 系统调用,它宛如开启一扇通往 epoll 世界的大门,其参数 size 原本用于告知内核这个 epoll 对象大致会处理的事件数量,不过在现今的 Linux 版本中,此参数已基本失去意义,可随意传入一个大于 0 的值,调用成功后,内核会生成一个 epoll 实例数据结构,并返回一个文件描述符,后续对该 epoll 实例的操作都将围绕这个句柄展开,它就像一把钥匙,掌控着与 epoll 相关的一切资源访问权限。
接着是 epoll_ctl 函数,这是 epoll 的 “操控枢纽”,用于向 epoll 对象添加、修改或删除事件。它的参数 op 明确操作类型,如 EPOLL_CTL_ADD 用于添加新的待监听事件,EPOLL_CTL_DEL 则将某个已监听事件移除,EPOLL_CTL_MOD 负责修改现有监听事件的属性。
fd 参数指定要操作的文件描述符,而 event 参数是一个关键结构体,其中的 events 字段描述期望监听的 epoll 事件,像常见的 EPOLLIN 代表对应连接上有数据可读,EPOLLOUT 表示连接可写发送,EPOLLET 则用于设定边缘触发模式,不同的事件组合让开发者能精准掌控对各类 IO 事件的监听需求。
最后是 epoll_wait 函数,它是应用程序等待事件发生的 “瞭望哨”。应用程序调用它时,会阻塞等待注册事件的就绪通知,一旦有事件触发,它便收集 epoll 监控的事件中已经发生的那些,将触发的事件信息写入传入的 events 数组中,并返回当前发生的事件个数。
其中,events 数组必须由用户态分配内存,内核会负责把就绪事件复制到该数组,maxevents 参数限定了本次可以返回的最大事件数目,通常设置为 events 数组的长度,timeout 参数则规定了阻塞等待的最长时间,不同取值对应不同的等待策略,如 - 1 表示一直阻塞直到有文件描述符就绪或捕获到信号,0 用于非阻塞检测,大于 0 则是限时等待。
这一系列 API 操作背后,是红黑树和链表两大核心数据结构在默默发力。红黑树作为一种自平衡的二叉搜索树,承担着高效管理所有被监听文件描述符的重任。当执行 epoll_ctl 添加、删除或修改操作时,其时间复杂度仅为 O (log n),能够快速定位目标文件描述符,确保操作的高效性,无论面对多少个文件描述符,都能有条不紊地进行管理。而链表,通常以双向链表形式呈现,它扮演着存储就绪事件的关键角色。
每当有文件描述符就绪,内核便通过回调机制将其加入链表,当 epoll_wait 被调用时,只需遍历这个链表,就能迅速将所有就绪的文件描述符返回给应用程序,无需像传统方式那样遍历所有被监听的文件描述符,极大地节省了 CPU 时间,提升了系统响应速度。
4.3触发方式:水平触发与边缘触发
epoll 支持两种触发方式:水平触发(Level Trigger,LT)与边缘触发(Edge Trigger,ET),它们犹如 epoll 的两种 “通知风格”,各有千秋。
水平触发是 epoll 的默认工作模式,它的行为模式较为 “贴心”。对于读操作而言,只要内核缓冲区中存有数据,即缓冲内容不为空,LT 模式便认定读事件就绪,返回读就绪通知,告知应用程序可以前来读取数据。同理,对于写操作,只要缓冲区还有空闲空间,尚未写满,就会返回写就绪状态。
在这种模式下,即便应用程序此次没有一次性将数据全部读写完毕,比如读写缓冲区设置较小,未能一次容纳所有数据,下次调用 epoll_wait 时,它依然会贴心地再次通知,仿佛在轻声提醒:“还有数据没处理完呢,快来继续。” 这种模式编程出错的概率相对较小,因为它给予应用程序足够的 “容错空间”,让开发者无需过度担忧数据遗漏问题,传统的 select、poll 其实也类似这种工作方式,对于初学者或是对实时性、准确性要求极高的场景,LT 模式是较为稳妥的选择。
与之相对的边缘触发则像是一位 “高效信使”,只在状态发生关键变化时才传递消息。对于读操作,当缓冲区由不可读变为可读,也就是从空变为不空的瞬间,或者当有新数据到达,使得缓冲区中的待读数据量增多时,又或是应用进程通过 EPOLL_CTL_MOD 修改 EPOLLIN 事件时,ET 模式才会触发读就绪通知,告知应用程序有新数据到来,且仅通知这一次。
后续即便缓冲区还有剩余数据未读完,只要没有新的状态变化,它便不再发声。写操作同理,当缓冲区由不可写变为可写,例如旧数据被成功发送走,腾出空间,或是缓冲区空间状态因其他原因改变且应用进程修改 EPOLLOUT 事件时,才触发写就绪通知。
这种模式下,应用程序需要更加 “机灵”,通常要配合非阻塞的文件描述符使用,并且要确保在收到通知后尽可能一次性处理完数据,避免错过读取或写入时机,因为一旦错过,可能要等到下一次状态变化才能再次得到通知。不过,也正因如此,ET 模式减少了不必要的通知次数,降低了内核与用户态之间的频繁交互,在处理高并发、追求极致性能的场景中,能有效减少 CPU 资源浪费,提升系统整体吞吐量。
在实际应用场景选择上,如果是开发诸如简单的文件传输服务器,数据读写相对平稳,对性能要求不是顶级严苛,且希望代码逻辑简洁、容错性高,水平触发模式足以胜任。而像大型的即时通讯服务器、高性能的网络代理服务器等,面对海量并发连接,每一次系统调用、每一点 CPU 资源都极为珍贵,此时边缘触发模式结合非阻塞 IO,便能充分发挥其高性能优势,让服务器在高负载下依然游刃有余,快速响应各类客户端请求,保障服务质量。
五、用户态与内核太:系统的双重世界
5.1为何要有两种状态
在计算机操作系统的精妙架构里,用户态与内核态宛如两个截然不同的 “世界”,它们的划分绝非偶然,而是源于对系统安全与稳定性的深度考量。现代操作系统管理着海量的资源,像内存、硬盘、CPU 等硬件设备,以及各类系统关键数据结构,这些犹如一座精密大厦的基石,一旦遭到破坏,整个系统将面临崩塌的危险。从权限角度出发,为了防止普通应用程序因误操作或恶意行为肆意篡改系统关键数据、干扰硬件运行,操作系统巧妙地划分出用户空间与内核空间。
用户态如同一个被约束的 “访客”,运行在其中的应用程序权限受限,只能访问自己所属的用户空间内存区域,执行非特权指令,对于如直接操控硬件设备、修改内核数据结构这类高危操作,被严格禁止,犹如访客只能在指定房间活动,不能触碰大厦的核心设施。而内核态则如同大厦的 “管理员”,拥有至高无上的权限,能够自由穿梭于内核空间,执行所有 CPU 指令,无论是调配内存、调度进程,还是驱动硬件设备,都游刃有余,全方位保障系统的稳定运行。
以常见的硬盘读写操作为例,用户程序若想从硬盘读取数据,自身并无直接与硬盘控制器交互的能力,因为它处于权限受限的用户态。此时,只能通过系统调用向内核发起请求,内核以其内核态的特权身份接管后续流程,精准地与硬盘控制器沟通,按照既定的存储逻辑定位数据、读取数据,再将数据安全地传递回用户程序。这种严格的权限划分机制,如同坚固的防护盾,有效隔离了不稳定因素,确保系统核心部分不受外界干扰,持续稳定运行。
5.2状态切换的关键时刻
进程在运行过程中,并非一成不变地处于某种状态,而是会依据特定的场景,灵活地在用户态与内核态之间切换。其中,系统调用、硬中断、用户态代码出错是引发切换的常见导火索。
系统调用是进程主动寻求内核协助的重要途径。当应用程序执行如打开文件(open 函数)、网络通信(socket 相关函数)等操作时,由于这些操作涉及系统底层资源的调配,必须借助内核的力量。以读取文件为例,用户进程调用 read 函数,这一操作瞬间触发系统调用,进程如同礼貌的求助者,通过特定的软中断指令(如 Linux 中的 int 0X80)向内核发出请求,告知内核自身需求,随后 CPU 迅速响应,暂停当前用户态代码执行,转而进入内核态,将控制权移交内核,由内核中的对应代码逻辑接手处理文件读取流程,从磁盘寻址、数据加载到最终准备好供用户进程使用的数据。
硬中断则像是系统的 “紧急警报”,由外部硬件设备触发。像网卡接收到新的网络数据包、键盘有按键按下、硬盘完成读写操作等情况,硬件设备会立即向 CPU 发送中断信号。CPU 在执行用户态程序时收到该信号,会即刻放下手头的工作,紧急切换至内核态,运行相应的中断处理程序。例如,网卡触发中断后,内核态的中断处理程序迅速启动,它高效地接收数据包,将数据搬运至内存缓冲区,必要时唤醒等待该数据的进程,一系列操作一气呵成,确保硬件数据及时响应处理,不出现延误。
此外,当用户态代码运行出现错误,如访问非法内存地址、执行除零等非法运算时,CPU 硬件检测到异常,为避免错误进一步恶化,会立即强制切换至内核态,让内核中的异常处理程序介入。内核会依据错误类型,采取诸如终止出错进程、向其他相关进程发送信号等措施,维护系统整体的稳定运行,避免因单个进程的错误拖垮整个系统。
5.3切换过程中的细节
进程在用户态与内核态之间切换时,背后实则隐藏着一套严谨且复杂的流程,涉及多个关键步骤,每一步都对保障系统稳定运行起着至关重要的作用。
当进程即将切换至内核态,首要任务便是保存现场。此时,CPU 会迅速将当前进程在用户态下的寄存器上下文信息妥善保存起来,这些寄存器犹如进程运行的 “工作笔记”,记录着程序计数器(指向当前执行指令的下一条指令地址)、通用寄存器(存储着运算数据、变量值等关键信息)等内容,保存它们是为了后续能精准恢复现场,让进程在返回用户态时能无缝衔接,继续未完成的任务。
紧接着,若是因系统调用引发的切换,还需将用户态传递给内核的参数精准复制到内核空间,确保内核能准确理解用户进程的需求。完成参数传递后,内核会严谨地对进程的权限进行检查,核实此次切换是否合规,杜绝非法越权行为,如同重要场所的门禁检查,只有持有合法 “权限凭证” 的进程才能顺利通行。
权限检查无误后,内核开始执行对应的内核代码,无论是处理系统调用请求、响应中断,还是化解异常,内核都凭借其专业的 “技能”,有条不紊地完成任务。任务执行完毕,若有数据需要返回给用户进程,内核会小心地将结果数据复制回用户态空间,确保数据传递准确无误。
最后,在返回用户态之前,CPU 依据之前保存的寄存器上下文信息,将各个寄存器恢复至切换前状态,就像将散落的拼图碎片重新拼凑完整,让进程能在熟悉的用户态环境中继续前行,保证整个系统运行的连贯性与数据的一致性,为用户提供流畅、稳定的使用体验。
六、全文总结
通用网络 IO 底层原理、Socket、epoll 以及用户态内核态,这些知识板块紧密相连,共同构建了高效网络通信的基石。网卡与中断作为硬件基础,开启了数据流入计算机的大门,为后续处理提供原始素材;进程调度与阻塞机制、缓冲区设计巧妙平衡了系统资源利用与数据处理节奏,让进程有条不紊地运行。Socket 则凭借其独特的接口特性,成为网络通信的关键枢纽,不同类型的 Socket 满足多样化的通信需求,无论是可靠的流传输还是高效的数据包投递,亦或是深入底层的原始数据探索,它都能精准应对。
而 epoll 以其卓越的 IO 多路复用能力,在高并发场景下独领风骚,红黑树与链表的数据结构精妙配合,水平触发与边缘触发模式各展所长,为系统高效处理海量连接提供有力支撑。用户态与内核态的明确划分,宛如坚实的安全堡垒,保障系统稳定运行,通过严谨的状态切换机制,实现了应用程序与内核的协同合作。
在网络编程、服务器开发等诸多领域,深刻理解这些知识至关重要。对于开发者而言,掌握它们意味着能精准优化程序性能,在面对高并发挑战时游刃有余,打造出响应迅速、稳定可靠的网络应用。无论是构建大型电商平台应对购物高峰的海量订单处理,还是开发即时通讯软件保障信息实时畅达,又或是运营在线游戏服务器让玩家畅享流畅对战,这些知识都是背后的核心支撑力量。希望各位读者在今后的学习与实践中,能不断深入探索,将这些知识灵活运用,在网络编程的广阔天地里大展拳脚,创造出更多精彩的应用,推动技术的持续进步。