在 Linux 系统的复杂架构中,系统调用是用户空间与内核空间交互的关键桥梁。而 Hook 技术,则像是一把神奇的 “钥匙”,能够巧妙地介入系统调用的流程,实现各种强大而有趣的功能。无论是安全领域的监控防护,还是性能优化方面的精准调控,Hook 技术都发挥着重要作用。今天,就让我们深入 Linux 系统调用的世界,揭开 Hook 技术的神秘面纱。
一、Linux系统调用简介
系统调用(syscall)是一个通用的概念,它既包括应用层系统函数库的调用,也包括ring0层系统提供的syscall_table提供的系统api。
1.1系统调用的概念
系统调用是操作系统内核提供给用户空间应用程序使用的接口。当应用程序需要访问硬件资源(如磁盘、网络)、创建进程、分配内存等操作时,就会通过系统调用陷入内核态,由内核来完成这些任务。例如,常见的文件读写函数read和write,在底层实际上就是通过系统调用实现的。
1.2系统调用的实现机制
在 Linux 中,系统调用通过软件中断实现。以 x86 架构为例,应用程序执行int 0x80指令(在较新的内核中,也使用sysenter指令),触发一个软件中断,CPU 会切换到内核态,然后根据系统调用号在系统调用表中找到对应的内核函数进行执行。系统调用表是一个存储了所有系统调用函数指针的数组,每个系统调用都有唯一的编号,通过这个编号可以快速定位到相应的处理函数。
我们必须要明白,Hook技术是一个相对较宽的话题,因为操作系统从ring3到ring0是分层次的结构,在每一个层次上都可以进行相应的Hook,它们使用的技术方法以及取得的效果也是不尽相同的。本文的主题是"系统调用的Hook学习","系统调用的Hook"是我们的目的,而要实现这个目的可以有很多方法,本文试图尽量覆盖从ring3到ring0中所涉及到的Hook技术,来实现系统调用的监控功能。
二、Hook技术详解
2.1Ring3中Hook技术
⑴LD_PRELOAD动态连接.so函数劫持
LD_PRELOAD hook技术属于so依赖劫持技术的一种实现,所以要讨论这种技术的技术原理,我们先来看一下linux操作系统加载so的底层原理。
括Linux系统在内的很多开源系统都是基于Glibc的,动态链接的ELF可执行文件在启动时同时会启动动态链接器(/lib/ld-linux.so.X),程序所依赖的共享对象全部由动态链接器负责装载和初始化,所以这里所谓的共享库的查找过程,本质上就是动态链接器(/lib/ld-linux.so.X)对共享库路径的搜索过程,搜索过程如下:
/etc/ld.so.cache:Linux为了加速LD_PRELOAD的搜索过程,在系统中建立了一个ldconfig程序,这个程序负责
-
将共享库下的各个共享库维护一个SO-NAME(一一对应的符号链接),这样每个共享库的SO-NAME就能够指向正确的共享库文件
-
将全部SO-NAME收集起来,集中放到/etc/ld.so.cache文件里面,并建立一个SO-NAME的缓存
-
当动态链接器要查找共享库时,它可以直接从/etc/ld.so.cache里面查找。所以,如果我们在系统指定的共享库目录下添加、删除或更新任何一个共享库,或者我们更改了/etc/ld.so.conf、/etc/ld.preload的配置,都应该运行一次ldconfig这个程序,以便更新SO-NAME和/etc/ld.so.cache。很多软件包的安装程序在结束共享库安装以后都会调用ldconfig
根据/etc/ld.so.preload中的配置进行搜索(LD_PRELOAD):这个配置文件中保存了需要搜索的共享库路径,Linux动态共享库加载器根据顺序进行逐行广度搜索
根据环境变量LD_LIBRARY_PATH指定的动态库搜索路径:
根据ELF文件中的配置信息:任何一个动态链接的模块所依赖的模块路径保存在".dynamic"段中,由DT_NEED类型的项表示,动态链接器会按照这个路径去查找DT_RPATH所指定的路径,编译目标代码时,可以对gcc加入链接参数"-Wl,-rpath"指定动态库搜索路径。
-
DT_NEED段中保存的是绝对路径,则动态链接器直接按照这个路径进行直接加载
-
DT_NEED段中保存的是相对路径,动态链接器会在按照一个约定的顺序进行库文件查找下列路径:/lib、/usr/lib、/etc/ld.so.conf中配置指定的搜索路径
可以看到,LD_PRELOAD是Linux系统中启动新进程首先要加载so的搜索路径,所以它可以影响程序的运行时的链接(Runtime linker),它允许你定义在程序运行前"优先加载"的动态链接库。
我们只要在通过LD_PRELOAD加载的.so中编写我们需要hook的同名函数,根据Linux对外部动态共享库的符号引入全局符号表的处理,后引入的符号会被省略,即系统原始的.so(/lib64/libc.so.6)中的符号会被省略。
通过strace program也可以看到,Linux是优先加载LD_PRELOAD指明的.so,然后再加载系统默认的.so的:

⑵通过自写.so文件劫持LD_PRELOAD
①demo例子
正常程序main.c:
#include <stdio.h>
#include <string.h>
int main(int argc, char *argv[])
{
if( strcmp(argv[1], "test") )
{
printf("Incorrect password\n");
}
else
{
printf("Correct password\n");
}
return 0;
}用于劫持函数的.so代码hook.c
#include <stdio.h>
#include <string.h>
#include <dlfcn.h>
/*
hook的目标是strcmp,所以typedef了一个STRCMP函数指针
hook的目的是要控制函数行为,从原库libc.so.6中拿到strcmp指针,保存成old_strcmp以备调用
*/
typedef int(*STRCMP)(const char*, const char*);
int strcmp(const char *s1, const char *s2)
{
static void *handle = NULL;
static STRCMP old_strcmp = NULL;
if( !handle )
{
handle = dlopen("libc.so.6", RTLD_LAZY);
old_strcmp = (STRCMP)dlsym(handle, "strcmp");
}
printf("oops!!! hack function invoked. s1=<%s> s2=<%s>\n", s1, s2);
return old_strcmp(s1, s2);
}编译:
gcc -o test main.c
gcc -fPIC -shared -o hook.so hook.c -ldl运行:
LD_PRELOAD=./hook.so ./test 123②hook function注意事项
在编写用于function hook的.so文件的时候,要考虑以下几个因素
1. Hook函数的覆盖完备性
对于Linux下的指令执行来说,有7个Glibc API都可是实现指令执行功能,对这些API对要进行Hook
/*
#include <unistd.h>
int execl(const char *pathname, const char *arg0, ... /* (char *)0 */ );
int execv(const char *pathname, char *const argv[]);
int execle(const char *pathname, const char *arg0, .../* (char *)0, char *const envp[] */ );
int execve(const char *pathname, char *const argv[], char *const envp[]);
int execlp(const char *filename, const char *arg0, ... /* (char *)0 */ );
int execvp(const char *filename, char *const argv[]);
int fexecve(int fd, char *const argv[], char *const envp[]);
http://www.2cto.com/os/201410/342362.html
*/
2. 当前系统中存在function hook的重名覆盖问题
1) /etc/ld.so.preload中填写了多条.so加载条目
2) 其他程序通过"export LD_PRELOAD=.."临时指定了待加载so的路径
在很多情况下,出于系统管理或者集群系统日志收集的目的,运维人员会向系统中注入.so文件,对特定function函数进行hook,这个时候,当我们注入的.so文件中的hook function和原有的hook function存在同名的情况,Linux会自动忽略之后载入了hook function,这种情况我们称之为"共享对象全局符号介入"
3. 注入.so对特定function函数进行hook要保持原始业务的兼容性
典型的hook的做法应该是
hook_function()
{
save ori_function_address;
/*
do something in here
span some time delay
*/
call ori_function;
}
hook函数在执行完自己的逻辑后,应该要及时调用被hook前的"原始函数",保持对原有业务逻辑的透明
4. 尽量减小hook函数对原有调用逻辑的延时
hook_function()
{
save ori_function_address;
/*
do something in here
span some time delay
*/
call ori_function;
}
hook这个操作是一定会对原有的代码调用执行逻辑产生延时的,我们需要尽量减少从函数入口到"call ori_function"这块的代码逻辑,让代码逻辑尽可能早的去"call ori_function"
在一些极端特殊的场景下,存在对单次API调用延时极其严格的情况,如果延时过长可能会导致原始业务逻辑代码执行失败如果需要不仅仅是替换掉原有库函数,而且还希望最终将函数逻辑传递到原有系统函数,实现透明hook(完成业务逻辑的同时不影响正常的系统行为)、维持调用链,那么需要用到RTLD_NEXT
当调用dlsym的时候传入RTLD_NEXT参数,gcc的共享库加载器会按照"装载顺序(load order)(即先来后到的顺序)"获取"下一个共享库"中的符号地址
/*
Specifies the next object after this one that defines name. This one refers to the object containing the invocation of dlsym(). The next object is the one found upon the application of a load order symbol resolution algorithm (see dlopen()). The next object is either one of global scope (because it was introduced as part of the original process image or because it was added with a dlopen() operation including the RTLD_GLOBAL flag), or is an object that was included in the same dlopen() operation that loaded this one.
The RTLD_NEXT flag is useful to navigate an intentionally created hierarchy of multiply-defined symbols created through interposition. For example, if a program wished to create an implementation of malloc() that embedded some statistics gathering about memory allocations, such an implementation could use the real malloc() definition to perform the memory allocation-and itself only embed the necessary logic to implement the statistics gathering function.
http://pubs.opengroup.org/onlinepubs/009695399/functions/dlsym.html
http://www.newsmth.net/nForum/#!article/KernelTech/413
*/code example
// used for getting the orginal exported function address
#if defined(RTLD_NEXT)
# define REAL_LIBC RTLD_NEXT
#else
# define REAL_LIBC ((void *) -1L)
#endif
//REAL_LIBC代表当前调用链中紧接着下一个共享库,从调用方链接映射列表中的下一个关联目标文件获取符号
#define FN(ptr,type,name,args) ptr = (type (*)args)dlsym (REAL_LIBC, name)
...
FN(func,int,"execve",(const char *, char **const, char **const));我们知道,如果当前进程空间中已经存在某个同名的符号,则后载入的so的同名函数符号会被忽略,但是不影响so的载入,先后载入的so会形成一个链式的依赖关系,通过RTLD_NEXT可以遍历
③SO功能代码编写
这个小节我们来完成一个基本的进程、网络、模块加载监控的小demo。
1. 指令执行
1) execve
2) execv
2. 网络连接
1) connect
3. LKM模块加载
1) init_modulehook.c
#include <stdio.h>
#include <string.h>
#include <dlfcn.h>
#include <stdlib.h>
#include <sys/types.h>
#include <string.h>
#include <unistd.h>
#include <limits.h>
#include <netinet/in.h>
#include <linux/ip.h>
#include <linux/tcp.h>
#if defined(RTLD_NEXT)
# define REAL_LIBC RTLD_NEXT
#else
# define REAL_LIBC ((void *) -1L)
#endif
#define FN(ptr, type, name, args) ptr = (type (*)args)dlsym (REAL_LIBC, name)
int execve(const char *filename, char *const argv[], char *const envp[])
{
static int (*func)(const char *, char **, char **);
FN(func,int,"execve",(const char *, char **const, char **const));
//print the log
printf("filename: %s, argv[0]: %s, envp:%s\n", filename, argv[0], envp);
return (*func) (filename, (char**) argv, (char **) envp);
}
int execv(const char *filename, char *const argv[])
{
static int (*func)(const char *, char **);
FN(func,int,"execv", (const char *, char **const));
//print the log
printf("filename: %s, argv[0]: %s\n", filename, argv[0]);
return (*func) (filename, (char **) argv);
}
int connect(int sockfd, const struct sockaddr *addr, socklen_t addrlen)
{
static int (*func)(int, const struct sockaddr *, socklen_t);
FN(func,int,"connect", (int, const struct sockaddr *, socklen_t));
/*
print the log
获取、打印参数信息的时候需要注意
1. 加锁
2. 拷贝到本地栈区变量中
3. 然后再打印
调试的时候发现直接获取打印会导致core dump
*/
printf("socket connect hooked!!\n");
//return (*func) (sockfd, (const struct sockaddr *) addr, (socklen_t)addrlen);
return (*func) (sockfd, addr, addrlen);
}
int init_module(void *module_image, unsigned long len, const char *param_values)
{
static int (*func)(void *, unsigned long, const char *);
FN(func,int,"init_module",(void *, unsigned long, const char *));
/*
print the log
lkm的加载不需要取参数,只需要捕获事件本身即可
*/
printf("lkm load hooked!!\n");
return (*func) ((void *)module_image, (unsigned long)len, (const char *)param_values);
}编译,并装载
//编译出一个so文件
gcc -fPIC -shared -o hook.so hook.c -ldl添加LD_PRELOAD有很多种方式
1. 临时一次性添加(当条指令有效)
LD_PRELOAD=./hook.so nc www.baidu.com 80
/*
LD_PRELOAD后面接的是具体的库文件全路径,可以连接多个路径
程序加载时,LD_PRELOAD加载路径优先级高于/etc/ld.so.preload
*/
2. 添加到环境变量LD_PRELOAD中(当前会话SESSION有效)
export LD_PRELOAD=/zhenghan/snoopylog/hook.so
//"/zhenghan/snoopylog/"是编译.so文件的目录
unset LD_PRELOAD
3. 添加到环境变量LD_LIBRARY_PATH中
假如现在需要在已有的环境变量上添加新的路径名,则采用如下方式
LD_LIBRARY_PATH=/zhenghan/snoopylog/hook.so:$LD_LIBRARY_PATH.(newdirs是新的路径串)
/*
LD_LIBRARY_PATH指定查找路径,这个路径优先级别高于系统预设的路径
*/
4. 添加到系统配置文件中
vim /etc/ld.so.preload
add /zhenghan/snoopylog/hook.so
5. 添加到配置文件目录中
cat /etc/ld.so.conf
//include ld.so.conf.d/*.conf效果测试
1. 指令执行
在代码中手动调用: execve(argv[1], newargv, newenviron);
2. 网络连接
执行: nc www.baidu.com 80
3. LKM模块加载
编写测试LKM模块,执行: insmod hello.ko在真实的环境中,socket的网络连接存在大量的连接失败,非阻塞等待等等情况,这些都会触发connect的hook调用,对于connect的hook来说,我们需要对以下的事情进行过滤
1. 区分IPv4、IPv6
根据connect参数中的(struct sockaddr *addr)->sa_family进行判断
2. 区分执行成功、执行失败
如果本次connect调用执行失败,则不应该继续进行参数获取
int ret_code = (*func) (sockfd, addr, addrlen);
int tmp_errno = errno;
if (ret_code == -1 && tmp_errno != EINPROGRESS)
{
return ret_code;
}
3. 区分TCP、UDP连接
对于TCP和UDP来说,它们都可以发起connect请求,我们需要从中过滤出TCP Connect请求
#include <sys/types.h>
#include <sys/socket.h>
int getsockopt(int sock, int level, int optname, void *optval, socklen_t *optlen);
int setsockopt(int sock, int level, int optname, const void *optval, socklen_t optlen);
/*
#include <sys/types.h>
#include <sys/socket.h>
main()
{
int s;
int optval;
int optlen = sizeof(int);
if((s = socket(AF_INET, SOCK_STREAM, 0)) < 0)
perror("socket");
getsockopt(s, SOL_SOCKET, SO_TYPE, &optval, &optlen);
printf("optval = %d\n", optval);
close(s);
}
*/
执行:
optval = 1 //SOCK_STREAM 的定义正是此值④劫持效果测试
指令执行监控
execve.c
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main(int argc, char *argv[])
{
char *newargv[] = { NULL, "hello", "world", NULL };
char *newenviron[] = { NULL };
if (argc != 2)
{
fprintf(stderr, "Usage: %s <file-to-exec>\n", argv[0]);
exit(EXIT_FAILURE);
}
newargv[0] = argv[1];
execve(argv[1], newargv, newenviron);
perror("execve"); /* execve() only returns on error */
exit(EXIT_FAILURE);
}
//gcc -o execve execve.cmyecho.c
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char *argv[])
{
int j;
for (j = 0; j < argc; j++)
printf("argv[%d]: %s\n", j, argv[j]);
exit(EXIT_SUCCESS);
}
//gcc -o myecho myecho.c
可以看到,LD_PRELOAD在所有程序代码库加载前优先加载,对glibc中的导出函数进行了hook
网络连接监控

模块加载监控:hello.c
#include <linux/module.h> // included for all kernel modules
#include <linux/kernel.h> // included for KERN_INFO
#include <linux/init.h> // included for __init and __exit macros
#include <linux/cred.h>
#include <linux/sched.h>
static int __init hello_init(void)
{
struct cred *currentCred;
currentCred = current->cred;
printk(KERN_INFO "uid = %d\n", currentCred->uid);
printk(KERN_INFO "gid = %d\n", currentCred->gid);
printk(KERN_INFO "suid = %d\n", currentCred->suid);
printk(KERN_INFO "sgid = %d\n", currentCred->sgid);
printk(KERN_INFO "euid = %d\n", currentCred->euid);
printk(KERN_INFO "egid = %d\n", currentCred->egid);
printk(KERN_INFO "Hello world!\n");
return 0; // Non-zero return means that the module couldn't be loaded.
}
static void __exit hello_cleanup(void)
{
printk(KERN_INFO "Cleaning up module.\n");
}
module_init(hello_init);
module_exit(hello_cleanup);Makefile
obj-m := hello.o
KDIR := /lib/modules/$(shell uname -r)/build
PWD := $(shell pwd)
all:
$(MAKE) -C $(KDIR) M=$(PWD) modules
clean:
$(MAKE) -C $(KDIR) M=$(PWD) clean加载模块:insmod hello.ko

使用snoopy进行execve/execv、connect、init_module hook
snoopy会监控服务器上的命令执行,并记录到syslog。
本质上,snoopy是利用ld_preload技术实现so依赖劫持的,只是它的工程化完善度更高,日志采集和日志整理传输这方面已经帮助我们完成了。
#cat /etc/ld.so.preload
/usr/local/snoopy/lib/snoopy.so基于PD_PRELOAD、LD_LIBRARY_PATH环境变量劫持绕过Hook模块
我们知道,snoopy监控服务器上的指令执行,是通过修改系统的共享库预加载配置文件(/etc/ld.so.preload)实现,但是这种方式存在一个被黑客绕过的可能
LD_PRELOAD的加载顺序优先于/etc/ld.so.preload的配置项,黑客可以利用这点来强制覆盖共享库的加载顺序
1. 强制指定LD_PRELOAD的环境变量
export LD_PRELOAD=/lib64/libc.so.6
bash
/*
新启动的bash终端默认会使用LD_PRELOAD的共享库路径
*/
2. LD_PRELOAD="/lib64/libc.so.6" bash
/*
重新开启一个加载了默认libc.so.6共享库的bash session
因为对于libc.so.6来说,它没有使用dlsym去动态获取API Function调用链条的RTL_NEXT函数,即调用链是断开的
*/在这个新的Bash下执行的指令,因为都不会调用到snoopy的hook函数,所以也不会被记录下来。
基于ptrace()调试技术进行API Hook
在Linux下,除了使用LD_PRELOAD这种被动Glibc API注入方式,还可以使用基于调试器(Debuger)思想的ptrace()主动注入方式,总体思路如下:
-
使用Linux Module、或者LSM挂载点对进程的启动动作进行实时的监控,并通过Ring0-Ring3通信,通知到Ring3程序有新进程启动的动作
-
用ptrace函数attach上目标进程
-
让目标进程的执行流程跳转到mmap函数来分配一小段内存空间
-
把一段机器码拷贝到目标进程中刚分配的内存中去
-
最后让目标进程的执行流程跳转到注入的代码执行
通过静态编码绕过LD_PRELOAD机制监控
通过静态链接方式编译so模块:
gcc -o test test.c -static在静态链接的模式下,程序不会去搜索系统中的so文件(不同是系统默认的、还是第三方加入的),所以也就不会调用到Hook SO模块。
通过内联汇编的方式绕过LD_PRELOAD机制监控
使用内嵌汇编的形式直接通过syscall指令使用系统调用功能,同样也不会调用到Glibc提供的API。
asm("movq $2, %%rax\n\t syscal:"=a"(ret));2.2Ring0中Hook技术
传统的kernel inline hook技术就是修改内核函数的opcode,通过写入jmp或push ret等指令跳转到新的内核函数中,从何达到劫持的目的。
-
我们知道实现一个系统调用的函数中一定会递归的嵌套有很多的子函数,即它必定要调用它的下层函数。
-
从汇编的角度来说,对一个子函数的调用是采用"段内相对短跳转 jmp offset"来实现的,即CPU根据offset来进行一个偏移量的跳转。如果我们把下层函数在上层函数中的offset替换成我们"Hook函数"的offset,这样上层函数调用下层函数时,就会跳到我们的"Hook函数"中。
-
我们就可以在"Hook函数"中做过滤和劫持内容的工作
以sys_read作为例子:
\linux-2.6.32.63\fs\read_write.c
asmlinkage ssize_t sys_read(unsigned int fd, char __user * buf, size_t count)
{
struct file *file;
ssize_t ret = -EBADF;
int fput_needed;
file = fget_light(fd, &fput_needed);
if (file)
{
loff_t pos = file_pos_read(file);
ret = vfs_read(file, buf, count, &pos);
file_pos_write(file, pos);
fput_light(file, fput_needed);
}
return ret;
}
EXPORT_SYMBOL_GPL(sys_read);在sys_read()中,调用了子函数vfs_read()来完成读取数据的操作,在sys_read()中调用子函数vfs_read()的汇编命令是:
call 0xc106d75c <vfs_read>等同于:
jmp offset(相对于sys_read()的基址偏移)所以,我们的思路很明确,找到call 0xc106d75c <vfs_read>这条汇编,把其中的offset改成我们的Hook函数对应的offset,就可以实现劫持目的了
1. 搜索sys_read的opcode 2. 如果发现是call指令,根据call后面的offset计算要跳转的地址是不是我们要hook的函数地址 1) 如果"不是"就重新计算Hook函数的offset,用Hook函数的offset替换原来的offset 2) 如果"已经是"Hook函数的offset,则说明函数已经处于被劫持状态了,我们的Hook引擎应该直接忽略跳过,避免重复劫持
poc:
/*
参数:
1. handler是上层函数的地址,这里就是sys_read的地址
2. old_func是要替换的函数地址,这里就是vfs_read
3. new_func是新函数的地址,这里就是new_vfs_read的地址
*/
unsigned int patch_kernel_func(unsigned int handler, unsigned int old_func,
unsigned int new_func)
{
unsigned char *p = (unsigned char *)handler;
unsigned char buf[4] = "\x00\x00\x00\x00";
unsigned int offset = 0;
unsigned int orig = 0;
int i = 0;
DbgPrint("\n*** hook engine: start patch func at: 0x%08x\n", old_func);
while (1) {
if (i > 512)
return 0;
if (p[0] == 0xe8) {
DbgPrint("*** hook engine: found opcode 0x%02x\n", p[0]);
DbgPrint("*** hook engine: call addr: 0x%08x\n",
(unsigned int)p);
buf[0] = p[1];
buf[1] = p[2];
buf[2] = p[3];
buf[3] = p[4];
DbgPrint("*** hook engine: 0x%02x 0x%02x 0x%02x 0x%02x\n",
p[1], p[2], p[3], p[4]);
offset = *(unsigned int *)buf;
DbgPrint("*** hook engine: offset: 0x%08x\n", offset);
orig = offset + (unsigned int)p + 5;
DbgPrint("*** hook engine: original func: 0x%08x\n", orig);
if (orig == old_func) {
DbgPrint("*** hook engine: found old func at"
" 0x%08x\n",
old_func);
DbgPrint("%d\n", i);
break;
}
}
p++;
i++;
}
offset = new_func - (unsigned int)p - 5;
DbgPrint("*** hook engine: new func offset: 0x%08x\n", offset);
p[1] = (offset & 0x000000ff);
p[2] = (offset & 0x0000ff00) >> 8;
p[3] = (offset & 0x00ff0000) >> 16;
p[4] = (offset & 0xff000000) >> 24;
DbgPrint("*** hook engine: pachted new func offset.\n");
return orig;
}对于这类劫持攻击,目前常见的做法是fireeye的"函数返回地址污点检测",通过对原有指令返回位置的汇编代码作污点标记,通过查找jmp,push ret等指令来进行防御。
⑴利用0x80中断劫持system_call->sys_call_table进行系统调用Hook
我们知道,要对系统调用(sys_call_table)进行替换,却必须要获取该地址后才可以进行替换。但是Linux 2.6版的内核出于安全的考虑没有将系统调用列表基地址的符号sys_call_table导出,但是我们可以采取一些hacking的方式进行获取。
因为系统调用都是通过0x80中断来进行的,故可以通过查找0x80中断的处理程序来获得sys_call_table的地址。其基本步骤是
1. 获取中断描述符表(IDT)的地址(使用C ASM汇编) 2. 从中查找0x80中断(系统调用中断)的服务例程(8*0x80偏移) 3. 搜索该例程的内存空间, 4. 从其中获取sys_call_table(保存所有系统调用例程的入口地址)的地址
编程示例
find_sys_call_table.c
#include <linux/module.h>
#include <linux/kernel.h>
// 中断描述符表寄存器结构
struct
{
unsigned short limit;
unsigned int base;
} __attribute__((packed)) idtr;
// 中断描述符表结构
struct
{
unsigned short off1;
unsigned short sel;
unsigned char none, flags;
unsigned short off2;
} __attribute__((packed)) idt;
// 查找sys_call_table的地址
void disp_sys_call_table(void)
{
unsigned int sys_call_off;
unsigned int sys_call_table;
char* p;
int i;
// 获取中断描述符表寄存器的地址
asm("sidt %0":"=m"(idtr));
printk("addr of idtr: %x\n", &idtr);
// 获取0x80中断处理程序的地址
memcpy(&idt, idtr.base+8*0x80, sizeof(idt));
sys_call_off=((idt.off2<<16)|idt.off1);
printk("addr of idt 0x80: %x\n", sys_call_off);
// 从0x80中断服务例程中搜索sys_call_table的地址
p=sys_call_off;
for (i=0; i<100; i++)
{
if (p=='\xff' && p[i+1]=='\x14' && p[i+2]=='\x85')
{
sys_call_table=*(unsigned int*)(p+i+3);
printk("addr of sys_call_table: %x\n", sys_call_table);
return ;
}
}
}
// 模块载入时被调用
static int __init init_get_sys_call_table(void)
{
disp_sys_call_table();
return 0;
}
module_init(init_get_sys_call_table);
// 模块卸载时被调用
static void __exit exit_get_sys_call_table(void)
{
}
module_exit(exit_get_sys_call_table);
// 模块信息
MODULE_LICENSE("GPL2.0");
MODULE_AUTHOR("LittleHann");Makefile
obj-m := find_sys_call_table.o编译
make -C /usr/src/kernels/2.6.32-358.el6.i686 M=$(pwd) modules测试效果
dmesg| tail

获取到了sys_call_table的基地址之后,我们就可以修改指定offset对应的系统调用了,从而达到劫持系统调用的目的。
⑵获取sys_call_table的常用方法
①通过dump获取绝对地址
模拟出一个call *sys_call_table(,%eax,4),然后看其机器码,然后在system_call的附近基于这个特征进行寻找
#include <stdio.h>
void fun1()
{
printf("fun1/n");
}
void fun2()
{
printf("fun2/n");
}
unsigned int sys_call_table[2] = {fun1, fun2};
int main(int argc, char **argv)
{
asm("call *sys_call_table(%eax,4");
}
编译
gcc test.c -o test
objdump进行dump
objdump -D ./test | grep sys_call_table②通过/boot/System.map-2.6.32-358.el6.i686文件查找
cd /boot
grep sys_call_table System.map-2.6.32-358.el6.i686③通过读取/dev/kmem虚拟内存全镜像设备文件获得sys_call_table地址
Linux下/dev/mem和/dev/kmem的区别:
/dev/mem: 物理内存的全镜像。可以用来访问物理内存。比如: 1) X用来访问显卡的物理内存, 2) 嵌入式中访问GPIO。用法一般就是open,然后mmap,接着可以使用map之后的地址来访问物理内存。这其实就是实现用户空间驱动的一种方法。2. /dev/kmem: kernel看到的虚拟内存的全镜像。可以用来: 1) 访问kernel的内容,查看kernel的变量, 2) 用作rootkit之类的
code
#include <stdio.h>
#include <sys/types.h>
#include <fcntl.h>
#include <stdlib.h>
int kfd;
struct
{
unsigned short limit;
unsigned int base;
} __attribute__ ((packed)) idtr;
struct
{
unsigned short off1;
unsigned short sel;
unsigned char none, flags;
unsigned short off2;
} __attribute__ ((packed)) idt;
int readkmem (unsigned char *mem, unsigned off, int bytes)
{
if (lseek64 (kfd, (unsigned long long) off, SEEK_SET) != off)
{
return -1;
}
if (read (kfd, mem, bytes) != bytes)
{
return -1;
}
}
int main (void)
{
unsigned long sct_off;
unsigned long sct;
unsigned char *p, code[255];
int i;
/* request IDT and fill struct */
asm ("sidt %0":"=m" (idtr));
if ((kfd = open ("/dev/kmem", O_RDONLY)) == -1)
{
perror("open");
exit(-1);
}
if (readkmem ((unsigned char *)&idt, idtr.base + 8 * 0x80, sizeof (idt)) == -1)
{
printf("Failed to read from /dev/kmem\n");
exit(-1);
}
sct_off = (idt.off2 << 16) | idt.off1;
if (readkmem (code, sct_off, 0x100) == -1)
{
printf("Failed to read from /dev/kmem\n");
exit(-1);
}
/* find the code sequence that calls SCT */
sct = 0;
for (i = 0; i < 255; i++)
{
if (code[i] == 0xff && code[i+1] == 0x14 && code[i+2] == 0x85)
{
sct = code[i+3] + (code[i+4] << 8) + (code[i+5] << 16) + (code[i+6] << 24);
}
}
if (sct)
{
printf ("sys_call_table: 0x%x\n", sct);
}
close (kfd);
}④通过函数特征码循环搜索获取sys_call_table地址 (64 bit)
unsigned long **find_sys_call_table()
{
unsigned long ptr;
unsigned long *p;
for (ptr = (unsigned long)sys_close; ptr < (unsigned long)&loops_per_jiffy; ptr += sizeof(void *))
{
p = (unsigned long *)ptr;
if (p[__NR_close] == (unsigned long)sys_close)
{
printk(KERN_DEBUG "Found the sys_call_table!!!\n");
return (unsigned long **)p;
}
}
return NULL;
}要特别注意的是代码中进行函数地址搜索的代码:if (p[__NR_close] == (unsigned long)sys_close)
在64bit Linux下,函数的地址是8字节的,所以要使用unsigned long
我们可以在linux下执行以下两条指令
grep sys_close System.map-2.6.32-358.el6.i686
grep loops_per_jiffy System.map-2.6.32-358.el6.i686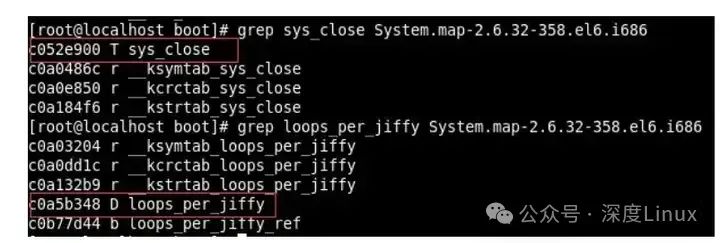
可以看到,系统调用表sys_call_table中的函数地址都落在这个地址区间中,因此我们可以使用loop搜索的方法去获取sys_call_table的基地址
⑶通过kprobe方式动态获取kallsyms_lookup_name,然后利用kallsyms_lookup_name获取sys_call_table的地址
通过kprobe的函数hook挂钩机制,可以获取内核中任意函数的入口地址,我们可以先获取"kallsyms_lookup_name"函数的入口地址
//get symbol name by "kprobe.addr"
//when register a kprobe on succefully return,the structure of kprobe save the symbol address at "kprobe.addr"
//just return this value
static void* aquire_symbol_by_kprobe(char* symbol_name)
{
void *symbol_addr=NULL;
struct kprobe kp;
do
{
memset(&kp,0,sizeof(kp));
kp.symbol_name=symbol_name;
kp.pre_handler=kprobe_pre;
if(register_kprobe(&kp)!=0)
{
break;
}
//this is the address of "symbol_name"
symbol_addr=(void*)kp.addr;
//now kprobe is not used any more,so unregister it
unregister_kprobe(&kp);
}while(false);
return symbol_addr;
}
//调用之
tmp_lookup_func = aquire_symbol_by_kprobe("kallsyms_lookup_name");kallsyms_lookup_name()可以用于获取内核导出符号表中的符号地址,而sys_call_table的地址也存在于内核导出符号表中,我们可以使用kallsyms_lookup_name()获取到sys_call_table的基地址
(void**)kallsyms_lookup_name("sys_call_table");⑷利用Linux内核机制kprobe机制(kprobes, jprobe和kretprobe)进行系统调用Hook
kprobe是一个动态地收集调试和性能信息的工具,它从Dprobe项目派生而来,它几乎可以跟踪任何函数或被执行的指令以及一些异步事件。它的基本工作机制是:
-
1. 用户指定一个探测点,并把一个用户定义的处理函数关联到该探测点
-
2. 在注册探测点的时候,对被探测函数的指令码进行替换,替换为int 3的指令码
-
3. 在执行int 3的异常执行中,通过通知链的方式调用kprobe的异常处理函数
-
4. 在kprobe的异常出来函数中,判断是否存在pre_handler钩子,存在则执行
-
5. 执行完后,准备进入单步调试,通过设置EFLAGS中的TF标志位,并且把异常返回的地址修改为保存的原指令
-
6. 代码返回,执行原有指令,执行结束后触发单步异常 7. 在单步异常的处理中,清除单步标志,执行post_handler流程,并最终返回
从原理上来说,kprobe的这种机制属于系统提供的"回调订阅",和netfilter是类似的,linux内核通过在某些代码执行流程中给出回调函数接口供程序员订阅,内核开发人员可以在这些回调点上注册(订阅)自定义的处理函数,同时还可以获取到相应的状态信息,方便进行过滤、分析
kprobe实现了三种类型的探测点:
-
1. kprobes kprobes是可以被插入到内核的任何指令位置的探测点,kprobe允许在同一地址注册多个kprobes,但是不能同时在该地址上有多个jprobes
-
2. jprobe jprobe则只能被插入到一个内核函数的入口
-
3. kretprobe(也叫返回探测点) 而kretprobe则是在指定的内核函数返回时才被执行
在本文中,我们可以使用kprobe的程序实现作一个内核模块,模块的初始化函数来负责安装探测点,退出函数卸载那些被安装的探测点。kprobe提供了接口函数(APIs)来安装或卸载探测点。目前kprobe支持如下架构:i386、x86_64、ppc64、ia64(不支持对slot1指令的探测)、sparc64 (返回探测还没有实现)
三、Linux系统调用中常见的Hook技术方法
3.1基于函数指针的 Hook
在 Linux 内核中,系统调用函数的入口地址存储在系统调用表中,这个表实际上是一个函数指针数组。基于函数指针的 Hook 方法就是直接修改系统调用表中对应函数的指针,使其指向我们自定义的 Hook 函数。
实现步骤:首先需要找到系统调用表的地址,这在不同的内核版本和架构上可能有所不同。然后,通过修改内存中的函数指针,将其指向自定义的 Hook 函数。在 Hook 函数中,可以先执行自己的逻辑,然后再调用原来的系统调用函数(如果需要的话)。
示例代码(简化示意):
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/syscalls.h>
// 保存原来的系统调用函数指针
asmlinkage long (*original_sys_open)(const char __user *, int, umode_t);
// 自定义的Hook函数
asmlinkage long my_sys_open(const char __user *filename, int flags, umode_t mode) {
printk(KERN_INFO "MyHook: Opening file: %s\n", filename);
// 调用原来的系统调用函数
return original_sys_open(filename, flags, mode);
}
static int __init my_init(void) {
// 获取系统调用表地址
unsigned long *sys_call_table = (unsigned long *)sys_call_table;
// 保存原来的系统调用函数指针
original_sys_open = (void *)sys_call_table[__NR_open];
// 修改系统调用表中的函数指针
sys_call_table[__NR_open] = (unsigned long)my_sys_open;
return 0;
}
static void __exit my_exit(void) {
// 恢复原来的系统调用函数指针
unsigned long *sys_call_table = (unsigned long *)sys_call_table;
sys_call_table[__NR_open] = (unsigned long)original_sys_open;
}
module_init(my_init);
module_exit(my_exit);
MODULE_LICENSE("GPL");优点与局限性:这种方法简单直接,效果显著。但是,由于直接修改系统调用表,可能会导致内核的稳定性问题,并且在不同的内核版本之间移植性较差,因为系统调用表的结构和地址可能会发生变化。
3.2基于 GOT(Global Offset Table)的 Hook
在用户空间的动态链接库中,GOT 是一个重要的数据结构,用于存储外部函数的地址。基于 GOT 的 Hook 方法主要应用于用户空间的程序,通过修改 GOT 表中函数的地址,实现对系统调用的 Hook。
实现步骤:首先需要找到目标函数在 GOT 表中的项,然后修改该项的内容,使其指向自定义的 Hook 函数。在 Hook 函数中,可以进行自己的逻辑处理,最后再通过调用原来的函数地址(保存在一个临时变量中)来执行原函数的功能。
示例代码(以 C 语言和动态链接库为例):
#include <stdio.h>
#include <stdlib.h>
#include <dlfcn.h>
// 自定义的Hook函数
int my_open(const char *pathname, int flags, mode_t mode) {
printf("MyHook: Opening file: %s\n", pathname);
// 获取原来的open函数指针
int (*original_open)(const char *, int, mode_t) = dlsym(RTLD_NEXT, "open");
// 调用原来的open函数
return original_open(pathname, flags, mode);
}
// 通过环境变量LD_PRELOAD加载这个库时,会优先使用这个函数
__attribute__((constructor)) void my_init(void) {
void *handle = dlopen(NULL, RTLD_NOW);
if (!handle) {
fprintf(stderr, "Error opening library: %s\n", dlerror());
exit(EXIT_FAILURE);
}
// 使用dlsym获取原来的open函数指针(这里只是示例,实际可能需要更复杂的处理)
int (*original_open)(const char *, int, mode_t) = dlsym(handle, "open");
if (!original_open) {
fprintf(stderr, "Error getting original open function: %s\n", dlerror());
dlclose(handle);
exit(EXIT_FAILURE);
}
// 这里可以通过一些技巧修改GOT表中open函数的地址,使其指向my_open函数
// 具体实现因不同系统和编译器而异,此处简化示意
}优点与局限性:这种方法主要在用户空间操作,对内核的影响较小,相对安全稳定。而且,它可以针对特定的用户程序进行 Hook,具有较好的灵活性。但是,它只能 Hook 用户空间调用的系统调用函数,对于内核内部直接调用的系统调用则无法生效。
3.3基于内核模块的 Kprobes Hook
Kprobes 是 Linux 内核提供的一种动态探测机制,它允许开发者在不修改内核源代码的情况下,对内核函数的执行进行探测和干预。基于 Kprobes 的 Hook 技术就是利用这一机制来实现对系统调用的 Hook。
实现步骤:首先需要注册一个 Kprobe 结构体,指定要 Hook 的内核函数以及在函数执行前、执行后和发生异常时的回调函数。然后,通过内核提供的函数将 Kprobe 注册到内核中。在回调函数中,可以编写自己的 Hook 逻辑。
示例代码(简化示意):
#include <linux/module.h>
#include <linux/kprobes.h>
// 定义一个Kprobe结构体
static struct kprobe my_kprobe = {
.symbol_name = "__x64_sys_open", // 要Hook的系统调用函数名
};
// 函数执行前的回调函数
static int pre_handler(struct kprobe *p, struct pt_regs *regs) {
printk(KERN_INFO "MyHook: Before open system call\n");
return 0;
}
// 函数执行后的回调函数
static void post_handler(struct kprobe *p, struct pt_regs *regs, unsigned long flags) {
printk(KERN_INFO "MyHook: After open system call\n");
}
// 发生异常时的回调函数
static void fault_handler(struct kprobe *p, struct pt_regs *regs, int trapnr) {
printk(KERN_INFO "MyHook: Fault in open system call\n");
}
static int __init my_init(void) {
// 设置回调函数
my_kprobe.pre_handler = pre_handler;
my_kprobe.post_handler = post_handler;
my_kprobe.fault_handler = fault_handler;
// 注册Kprobe
if (register_kprobe(&my_kprobe) < 0) {
printk(KERN_INFO "Failed to register kprobe\n");
return -1;
}
return 0;
}
static void __exit my_exit(void) {
// 注销Kprobe
unregister_kprobe(&my_kprobe);
printk(KERN_INFO "Kprobe unregistered\n");
}
module_init(my_init);
module_exit(my_exit);
MODULE_LICENSE("GPL");优点与局限性:Kprobes Hook 技术功能强大,能够深入内核内部进行 Hook 操作,并且对内核的影响相对较小,因为它是一种动态探测机制,不需要修改内核的静态代码。然而,它的实现相对复杂,需要对内核机制有较深入的理解,并且在使用不当的情况下,可能会对内核性能产生一定的影响。
四、Hook技术挑战与应对
4.1内核稳定性问题
无论是直接修改系统调用表还是使用 Kprobes 等技术,都可能对内核的稳定性造成潜在威胁。一旦 Hook 代码出现错误,可能导致内核崩溃或者出现不可预测的行为。
应对方法:在编写 Hook 代码时,要进行严格的测试和调试,确保代码的正确性和稳定性。同时,可以采用一些安全机制,如对修改的内存区域进行备份,以便在出现问题时能够快速恢复。
4.2兼容性问题
不同的 Linux 内核版本和架构在系统调用表结构、函数命名等方面可能存在差异,这给 Hook 技术的跨版本和跨架构应用带来了困难。
应对方法:在编写 Hook 代码时,要充分考虑内核版本和架构的兼容性。可以通过宏定义等方式,根据不同的内核版本和架构进行不同的代码处理。同时,关注内核的更新和变化,及时调整 Hook 代码。
4.3安全风险
Hook 技术如果被恶意利用,可能会对系统安全造成严重威胁。例如,恶意软件可以通过 Hook 关键系统调用,隐藏自己的行为或者获取敏感信息。
应对方法:加强系统的安全防护,使用安全检测工具及时发现和阻止恶意的 Hook 行为。同时,对于合法的 Hook 应用,要进行严格的权限管理和审计,确保 Hook 技术的使用是安全可靠的。