标题:A model-based gait recognition method with body pose and human prior knowledge
概要
作者提出了一个新的基于模型的步态识别方法,PoseGait。步态识别是生物特征识别中一个比较有挑战且有吸引力的领域。之前的一些方法主要基于外形,而基于外形的特征通常从人的体形中提取,很容易倍计算且比较高效。然而由于很多因素,外形一般不是不变的。一个基于体形方法的替代是基于模型的方法。然而,在低分辨率下比较困难。相对于之前的方法,作者使用人体3D姿态估计作为步态识别的输入。人体3D坐标对于很多外部因素的改变是不变的。作者设计了一个3D姿态的时空特征来提高识别率。作者的方法在两个大型数据集上进行验证。实验结果也表现出了良好的鲁棒性与SOTA。
1、介绍
行走风格作为一个人的特征,可以用于识别一个人。相比如其他生物特征,例如指纹、人脸、虹膜和掌纹,步态有例如非接触、难以造价和适合长距离识别等特点。步态识别算法在过去几十年也越来越鲁棒,并且在现实世界有了很多的应用。
步态是一种行为生物识别特征,不像例如指纹、虹膜和人脸等物理生物特征那样鲁棒。当有些改变时,例如衣着、携带的东西,步态特征就会剧烈的改变,一些之前的工作尝试去建模人体并且捕捉在不同主题下的运动模式。使用人体部分运动思想是直观且合理的。但是准确地定位和追踪身体区域是很困难的。
在过去的几十年,基于外貌的步态识别方法比基于模型的更加流行,基于外貌的方法通常使用人体外形作为生输入,这些方法在外貌没有明显改变时可以实现非常高的识别率。然而,真实世界中人外观的改变可能会很巨大导致这个方法的表现变差。经过对比,基于模型特征的方法基于人体结构和运动,所以对于人体的外形没有那么敏感。最近在姿态估计方面的进展为基于模型的方法带来了希望。基于模型的特征通常从人体结构中提取,所以他们可能处理很多种变化,尤其是视角的变化。
作者提出了一个新颖的基于模型的自该估计方法,PoseGait,能够提取人的姿态作为特征。作者通过实验印证了能与基于外貌特征相关的准确率,然而能够对外界因素的改变有更好的鲁棒性。该工作的主要贡献如下:
- 作者提出了一个新颖的基于模型的步态识别方法,能够提取人的姿态作为特征。这个方法可以首先即使在低分辨率下的高准确率。
- 作者基于3D姿态信息设计了特征,具有足够的优势。
- CNN和RNN/LSTM能够通过两种loss的融合成功提取时空步态特征
2、相关工作
基于外貌的方法
基于姿态估计的方法
3、PoseGait
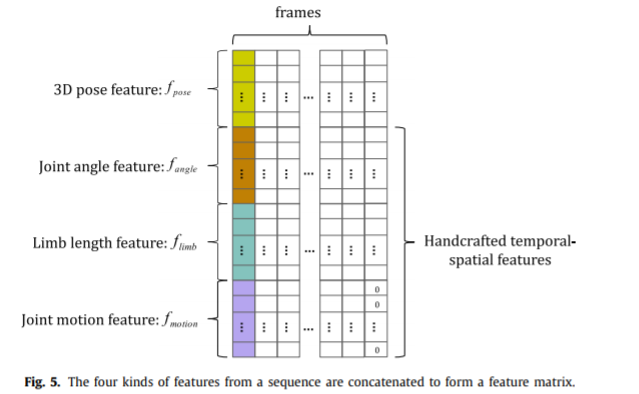
作者提出的方法以3D人体关节点作为输入,能够有效应对角度改变。相比于很多基于外貌的特征,例如GEI,本文使用的方法是低维的方法,只是用一些关节位置点。为了抽取时间特征,作者从一系列的帧中抽取特征。根据之前的一些工作,运动模式和角度对人体识别十分重要。在本文的工作中,作者基于先验知识设计了一些特征来提高特征提取的效率。作者将四种四种合并了起来,具体将在后面进行介绍。训练过程中,作者设计了两种loss来降低类内差异并增加类间差异。整个方法的框架如上图。
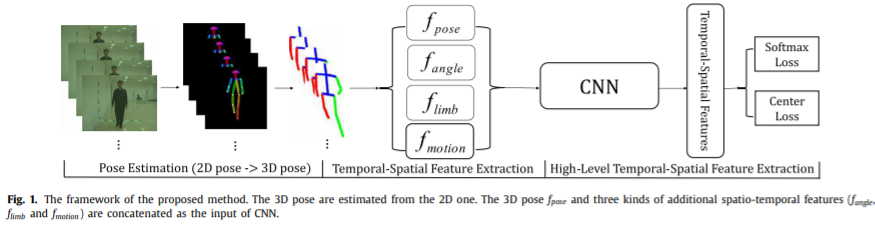
Human body pose features
为了降低携带东西以及衣物变化造成的影响,作者提出了一种姿态特征。在之前的方法中,关节运动对识别不同物体有足够的能力。但是自动化精确的识别却有很大的挑战。作者提出的方法使用OpenPose进行姿态估计,包括18个身体关节点。
图像的大小根据目标与相机之间的距离调整,脖子到臀部的距离被记为单元长度。然后身体关节坐标便可以通过下面的方式归一化:
这里的Hnh就是脖子到臀部的距离。
这样提取出的姿态是2D的,对于视角变化不够鲁棒。解决方法是估计3D的姿态。3D hunman pose estimation = 2D pose estimation + matching这篇文章中的方法使之成为了可能。这个方法中的输入是14个点,而OpenPose估计出来的方法是14个点,所以作者将脸部的一些特征平均了一下。
为了降低视角变化的影响,作者将x方法设置为前进方向,y方向为左右肩定义的方向,z方向是垂直于地面的方向。这个3D姿态经过了旋转和归一化。
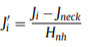


Designing spatio-temporal features
有的3D姿态估计以后,下一步就是基于3D姿态设计一些特征,例如关节角度、运动。基于先验知识的特征会有利于神经网络的学习。参考论文21中有类似的方法,包括静态姿态、运动和offset来提高动作识别的的效果。受到了这种方法的启发,作者设计了三种额外的时空姿态特征。分别是关节角度、肢体长度和关节运动。
关节角度
Wang等人提出的一种基于模型的方法使用关节角度和关节轨迹来捕捉人体的动态特征。相比于这个方法,作者的方法认为3D关节位置更加精确,不只是下肢,全部的特征都可以被捕捉到。
角度被定义为两个关节点之间,包括{(1,0), (1,2), (2,3), (3,4), (1,5), (5,6), (6,7), (1,8), (8,9), (9,10),
(1,11), (11,12), (12, 13)},其中α和β被定义为左肩和左肘之间。
肢体长度
肢体长度为两个相邻的关节之间的距离,可以看做一个基于模型的空间特征。
关节运动
行走风格可以通过关节运动描述。论文22中提出了一种FDEI特征,使用帧之间的区别来捕捉动态信息。FDEI是人体轮廓之间的差异,这里作者使用的是人体关节之间的差异。
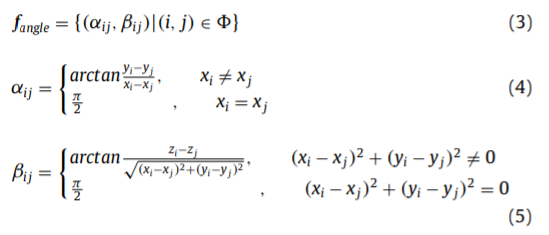

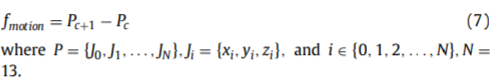
Fusion of features
对于每一帧,可以得到四种特征,可以合成一个向量。然后不同帧的特征向量可以形成一个特征矩阵。其中运动特征比其他特征少一个,作者设置了一个0向量使之完整。由于输入特征有一个固定的尺寸,可以直接作为CNN模型的输入。
The network design
由于特征是逐帧的,所以很容易想到用RNN和LSTM。之前的工作作者提出了把CNN和LSTM合并的PTSN,但是有些研究者认为CNN比RNN的特征提取能力更强。相比于CNN,RNN的计算难度更大。有的研究者也证明了CNN有足够的能力来处理时序数据,所以作者使用了CNN或LSTM。
对于步态识别任务,降低类内差异和扩大类间差异是很重要的。根据一些工作的建议,作者使用了多loss策略来提升网络效果。一共设计了两个loss,分别是softmax loss和center loss。前者用来把扩大类间差异,后者通过最小化类内变化来保持不同类特征的可分离性。

4、实验结果与分析
数据集
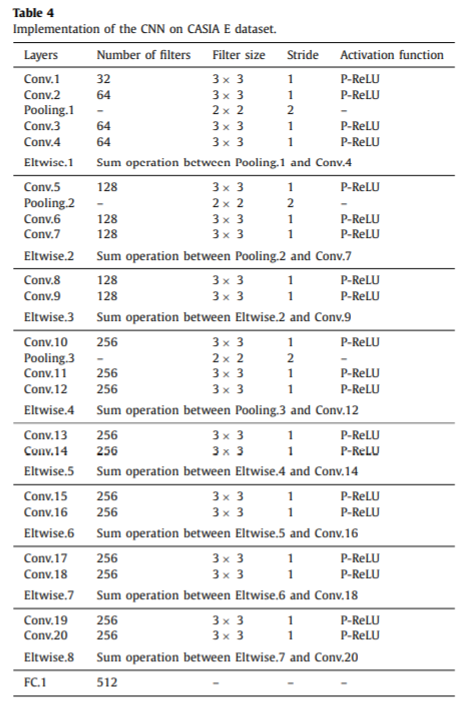
为了评估给出的姿态识别方法,需要RGB的视频帧,因为人体的姿态估计需要根据彩色图像而不能根据轮廓。作者选择了CASIA B步态数据库,因为它包括原始的彩色视频帧。OU-ISIR研究组提供了几个比较大的姿态数据库,但是因为隐私问题不能提供原始的视频帧,所以作者选择了CASIA E作为第二个数据集。
CASIA B是一个著名的公开步态数据集,广泛被研究者们使用。一共包括124个对象(31个女性和93个男性)。每个对象有10个序列,6个序列为正常行走,两个为背着包,还有两个为穿着大衣。然后还有从11个相机同时拍摄的11个视角,角度为{0◦, 18◦, , 180◦}。
CASIA E是一个新提出的步态数据集。包括1014个对象,比CASIA B大很多。不同于其他超过一千个个体的步态数据集,该步态数据从13个角度收集,从0度到180度以15度为间隔。其中每个对象有6个序列,两个正常行走,两个背着包,两个穿着大衣。
如果CASIA B用这个因为数据太少会过拟合。


实验设置
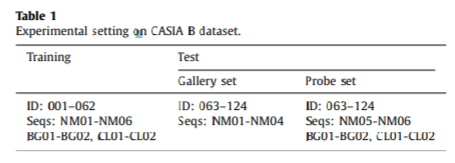
第一组实验在CASIA B上进行,其中前62个作为训练集,其他的作为测试集,与SPAE 和
GaitGAN的配置一样。正常行走的作为gallery set,其他的作为probe set。(gallery set为记录进系统的特征,而probe set用于测试与系统中的步态特征是否匹配)
CASIA E数据集的配置与CASIA B类似。其中前507个用作训练集,后面的507为测试集。测试中有两类配置,正常行走的使用相应的视角。由于正常行走每类共有两个,作者将第一个作为gallery,第二个作为probe。第二种配置,前两个正常行走的作为gallery,其他的作为probe。
Experimental results on CASIA B dataset
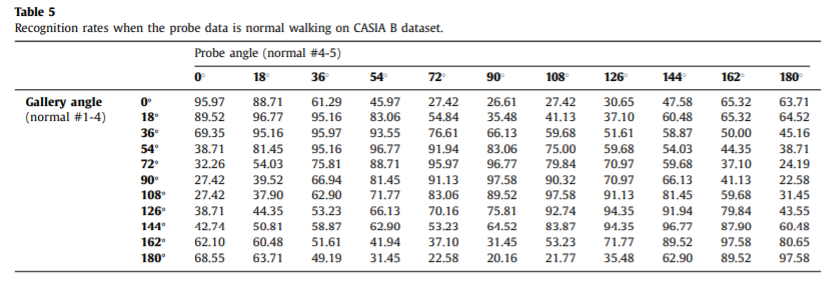
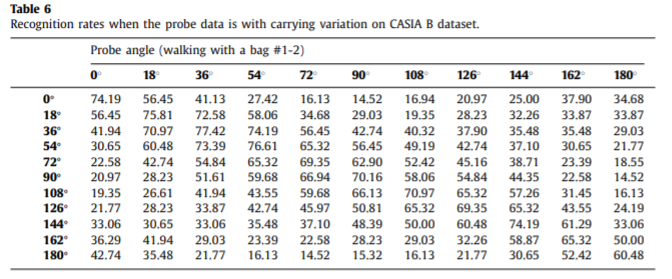
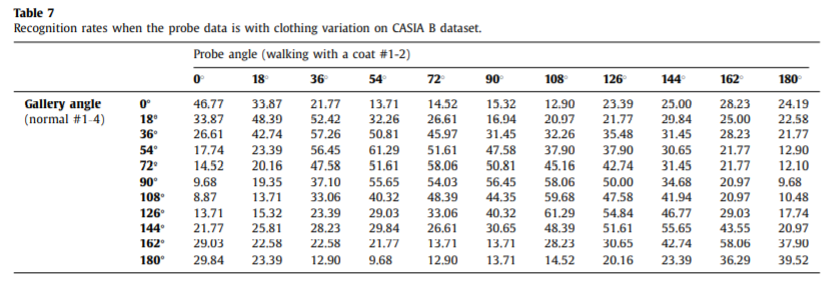
Effectiveness of the handcrafted features by prior knowledge
为了降低CNN特征提取的负担,并且使特征更加有判别力,使用了通过人类先验知识的特征。为了证明这些特征的有效性,使用不同的特征做了如下的实验,其中的数值平均值。
这里能得出一些结论:首先,如果没有任何变化,fpose可以达到高达60.92%的准确率,在正常行走和背着包的情况下是这些特征中最好的。然后再穿大衣的情况下运动特征更加重要,证明它对服装变化有一定的鲁棒性。如果将几个特征合并起来,会有比较显著的识别率提升。

Comparisons with appearance-based methods
基于模型的特征更加轻量,并且没有像基于外貌特征的那么多的冗余信息,说明特征人能够提取更加有挑战性。从表中可以看出作者提出的方法比前三个都要好,与第四个相当。同时也可以看出这种方法在穿大衣的情况更具有鲁棒性,这是基于模型方法的优点,而基于外貌的受之影响较大。
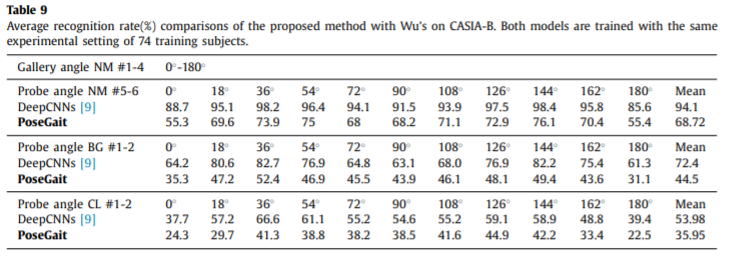
另外,论文9的方法实验配置有所不同,为了能够比较作者同样做了相关实验。
而这个方法明显优于本文提出的,这是因为其使用了高维的外貌特征;其次,他们以验证的方式对CNN进行配对训练,因此训练的组合数量可能超过一百万。相比之下,作者的模型是以分类和验证的方式训练的。样本数量远少于[9]中的样本数量。
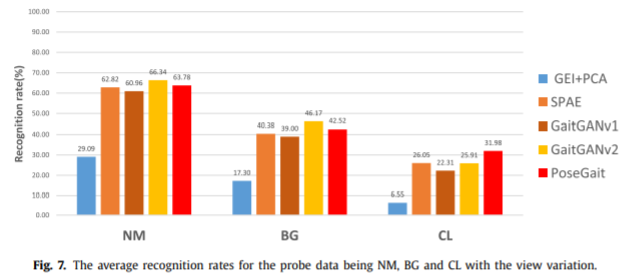
Effectiveness on view variation
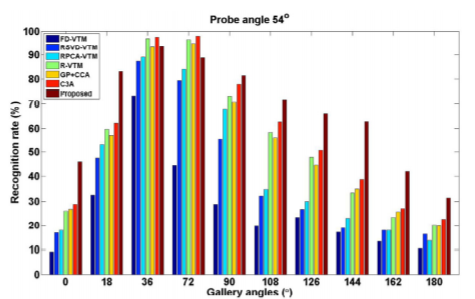
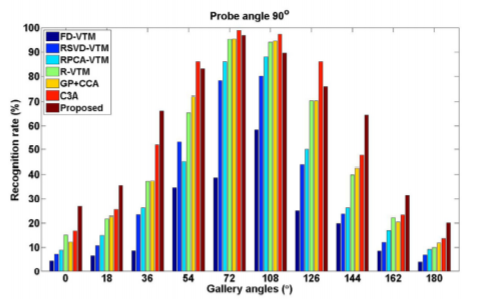
给出的方法与SOTA效果类似,在服装改变下鲁棒性更好。为了进一步验证性能,作者还使用一些交叉视角的步态估计方法。probe角度采用了54,90和126。
可以发现,作者提出的方法当gallery angle和probe angle差异很大的时候比其他方法有更好地效果,提升效果更加显著。因为作者使用3D空间将两者统一到一个视角,所以对于视角更加鲁棒。

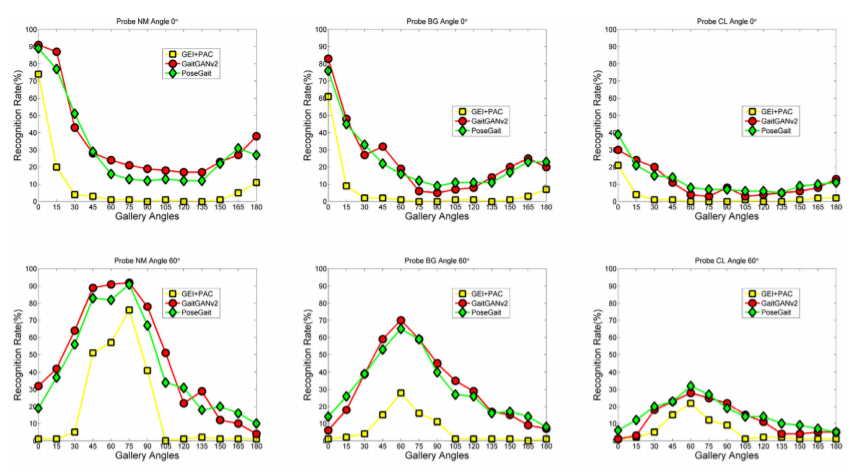
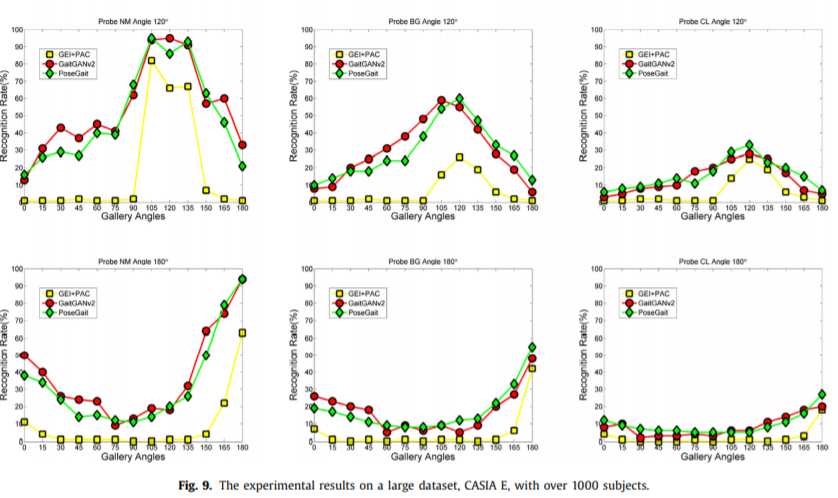
Experimental results on CASIA E dataset
为了进一步验证方法的效果,还在CASIA E上做了实验。因为该数据集没有公开,所以不能引用原始论文的结果。
实验结论与第一个数据集基本一致。
Computational cost analysis

5、结论与未来展望
随着基于深度学习的人体建模方的进步,作者提出了一种基于建模的步态识别方法,称为PoseGait。它使用3D人体姿态作为特征,因为只有关节点这个特征非常的袖珍。作者在CASIA B和CASIA E数据集上做了实验,表现出与SOTA类似的效果。另外,作者根据人体先验知识合并了三种类型的时空特征来提升识别率。实验证明CNN比LSTM或RNN有更好的效果。
尽管只达到了与SOTA类似的效果,但是这种基于建模的方法表现出很大的潜力。除了OpenPose,还有其他建模方法例如DensePose,但是其建模有限制,导致数据不完整,无法用于不太估计。未来的人体建模会持续的提升,这种基于建模的方法也会随之提升。
总结
这篇文章理论上的创新不是特别的大,包括使用的OpenPose也是提出了很长时间的。但是做了很多实践性的工作,包括用OpenPose去解决步态估计,在其输出的特征点的基础上再根据一篇有关从2D到3D的论文将其扩展到3D姿态估计,并且对于其中的特征经过了比较精心的设计。至于模型也尝试用CNN去代替RNN,这个思想在之前的一些论文中也有了,但是本篇论文实现了一个应用。总的来说,尽管没有理论上的突破,但是实践结果很好,能够将领域内的优秀的方法实现应用,并且做了大量的对比实验,工作量也是很大的。应用上的创新还是可以简单总结一下:
- 尝试通过3D姿态估计(从OpenPose输出的2D通过预测方法转为3D)解决步态识别问题
- 根据先验知识与3D姿态估计结果设计特征
- 设计了loss来扩大类间差异,缩小类内差异
- 用特征提取能力较强的CNN来代替RNN解决时序问题
总的来说,本篇文章对于用姿态估计解决步态识别还是很有启发性的,包括从数据处理到特征提取,再到模型验证,都能反映领域的一般方法,有很多值得学习的地方。其实也可以看出,除了对3D姿态估计的应用,比较重要的一点是其设计的特征,决定了学习的效果。从人体的躯干动作出发对于步态识别其实也是更合理的,因此这个方向相比于基于外貌特征的潜力应该要更大一些。