这里主要是对EasyAnimate的论文阅读记录,感兴趣的话可以参考一下,如果想要直接阅读原英文论文的话地址在这里,如下所示:

摘要
本文介绍了EasyAnimate,一种利用Transformer架构实现高性能视频生成的高级方法。我们将原本设计用于2D图像合成的DiT框架扩展到3D视频生成,通过引入一个名为混合运动模块的特殊运动模块块。在运动模块中,我们结合了时间注意力和全局注意力,以确保生成连贯的帧和无缝的运动过渡。此外,我们提出了Slice VAE,一种新颖的方法来压缩时间轴,从而促进长时长视频的生成。目前,EasyAnimate能够从不同分辨率的图像生成最多144帧的视频。我们提供了一个基于DiT的全面视频生产生态系统,涵盖数据预处理、VAE训练、DiT模型训练(包括基线模型和LoRA模型)以及端到端视频推理。代码可在以下网址获取:https://github.com/ajgc-apps/EasyAnimate。如下所示:

1 引言
人工智能在文本、图像和声音的创意内容生成方面已经显著扩展了视野。在视觉领域,扩散模型在图像生成和修改中得到了广泛应用。开源项目如Stable Diffusion[21]在将文本转换为图像方面取得了显著进展。
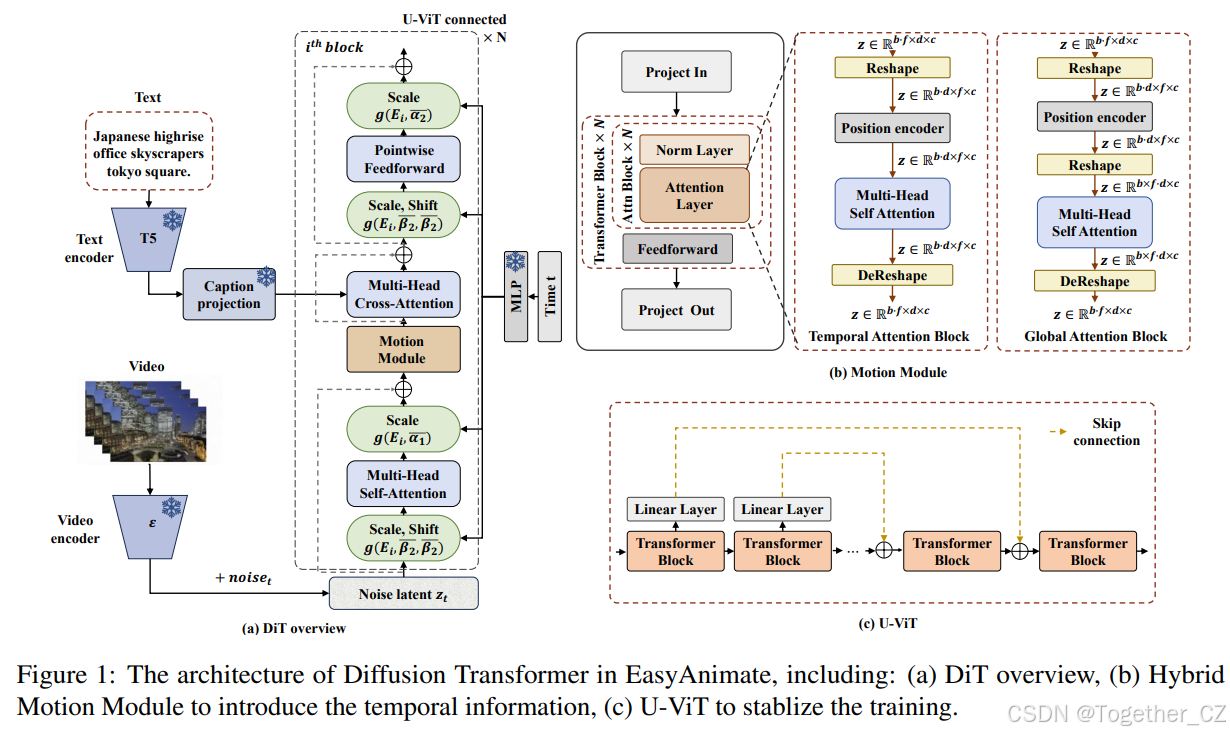
图1:EasyAnimate中扩散Transformer的架构,包括:(a) DiT概述,(b) 混合运动模块以引入时间信息,(c) U-ViT以稳定训练。
然而,在视频生成方面,当前模型仍面临一些挑战,如质量差、视频长度有限和运动不自然,表明在技术上仍有很大的进步空间。利用稳定扩散方法进行视频合成的开创性工作[22, 4, 23, 14],主要集中在UNet架构的降噪过程中。最近,Sora[16]展示了非凡的视频生成能力,能够生成长达一分钟的高保真视频。这一进展显著提升了现实世界模拟的真实性,并揭示了Transformer架构在视频生成中的关键作用,促使开源社区[17, 15]深入研究Transformer结构的复杂性。
在此背景下,我们介绍了EasyAnimate,一个简单而强大的视频生成基线。在DiT方面,我们通过引入名为混合运动模块的运动模块块来探索视频生成的时间信息。在运动模块中,我们结合了时间注意力和全局注意力,以确保生成连贯的帧和无缝的运动过渡。此外,EasyAnimate集成了图像以指导内容生成,使用文本到视频模型的运动先验。双流设置使用一个文本丰富的编码器进行图像编码和参考数据注入,同时使用变分自编码器进行掩码重建,从而实现图像到视频的生成。此外,我们提出了Slice VAE技术,旨在压缩时间维度并减少随着视频长度增加的内存使用,从而促进长时长视频的生产。我们提供了一个基于DiT的全面视频生产生态系统,包括数据预处理、VAE训练、DiT模型训练和端到端视频推理。图1展示了EasyAnimate的流程概览。
贡献可以总结如下:
(1) 我们提出了EasyAnimate,一种利用Transformer架构实现高性能视频生成的高级方法。
(2) 我们通过引入运动模块块来探索视频生成的时间信息。在运动模块中,我们结合了时间注意力和全局注意力,以确保生成连贯的帧和无缝的运动过渡。
(3) 我们提出了Slice VAE,以压缩时间维度并减少随着视频长度增加的GPU内存使用,从而促进长时长视频的生产。
2 相关工作
视频VAE: 在早期的研究中,基于图像的变分自编码器(VAEs)已被广泛用于视频帧的编码和解码,如AnimateDiff[Guo et al., 2023]、ModelScopeT2V[Wang et al., 2023]和OpenSora[Speaitech, 2024]。常见的图像VAE实现,如Stable Diffusion[StabilityAI, 2023],将视频帧压缩为潜在特征,将其空间维度缩小到宽度和高度的八分之一。这种方法忽略了时间动态,将视频转换为静态图像,未能压缩时间,导致潜在特征较大并增加了CUDA内存需求。这显著阻碍了长视频的创建,突显了在视频编码和解码中有效压缩时间的基本挑战。


图2:EasyAnimate可以根据图像和文本提示生成视频。
MagViT[Yu et al., 2023]是一个著名的视频VAE示例,据推测在Sora框架中使用。因果3D卷积块在标准3D卷积之前引入了时间填充,利用先前帧的信息来增强时间因果性,而不会受到后续帧的影响。MagViT允许同时处理图像和视频,通过整合图像训练来利用丰富且易于访问的图像,增强了DiT训练中的文本图像对齐。过去的研究表明[Blattmann et al., 2023],将图像纳入视频训练可以更有效地优化模型架构,提高其文本对齐和输出质量。尽管MagViT具有复杂的视频编码和解码能力,但在训练非常长的视频序列时仍面临内存限制,如1024x1024x40,通常超过A100 GPU的容量。这需要对大视频进行增量解码的批处理,而不是一步解码,突显了内存高效技术的重要性。
为了提高时间维度的压缩效率,我们提出了Slice VAE,它在时间轴上引入切片机制,通过批处理压缩长视频。此外,Slice VAE具有独特的上采样设置,可以分别处理图像和视频。
视频扩散模型: 利用稳定扩散方法进行视频合成的开创性工作[Guo et al., 2023; Chen et al., 2024; Wang et al., 2023; Luo et al., 2023],主要集中在UNet架构的降噪过程中。最近,Sora[OpenAI, 2024]展示了非凡的视频生成能力,能够生成长达一分钟的高保真视频。这一进展显著提升了现实世界模拟的真实性,并揭示了Transformer架构在视频生成中的关键作用。一个著名的基于Transformer的视频生成基线是Latte,它最初从输入视频中提取时空令牌,然后使用一系列Transformer块在潜在空间中建模视频分布。然而,Latte仅关注时间轴上每个潜在的信息,忽略了全局信息。
为了解决Latte中缺乏全局感知的问题,我们调整了最初用于2D图像合成的DiT框架,通过添加一个特殊的运动模块块,并结合时间注意力和全局注意力,进一步提高DiT的全局感知能力。
3 架构
我们在PixArt-α[Chen et al., 2023b]的基础上构建了EasyAnimate。它包括一个文本编码器(TS Encoder[Raffel et al., 2020])、视频VAE(一个视频编码器和一个视频解码器)和一个扩散Transformer(DiT)。这些组件将在以下部分详细说明。
Slice VAE
视频VAE的作用是压缩视频的潜在时间维度,以减少扩散过程本身所需的计算负载,这也涉及大量计算。以MagViT为例,当一次性处理1024x1024x21的视频时,即使使用A100 80GB GPU,我们也会遇到“内存不足”错误。因此,我们需要对输入数据进行批处理。
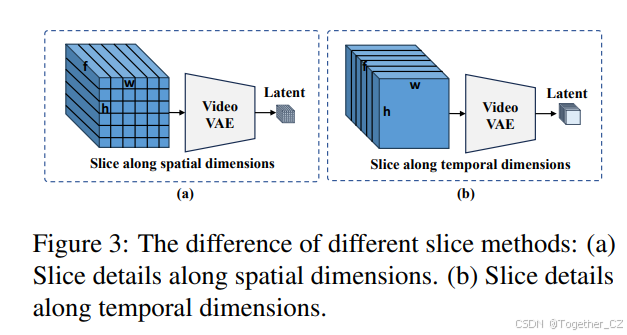
图3:不同切片方法的差异:(a) 沿空间维度的切片细节。(b) 沿时间维度的切片细节。
有两种批处理方法:一种是沿空间维度切片,另一种是沿时间维度分割。我们最初尝试沿空间维度切片,如图3(a)所示。虽然这可以减少模型的内存使用,但一次性解码近百帧视频仍需要大量内存,随着视频时间的增加。然后我们转向沿时间维度切片。使用这种方法,一组视频帧被分成几个段,每个段分别编码和解码,如图3(b)所示。在这种情况下,假设我们使用MagViT进行视频编码,由于MagViT中的前向填充,每个批次中第一个单元的潜在特征包含较少信息。这种信息分布不均可能是阻碍模型优化的独特因素。为了解决这个问题,我们设计了Slice VAE,如图4所示。

图4:Slice VAE的概述。Slice VAE对图像和视频采用不同的解码方法。
Slice VAE对图像和视频采用不同的解码方法。在处理视频时,我们在时间轴上对潜在特征进行下采样和上采样。此外,我们在不同批次之间实现特征共享,如图4所示。在解码过程中,特征与其前后的特征(如果可用)连接,从而获得更一致的特征。
视频扩散Transformer
扩散Transformer的架构如图1所示。我们在DiT中添加了一个特殊的运动模块,如图1(b)所示,使其从2D图像合成扩展到3D视频生成。在运动模块中,我们利用时间注意力和全局注意力机制的混合,以确保生成连贯的帧和流畅的运动过渡。此外,我们集成了U-ViT[Bao et al., 2023]连接,如图1(c)所示,以增强训练过程的稳定性。
混合运动模块:运动模块专门设计用于利用嵌入在帧长度中的时间信息。通过在时间维度上集成注意力机制,模型能够吸收这些时间数据,这对于生成视频运动至关重要。类似于AnimateDiff[Guo et al., 2023],我们的运动模块在时间轴上应用注意力机制。此外,我们关注运动模块中的全局信息,而不仅仅是时间轴,赋予整个模型全局感知能力,并增强动态重建性能。
图像引导:EasyAnimate允许在生成过程中将图像作为指导,利用文本到视频扩散模型的运动先验。这是通过一个双流架构实现的,其中包含文本信息的编码器对图像进行编码,以获得注入参考图像信息的文本嵌入。同时,变分自编码器对需要重建的掩码信息和参考图像信息进行编码,以促进图像到视频的生成。图像引导视频生成的详细信息如图5所示。
U-VIT:在训练过程中,我们观察到深度DiT往往不稳定,表现为模型的损失从0.05急剧增加到0.2,最终上升到1.0。为了增强模型优化过程并避免在DIT层反向传播时梯度崩溃,我们使用了相应Transformer块之间的长跳连接,这对于基于UNet框架的Stable Diffusion模型是有效的。为了在不进行全面重新训练的情况下无缝集成这一修改,我们初始化了几个全连接层,其权重填充为零,如图1(c)中的灰色块所示。
4 数据预处理
EasyAnimate的训练包括图像数据和视频数据。本节详细介绍了视频数据处理方法,包括三个主要阶段:视频分割、视频过滤和视频字幕生成。这些步骤对于筛选具有详细字幕的高质量视频数据至关重要,这些字幕能够封装视频内容的精髓。
视频分割
对于较长的视频分割,我们首先使用PySceneDetect[1]识别视频中的场景变化,并根据这些过渡进行场景切割,以确保视频片段的主题一致性。切割后,我们仅保留长度在3到10秒之间的片段用于模型训练。
视频过滤
我们从三个方面过滤视频数据,即运动过滤、文本过滤和美学过滤。

图5:图像引导视频生成的详细信息。
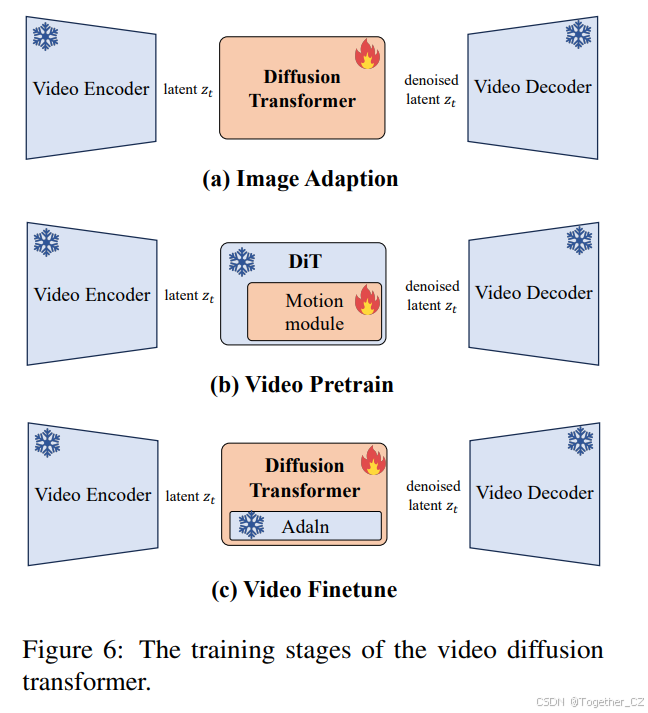
图6:视频扩散Transformer的训练阶段。
运动过滤:在视频生成模型的训练过程中,确保视频展示出运动感至关重要,以区别于静态图像。同时,保持运动的一致性也很重要,因为过于剧烈的运动会破坏视频的整体连贯性。为此,我们使用RAFT[Teed and Deng, 2020]计算指定帧率下帧之间的运动分数,并过滤具有适当运动分数的视频以进行动态微调。
文本过滤:视频数据通常包含特定的文本信息(例如字幕),这不利于视频模型的学习过程。为此,我们使用光学字符识别(OCR)确定视频中文字区域的比例面积。对采样帧进行OCR以表示视频的文本分数。然后,我们仔细过滤掉任何文字区域超过视频帧1%的视频片段,确保剩余的视频最优用于模型训练。
美学过滤:此外,互联网上存在许多低质量的视频。这些视频可能缺乏主题焦点或模糊度过高。为了提高训练数据集的质量,我们计算美学分数[2]并保留高分数的视频,获得视觉上吸引人的训练集用于视频生成。
视频字幕生成
视频字幕的质量直接影响生成视频的结果。我们全面比较了几种大型多模态模型,权衡了它们的性能和操作效率。经过仔细考虑和评估,我们选择了VideoChat[Li et al., 2023]和VILA[Lin et al., 2023]进行视频数据字幕生成,因为它们在我们的评估中表现出色,特别是在生成具有细节和时间信息的视频字幕方面显示出巨大潜力。
5 训练过程
总共,我们使用了大约1200万张图像和视频数据来训练视频VAE模型和DiT模型。我们首先训练视频VAE,然后使用三阶段从粗到细的训练策略将DiT模型适应新的VAE。
视频VAE
我们首先使用Adam优化器,beta值为(0.5, 0.9),学习率为1e-4,总共训练350,000步,批量大小为128,训练MagViT。
然后,我们从上述训练的MagViT初始化Slice VAE的权重。Slice VAE分两阶段训练。首先,我们使用Adam优化器,beta=(0.5, 0.9),批量大小=96,学习率为1e-4,训练整个VAE 200,000步。接下来,按照Stable Diffusion[Stability-AI, 2023]的流程,我们在第二阶段仅训练解码器100,000步,以更好地增强解码视频的保真度。
视频扩散Transformer
如图6所示,DiT模型的训练过程分为几个阶段。
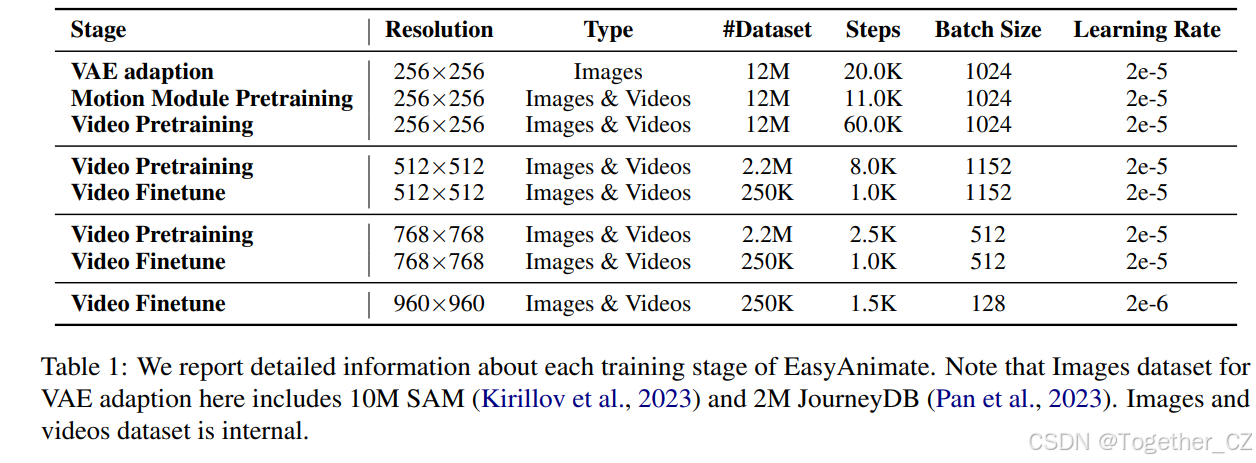
表1:我们报告了EasyAnimate每个训练阶段的详细信息。请注意,VAE适应的图像数据集包括10M SAM(Kirillov et al., 2023)和2M JourneyDB(Pan et al., 2023)。图像和视频数据集为内部数据。
在第一阶段,引入新的视频VAE后,我们首先使用图像数据将其与DiT参数对齐。在第二阶段,我们使用大规模视频数据集和图像数据预训练运动模块块,从而引入DiT的视频生成能力。此时,尽管模型能够生成具有基本运动的视频,但输出质量通常较差,表现为运动有限和清晰度不足。
因此,在第三阶段,我们使用大规模视频数据集解冻整个DiT模型,使其更好地感知动态。最后,我们使用高质量视频数据微调整个DiT模型,以增强其生成性能。模型逐步从较低分辨率到较高分辨率进行训练,这是一种有效的策略,可以节省GPU内存并减少计算时间。
为了适应不同分辨率的视频生成,我们使用桶策略训练不同视频分辨率。
6 结论
本文介绍了EasyAnimate,一种基于Transformer架构的高性能AI视频生成和训练管道。EasyAnimate引入了一个名为混合运动模块的特殊运动模块,旨在保证均匀的帧生成和运动的无缝过渡。它还支持图像引导的视频生成。此外,为了解决VAE在生成长视频时GPU内存不足的问题,我们提出了Slice VAE,用于沿时间轴进行批量编码和解码。该模型能够在训练和推理过程中适应不同的帧数和分辨率组合,适用于生成图像和视频。