数据来源于阿里云天池,为淘宝app平台在2014年11月18日-12月18日的数据。
数据处理
导入相关的包,设置seaborn的绘图风格:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
使用open看一下数据形式:
filename = 'tianchi_mobile_recommend_train_user.csv'
with open(filename) as f:
for _ in range(5):
line = f.readline()
line.strip()
print(line)
user_id,item_id,behavior_type,user_geohash,item_category,time
98047837,232431562,1,,4245,2014-12-06 02
97726136,383583590,1,,5894,2014-12-09 20
98607707,64749712,1,,2883,2014-12-18 11
98662432,320593836,1,96nn52n,6562,2014-12-06 10
使用read_csv读取数据:
data = pd.read_csv(filename, sep=',')
data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 12256906 entries, 0 to 12256905
Data columns (total 6 columns):
# Column Dtype
--- ------ -----
0 user_id int64
1 item_id int64
2 behavior_type int64
3 user_geohash object
4 item_category int64
5 time object
dtypes: int64(4), object(2)
memory usage: 561.1+ MB
data.head()
将behavior_type的值替换为对应的行为:
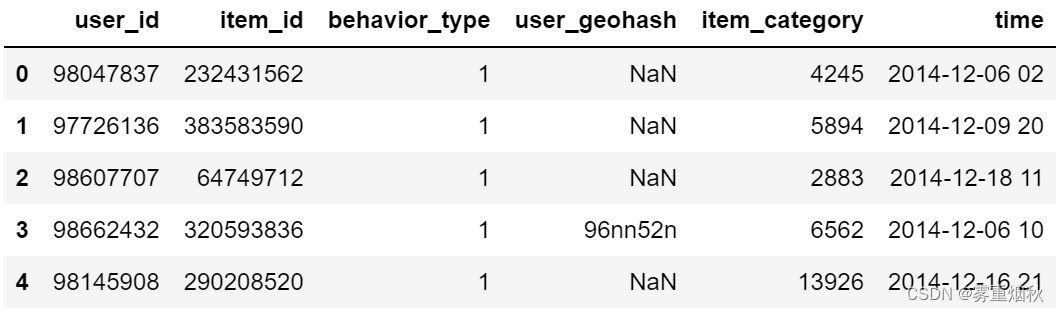
# 将behavior列改变
behavior_mapping = {'1': 'click', '2': 'collect', '3': 'cart', '4': 'purchase'}
data['behavior_type'] = data['behavior_type'].astype(str).map(behavior_mapping)
data
检查是否有重复项,即同一时间、同一用户、同一商品、同一个行为:
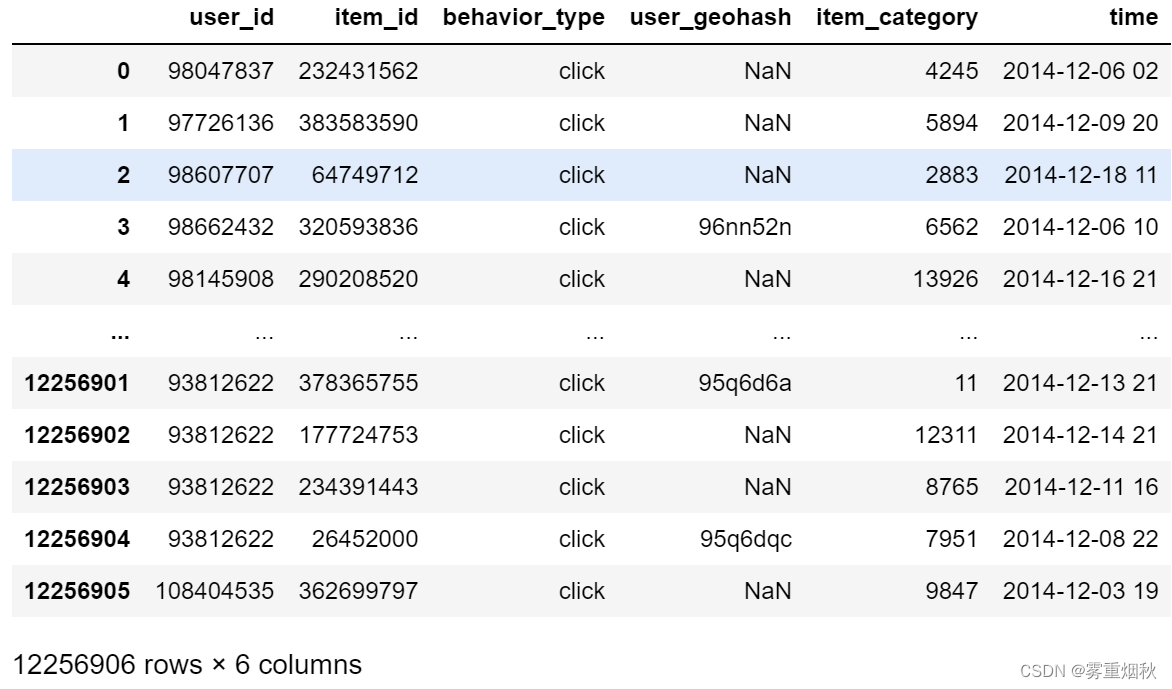
# 检查重复项
duplicates = data.duplicated(subset=['user_id', 'item_id', 'time', 'behavior_type'])
duplicates[duplicates == True].sum()
6043527
去除重复项:
data = data.drop_duplicates(['user_id', 'item_id'], keep='first')
data
# 将time列转换成datatime类型
data['time'] = pd.to_datetime(data['time'])
data.loc[:, 'time'] = data['time'].dt.strftime('%m-%d')
data
每日pv统计
daily_pv = data[data['behavior_type'] == 'click'].groupby(data['time']).size()
daily_pv
time
11-18 141760
11-19 135782
11-20 132636
11-21 125752
11-22 136362
11-23 145400
11-24 141774
11-25 137280
11-26 134526
11-27 137784
每日uv统计
daily_uv = data[data['behavior_type'] == 'click'].groupby(data['time']).user_id.nunique()
daily_uv
time
11-18 6189
11-19 6206
11-20 6096
11-21 6026
11-22 5921
11-23 6115
11-24 6226
11-25 6062
11-26 6064
11-27 6089
11-28 5889
11-29 5944
将pv和uv绘图
fig = plt.figure(figsize=(12, 6)) # 增加图表宽度
ax1 = fig.add_subplot(2, 1, 1) # 第一个坐标轴(2行1列的第一个)
ax2 = fig.add_subplot(2, 1, 2) # 第二个坐标轴(2行1列的第二个)
# 在第一个坐标轴上绘制PV数据
ax1.plot(daily_pv.index, daily_pv.values, label='PV', color='blue')
ax1.tick_params(axis='x', rotation=45)
# 在第二个坐标轴上绘制UV数据
ax2.plot(daily_uv.index, daily_uv.values, label='UV', color='green')
ax2.tick_params(axis='x', rotation=45)
fig.subplots_adjust(hspace=0.35)
结果分析:可以看出,pv和uv是高度正相关的,在双十二左右都剧烈增加,出现井喷现象,说明了活动的热度。
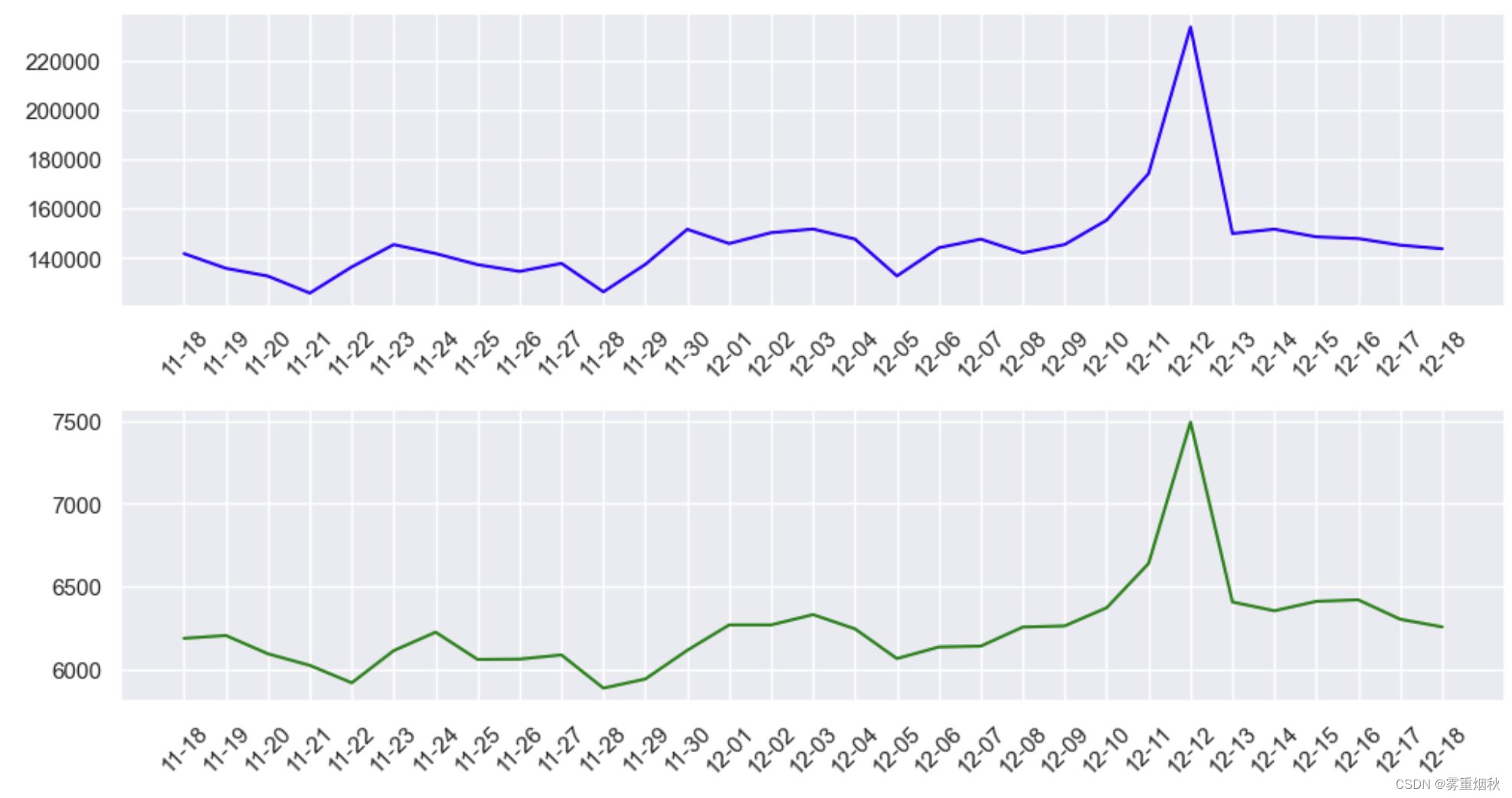
每日用户的行为趋势
daily_behavior = data.groupby(['behavior_type', 'time']).user_id.nunique()
daily_behavior
behavior_type time
cart 11-18 1027
11-19 969
11-20 992
11-21 871
11-22 927
...
purchase 12-14 366
12-15 453
12-16 427
12-17 417
12-18 415
Name: user_id, Length: 124, dtype: int64
plt.figure(figsize=(12, 6))
daily_behavior.unstack(0).plot()
可以看出双十二的时候,购买人数峰值高于收藏,说明很多人都是活动直接下单,活动力度很大,而日常情况下,加购物车>收藏>购买,人们更普遍的进行加购物车操作,收藏操作相对少一些。
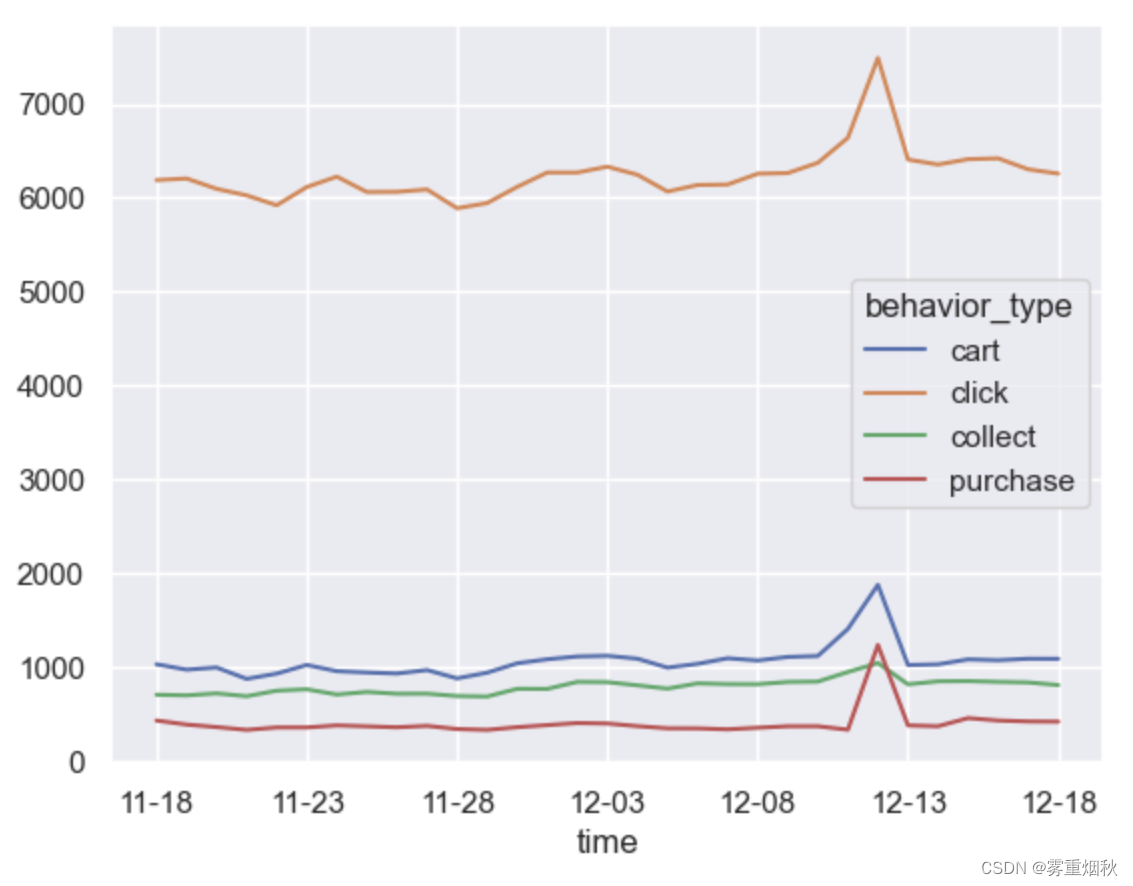
漏斗模型:用户行为转换分析
from pyecharts.charts import Funnel
from pyecharts import options as opts
Funnel_behavior=data.groupby(['behavior_type'])['user_id'].nunique()
Funnel_behavior.rename('Count', inplace=True)
Funnel_behavior.drop(index='collect', inplace=True)
value = Funnel_behavior.values.tolist()
key = Funnel_behavior.index.tolist()
# 计算每个阶段的百分比
for i in range(0, len(value)):
value[i] = value[i] / tmp * 100 # 以第一个阶段为基准计算百分比
value[i] = "{:.2f}".format(value[i]) # 格式化为两位小数
# 创建 Funnel 图表实例
c = Funnel()
# 使用 add 方法添加数据
c.add(
'', # 系列名称
list(zip(key, value)), # 数据
label_opts=opts.LabelOpts(
is_show=True, # 显示标签
formatter='{b}: {d}%' # 格式化标签显示为 "行为类型: 百分比%"
)
)
# 设置全局配置,例如标题
c.set_global_opts(title_opts=opts.TitleOpts(title="用户行为转化漏斗"))
c.render_notebook()
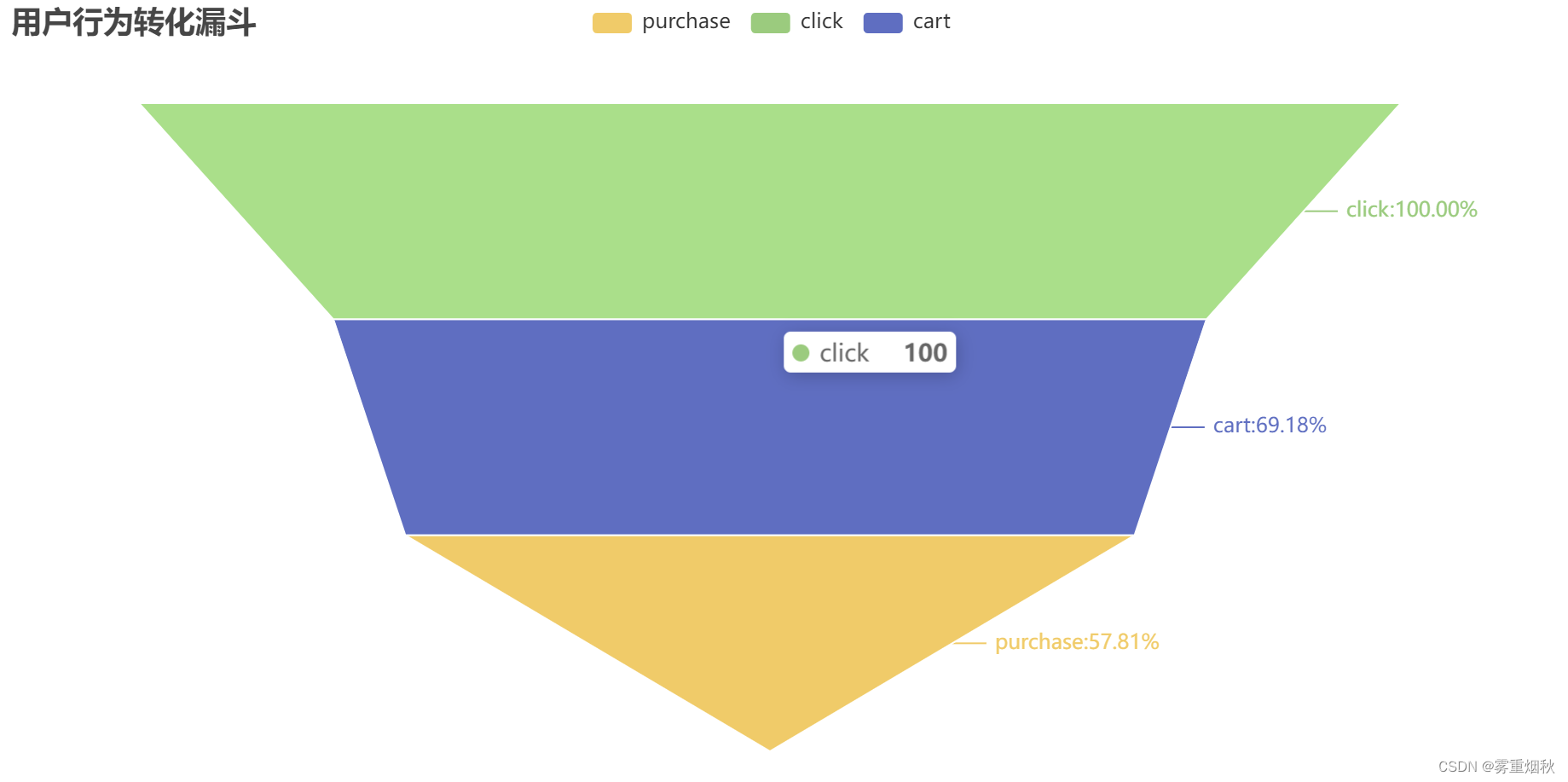
可以看出,click人数的69.18%都进行了cart操作,57.81%都进行了purchase操作,说明加购物车到购买是比较容易的,因此要提高从点击转化为加购物车的转化率,这样购买人数也会提高。
周期内用户行为频率
data.loc[:, 'user_id1'] = data['user_id']
user_data = data.pivot_table('user_id', index='user_id1', columns='behavior_type', aggfunc='count')
根据click次数升序排列:
user_behavior = user_data.sort_values(by='click', ascending=False)
用describe得到一些统计量:
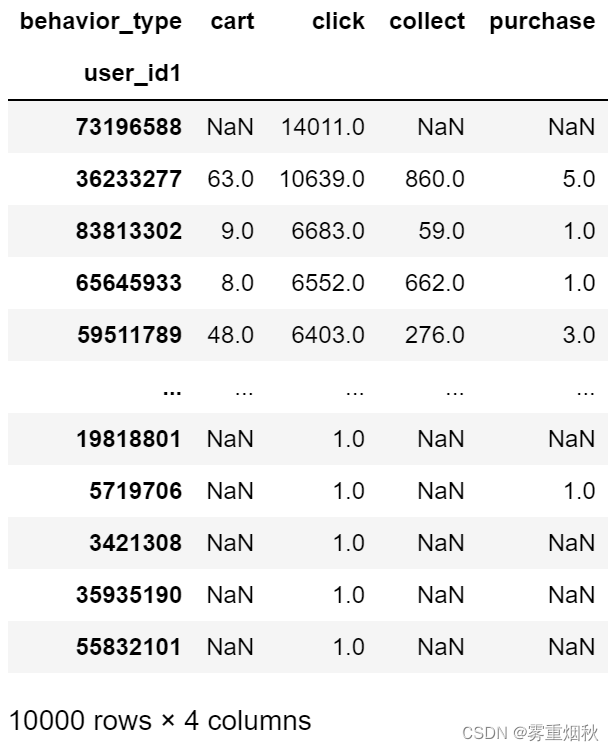
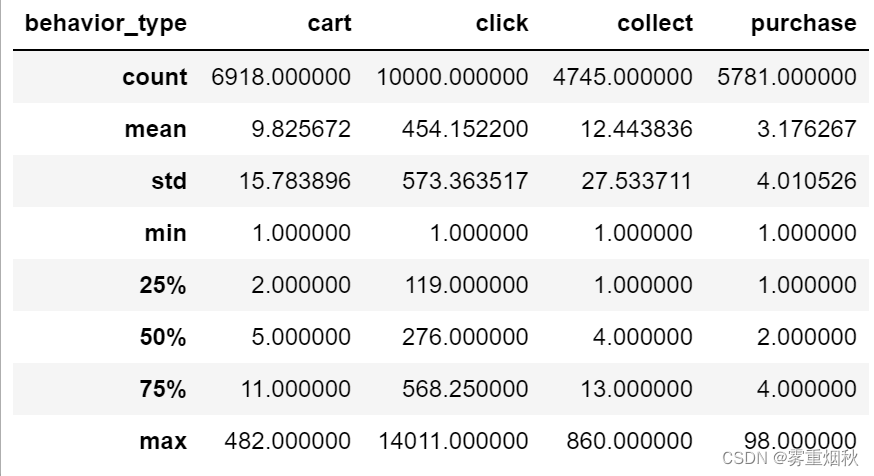
user_behavior.describe()
# 包含缺失值的统计量
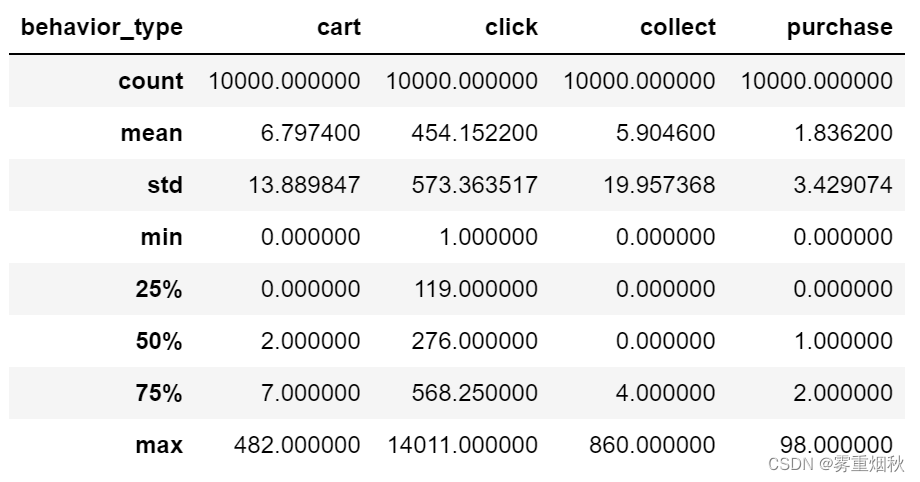
user_behavior.fillna(0).describe()
能够看出,平均购买次数近两次,收藏和购买行为用户占总用户的50%。
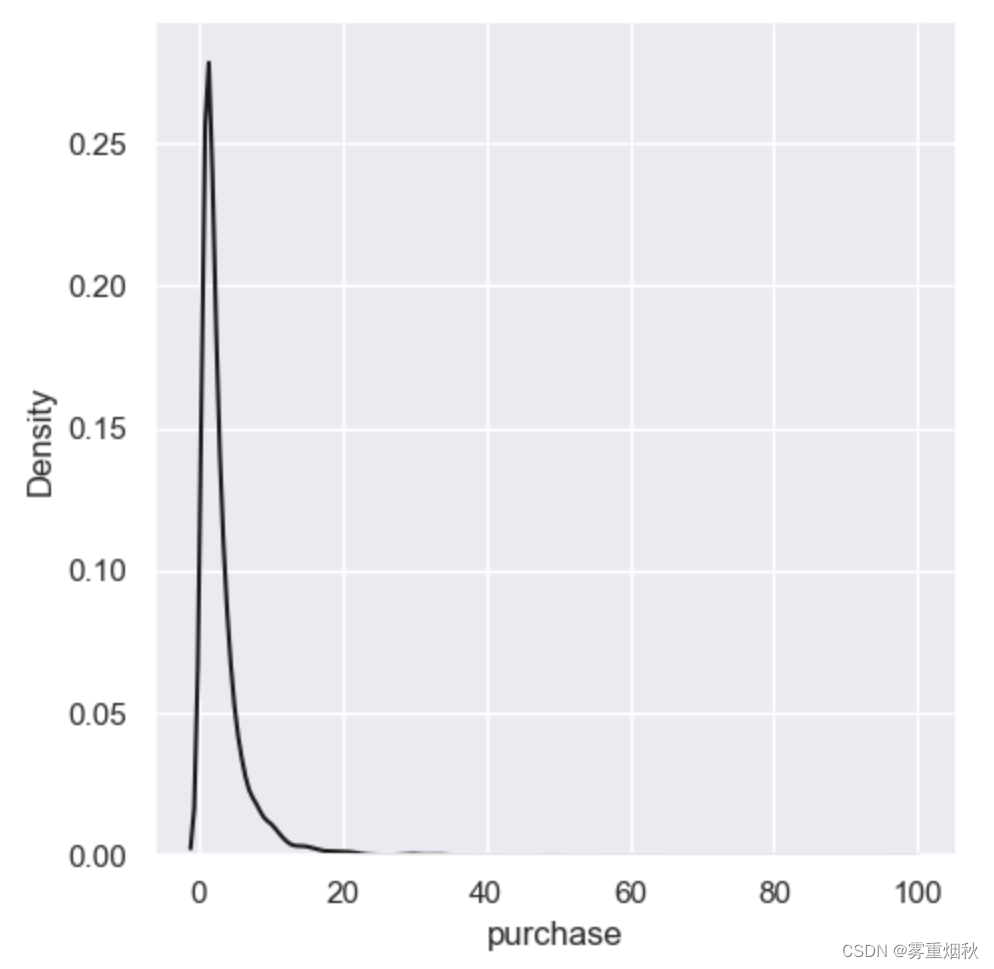
画出密度分布图:
sns.displot(user_behavior['purchase'], color='k', kind='kde')
跳失率和复购率
跳失率=只有点击行为的用户/总用户数:
grouped_userid = data.groupby('user_id')
grouped_usertype = grouped_userid.behavior_type.value_counts().unstack(1)
users_click = grouped_usertype[grouped_usertype['click'] == grouped_usertype.sum(axis=1)]
onlyclick_rate = users_click.shape[0] / data['user_id'].nunique()
print("跳失率:{:.2f}%".format(onlyclick_rate*100))
跳失率:11.98%
复购率=购买2次及以上用户数/总购买用户数:
users_buytwo_rate = grouped_usertype[grouped_usertype['purchase'] >= 2].shape[0] / data[data['behavior_type'] == 'purchase'].user_id.nunique()
print("复购率:{:.2f}%".format(users_buytwo_rate*100))
复购率:60.73%
跳失率为11.98%,说明大部分用户在点击后都有其他的行为发生,说明内容比较吸引人,复购率60.73%说明有4成的人只买过一次,这可能和商品属性、售后服务等有关,这部分有提升空间。