一、什么是分析
Elasticsearch 的分析过程是将文本数据转换成适合搜索的形式的关键步骤。这一过程主要包括四个阶段:字符过滤、分词、词条过滤和词条索引。
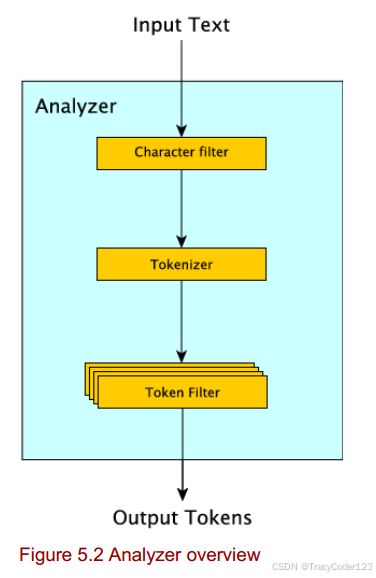
1. 字符过滤 (Character Filtering)
字符过滤是分析过程的第一步,它发生在文本被分词之前。字符过滤器的主要作用是对输入文本进行预处理,以去除或替换某些字符。这一步可以帮助改善后续分析的效果,尤其是在处理包含特殊字符或格式化内容(如 HTML 标签)的文本时尤为重要。
- 用途:例如,可以使用字符过滤器来删除文本中的 HTML 标签,或将某些字符转换为其他字符(比如将连字符转换为空格)。
- 实现:Elasticsearch 提供了一些内置的字符过滤器,如
html_strip用于剥离 HTML 标签。此外,也可以编写自定义的字符过滤器来满足特定的需求。
2. 分词 (Breaking into Tokens)
分词是将文本切分为更小的单位,即词条(tokens)的过程。每个词条代表一个独立的搜索项。分词器的选择对最终的搜索结果影响很大。
- 分词器类型:
- 标准分词器:适用于多种语言,能够识别并分割大多数常见文本。
- 语言特定分词器:如中文分词器(如 IK 分词器或结巴分词器),能够更好地处理特定语言的文本。
- 模式分词器:允许使用正则表达式来自定义分词规则。
- 例子:假设有一个句子 “Elasticsearch is a powerful search engine”,标准分词器会将其分解为 [“Elasticsearch”, “is”, “a”, “powerful”, “search”, “engine”]。
3. 词条过滤 (Token Filtering)
分词后的词条会通过一系列的词条过滤器进行处理,以优化搜索性能和相关性。词条过滤器可以执行多种操作,包括但不限于:
- 小写转换:将所有词条转换为小写,以确保搜索时不区分大小写。
- 停用词移除:移除那些在搜索中通常不提供有用信息的常见词汇,如 “the”、“and” 等。
- 词干提取:将词条还原到其基本形式,例如将 “running” 转换为 “run”。
- 同义词扩展:将词条替换为一组相关的词条,以提高搜索的覆盖范围。
- 词形还原:将词条还原到其词典形式,与词干提取类似,但更精确。
4. 词条索引 (Token Indexing)
经过字符过滤、分词和词条过滤之后,最终的词条将被索引。索引过程涉及将词条及其元数据(如位置信息、频率等)存储在倒排索引中。倒排索引是一种数据结构,它允许快速查找包含特定词条的文档。
- 倒排索引结构:每个词条对应一个文档列表,列表中的每个元素表示该词条出现在哪个文档中以及出现的位置。
- 索引存储:词条和其元数据被高效地存储,以便于快速检索。
二、内置分析器分类
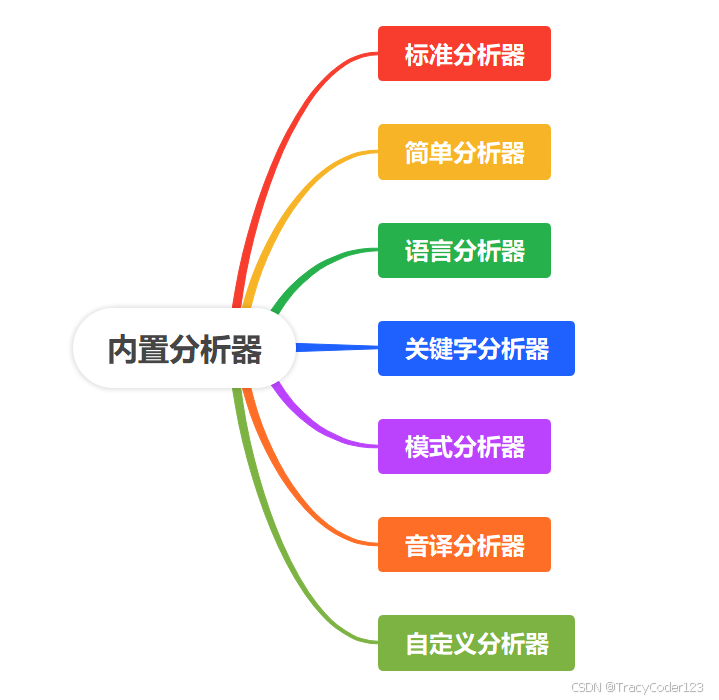
Elasticsearch 提供了多种内置的分析器,每种分析器都针对特定的使用场景进行了优化。这些内置分析器可以处理不同的语言和文本类型,帮助用户更有效地索引和搜索数据。下面详细介绍几种常用的内置分析器及其特点:
1. 标准分析器 (Standard Analyzer)
描述:这是 Elasticsearch 的默认分析器,适用于多种语言的通用文本分析。它使用标准分词器和标准词条过滤器。
分词器:
- 标准分词器:将文本拆分为单词,忽略标点符号和空白字符。
词条过滤器:
- 小写过滤器:将所有词条转换为小写。
- 停止词过滤器:移除常见的停用词(如 “the”、“is” 等)。
示例:
{
"analyzer": {
"standard": {
"type": "standard"
}
}
}
2. 简单分析器 (Simple Analyzer)
描述:适用于简单的文本分析,主要用于英文。它使用简单分词器,将文本按非字母字符拆分,并将所有词条转换为小写。
分词器:
- 简单分词器:将文本按非字母字符拆分。
词条过滤器:
- 小写过滤器:将所有词条转换为小写。
示例:
{
"analyzer": {
"simple": {
"type": "simple"
}
}
}
3. 语言分析器 (Language Analyzers)
描述:Elasticsearch 提供了多种语言特定的分析器,每种语言分析器都针对特定语言的语法和词汇进行了优化。
示例:
- 英语分析器 (
english):- 分词器:标准分词器
- 词条过滤器:小写过滤器、英语停用词过滤器、英语词干提取过滤器
- 中文分析器 (
smartcn):- 分词器:智能中文分词器
- 词条过滤器:小写过滤器
示例:
{
"analyzer": {
"english": {
"type": "english"
},
"smartcn": {
"type": "smartcn"
}
}
}
4. 关键字分析器 (Keyword Analyzer)
描述:不进行任何分析,直接将整个输入文本作为一个单一的词条。适用于不需要分词的字段,如 ID、标签等。
分词器:
- 关键字分词器:将整个输入文本作为一个单一的词条。
示例:
{
"analyzer": {
"keyword": {
"type": "keyword"
}
}
}
5. 模式分析器 (Pattern Analyzer)
描述:使用正则表达式来分词。适用于需要自定义分词规则的场景。
分词器:
- 模式分词器:根据提供的正则表达式将文本拆分为词条。
示例:
{
"analyzer": {
"pattern_analyzer": {
"type": "pattern",
"pattern": "\\W+",
"lowercase": true
}
}
}
6. 音译分析器 (Phonetic Analyzer)
描述:将词条转换为其音译形式,适用于模糊匹配和拼写纠正。常用算法包括 Soundex 和 Metaphone。
分词器:
- 标准分词器
词条过滤器:
- 音译过滤器:将词条转换为其音译形式。
示例:
{
"analyzer": {
"phonetic_analyzer": {
"tokenizer": "standard",
"filter": ["soundex"]
}
}
}
7. 自定义分析器 (Custom Analyzer)
描述:用户可以根据需要组合不同的分词器、字符过滤器和词条过滤器来创建自定义分析器。
示例:
{
"settings": {
"analysis": {
"analyzer": {
"my_custom_analyzer": {
"type": "custom",
"char_filter": ["html_strip"],
"tokenizer": "standard",
"filter": ["lowercase", "stop", "snowball"]
}
}
}
}
}
三、如何使用分析器
我们可以在创建索引时使用分析器,也可以在ES配置文件中指定全局的analyzer;以及结合以上两种方法使用。
1. 在创建索引时使用分析器
在创建索引时,可以指定特定字段使用的分析器。这种方式提供了细粒度的控制,可以根据每个字段的具体需求选择不同的分析器。
示例
假设我们有一个博客文章的索引,其中包含标题和内容字段,我们可以分别为这两个字段指定不同的分析器。
PUT /blog
{
"settings": {
"analysis": {
"analyzer": {
"default_title_analyzer": {
"type": "standard"
},
"default_content_analyzer": {
"type": "english"
}
}
}
},
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "default_title_analyzer"
},
"content": {
"type": "text",
"analyzer": "default_content_analyzer"
}
}
}
}
在这个示例中:
default_title_analyzer使用标准分析器。default_content_analyzer使用英语分析器。title字段使用default_title_analyzer。content字段使用default_content_analyzer。
2. 在 ES 配置文件中指定全局的分析器
在 Elasticsearch 的配置文件(通常是 elasticsearch.yml)中,可以设置全局的分析器。这种方式适用于希望在整个集群中统一使用某个分析器的情况。
示例
假设我们希望在集群中统一使用标准分析器作为默认分析器。
index.analysis.analyzer.default.type: standard
这样配置后,所有新创建的索引如果没有指定特定的分析器,都会使用标准分析器。
3. 结合以上两种方法使用
在实际应用中,可以结合以上两种方法,既在配置文件中设置全局的分析器,又在创建索引时为特定字段指定不同的分析器。这样可以灵活地满足不同场景的需求。
示例
假设我们在配置文件中设置全局的默认分析器为标准分析器,但在创建索引时为特定字段指定不同的分析器。
配置文件 elasticsearch.yml:
index.analysis.analyzer.default.type: standard
创建索引时的配置:
PUT /blog
{
"settings": {
"analysis": {
"analyzer": {
"default_content_analyzer": {
"type": "english"
}
}
}
},
"mappings": {
"properties": {
"title": {
"type": "text"
},
"content": {
"type": "text",
"analyzer": "default_content_analyzer"
}
}
}
}
在这个示例中:
- 全局默认分析器是标准分析器。
title字段没有指定分析器,因此会使用全局的默认分析器(标准分析器)。content字段指定了default_content_analyzer,使用英语分析器。