这节我们主要认识一下内存,便于理解指针操作和后续内存管理。
一、内存分区模型
C程序在执行时,将内存大方向划分为4个区域
(可以结合函数小节的函数栈帧部分看一下)
⚪ 代码区:存放函数体的二进制代码,由操作系统进行管理
⚪ 全局区:存放全局变量和静态变量以及常量
⚪ 堆区:由编译器自动分配释放,存放函数的参数值、局部变量等
⚪ 栈区:由程序员分配和释放,若程序员不释放,程序结束时由操作系统回收
内存分区的意义:不同区域存放的数据,赋予不同的生命周期,给我们更大的灵活编程。
1.程序运行前
在程序编译后,生成了exe可执行程序,未执行该程序前分为两个区域
代码区(代码段):
存放CPU执行的机器指令
代码区是共享的,共享的目的是对于频繁被执行的程序,只需要在内存中有一份代码即可。
代码区是只读的,使其只读的原因是防止程序意外地修改了它的指令
全局区(数据段) :
全局变量和静态变量存放在此。
全局区还包含了常量区,字符串常量和其它常量也存放在此。
该区域地数据在程序结束后由操作系统释放。
全局区:全局变量与静态局部变量
int a;//全局变量-全局区
int main()
{
static int b;//静态局部变量-全局区
return 0;
}静态修饰符static 修饰地全局变量只能在本文件内使用,外部文件无法通过extern解析调用,无修饰地全局变量才是真正意义上的全局变量,本程序地其它文件可以通过extern调用。
2.程序运行后
栈区:
由编译器自动分配/释放内存,存放函数参数和局部变量。
注意:函数不要返回局部变量的地址,栈区开辟的空间由编译器自动释放掉了
int* func()
{
int b=10;
return &b;
}
int main()
{
int *p=func();
printf("%p\n",p);
printf("%p\n",p);
p=NULL;
return 0;
}第一次打印会有结果,是因为编译器做了保留。但无论第几次,都已经是非法操作内存。不要这样操作。(函数运行过程参考函数节函数栈帧部分)
堆区:
由程序员分配释放,如果程序员不释放,当程序结束后由操作系统自动回收。
在C语言主要通过malloc()函数分配堆内存,free()函数释放内存
在C++中主要通过new关键字在堆区开辟内存。
int* func()
{
int* p = (int*)malloc(sizeof(int));
*p = 10;
return p;
}
int main()
{
int* p = func();
printf("%d\n", *p);//输出: 10
return 0;
}指针p指向的内存如果没有被程序员释放,那么程序运行时这个内存就会一直存在。所以根据地址可以找到该块内存。只要没有释放内存,打印几次都不会非法访问。
二、数据在内存中的存储
1.整数在内存中的存储
(回看操作符小节)在讲解操作符的时候,我们就讲过了二进制的相关内容,计算机的数据全部是以二进制形式存储。对于整型来说,数据存放内存中其实存放的就是补码。为什么呢?
在计算机系统中,数值⼀律⽤补码来表⽰和存储。原因在于,使⽤补码,可以将符号位和数值域统⼀处理;同时,加法和减法也可以统⼀处理(CPU只有加法器)此外,补码与原码相互转换,其运算过程是相同的,不需要额外的硬件电路。
2.浮点数在内存中的存储
常见的浮点数:3.14159、1e10等,浮点数家族包括float、double、long double。浮点数表示的范围:float.h中定义。
看看下面这段代码输出什么?
int main()
{
int n = 9;
float* pFloat = (float*)&n;
printf("n的值为:%d\n", n);
printf("*pFloat的值为:%f\n", *pFloat);
*pFloat = 9.0;
printf("num的值为:%d\n", n);
printf("*pFloat的值为:%f\n", *pFloat);
return 0;
}上面这段代码中,n和*pFloat在内存中明明是同一个数,为什么浮点数和整数解读的差别这么大?
要理解这个结果,一定要搞懂浮点数在计算机内部的表示方法。
根据国际标准IEEE(电气电子工程师学会)754,任意一个浮点数V都可以表示成以下形式:
V = (−1) ^S ∗ M ∗ 2^E1. ( -1 )^S 代表符号位,当S=0时,代表正数;S=1时,代表负数2. M 代表有效数字,范围是[1 , 2)3. 2^E 代表指数位
eg.十进制的5.0,写成二进制就是101.0,相当于1.01 × 2^2。那么,按照上⾯V的格式,可以得出S=0,M=1.01,E=2。
eg.十进制的-5.0,写成二进制就是-101.0,相当于-1.01 × 2^2。那么,按照上面V的格式,可以得出 S=1,M=1.01, E=2。
IEEE 754规定:对于32位的浮点数,最⾼的1位存储符号位S,接着的8位存储指数E,剩下的23位存储有效数字M对于64位的浮点数,最⾼的1位存储符号位S,接着的11位存储指数E,剩下的52位存储有效数字M

存的过程:
IEEE 754 对有效数字M和指数E,还有⼀些特别规定。
前⾯说过, 1≤M<2 ,也就是说,M可以写成 1.xxxxxx 的形式,其中 xxxxxx 表⽰⼩数部分。IEEE 754 规定,在计算机内部保存M时,默认这个数的第⼀位总是1,因此可以被舍去,只保存后⾯的 xxxxxx部分。⽐如保存1.01的时候,只保存01,等到读取的时候,再把第⼀位的1加上去。这样做的⽬ 的,是节省1位有效数字。以32位浮点数为例,留给M只有23位,将第⼀位的1舍去以后,等于可以保 存24位有效数字。E为一个无符号整型,这意味着,如果E为8位,它的取值范围为0~255;如果E为11位,它的取值范围为0~2047。但是,我 们知道,科学计数法中的E是可以出现负数的,所以IEEE 754规定,存⼊内存时E的真实值必须再加上⼀个中间数,对于8位的E,这个中间数是127;对于11位的E,这个中间数是1023。⽐如,2^10的E是10,所以保存成32位浮点数时,必须保存成10+127=137,即10001001。
取的过程:
1.E不全为0或不全为1
这时,浮点数就采⽤下⾯的规则表⽰,即指数E的计算值减去127(或1023),得到真实值,再将有效数字M前加上第⼀位的1。⽐如:0.5 的⼆进制形式为0.1,由于规定正数部分必须为1,即将⼩数点右移1位,则为1.0*2^(-1),其阶码为-1+127(中间值)=126,表⽰为01111110,⽽尾数1.0去掉整数部分为0,补⻬0到23位00000000000000000000000,则其⼆进制表⽰形式为:0 01111110 00000000000000000000000
2.E全为0
这时,浮点数的指数E等于1-127(或者1-1023)即为真实值,有效数字M不再加上第⼀位的1,⽽是还 原为0.xxxxxx的⼩数。这样做是为了表⽰±0,以及接近于0的很⼩的数字。
0 00000000 00100000000000000000000
3.E全为1这时,如果有效数字M全为0,表⽰±⽆穷⼤(正负取决于符号位s)0 11111111 00010000000000000000000
3.大小端字节序和字节序判断
什么是大小端?

为什么会有大小端?

//返回1,就是小端存储;返回0,就是大端存储
//方法一
int check_sys()
{
int i=1;
return (*(char *)&i);
}
//方法二
int check_sys()
{
union
{
int i;
char c;
}un;
un.i=1;
reuturn un.c;
}
三、C语言的内存函数
1.memcpy函数
void * memcpy(void* destination, const void* source, size_t num);• 函数memcpy从source的位置开始向后复制num个字节的数据到destination指向的内存位置。• 这个函数在遇到 '\0' 的时候并不会停下来。• 如果source和destination有任何的重叠,复制的结果都是未定义的。Tips:对于重叠的内存,交给memmove来处理。
#include <stdio.h>
#include <string.h>
int main()
{
int arr1[] = { 1,2,3,4,5,6,7,8,9,10 };
int arr2[10] = { 0 };
memcpy(arr2, arr1, 20);
int i = 0;
for (i = 0; i < 10; i++)
{
printf("%d ", arr2[i]);//等价于printf("%d ",arr1[i]);
}
return 0;
}2.memmove函数
void * memmove ( void * destination, const void * source, size_t num );• 和memcpy的差别就是memmove函数处理的源内存块和⽬标内存块是可以重叠的。• 如果源空间和⽬标空间出现重叠,就得使⽤memmove函数处理。
#include <stdio.h>
#include <string.h>
int main()
{
int arr1[] = { 1,2,3,4,5,6,7,8,9,10 };
memmove(arr1+2, arr1, 20);
int i = 0;
for (i = 0; i < 10; i++)
{
printf("%d ", arr1[i]); //输出: 1 2 1 2 3 4 5 8 9 10
}
return 0;
}3.memset函数
void * memset ( void * ptr, int value, size_t num );memset是⽤来设置内存的,将内存中的值以字节为单位设置成想要的内容。
#include <stdio.h>
#include <string.h>
int main ()
{
char str[] = "hello world";
memset (str,'x',6);
printf(str); //输出: xxxxxxworld!
return 0;
}4.memcmp函数
int memcmp ( const void * ptr1, const void * ptr2, size_t num );• ⽐较从ptr1和ptr2指针指向的位置开始,向后的num个字节• 返回值如下:
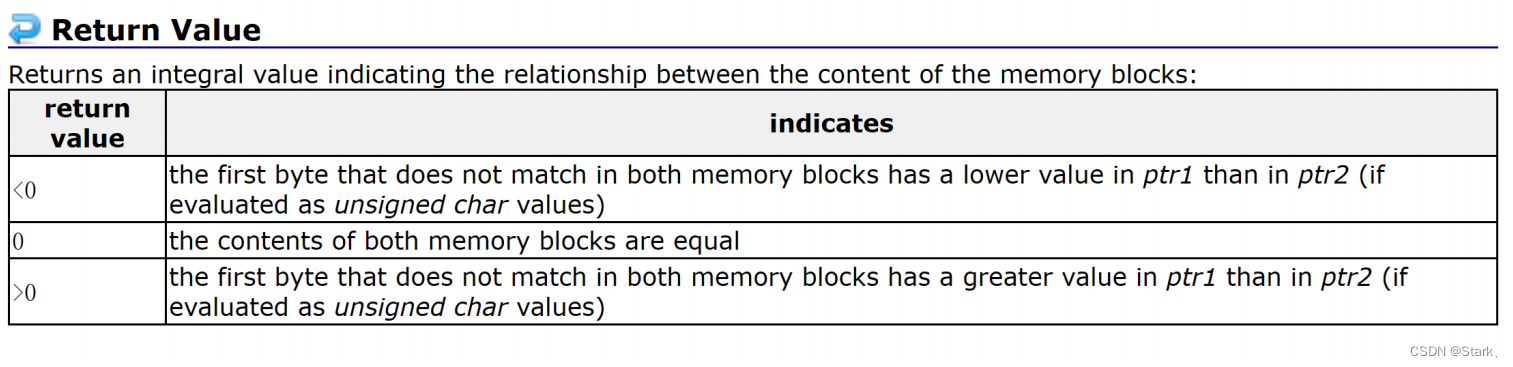
四、动态内存管理

有需要的小伙伴可以私信我获得这方面的具体内容。
附图:

谢谢观看!